Questo articolo descrive come un team di sviluppo ha usato le metriche per trovare colli di bottiglia e migliorare le prestazioni di un sistema distribuito. L'articolo si basa sul test di carico effettivo eseguito per un'applicazione di esempio.
Questo articolo fa parte di una serie. Leggere la prima parte qui.
Scenario: elaborare un flusso di eventi usando Funzioni di Azure.

In questo scenario, una flotta di droni invia dati di posizione in tempo reale a hub IoT di Azure. Un'app Funzioni riceve gli eventi, trasforma i dati in formato GeoJSON e scrive i dati trasformati in Azure Cosmos DB. Azure Cosmos DB offre supporto nativo per i dati geospaziali e le raccolte di Azure Cosmos DB possono essere indicizzate per query spaziali efficienti. Ad esempio, un'applicazione client potrebbe eseguire query per tutti i droni entro 1 km di una determinata posizione o trovare tutti i droni all'interno di una determinata area.
Questi requisiti di elaborazione sono abbastanza semplici che non richiedono un motore di elaborazione di flusso completo. In particolare, l'elaborazione non aggiunge flussi, aggrega i dati o elabora in finestre temporali. In base a questi requisiti, Funzioni di Azure è un'ottima soluzione per l'elaborazione dei messaggi. Azure Cosmos DB può anche ridimensionare per supportare velocità effettiva di scrittura molto elevata.
Monitoraggio della velocità effettiva
Questo scenario presenta una sfida interessante sulle prestazioni. La frequenza dei dati per dispositivo è nota, ma il numero di dispositivi potrebbe variare. Per questo scenario aziendale, i requisiti di latenza non sono particolarmente rigorosi. La posizione segnalata di un drone deve essere accurata solo entro un minuto. Detto questo, l'app per le funzioni deve mantenere il tasso medio di inserimento nel tempo.
hub IoT archivia i messaggi in un flusso di log. I messaggi in ingresso vengono aggiunti alla parte finale del flusso. Un lettore del flusso, in questo caso, l'app per le funzioni controlla la propria frequenza di attraversamento del flusso. Questo disaccoppiamento dei percorsi di lettura e scrittura rende hub IoT molto efficiente, ma significa anche che un lettore lento può cadere dietro. Per rilevare questa condizione, il team di sviluppo ha aggiunto una metrica personalizzata per misurare la ritarda dei messaggi. Questa metrica registra il delta tra quando un messaggio arriva alla hub IoT e quando la funzione riceve il messaggio per l'elaborazione.
var ticksUTCNow = DateTimeOffset.UtcNow;
// Track whether messages are arriving at the function late.
DateTime? firstMsgEnqueuedTicksUtc = messages[0]?.EnqueuedTimeUtc;
if (firstMsgEnqueuedTicksUtc.HasValue)
{
CustomTelemetry.TrackMetric(
context,
"IoTHubMessagesReceivedFreshnessMsec",
(ticksUTCNow - firstMsgEnqueuedTicksUtc.Value).TotalMilliseconds);
}
Il TrackMetric metodo scrive una metrica personalizzata in Application Insights. Per informazioni sull'uso TrackMetric all'interno di una funzione di Azure, vedere Telemetria personalizzata nella funzione C#.
Se la funzione mantiene il volume dei messaggi, questa metrica deve rimanere a uno stato costante basso. Alcune latenza non sono inevitabili, quindi il valore non sarà mai zero. Tuttavia, se la funzione cade dietro, il delta tra il tempo inqueued e il tempo di elaborazione inizieranno a salire.
Test 1: Baseline
Il primo test di carico ha mostrato un problema immediato: l'app per le funzioni ha ricevuto in modo coerente errori HTTP 429 da Azure Cosmos DB, che indica che Azure Cosmos DB limitava le richieste di scrittura.
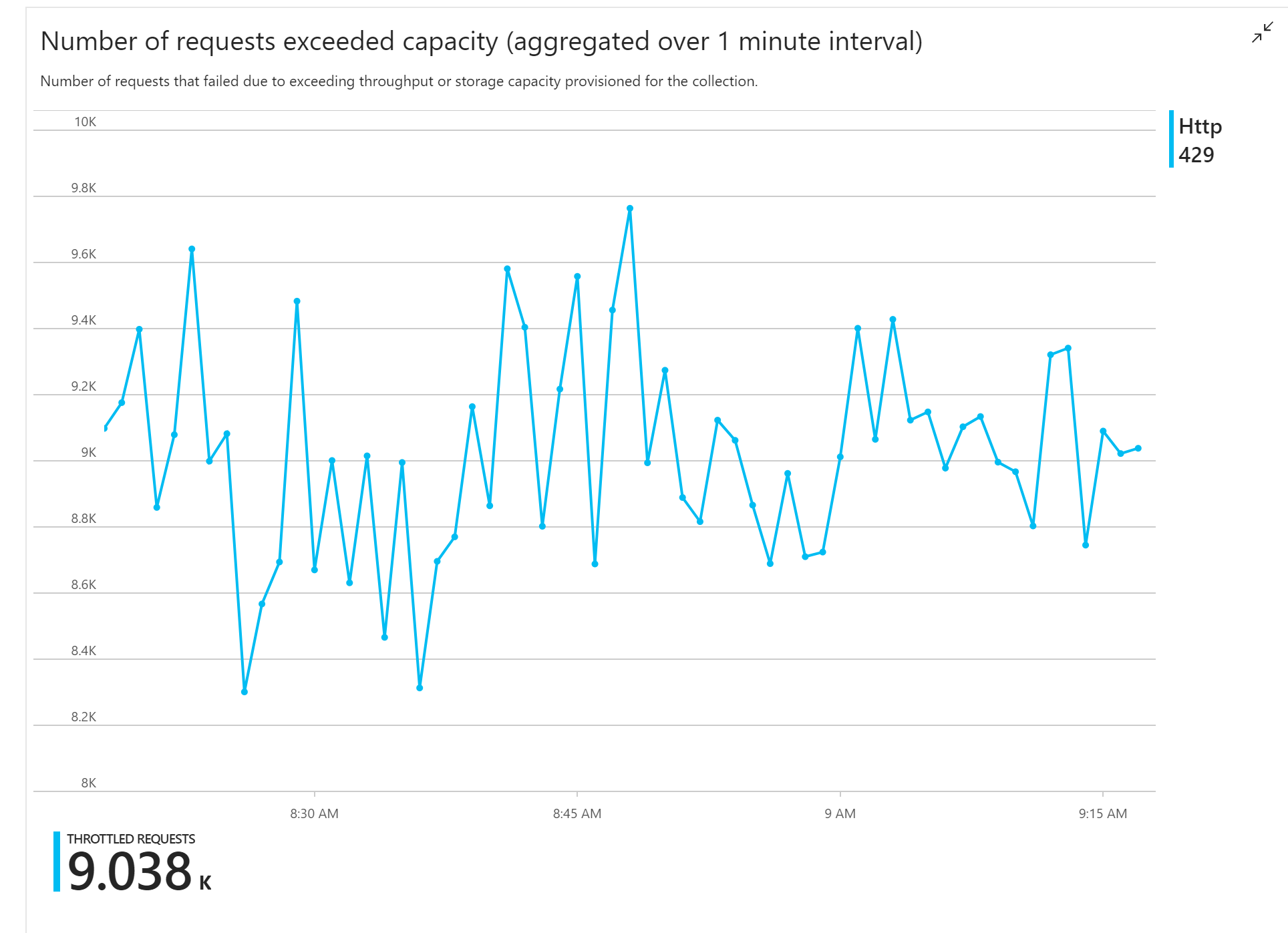
In risposta, il team ha ridimensionato Azure Cosmos DB aumentando il numero di UR allocati per la raccolta, ma gli errori sono continuati. Questo sembra strano, perché il calcolo back-of-envelope ha mostrato che Azure Cosmos DB non dovrebbe avere problemi a mantenere il volume delle richieste di scrittura.
Successivamente, uno degli sviluppatori ha inviato il messaggio di posta elettronica seguente al team:
Ho guardato Azure Cosmos DB per il percorso caldo. C'è una cosa che non capisco. La chiave di partizione è deliveryId, ma non viene inviato deliveryId ad Azure Cosmos DB. Sono mancante qualcosa?
Era l'indizio. Esaminando la mappa termica della partizione, si è verificato che tutti i documenti sono stati atterrati sulla stessa partizione.
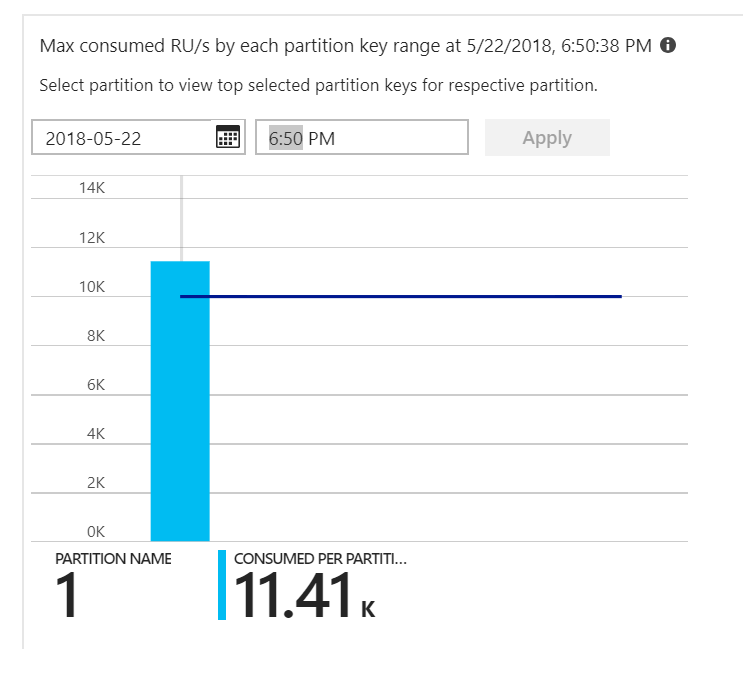
Ciò che si vuole vedere nella mappa termica è una distribuzione uniforme in tutte le partizioni. In questo caso, poiché ogni documento è stato scritto nella stessa partizione, l'aggiunta di unità ur non è stata utile. Il problema è stato rilevato come un bug nel codice. Sebbene l'insieme Azure Cosmos DB avesse una chiave di partizione, la funzione di Azure non includeva effettivamente la chiave di partizione nel documento. Per altre informazioni sulla mappa termica delle partizioni, vedere Determinare la distribuzione della velocità effettiva tra partizioni.
Test 2: Correzione del problema di partizionamento
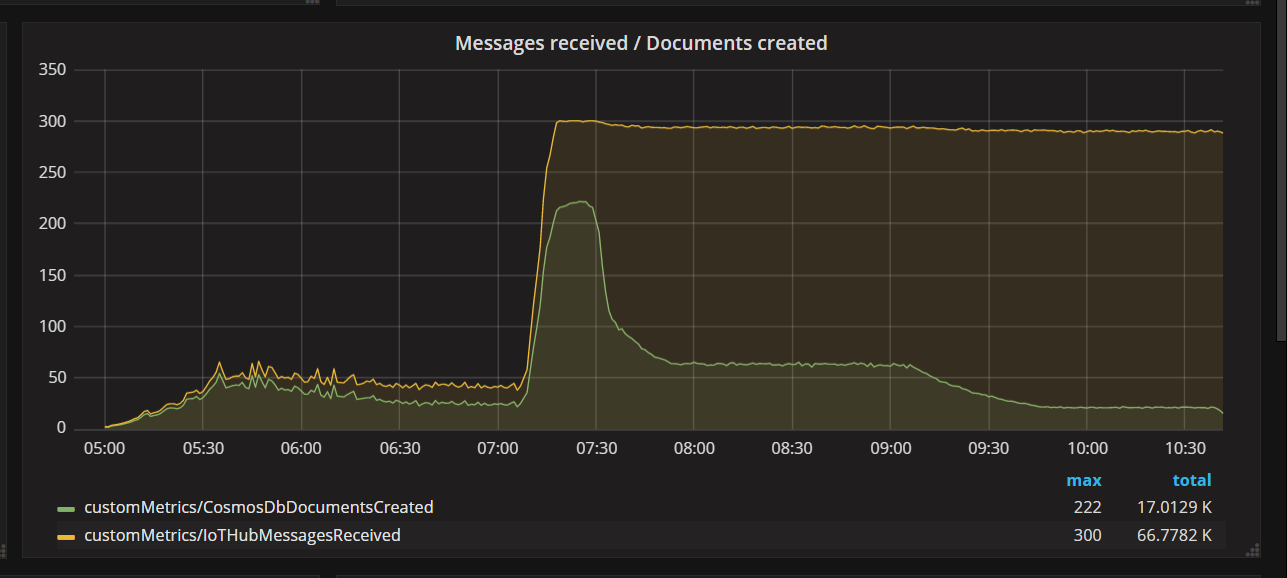
Quando il team ha distribuito una correzione del codice ed è stato eseguito nuovamente il test, Azure Cosmos DB ha arrestato la limitazione. Per un po', tutto sembrava buono. Tuttavia, a un determinato carico, i dati di telemetria hanno mostrato che la funzione scriveva meno documenti che dovrebbe. Il grafico seguente mostra i messaggi ricevuti da hub IoT rispetto ai documenti scritti in Azure Cosmos DB. La riga gialla è il numero di messaggi ricevuti per batch e il verde è il numero di documenti scritti per batch. Questi devono essere proporzionali. Invece, il numero di operazioni di scrittura del database per batch scende significativamente a circa 07:30.
Il grafico successivo mostra la latenza tra quando un messaggio arriva a hub IoT da un dispositivo e quando l'app per le funzioni elabora tale messaggio. Si può notare che allo stesso tempo, la ritarda picchi drasticamente, livelli di off e il calo.
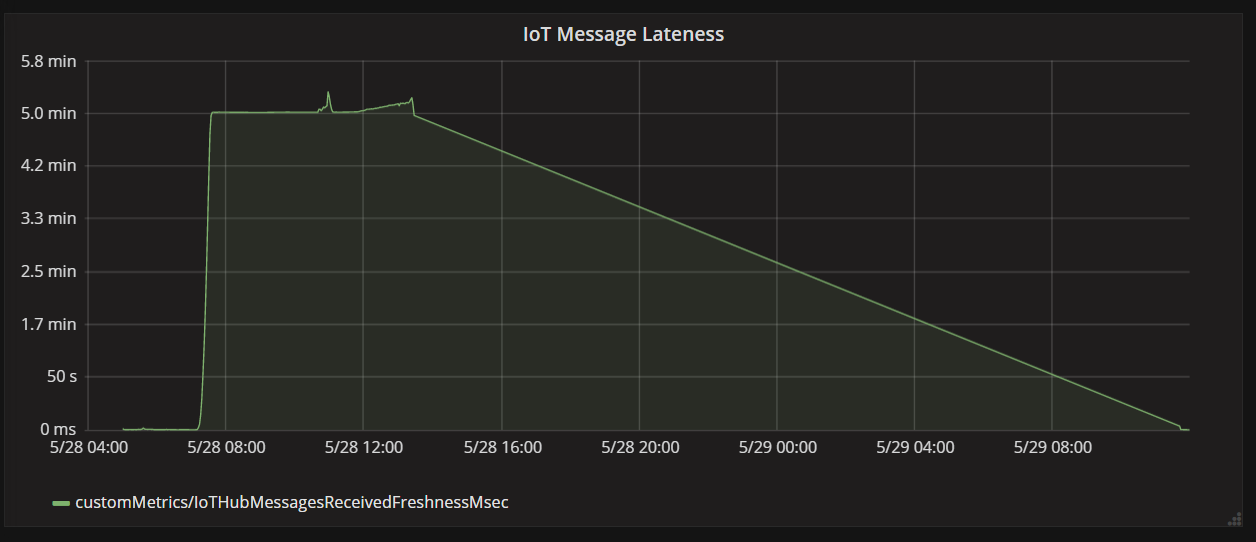
Il motivo per cui il valore supera i 5 minuti e quindi scende a zero è perché l'app per le funzioni elimina i messaggi che sono più di 5 minuti in ritardo:
foreach (var message in messages)
{
// Drop stale messages,
if (message.EnqueuedTimeUtc < cutoffTime)
{
log.Info($"Dropping late message batch. Enqueued time = {message.EnqueuedTimeUtc}, Cutoff = {cutoffTime}");
droppedMessages++;
continue;
}
}
È possibile visualizzare questo problema nel grafico quando la metrica di ritardo torna a zero. Nel frattempo, i dati sono stati persi, perché la funzione ha eliminato i messaggi.
Cosa succedeva? Per questo particolare test di carico, l'insieme Azure Cosmos DB aveva UR da risparmiare, quindi il collo di bottiglia non era nel database. Invece, il problema si è verificato nel ciclo di elaborazione dei messaggi. Semplicemente, la funzione non scriveva i documenti abbastanza rapidamente per mantenere il volume in ingresso dei messaggi. Nel tempo, è caduto ulteriormente e più indietro.
Test 3: Scritture parallele
Se il tempo per elaborare un messaggio è il collo di bottiglia, una soluzione consiste nel elaborare più messaggi in parallelo. In questo scenario:
- Aumentare il numero di hub IoT partizioni. Ogni hub IoT partizione viene assegnata un'istanza di funzione alla volta, quindi si prevede che la velocità effettiva venga ridimensionata in modo lineare con il numero di partizioni.
- Parallelizzare la scrittura del documento all'interno della funzione.
Per esplorare la seconda opzione, il team ha modificato la funzione per supportare le scritture parallele. La versione originale della funzione ha usato l'associazione di output di Azure Cosmos DB. La versione ottimizzata chiama direttamente il client Azure Cosmos DB ed esegue le scritture in parallelo usando Task.WhenAll:
private async Task<(long documentsUpserted,
long droppedMessages,
long cosmosDbTotalMilliseconds)>
ProcessMessagesFromEventHub(
int taskCount,
int numberOfDocumentsToUpsertPerTask,
EventData[] messages,
TraceWriter log)
{
DateTimeOffset cutoffTime = DateTimeOffset.UtcNow.AddMinutes(-5);
var tasks = new List<Task>();
for (var i = 0; i < taskCount; i++)
{
var docsToUpsert = messages
.Skip(i * numberOfDocumentsToUpsertPerTask)
.Take(numberOfDocumentsToUpsertPerTask);
// client will attempt to create connections to the data
// nodes on Azure Cosmos DB clusters on a range of port numbers
tasks.Add(UpsertDocuments(i, docsToUpsert, cutoffTime, log));
}
await Task.WhenAll(tasks);
return (this.UpsertedDocuments,
this.DroppedMessages,
this.CosmosDbTotalMilliseconds);
}
Si noti che le condizioni di gara sono possibili con l'approccio. Si supponga che due messaggi dallo stesso drone vengano ricevuti nello stesso batch di messaggi. Scrivendoli in parallelo, il messaggio precedente potrebbe sovrascrivere il messaggio successivo. Per questo particolare scenario, l'applicazione può tollerare la perdita di un messaggio occasionale. I droni inviano nuovi dati di posizione ogni 5 secondi, quindi i dati in Azure Cosmos DB vengono aggiornati continuamente. In altri scenari, tuttavia, può essere importante elaborare i messaggi strettamente in ordine.
Dopo aver distribuito questa modifica del codice, l'applicazione è stata in grado di inserire più di 2500 richieste/sec usando un hub IoT con 32 partizioni.
Considerazioni sul lato client
L'esperienza client complessiva potrebbe essere ridotta dalla parallelizzazione aggressiva sul lato server. È consigliabile usare la libreria di executor bulk di Azure Cosmos DB (non illustrata in questa implementazione) che riduce significativamente le risorse di calcolo lato client necessarie per saturazione della velocità effettiva allocata a un contenitore azure Cosmos DB. Un'applicazione con thread singolo che scrive i dati usando l'API di importazione bulk raggiunge quasi dieci volte una velocità effettiva di scrittura maggiore rispetto a un'applicazione a più thread che scrive dati in parallelo durante la saturazione della CPU del computer client.
Riepilogo
Per questo scenario sono stati identificati i colli di bottiglia seguenti:
- Partizione di scrittura frequente, a causa di un valore di chiave di partizione mancante nei documenti scritti.
- Scrittura di documenti in serie per hub IoT partizione.
Per diagnosticare questi problemi, il team di sviluppo si basa sulle metriche seguenti:
- Richieste limitate in Azure Cosmos DB.
- Mappa termica delle partizioni: numero massimo di UR usate per partizione.
- Messaggi ricevuti rispetto ai documenti creati.
- Ritardo dei messaggi.
Passaggi successivi
Esaminare gli antipattern delle prestazioni