Scomporre un'attività che esegue un'elaborazione complessa in una serie di elementi distinti riutilizzabili. In questo modo è possibile migliorare le prestazioni, la scalabilità e la riutilizzabilità consentendo agli elementi attività che eseguono l'elaborazione di essere distribuiti e ridimensionati in modo indipendente.
Contesto e problema
È disponibile una pipeline di attività sequenziali che è necessario elaborare. Un approccio semplice ma flessibile per implementare questa applicazione consiste nell'eseguire questa elaborazione in un modulo monolitico. Tuttavia, questo approccio potrebbe ridurre le opportunità di refactoring del codice, ottimizzarlo o riutilizzarlo se sono necessarie parti della stessa elaborazione altrove nell'applicazione.
Il diagramma seguente illustra uno dei problemi relativi all'elaborazione dei dati usando un approccio monolitico, ovvero l'impossibilità di riutilizzare il codice tra più pipeline. In questo esempio un'applicazione riceve ed elabora i dati da due origini. Un modulo separato elabora i dati da ogni origine eseguendo una serie di attività per trasformare i dati prima di passare il risultato alla logica di business dell'applicazione.
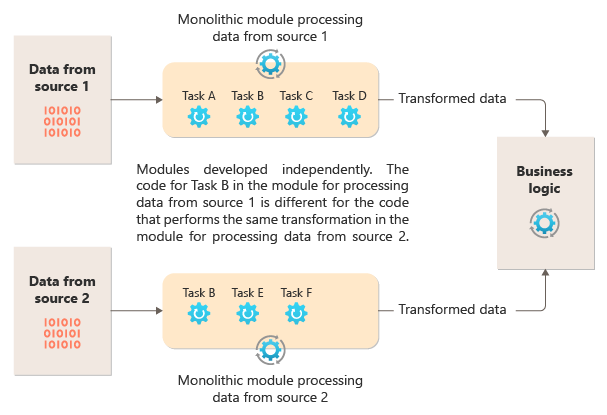
Alcune delle attività eseguite dai moduli monolitici sono funzionalmente simili, ma il codice deve essere ripetuto in entrambi i moduli ed è probabilmente strettamente associato all'interno del relativo modulo. Oltre all'impossibilità di riutilizzare la logica, questo approccio introduce un rischio quando cambiano i requisiti. È necessario ricordare di aggiornare il codice in entrambe le posizioni.
Esistono altre sfide con un'implementazione monolitica non correlata a più pipeline o riutilizzo. Con un monolith, non è possibile eseguire attività specifiche in ambienti diversi o ridimensionarle in modo indipendente. Alcune attività potrebbero essere a elevato utilizzo di calcolo e potrebbero trarre vantaggio dall'esecuzione su hardware potente o dall'esecuzione di più istanze in parallelo. Altre attività potrebbero non avere gli stessi requisiti. Inoltre, con monoliti, è difficile riordinare le attività o inserire nuove attività nella pipeline. Queste modifiche richiedono la necessità di ripetere l'intera pipeline.
Soluzione
Suddividere l'elaborazione richiesta per ogni flusso in un set di componenti separati (o filtri), ognuno dei quali esegue una singola attività. I filtri sono composti in pipeline collegando i filtri con pipe. I filtri ricevono messaggi da una pipe in ingresso e pubblicano messaggi in una pipe in uscita diversa. Le pipe non eseguono il routing o altre logiche. Connettono solo i filtri, passando il messaggio di output da un filtro come input al successivo.
I filtri agiscono in modo indipendente e non sono a conoscenza di altri filtri. Sono consapevoli solo dei relativi schemi di input e output. Di conseguenza, i filtri possono essere disposti in qualsiasi ordine, purché lo schema di input per qualsiasi filtro corrisponda allo schema di output per il filtro precedente. L'uso di uno schema standardizzato per tutti i filtri migliora la possibilità di riordinare i filtri.
L'accoppiamento libero dei filtri semplifica le attività seguenti:
- Creare nuove pipeline composte da filtri esistenti
- Aggiornare o sostituire la logica nei singoli filtri
- Riordinare i filtri, se necessario
- Eseguire filtri su hardware diverso, se necessario
- Eseguire filtri in parallelo
Questo diagramma mostra una soluzione implementata con pipe e filtri:
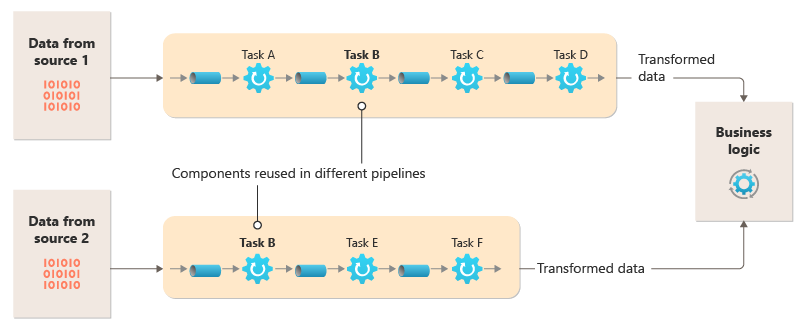
Il tempo necessario per elaborare una singola richiesta dipende dalla velocità dei filtri più lenti nella pipeline. Uno o più filtri possono essere colli di bottiglia, soprattutto se un numero elevato di richieste viene visualizzato in un flusso da una determinata origine dati. La possibilità di eseguire istanze parallele di filtri lenti consente al sistema di distribuire il carico e migliorare la velocità effettiva.
La possibilità di eseguire filtri in istanze di calcolo diverse consente di ridimensionarli in modo indipendente e sfruttare l'elasticità fornita da molti ambienti cloud. Un filtro a elevato utilizzo di calcolo può essere eseguito su hardware a prestazioni elevate, mentre altri filtri meno impegnativi possono essere ospitati su hardware meno costoso. I filtri non devono neanche trovarsi nello stesso data center o nella stessa posizione geografica, consentendo l'esecuzione di ogni elemento in una pipeline in un ambiente vicino alle risorse necessarie. Questo diagramma mostra un esempio applicato alla pipeline per i dati dell'origine 1:
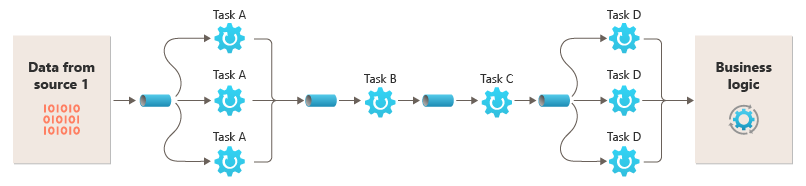
Se l'input e l'output di un filtro sono strutturati come flusso, è possibile eseguire l'elaborazione per ogni filtro in parallelo. Il primo filtro nella pipeline può avviare il lavoro e restituire i risultati, che vengono passati direttamente al filtro successivo nella sequenza prima che il primo filtro completi il proprio lavoro.
L'uso del modello Pipe e filtri insieme al modello Transazioni di compensazione è un approccio alternativo all'implementazione di transazioni distribuite. È possibile suddividere una transazione distribuita in attività distinte e compensabili, ognuna delle quali può essere implementata tramite un filtro che implementa anche il modello di transazione di compensazione. È possibile implementare i filtri in una pipeline come attività ospitate separate che vengono eseguite vicino ai dati gestiti.
Considerazioni e problemi
Quando si decide come implementare questo modello, tenere presente quanto segue:
Complessità. La maggiore flessibilità offerta da questo modello può anche presentare complessità, specialmente se i filtri in una pipeline sono distribuiti su server diversi.
Affidabilità. Usare un'infrastruttura che garantisce che il flusso di dati tra i filtri in una pipe non andrà perso.
Idempotenza. Se un filtro in una pipeline non riesce dopo aver ricevuto un messaggio e il lavoro viene riprogrammato in un'altra istanza del filtro, parte del lavoro potrebbe essere già stata completata. Se il lavoro aggiorna alcuni aspetti dello stato globale (ad esempio le informazioni archiviate in un database), è possibile ripetere un singolo aggiornamento. Un problema simile potrebbe verificarsi se un filtro ha esito negativo dopo che ha inviato i risultati al filtro successivo, ma prima di indicare che il lavoro è stato completato correttamente. In questi casi, un'altra istanza del filtro potrebbe ripetere questo lavoro, causando la pubblicazione degli stessi risultati due volte. Questo scenario potrebbe comportare filtri successivi nell'elaborazione della pipeline due volte gli stessi dati. Di conseguenza, i filtri in una pipeline devono essere progettati per essere idempotenti. Per altre informazioni, vedere Idempotency Patterns (Modelli di Idempotenza) nel blog di Jonathan Oliver.
Messaggi ripetuti. Se un filtro in una pipeline non riesce dopo aver inviato un messaggio alla fase successiva della pipeline, potrebbe essere eseguita un'altra istanza del filtro e verrà inserita una copia dello stesso messaggio nella pipeline. Questo scenario potrebbe causare il passaggio di due istanze dello stesso messaggio al filtro successivo. Per evitare questo problema, la pipeline deve rilevare ed eliminare messaggi duplicati.
Nota
Se si implementa la pipeline usando code di messaggi (ad esempio bus di servizio di Azure code), l'infrastruttura di accodamento messaggi potrebbe fornire il rilevamento e la rimozione automatici dei messaggi duplicati.
Contesto e stato. In una pipeline, ciascun filtro viene eseguito essenzialmente in isolamento e non deve formulare alcuna ipotesi su come è stato richiamato. Di conseguenza, ogni filtro deve essere fornito con contesto sufficiente per eseguire il proprio lavoro. Questo contesto può includere una quantità significativa di informazioni sullo stato. Se i filtri usano lo stato esterno, ad esempio i dati in un database o un'archiviazione esterna, è necessario considerare l'impatto sulle prestazioni. Ogni filtro deve caricare, operare e rendere persistente lo stato, che comporta un sovraccarico sulle soluzioni che caricano lo stato esterno una sola volta.
Tolleranza al messaggio. I filtri devono essere tolleranti ai dati nel messaggio in arrivo in cui non operano. Operano sui dati pertinenti e ignorano altri dati e li passano senza modifiche nel messaggio di output.
Gestione degli errori: ogni filtro deve determinare cosa fare in caso di errore di interruzione. Il filtro deve determinare se ha esito negativo nella pipeline o propaga l'eccezione.
Quando usare questo modello
Usare questo modello quando:
L'elaborazione richiesta da un'applicazione può essere facilmente suddivisa in un set di passaggi indipendenti.
I passaggi di elaborazione eseguiti da un'applicazione hanno requisiti di scalabilità differenti.
Nota
È possibile raggruppare i filtri che devono essere ridimensionati nello stesso processo. Per altre informazioni, vedere Compute Resource Consolidation pattern (Modello di consolidamento delle risorse di calcolo).
È necessaria la flessibilità necessaria per consentire il riordinamento dei passaggi di elaborazione usata dall'applicazione o per consentire la possibilità di aggiungere e rimuovere passaggi.
Il sistema può trarre vantaggio dalla distribuzione dell'elaborazione per i passaggi su server diversi.
È necessaria una soluzione affidabile che riduce al minimo gli effetti dell'errore in un passaggio durante l'elaborazione dei dati.
Questo modello potrebbe non essere utile quando:
L'applicazione segue un modello di richiesta-risposta.
L'elaborazione delle attività deve essere completata come parte di una richiesta iniziale, ad esempio uno scenario di richiesta/risposta.
I passaggi di elaborazione eseguiti da un'applicazione non sono indipendenti o devono essere eseguiti insieme come parte di una singola transazione.
La quantità di informazioni di contesto o stato necessarie per un passaggio rende questo approccio inefficiente. Potrebbe essere possibile rendere persistenti le informazioni sullo stato in un database, ma non usare questa strategia se il carico aggiuntivo sul database causa una contesa eccessiva.
Progettazione del carico di lavoro
Un architetto deve valutare il modo in cui il modello Pipe e filtri può essere usato nella progettazione del carico di lavoro per soddisfare gli obiettivi e i principi trattati nei pilastri di Azure Well-Architected Framework. Ad esempio:
| Concetto fondamentale | Come questo modello supporta gli obiettivi di pilastro |
|---|---|
| Le decisioni di progettazione dell'affidabilità consentono al carico di lavoro di diventare resilienti a malfunzionamenti e di assicurarsi che venga ripristinato in uno stato completamente funzionante dopo che si verifica un errore. | La singola responsabilità di ogni fase consente di concentrarsi sull'attenzione ed evita la distrazione dell'elaborazione dei dati conmming. - SEMPLICITÀ RE:01 - RE:07 Processi in background |
Come per qualsiasi decisione di progettazione, prendere in considerazione eventuali compromessi rispetto agli obiettivi degli altri pilastri che potrebbero essere introdotti con questo modello.
Esempio
È possibile usare una sequenza di code di messaggi per fornire l'infrastruttura necessaria per implementare una pipeline. Una coda di messaggi iniziale riceve messaggi non elaborati che diventano l'inizio delle pipe e dell'implementazione del modello di filtri. Un componente implementato come attività di filtro è in ascolto di un messaggio in questa coda, esegue il lavoro e quindi pubblica un messaggio nuovo o trasformato nella coda successiva nella sequenza. Un'altra attività di filtro può restare in ascolto dei messaggi in questa coda, elaborarli, pubblicare i risultati in un'altra coda e così via, fino al passaggio finale che termina il processo di pipe e filtri. Questo diagramma illustra una pipeline che usa code di messaggi:

È possibile implementare una pipeline di elaborazione di immagini usando questo modello. Se il carico di lavoro accetta un'immagine, l'immagine potrebbe passare attraverso una serie di filtri ampiamente indipendenti e riordinabili per eseguire azioni come:
- Moderazione del contenuto
- resizing
- Watermarking
- Riorientamento
- Rimozione dei metadati exif
- Pubblicazione della rete per la distribuzione di contenuti (rete CDN)
In questo esempio i filtri possono essere implementati come distribuiti singolarmente Funzioni di Azure o anche una singola app per le funzioni di Azure che contiene ogni filtro come distribuzione isolata. L'uso di trigger, associazioni di input e associazioni di output di Funzioni di Azure può semplificare il codice di filtro e lavorare automaticamente con una pipe basata su coda usando un controllo attestazione per l'immagine da elaborare.

Di seguito è riportato un esempio dell'implementazione di un filtro come funzione di Azure, attivato da una pipe di Archiviazione coda con un'attestazione Check all'immagine e la scrittura di un nuovo controllo attestazioni in un'altra pipe di Archiviazione coda potrebbe essere simile. L'implementazione è stata sostituita con pseudocodice nei commenti per brevità. Altro codice simile a questo è disponibile nella dimostrazione del modello Pipe e filtri disponibile in GitHub.
// This is the "Resize" filter. It handles claim checks from input pipe, performs the
// resize work, and places a claim check in the next pipe for anther filter to handle.
[Function(nameof(ResizeFilter))]
[QueueOutput("pipe-fjur", Connection = "pipe")] // Destination pipe claim check
public async Task<string> RunAsync(
[QueueTrigger("pipe-xfty", Connection = "pipe")] string imageFilePath, // Source pipe claim check
[BlobInput("{QueueTrigger}", Connection = "pipe")] BlockBlobClient imageBlob) // Image to process
{
_logger.LogInformation("Processing image {uri} for resizing.", imageBlob.Uri);
// Idempotency checks
// ...
// Download image based on claim check in queue message body
// ...
// Resize the image
// ...
// Write resized image back to storage
// ...
// Create claim check for image and place in the next pipe
// ...
_logger.LogInformation("Image resizing done or not needed. Adding image {filePath} into the next pipe.", imageFilePath);
return imageFilePath;
}
Nota
Spring Integration Framework ha un'implementazione del modello di pipe e filtri.
Passaggi successivi
Quando si implementa questo modello, potrebbero risultare utili le risorse seguenti:
- Una dimostrazione del modello pipe e filtri che usa lo scenario di elaborazione delle immagini è disponibile in GitHub.
- Modelli di idempotenza, nel blog di Jonathan Oliver.
Risorse correlate
I modelli seguenti possono essere rilevanti anche quando si implementa questo modello:
- Modello Claim-Check. Una pipeline implementata usando una coda potrebbe non contenere l'elemento effettivo inviato tramite i filtri, ma un puntatore ai dati che devono essere elaborati. Nell'esempio viene usato un controllo attestazioni nella coda di Azure Archiviazione per le immagini archiviate in Archiviazione BLOB di Azure.
- Modello di consumer concorrenti. Una pipeline può contenere più istanze di uno o più filtri. Questo approccio è utile per l'esecuzione di istanze parallele di filtri lenti. Consente al sistema di distribuire il carico e migliorare la velocità effettiva. Ogni istanza di un filtro compete per l'input con le altre istanze, ma due istanze di un filtro non devono essere in grado di elaborare gli stessi dati. Questo articolo illustra l'approccio.
- Compute Resource Consolidation pattern (Modello di consolidamento delle risorse di calcolo). Potrebbe essere possibile raggruppare i filtri che devono essere uniti in un singolo processo. Questo articolo fornisce altre informazioni sui vantaggi e sui compromessi di questa strategia.
- Modello di transazioni di compensazione. È possibile implementare un filtro come operazione che può essere invertita o con un'operazione di compensazione che ripristina lo stato a una versione precedente in caso di errore. Questo articolo illustra come implementare questo modello per mantenere o ottenere la coerenza finale.
- Pipe e filtri - Modelli di integrazione aziendale.