Antipattern di creazione di istanze non corretta
In alcuni casi, vengono create continuamente nuove istanze di una classe, anziché essere create una sola volta e quindi condivise. Questo comportamento può danneggiare le prestazioni e viene definito antipattern di creazione di istanze non corretta. Un antipattern è una risposta comune a un problema ricorrente che è in genere inefficace e può anche essere controproducente.
Descrizione del problema
Molte librerie forniscono astrazioni di risorse esterne. Internamente, queste classi gestiscono in genere le proprie connessioni alla risorsa, agendo come broker che i client possono usare per accedere alla risorsa. Di seguito sono riportati alcuni esempi di classi broker pertinenti per le applicazioni Azure:
System.Net.Http.HttpClient. Comunica con un servizio Web tramite HTTP.Microsoft.ServiceBus.Messaging.QueueClient. Invia e riceve messaggi da una coda del bus di servizio.Microsoft.Azure.Documents.Client.DocumentClient. Connessione a un'istanza di Azure Cosmos DB.StackExchange.Redis.ConnectionMultiplexer. Si connette a Redis, tra cui Cache Redis di Azure.
Per queste classi è prevista la creazione di una sola istanza, che viene riutilizzata per tutta la durata di un'applicazione. È un errore comune ritenere che queste classi debbano essere acquisite solo quando è necessario e rilasciate rapidamente. (Quelli elencati di seguito sono librerie .NET, ma il modello non è univoco per .NET. Nell'esempio ASP.NET seguente viene creata un'istanza di HttpClient per comunicare con un servizio remoto. L'esempio completo è disponibile qui.
public class NewHttpClientInstancePerRequestController : ApiController
{
// This method creates a new instance of HttpClient and disposes it for every call to GetProductAsync.
public async Task<Product> GetProductAsync(string id)
{
using (var httpClient = new HttpClient())
{
var hostName = HttpContext.Current.Request.Url.Host;
var result = await httpClient.GetStringAsync(string.Format("http://{0}:8080/api/...", hostName));
return new Product { Name = result };
}
}
}
In un'applicazione Web questa tecnica non è scalabile. Viene creato un nuovo oggetto HttpClient per ogni richiesta dell'utente. In caso di carico pesante, il server Web può esaurire il numero di socket disponibile, causando errori SocketException.
Questo problema non è limitato alla classe HttpClient. Altre classi che eseguono il wrapping di risorse o sono costose da creare potrebbero causare problemi simili. L'esempio seguente crea un'istanza della classe ExpensiveToCreateService. In questo caso il problema non è necessariamente l'esaurimento dei socket, ma semplicemente il tempo necessario per la creazione di ogni istanza. La creazione e l'eliminazione continua di istanze di questa classe possono incidere negativamente sulla scalabilità del sistema.
public class NewServiceInstancePerRequestController : ApiController
{
public async Task<Product> GetProductAsync(string id)
{
var expensiveToCreateService = new ExpensiveToCreateService();
return await expensiveToCreateService.GetProductByIdAsync(id);
}
}
public class ExpensiveToCreateService
{
public ExpensiveToCreateService()
{
// Simulate delay due to setup and configuration of ExpensiveToCreateService
Thread.SpinWait(Int32.MaxValue / 100);
}
...
}
Come correggere un antipattern di creazione di istanze non corretta
Se la classe che esegue il wrapping della risorsa esterna è condivisibile e thread-safe, creare un'istanza singleton condivisa o un pool di istanze della classe riutilizzabili.
L'esempio seguente usa un'istanza statica di HttpClient, condividendo quindi la connessione tra tutte le richieste.
public class SingleHttpClientInstanceController : ApiController
{
private static readonly HttpClient httpClient;
static SingleHttpClientInstanceController()
{
httpClient = new HttpClient();
}
// This method uses the shared instance of HttpClient for every call to GetProductAsync.
public async Task<Product> GetProductAsync(string id)
{
var hostName = HttpContext.Current.Request.Url.Host;
var result = await httpClient.GetStringAsync(string.Format("http://{0}:8080/api/...", hostName));
return new Product { Name = result };
}
}
Considerazioni
L'elemento principale di questo antipattern è la ripetuta creazione ed eliminazione di istanze di un oggetto condivisibile. Se una classe non è condivisibile (non è thread-safe), questo antipattern non è applicabile.
Il tipo di risorsa condivisa può indicare se si deve usare un singleton o creare un pool. La classe
HttpClientè progettata per essere condivisa anziché inserita in un pool. Altri oggetti potrebbero supportare il pool, consentendo al sistema di distribuire il carico di lavoro tra più istanze.Gli oggetti che si condividono tra più richieste devono essere thread-safe. La classe
HttpClientè progettata per essere utilizzata in questo modo, ma altre classi potrebbero non supportare richieste simultanee. Controllare la documentazione disponibile.Prestare attenzione quando si impostano proprietà su oggetti condivisi, perché tale operazione può causare situazioni di race condition. Ad esempio, se si imposta
DefaultRequestHeaderssulla classeHttpClientprima di ogni richiesta, può verificarsi una situazione di race condition. Impostare tali proprietà una sola volta, ad esempio durante l'avvio, quindi creare istanze separate se è necessario configurare impostazioni diverse.Alcuni tipi di risorse sono scarse e non devono essere trattenute. Le connessioni di database sono un esempio. Tenendo aperta una connessione di database non necessaria si potrebbe impedire l'accesso contemporaneo al database da parte di altri utenti.
In .NET Framework molti oggetti che stabiliscono connessioni a risorse esterne vengono creati usando metodi factory statici di altre classi che gestiscono tali connessioni. Questi oggetti devono essere salvati e riutilizzati, invece di essere eliminati e ricreati. Ad esempio, nel bus di servizio di Azure, l'oggetto
QueueClientviene creato tramite un oggettoMessagingFactory. Internamente,MessagingFactorygestisce le connessioni. Per altre informazioni, vedere Procedure consigliate per il miglioramento delle prestazioni tramite la messaggistica del bus di servizio.
Come rilevare un antipattern di creazione di istanze non corretta
Sintomi di questo problema includono la riduzione della velocità effettiva o l'aumento della frequenza degli errori, insieme a uno o più degli effetti seguenti:
- Aumento delle eccezioni che indicano l'esaurimento delle risorse, ad esempio i socket, le connessioni al database, gli handle di file e così via.
- Aumento dell'uso di memoria e del garbage collection.
- Aumento dell'attività di rete, disco o database.
Per provare a identificare questo problema è possibile eseguire la procedura seguente:
- Eseguire il monitoraggio del processo per il sistema di produzione per identificare i punti associati a tempi di risposta più lunghi o arresti anomali del sistema causati da mancanza di risorse.
- Esaminare i dati di telemetria acquisiti in questi punti per determinare quali operazioni potrebbero creare ed eliminare oggetti che consumano risorse.
- Eseguire test di carico su ogni operazione sospetta, in un ambiente di test controllato anziché nel sistema di produzione.
- Esaminare il codice sorgente ed esaminare come vengono gestiti gli oggetti broker.
Esaminare le tracce dello stack per le operazioni a esecuzione prolungata o che generano eccezioni quando il sistema è in condizioni di carico. Queste informazioni sono utili per identificare come vengono usate le risorse da queste operazioni. Le eccezioni possono aiutare a determinare se gli errori sono causati dall'esaurimento di risorse condivise.
Diagnosi di esempio
Le sezioni seguenti applicano questa procedura all'applicazione di esempio descritta in precedenza.
Identificare i punti di rallentamento o errore
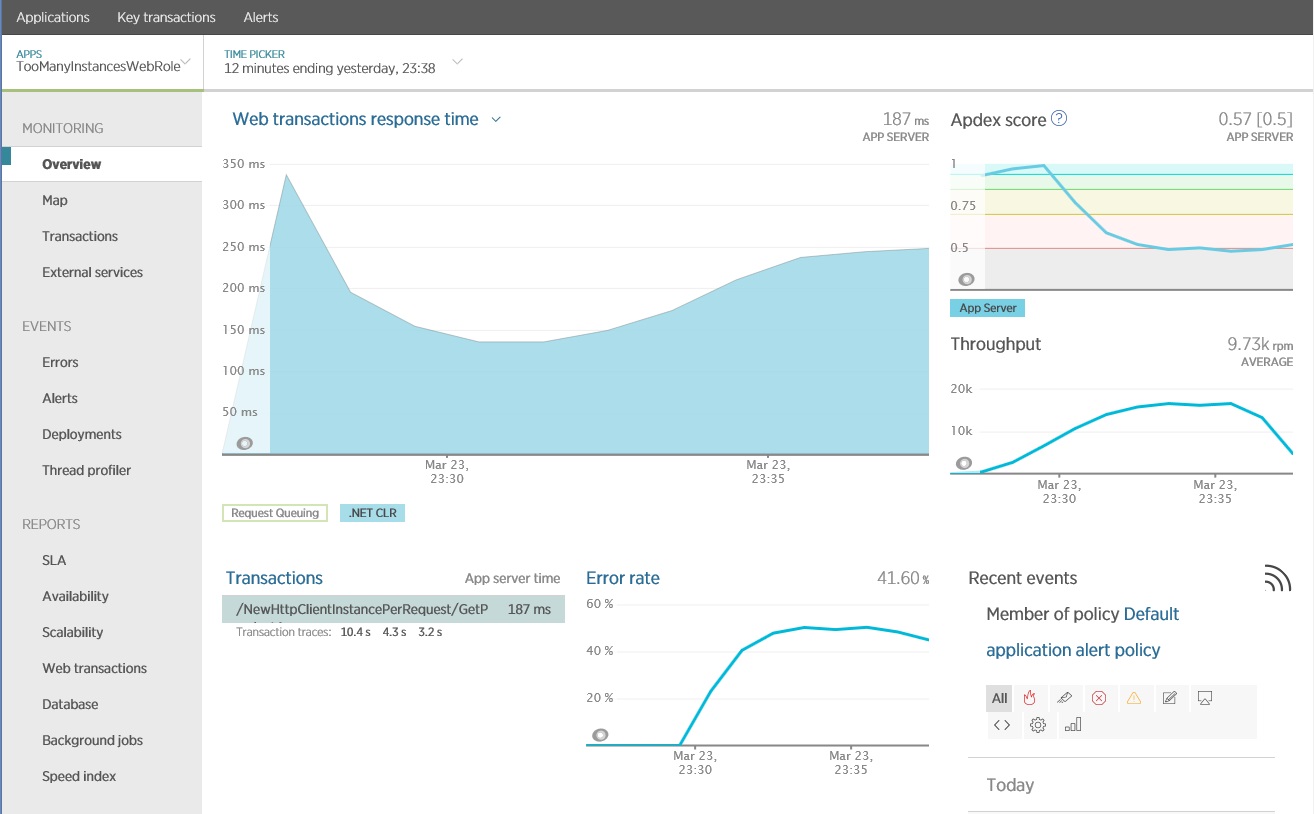
La figura seguente mostra i risultati generati utilizzando New Relic APM, che mostra le operazioni che hanno tempi di risposta lunghi. In questo caso, vale la pena di analizzare ulteriormente il metodo GetProductAsync nel controller NewHttpClientInstancePerRequest. Si noti che il tasso di errore aumenta quando queste operazioni sono in esecuzione.
Esaminare i dati di telemetria e trovare le correlazioni
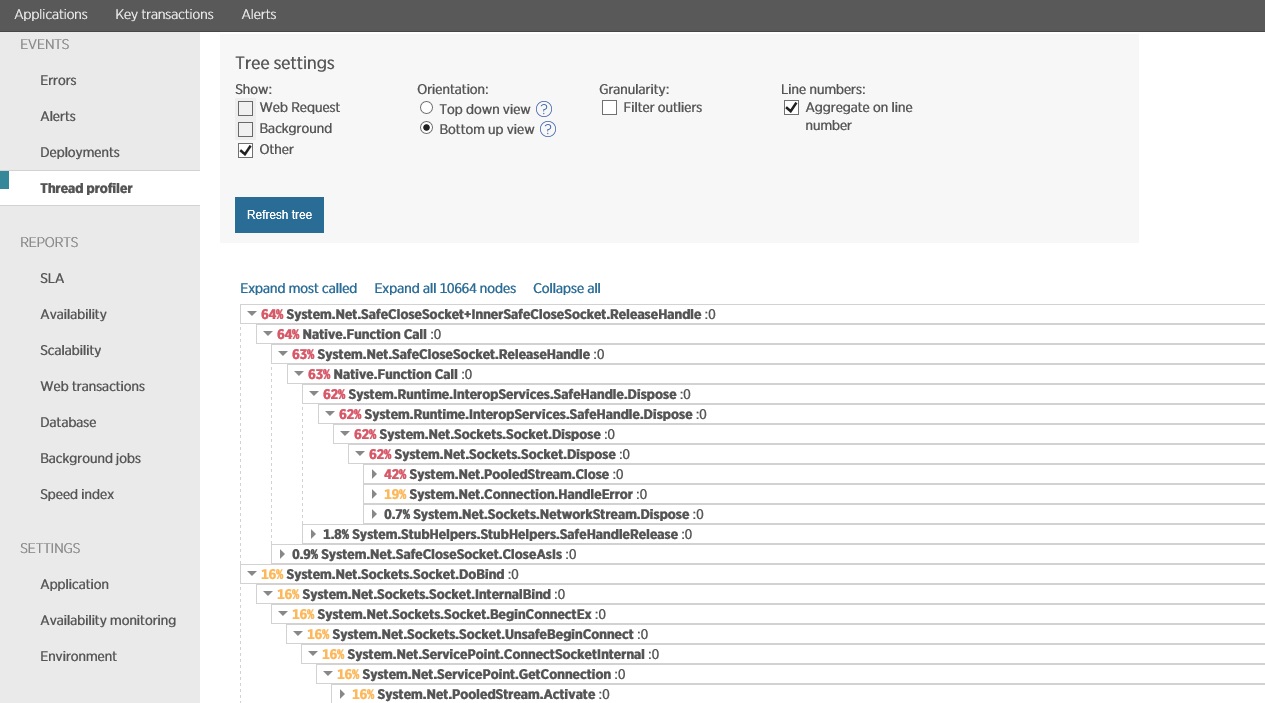
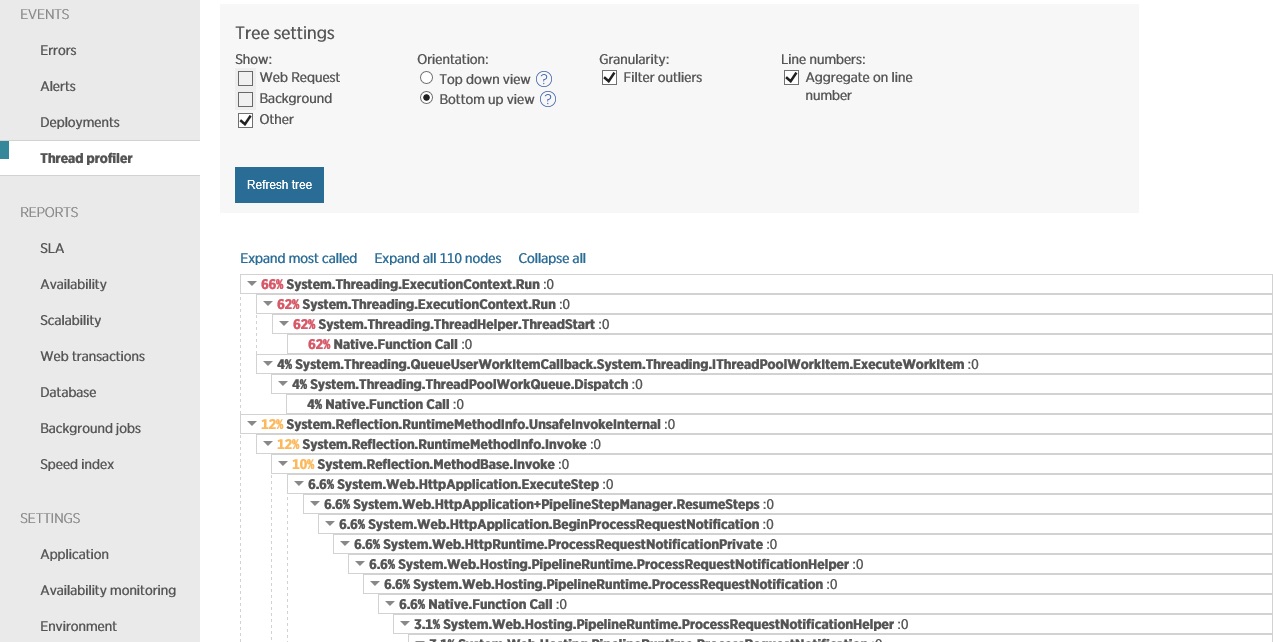
L'immagine successiva mostra i dati acquisiti usando la profilatura dei thread, nello stesso periodo corrispondente all'immagine precedente. Il sistema impiega molto tempo per l'apertura delle connessioni socket e anche più tempo per chiuderle e gestire le eccezioni di socket.
Eseguire i test di carico
Per simulare le operazioni tipiche che gli utenti potrebbero eseguire, utilizzare i test di carico. Ciò consente di identificare quali parti di un sistema subiscono un esaurimento delle risorse con carichi diversi. Eseguire questi test in un ambiente controllato anziché nel sistema di produzione. Il grafico seguente mostra la velocità effettiva delle richieste gestite dal controller NewHttpClientInstancePerRequest mentre il carico utente aumenta a 100 utenti simultanei.
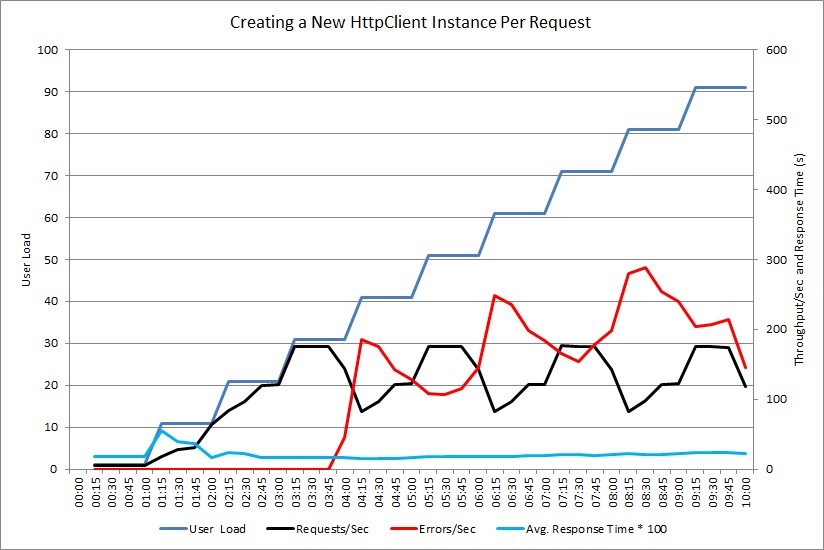
Inizialmente il volume di richieste gestite al secondo aumenta man mano che aumenta il carico di lavoro. Quando gli utenti sono circa 30, invece, il volume di richieste riuscite raggiunge un limite e il sistema inizia a generare eccezioni. Da quel punto in avanti, il volume delle eccezioni aumenta gradualmente con il carico utente.
Il test di carico ha segnalato questi errori come errori HTTP 500 (server interno). L'esame dei dati di telemetria ha dimostrato che questi errori sono stati causati dall'esaurimento delle risorse di socket da parte del sistema, con la creazione di un numero sempre crescente di oggetti HttpClient.
Il grafico successivo mostra un test simile per un controller che crea l'oggetto personalizzato ExpensiveToCreateService.
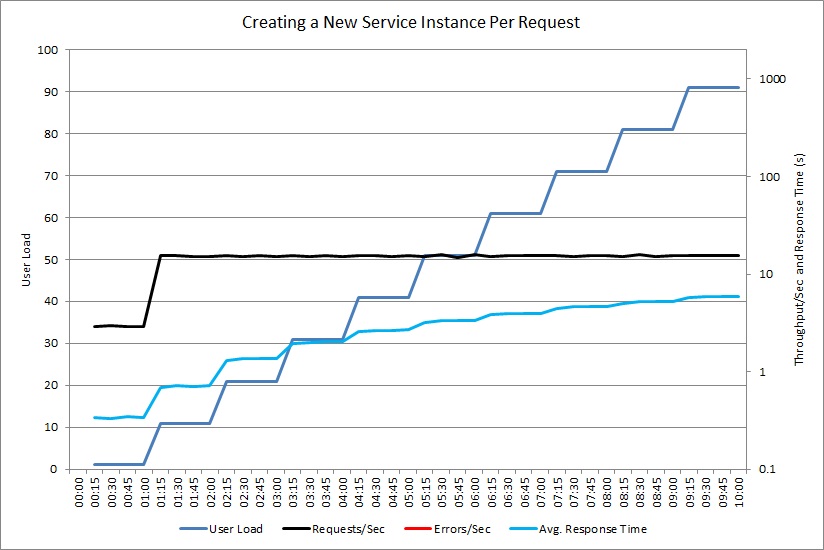
Questa volta il controller non genera alcuna eccezione, ma la velocità effettiva raggiunge ancora una soglia, mentre il tempo di risposta medio aumenta con fattore 20 Il grafico usa una scala logaritmica per il tempo di risposta e la velocità effettiva. I dati di telemetria hanno dimostrato che la creazione di nuove istanze di ExpensiveToCreateService è stata la causa principale del problema.
Implementare la soluzione e verificare il risultato
Dopo aver cambiato il metodo GetProductAsync in modo che venga condivisa una singola istanza HttpClient, un secondo test di carico ha dimostrato prestazioni migliorate. Non sono stati segnalati errori e il sistema è stato in grado di gestire un incremento del carico fino a 500 richieste al secondo. Il tempo medio di risposta si è ridotto a metà rispetto al test precedente.
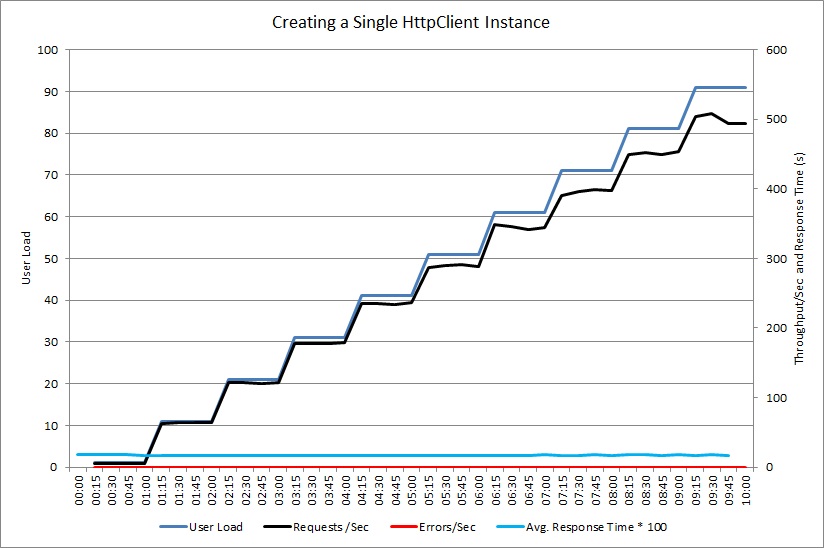
Per il confronto, l'immagine seguente mostra i dati di telemetria di monitoraggio dello stack. Questa volta il sistema passa la maggior parte del tempo a eseguire il lavoro effettivo, anziché ad aprire e chiudere socket.
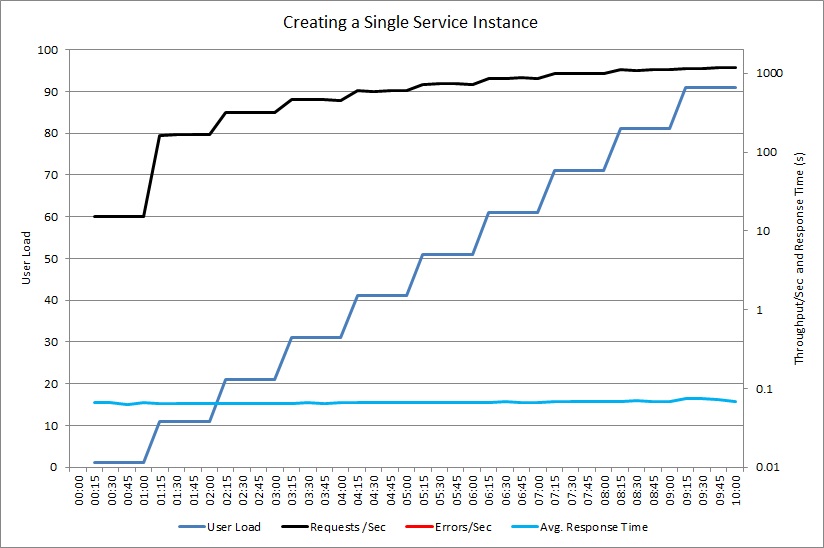
Il grafico successivo mostra un test di carico simile utilizzando un'istanza condivisa dell'oggetto ExpensiveToCreateService. Anche questa volta il volume di richieste gestite aumenta in linea con il carico utente, mentre il tempo di risposta medio rimane basso.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per