Antipattern Front End occupato
L'esecuzione di attività asincrone in un numero elevato di thread in background può rendere non disponibili le risorse per altre attività simultanee in primo piano generando tempi di risposta non accettabili.
Descrizione del problema
Le attività a elevato utilizzo di risorse possono allungare i tempi di risposta per le richieste utente e generare una latenza elevata. Un modo per migliorare i tempi di risposta è eseguire l'offload di un'attività a elevato utilizzo di risorse in un thread separato. Questo approccio consente all'applicazione di fornire risposte tempestive durante l'elaborazione in background. Tuttavia anche le attività eseguite in un thread in background usano risorse. Un numero elevato di attività può impegnare in modo eccessivo i thread che gestiscono le richieste.
Nota
Il termine generico risorsa può dare riferimento, ad esempio, all'utilizzo di CPU e memoria o alle operazioni di I/O del disco e della rete.
In genere questo problema si verifica con le applicazioni sviluppate come frammento di codice monolitico, in cui tutta la logica di business viene combinata in un singolo livello condiviso con il livello di presentazione.
L'esempio con ASP.NET seguente illustra il problema. L'esempio completo è disponibile qui.
public class WorkInFrontEndController : ApiController
{
[HttpPost]
[Route("api/workinfrontend")]
public HttpResponseMessage Post()
{
new Thread(() =>
{
//Simulate processing
Thread.SpinWait(Int32.MaxValue / 100);
}).Start();
return Request.CreateResponse(HttpStatusCode.Accepted);
}
}
public class UserProfileController : ApiController
{
[HttpGet]
[Route("api/userprofile/{id}")]
public UserProfile Get(int id)
{
//Simulate processing
return new UserProfile() { FirstName = "Alton", LastName = "Hudgens" };
}
}
Il metodo
Postdel controllerWorkInFrontEndimplementa un'operazione HTTP POST. Questa operazione simula un'attività a esecuzione prolungata con utilizzo intensivo della CPU. L'attività viene eseguita in un thread separato nel tentativo di consentire il rapido completamento dell'operazione POST.Il metodo
Getdel controllerUserProfileimplementa un'operazione HTTP GET. Questo metodo implica un utilizzo della CPU notevolmente inferiore.
Il problema principale è il fabbisogno di risorse del metodo Post. Anche se l'attività viene inserita in un thread in background, è possibile che vengano usate notevoli risorse della CPU. Queste risorse vengono condivise con altre operazioni eseguite da altri utenti simultanei. Se un numero discreto di utenti invia questa richiesta nello stesso momento, è probabile che le prestazioni complessive si riducano, rallentando tutte le operazioni. Gli utenti che usano il metodo Get potrebbero, ad esempio, riscontrare una latenza elevata.
Come risolvere il problema
Trasferire i processi con uso intensivo di risorse in un back-end separato.
Con questo approccio, il front-end inserisce le attività a elevato utilizzo di risorse in una coda di messaggi. Il back-end preleva le attività per l'elaborazione asincrona. La coda funge anche da livellatore di carico, memorizzando nel buffer le richieste per il back-end. Se la coda diventa troppo lunga, è possibile configurare la scalabilità automatica in modo da aumentare il numero di istanze per il back-end.
Di seguito è riportata una versione modificata del codice precedente. In questa versione il metodo Post inserisce un messaggio in una coda del bus di servizio.
public class WorkInBackgroundController : ApiController
{
private static readonly QueueClient QueueClient;
private static readonly string QueueName;
private static readonly ServiceBusQueueHandler ServiceBusQueueHandler;
public WorkInBackgroundController()
{
var serviceBusConnectionString = ...;
QueueName = ...;
ServiceBusQueueHandler = new ServiceBusQueueHandler(serviceBusConnectionString);
QueueClient = ServiceBusQueueHandler.GetQueueClientAsync(QueueName).Result;
}
[HttpPost]
[Route("api/workinbackground")]
public async Task<long> Post()
{
return await ServiceBusQueueHandler.AddWorkLoadToQueueAsync(QueueClient, QueueName, 0);
}
}
Il back-end estrae i messaggi dalla coda del bus di servizio ed esegue l'elaborazione.
public async Task RunAsync(CancellationToken cancellationToken)
{
this._queueClient.OnMessageAsync(
// This lambda is invoked for each message received.
async (receivedMessage) =>
{
try
{
// Simulate processing of message
Thread.SpinWait(Int32.MaxValue / 1000);
await receivedMessage.CompleteAsync();
}
catch
{
receivedMessage.Abandon();
}
});
}
Considerazioni
- Questo approccio aggiunge un ulteriore livello di complessità all'applicazione. È necessario gestire in modo sicuro l'accodamento e la rimozione dalla coda per evitare la perdita di richieste in caso di errore.
- L'applicazione stabilisce una dipendenza da un servizio aggiuntivo per la coda di messaggi.
- L'ambiente di elaborazione deve essere sufficientemente scalabile per gestire il carico di lavoro previsto e soddisfare gli obiettivi di velocità effettiva necessari.
- Sebbene questo approccio migliori la velocità di risposta complessiva, il completamento delle attività trasferite nel back-end può richiedere più tempo.
Come rilevare il problema
Uno dei sintomi di un front-end occupato è la latenza elevata durante l'esecuzione delle attività a elevato utilizzo di risorse. È probabile che gli utenti finali segnalano tempi di risposta estesi o errori causati dal timeout dei servizi. Questi errori potrebbero anche restituire errori HTTP 500 (server interno) o ERRORI HTTP 503 (Servizio non disponibile). Esaminare i log di eventi per il server Web che possono contenere informazioni più dettagliate sulle cause e le circostanze degli errori.
Per provare a identificare questo problema è possibile eseguire la procedura seguente:
- Eseguire il monitoraggio del processo per il sistema di produzione per identificare i punti associati a tempi di risposta più lunghi.
- Esaminare i dati di telemetria acquisiti in questi punti per determinare la combinazione di operazioni eseguite e di risorse usate.
- Individuare eventuali correlazioni tra i tempi di risposta insoddisfacenti e i volumi e le combinazioni di operazioni eseguite in questi intervalli.
- Eseguire il test di carico di ogni operazione sospetta per identificare quali operazioni stanno usando le risorse rendendole non disponibili ad altre operazioni.
- Esaminare il codice sorgente di queste operazioni per determinare la possibile causa dell'eccessivo consumo eccessivo di risorse.
Diagnosi di esempio
Le sezioni seguenti applicano questa procedura all'applicazione di esempio descritta in precedenza.
Identificare i punti di rallentamento
Instrumentare ciascun metodo per tenere traccia della durata e delle risorse usate da ogni richiesta. Monitorare quindi l'applicazione in produzione. In questo modo si ottiene una visione generale del modo in cui le richieste si contendono le risorse. Durante i periodi di stress, è probabile che le richieste a esecuzione lenta con elevato utilizzo di risorse influiscano sulle altre operazioni; analizzare questo comportamento monitorando il sistema e rilevando il calo di prestazioni.
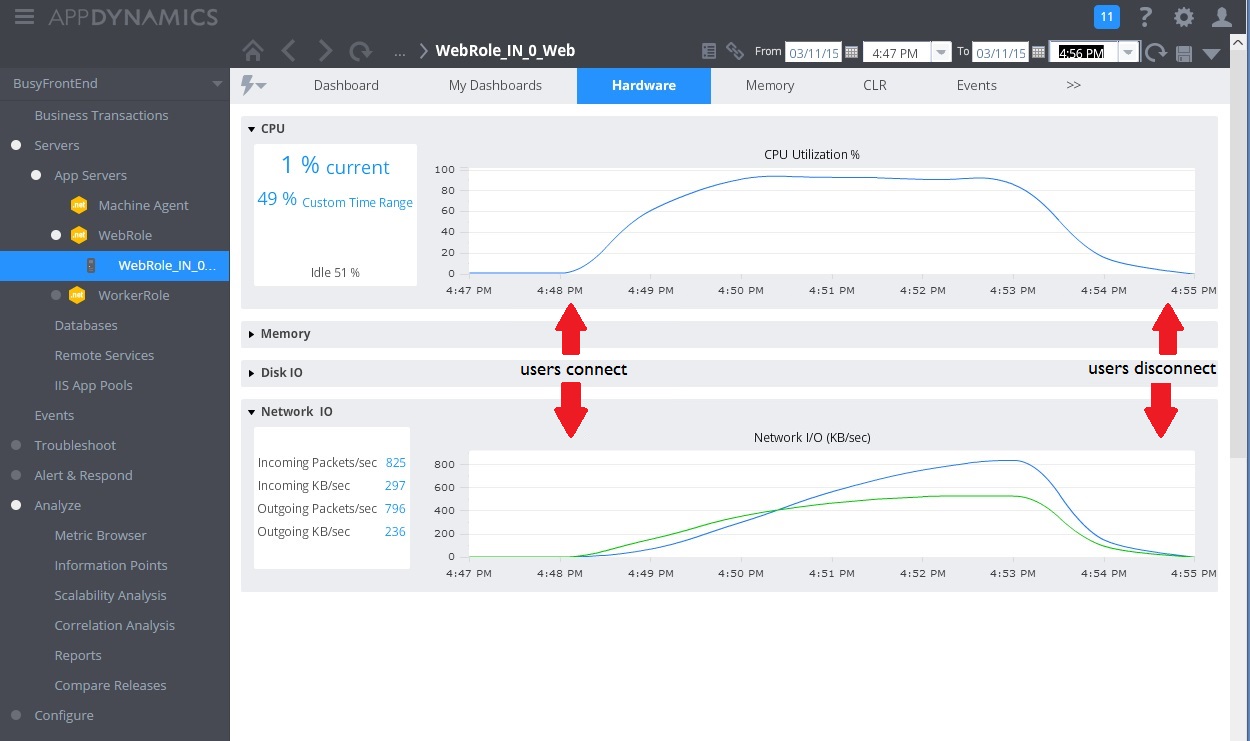
L'immagine seguente mostra un dashboard di monitoraggio. (Abbiamo usato AppDynamics per i test. Inizialmente, il sistema ha carico leggero. Gli utenti iniziano quindi a richiedere il metodo GET UserProfile. Le prestazioni sono abbastanza soddisfacenti fino a quando altri utenti iniziano ad inviare richieste al metodo POST WorkInFrontEnd. A questo punto i tempi di risposta si allungano notevolmente (prima freccia). I tempi di risposta migliorano solo dopo la diminuzione del volume di richieste per il controller WorkInFrontEnd (seconda freccia).
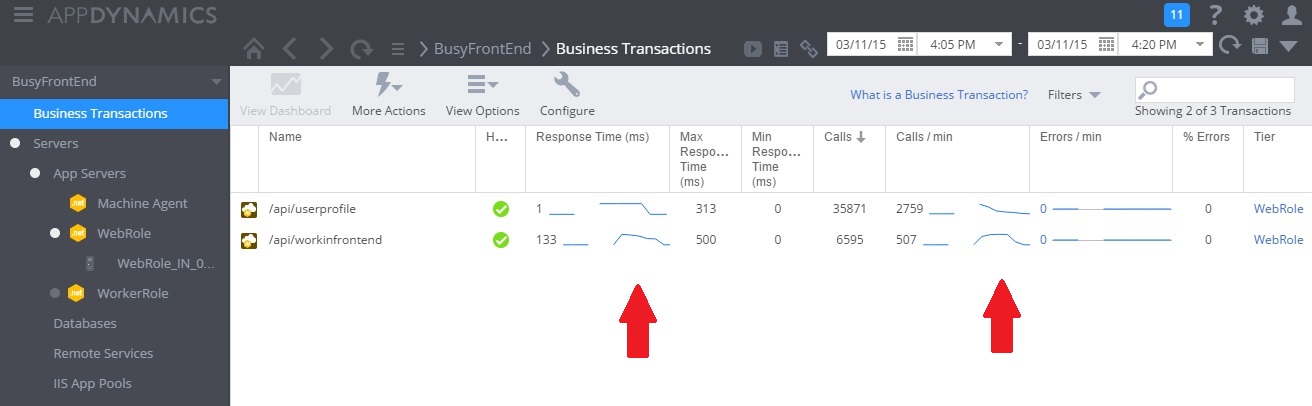
Esaminare i dati di telemetria e trovare le correlazioni
L'immagine successiva illustra alcune metriche raccolte per monitorare l'utilizzo delle risorse durante lo stesso intervallo. Inizialmente pochi utenti accedono al sistema. Quando il numero di utenti che si connette al sistema aumenta, l'utilizzo della CPU diventa molto elevato (100%). Si noti anche che la velocità di I/O della rete aumenta inizialmente quando aumenta l'utilizzo della CPU. Quando tuttavia si verifica un picco di utilizzo della CPU, la velocità di I/O della rete in realtà rallenta. Ciò avviene perché il sistema può gestire solo un numero relativamente ridotto di richieste quando la CPU raggiunge la capacità massima. A mano a mano che gli utenti si disconnettono, il carico della CPU diminuisce.
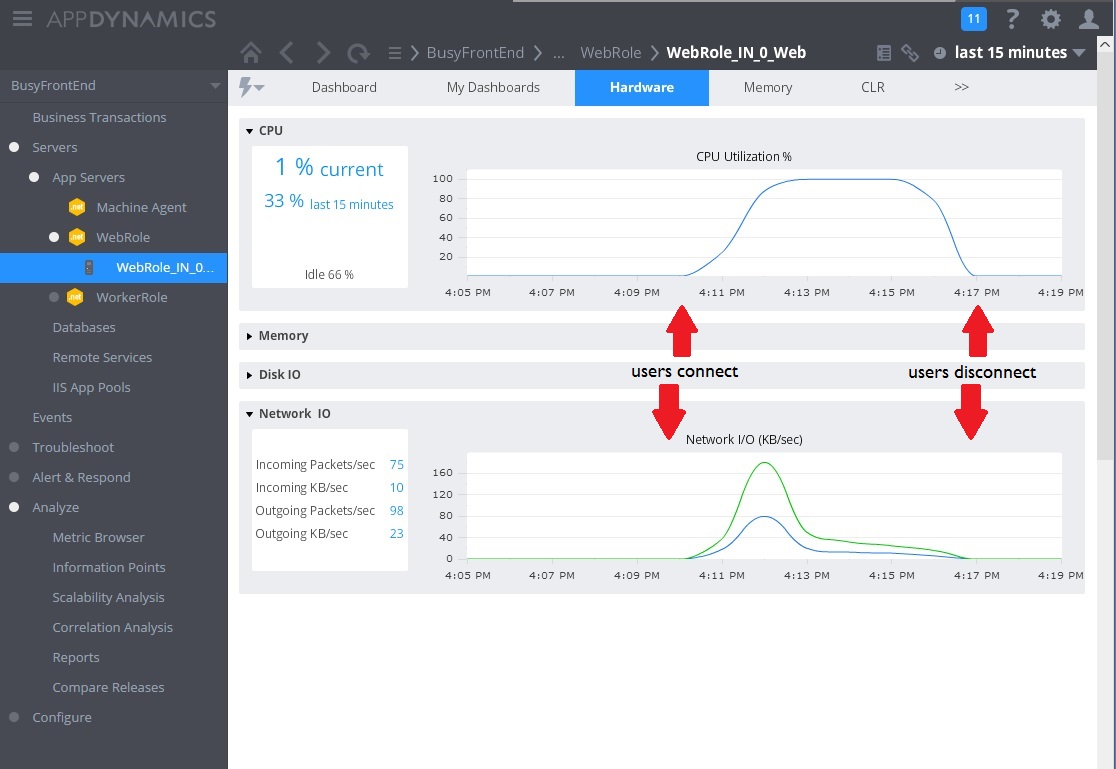
A questo punto sembra che il metodo Post nel controller WorkInFrontEnd sia il candidato ideale per un esame più attento. Per confermare l'ipotesi, sono necessarie ulteriori attività in un ambiente controllato.
Eseguire il test di carico
Il passaggio successivo è eseguire i test in un ambiente controllato. Ad esempio, eseguire una serie di test di carico includendo e quindi omettendo a turno ogni richiesta per verificare gli effetti.
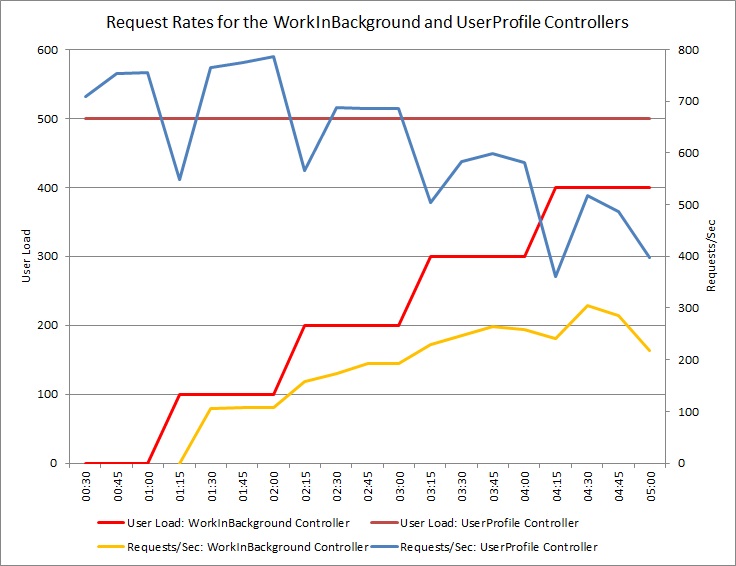
Il grafo seguente mostra i risultati dei test di carico eseguiti in una distribuzione identica del servizio cloud usata nei test precedenti. Nel test è stato usato un carico costante di 500 utenti che eseguono l'operazione Get nel controller UserProfile, oltre a un carico per passaggio di utenti che eseguono l'operazione Post nel controller WorkInFrontEnd.
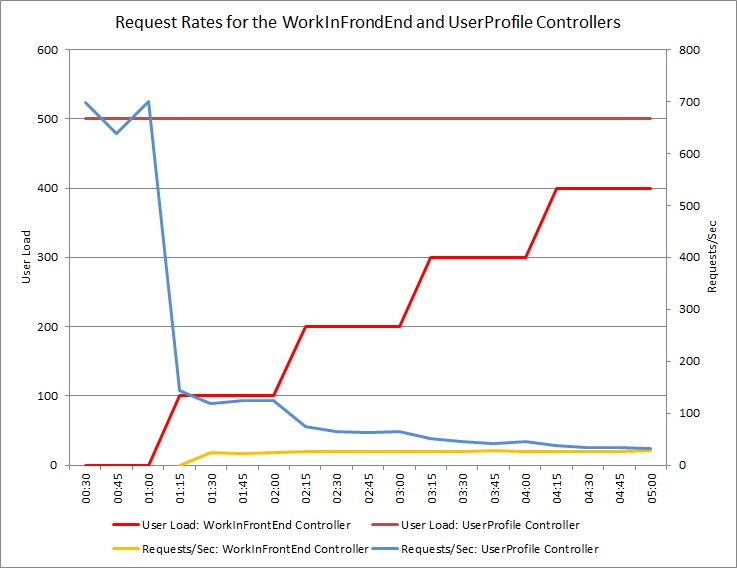
Inizialmente il carico per passaggio è 0 e quindi solo gli utenti attivi stanno eseguendo le richieste UserProfile. Il sistema è in grado di rispondere a circa 500 richieste al secondo. Dopo 60 secondi un carico di 100 utenti aggiuntivi inizia a inviare richieste POST al controller WorkInFrontEnd. Quasi immediatamente, il carico di lavoro inviato al controller UserProfile diminuisce fino a circa 150 richieste al secondo. Ciò è dovuto alla modalità di funzionamento dello strumento di esecuzione dei test di carico. Attende una risposta prima di inviare la richiesta successiva; maggiore è il tempo impiegato per ricevere una risposta, minore sarà la frequenza di richieste.
Quando il numero di utenti che invia richieste POST al controller WorkInFrontEnd aumenta, la velocità di risposta del controller UserProfile diminuisce. Si noti che il volume di richieste gestito dal controller WorkInFrontEnd rimane relativamente costante. La saturazione del sistema diventa evidente quando la velocità globale di entrambe le richieste tende verso un limite fisso ma basso.
Esaminare il codice sorgente
Il passaggio finale consiste nell'esaminare il codice sorgente. Il team di sviluppo è consapevole che il metodo Post può richiedere una notevole quantità di tempo e, per questo motivo, è stato usato un thread separato nell'implementazione originale. Questa scelta ha risolto il problema immediato perché il metodo Post non si è bloccato attendendo il completamento di un'attività a esecuzione prolungata.
Tuttavia, le attività eseguite da questo metodo usano ancora risorse di CPU, memoria e di altro tipo. L'abilitazione di questo processo per l'esecuzione asincrona potrebbe effettivamente compromettere le prestazioni, poiché gli utenti possono attivare contemporaneamente un numero elevato di operazioni di questo tipo in modo incontrollato. È previsto un limite al numero di thread che un server può eseguire. Superando questo limite è probabile che venga generata un'eccezione durante il tentativo di avviare un nuovo thread.
Nota
Questo non significa che è consigliabile evitare operazioni asincrone. L'esecuzione di un'operazione await asincrona in una chiamata di rete è una procedura consigliata. (Vedere il Antipattern di I/O sincrono. Il problema è che il lavoro a elevato utilizzo di CPU è stato generato su un altro thread.
Implementare la soluzione e verificare il risultato
L'immagine seguente mostra il monitoraggio delle prestazioni dopo l'implementazione della soluzione. Il carico è simile a quello illustrato in precedenza, ma i tempi di risposta per il controller UserProfile sono ora molto più veloci. Il volume di richieste è aumentato nella stessa durata da 2.759 a 23.565.
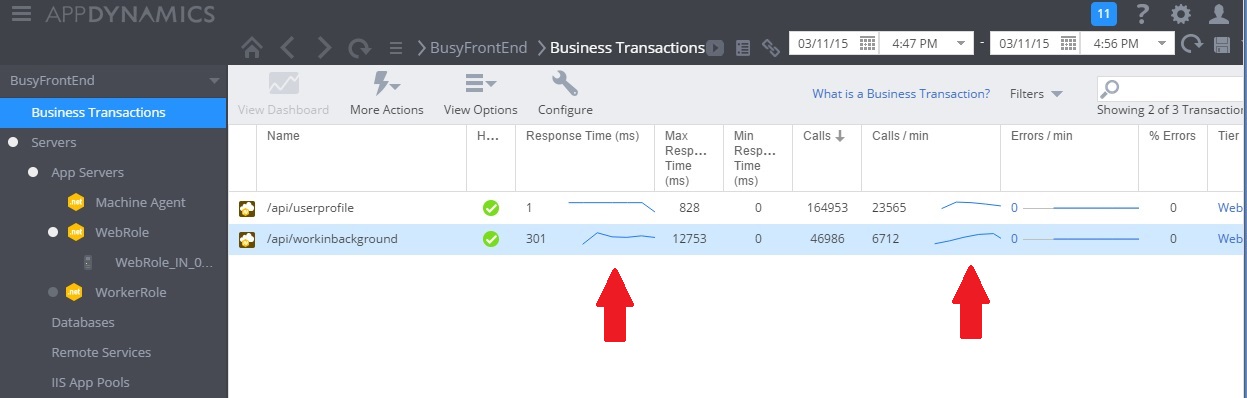
Si noti che il controller WorkInBackground ha inoltre gestito un volume di richieste molto più ampio. Tuttavia non è possibile eseguire un confronto diretto in questo caso, poiché il lavoro in esecuzione in questo controller è molto diverso dal codice originale. La nuova versione accoda semplicemente una richiesta, anziché eseguire un calcolo che richiede molto tempo. Il punto principale è che questo metodo non trascina più l'intero sistema sotto carico.
Anche l'utilizzo della CPU e della rete indica prestazioni migliori. L'utilizzo della CPU non ha mai raggiunto il 100% e il volume delle richieste di rete gestite è notevolmente maggiore del precedente e non si attenua finché il carico di lavoro non diminuisce.
Il grafo seguente mostra i risultati di un test di carico. Il volume complessivo di richieste elaborate risulta notevolmente migliore rispetto ai test precedenti.
Informazioni correlate
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per