Risolvere i problemi di scalabilità automatica di Monitoraggio di Azure
La scalabilità automatica di Monitoraggio di Azure consente di avere la giusta quantità di risorse in esecuzione per gestire il carico nell'applicazione. Consente di aggiungere risorse per gestire gli aumenti del carico e anche risparmiare denaro rimuovendo le risorse inattive. È possibile ridimensionare in base a una pianificazione, a una data fissa o a una metrica di risorsa scelta. Per altre informazioni, vedere la panoramica del ridimensionamento automatico.
Il servizio di scalabilità automatica fornisce metriche e log per comprendere quali azioni di scalabilità si sono verificate e la valutazione delle condizioni che hanno portato a tali azioni. È possibile trovare risposte a domande come:
- Perché il servizio è a scalabilità orizzontale o scalabilità orizzontale?
- Perché il servizio non è stato ridimensionato?
- Perché un'azione di scalabilità automatica ha avuto esito negativo?
- Perché un'azione di scalabilità automatica richiede tempo per la scalabilità?
Flex set di scalabilità di macchine virtuali
Le azioni di ridimensionamento della scalabilità automatica vengono ritardate fino a diverse ore dopo l'applicazione di un'azione di ridimensionamento manuale a una risorsa Flex Microsoft.Compute/virtualMachineScaleSets (VMSS) per un set specifico di operazioni di macchina virtuale.
Ad esempio, l'eliminazione dell'interfaccia della riga di comando della macchina virtuale di Azure o l'eliminazione dell'API REST della macchina virtuale di Azure in cui viene eseguita l'operazione in una singola macchina virtuale.
In questi casi, il servizio di scalabilità automatica non è a conoscenza delle singole operazioni della macchina virtuale.
Per evitare questo scenario, usare la stessa operazione, ma a livello di set di scalabilità di macchine virtuali. Ad esempio, l'istanza di eliminazione dell'interfaccia della riga di comando del set di scalabilità di macchine virtuali di Azure o l'istanza di eliminazione dell'API rest vmSS di Azure. La scalabilità automatica rileva la modifica del numero di istanze nel set di scalabilità di macchine virtuali ed esegue le azioni di ridimensionamento appropriate.
Metriche della scalabilità automatica
La scalabilità automatica offre quattro metriche per comprenderne l'operazione:
- Valore metrica osservato: valore della metrica su cui si è scelto di eseguire l'azione di scalabilità, come illustrato o calcolato dal motore di scalabilità automatica. Poiché una singola impostazione di scalabilità automatica può avere più regole e quindi più origini delle metriche, è possibile filtrare usando "origine metrica" come dimensione.
- Soglia metrica: soglia impostata per eseguire l'azione di scalabilità. Poiché una singola impostazione di scalabilità automatica può avere più regole e quindi più origini metriche, è possibile filtrare usando "regola metrica" come dimensione.
- Capacità osservata: numero attivo di istanze della risorsa di destinazione, come illustrato dal motore di scalabilità automatica.
- Azioni di scalabilità avviate: numero di azioni di scalabilità orizzontale e scalabilità orizzontale avviate dal motore di scalabilità automatica. È possibile filtrare in base alle azioni di aumento del numero di istanze rispetto alle azioni di scalabilità orizzontale.
È possibile usare Esplora metriche per tracciare tutte le metriche precedenti in un'unica posizione. Il grafico dovrebbe visualizzare:
- Metrica effettiva.
- Metrica come illustrato/calcolato dal motore di scalabilità automatica.
- Soglia per un'azione di scalabilità.
- Modifica della capacità.
Esempio 1: Analizzare una regola di scalabilità automatica
Un'impostazione di scalabilità automatica per un set di scalabilità di macchine virtuali:
- Aumenta il numero di istanze quando la percentuale media di CPU di un set è maggiore del 70% per 10 minuti.
- Aumenta quando la percentuale di CPU del set è inferiore al 5% per più di 10 minuti.
Esaminiamo le metriche del servizio di scalabilità automatica.
Il grafico seguente mostra una metrica Percentuale CPU per un set di scalabilità di macchine virtuali.

Il grafico successivo mostra la metrica Valore metrica osservato per un'impostazione di scalabilità automatica.

Il grafico finale mostra le metriche Soglia metrica e Capacità osservata. La metrica Soglia metrica nella parte superiore per la regola di scalabilità orizzontale è 70. La metrica Capacità osservata nella parte inferiore mostra il numero di istanze attive, attualmente 3.

Nota
È possibile filtrare La soglia delle metriche in base alla regola di attivazione della regola di metrica scale-out (aumento) per visualizzare la soglia di aumento del numero di istanze e per la regola di riduzione (riduzione).
Esempio 2: Scalabilità automatica avanzata per un set di scalabilità di macchine virtuali
Un'impostazione di scalabilità automatica consente a una risorsa del set di scalabilità di macchine virtuali di aumentare il numero di istanze in base alla metrica Flussi in uscita. L'opzione Divide metric by instance count (Divide metric by instance count ) per la soglia della metrica è selezionata.
La regola di azione di scalabilità è se il valore del flusso in uscita per ogni istanza è maggiore di 10, il servizio di scalabilità automatica deve aumentare il numero di istanze di 1 istanza.
In questo caso, il valore della metrica osservata dal motore di scalabilità automatica viene calcolato come valore effettivo della metrica diviso per il numero di istanze. Se il valore della metrica osservato è minore della soglia, non viene avviata alcuna azione di aumento del numero di istanze.
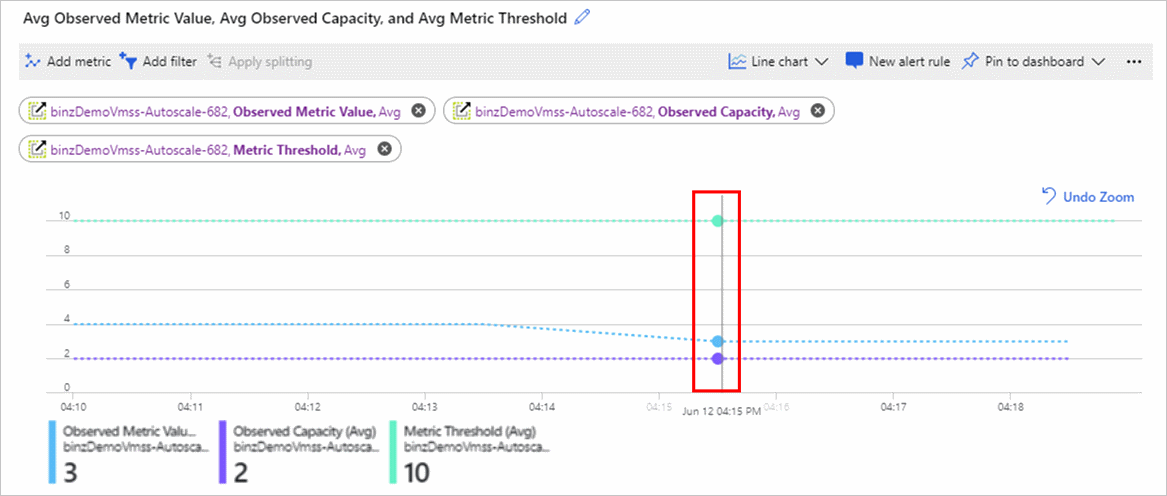
Gli screenshot seguenti mostrano due grafici delle metriche.
Il grafico Media flussi in uscita mostra il valore della metrica Flussi in uscita. Il valore effettivo è 6.

Il grafico seguente mostra alcuni valori:
- La metrica Valore metrico osservato al centro è 3 perché sono presenti 2 istanze attive e 6 diviso per 2 è 3.
- La metrica Capacità osservata nella parte inferiore mostra il numero di istanze visualizzato da un motore di scalabilità automatica.
- La metrica Soglia metrica nella parte superiore è impostata su 10.

Se sono presenti più regole di azione di ridimensionamento, è possibile usare la suddivisione o l'opzione aggiungi filtro nel grafico esplora metriche per esaminare una metrica in base a un'origine o a una regola specifica. Per altre informazioni sulla suddivisione di un grafico delle metriche, vedere Funzionalità avanzate dei grafici delle metriche - suddivisione.
Esempio 3: Informazioni sugli eventi di scalabilità automatica
Nella schermata delle impostazioni di scalabilità automatica passare alla scheda Cronologia di esecuzione per visualizzare le azioni di scalabilità più recenti. La scheda mostra anche la modifica in Capacità osservata nel tempo. Per altre informazioni su tutte le azioni di scalabilità automatica, incluse operazioni quali le impostazioni di scalabilità automatica di aggiornamento/eliminazione, visualizzare il log attività e filtrare in base alle operazioni di scalabilità automatica.

Ridimensionare automaticamente i log delle risorse
Il servizio di scalabilità automatica fornisce i log delle risorse. Esistono due categorie di log:
- Valutazioni della scalabilità automatica: il motore di scalabilità automatica registra le voci di log per ogni singola valutazione della condizione ogni volta che esegue un controllo. La voce include informazioni dettagliate sui valori osservati delle metriche, sulle regole valutate e se la valutazione ha generato o meno un'azione di scalabilità.
- Azioni di scalabilità automatica: il motore registra gli eventi di azione di scalabilità avviati dal servizio di scalabilità automatica e i risultati di tali azioni di scalabilità (esito positivo, negativo e quantità di scalabilità rilevata dal servizio di scalabilità automatica).
Come per qualsiasi servizio supportato da Monitoraggio di Azure, è possibile usare le impostazioni di diagnostica per instradare questi log a:
- L'area di lavoro Log Analytics per l'analisi dettagliata.
- Hub eventi di Azure e quindi a strumenti non Di Azure.
- L'account Archiviazione di Azure per l'archivio.

Lo screenshot precedente mostra il riquadro impostazioni di diagnostica di scalabilità automatica portale di Azure. È possibile selezionare la scheda Log di diagnostica/risorse e abilitare la raccolta e il routing dei log. È anche possibile eseguire la stessa azione usando l'API REST, l'interfaccia della riga di comando di Azure, PowerShell e i modelli di Azure Resource Manager per le impostazioni di diagnostica scegliendo il tipo di risorsa come Microsoft.Insights/Autoscale Impostazioni.
Risolvere i problemi usando i log di scalabilità automatica
Per una migliore esperienza di risoluzione dei problemi, è consigliabile instradare i log ai log di Monitoraggio di Azure (Log Analytics) tramite un'area di lavoro quando si crea l'impostazione di scalabilità automatica. Questo processo viene visualizzato nello screenshot della sezione precedente. È possibile convalidare le valutazioni e ridimensionare meglio le azioni usando Log Analytics.
Dopo aver configurato i log di scalabilità automatica da inviare all'area di lavoro Log Analytics, è possibile eseguire le query seguenti per controllare i log.
Per iniziare, provare questa query per visualizzare i log di valutazione della scalabilità automatica più recenti:
AutoscaleEvaluationsLog
| limit 50
In alternativa, provare la query seguente per visualizzare i log delle azioni di scalabilità più recenti:
AutoscaleScaleActionsLog
| limit 50
Usare le sezioni seguenti per rispondere a queste domande.
Si è verificata un'azione di scalabilità non prevista
Prima di tutto, eseguire la query per un'azione di scalabilità per trovare l'azione di scalabilità a cui si è interessati. Se si tratta dell'azione di scalabilità più recente, usare la query seguente:
AutoscaleScaleActionsLog
| take 1
Selezionare il CorrelationId campo nel log delle azioni di scalabilità. Usare CorrelationId per trovare il log di valutazione corretto. L'esecuzione della query seguente visualizza tutte le regole e le condizioni valutate e che hanno portato a tale azione di scalabilità.
AutoscaleEvaluationsLog
| where CorrelationId = "<correliationId>"
Quale profilo ha causato un'azione di scalabilità?
Si è verificata un'azione ridimensionata, ma sono presenti regole e profili sovrapposti ed è necessario tenere traccia di quale ha causato l'azione.
Trovare l'oggetto CorrelationId dell'azione di scalabilità, come illustrato nell'esempio 1. Eseguire quindi la query nei log di valutazione per altre informazioni sul profilo.
AutoscaleEvaluationsLog
| where CorrelationId = "<correliationId_Guid>"
| where ProfileSelected == true
| project ProfileEvaluationTime, Profile, ProfileSelected, EvaluationResult
È anche possibile comprendere meglio l'intera valutazione del profilo usando la query seguente:
AutoscaleEvaluationsLog
| where TimeGenerated > ago(2h)
| where OperationName contains == "profileEvaluation"
| project OperationName, Profile, ProfileEvaluationTime, ProfileSelected, EvaluationResult
Non è stata eseguita un'azione di scalabilità
È prevista un'azione di scalabilità e non è stata eseguita. Potrebbero non essere presenti eventi o log delle azioni di scalabilità.
Esaminare le metriche di scalabilità automatica se si usa una regola di scalabilità basata su metriche. È possibile che il valore della metrica osservata o la capacità osservata non siano gli elementi previsti, quindi la regola di scalabilità non è stata attivata. Verranno comunque visualizzate valutazioni, ma non una regola di aumento del numero di istanze. È anche possibile che il tempo di raffreddamento impedisca l'esecuzione di un'azione di scalabilità.
Esaminare i log di valutazione della scalabilità automatica durante il periodo di tempo in cui si prevede che si verifichi l'azione di scalabilità. Esaminare tutte le valutazioni effettuate e il motivo per cui ha deciso di non attivare un'azione di scalabilità.
AutoscaleEvaluationsLog
| where TimeGenerated > ago(2h)
| where OperationName == "MetricEvaluation" or OperationName == "ScaleRuleEvaluation"
| project OperationName, MetricData, ObservedValue, Threshold, EstimateScaleResult
Azione di scalabilità non riuscita
Potrebbe verificarsi un caso in cui il servizio di scalabilità automatica ha eseguito l'azione di scalabilità, ma il sistema ha deciso di non ridimensionare o non è riuscito a completare l'azione di scalabilità. Usare questa query per trovare le azioni di scalabilità non riuscite:
AutoscaleScaleActionsLog
| where ResultType == "Failed"
| project ResultDescription
Creare regole di avviso per ricevere una notifica di azioni o errori di scalabilità automatica. È anche possibile creare regole di avviso per ricevere notifiche sugli eventi di scalabilità automatica.
Schema dei log delle risorse di scalabilità automatica
Per altre informazioni, vedere Log delle risorse di scalabilità automatica.
Passaggi successivi
Leggere le informazioni sulle procedure consigliate per la scalabilità automatica.