Regole di avviso consigliate per i cluster Kubernetes
Gli avvisi in Monitoraggio di Azure identificano in modo proattivo i problemi relativi all'integrità e alle prestazioni delle risorse di Azure. Questo articolo descrive come abilitare e modificare un set di regole di avviso delle metriche consigliate predefinite per i cluster Kubernetes.
Tipi di regole di avviso
Esistono due tipi di regole di avviso delle metriche usate con i cluster Kubernetes.
| Tipo di regola di avviso | Descrizione |
|---|---|
| Regole di avviso per le metriche di Prometheus | Usare i dati delle metriche raccolti dal cluster Kubernetes in un servizio gestito di Monitoraggio di Azure per Prometheus. Queste regole richiedono l'abilitazione di Prometheus nel cluster e vengono archiviate in un gruppo di regole Prometheus. |
| Regole di avviso per le metriche della piattaforma | Usare le metriche raccolte automaticamente dal cluster del servizio Azure Kubernetes e vengono archiviate come regole di avviso di Monitoraggio di Azure. |
Abilitare le regole di avviso consigliate
Usare uno dei metodi seguenti per abilitare le regole di avviso consigliate per il cluster. È possibile abilitare le regole di avviso per le metriche di Prometheus e della piattaforma per lo stesso cluster.
Usando il portale di Azure, il gruppo di regole Prometheus verrà creato nella stessa area del cluster.
Dal menu Avvisi per il cluster selezionare Configura raccomandazioni.

Le regole di avviso di Prometheus e della piattaforma disponibili vengono visualizzate con le regole prometheus organizzate per pod, cluster e livello di nodo. Attivare o disattivare un gruppo di regole Prometheus per abilitare tale set di regole. Espandere il gruppo per visualizzare le singole regole. È possibile lasciare le impostazioni predefinite o disabilitare le singole regole e modificarne il nome e la gravità.
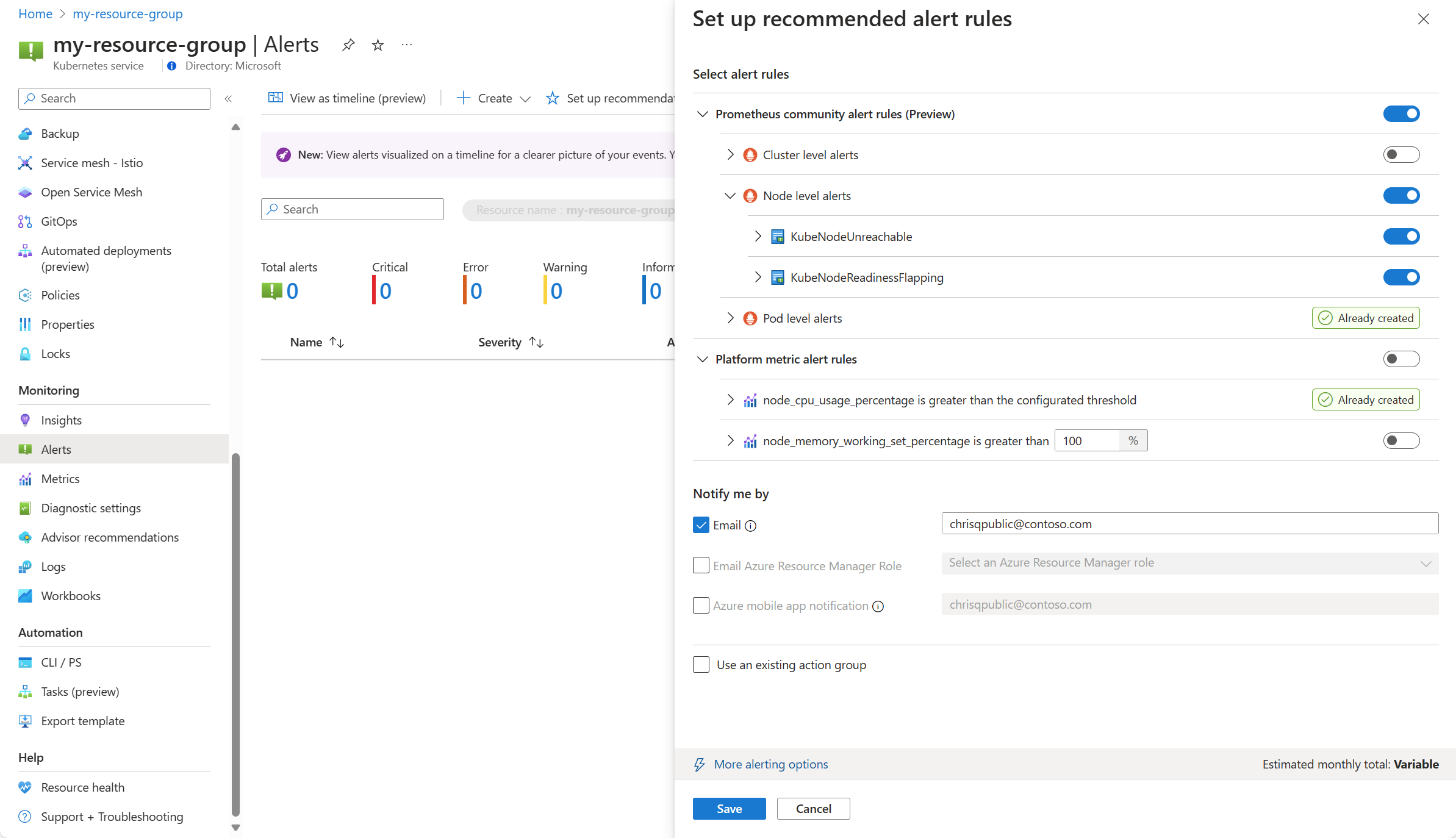
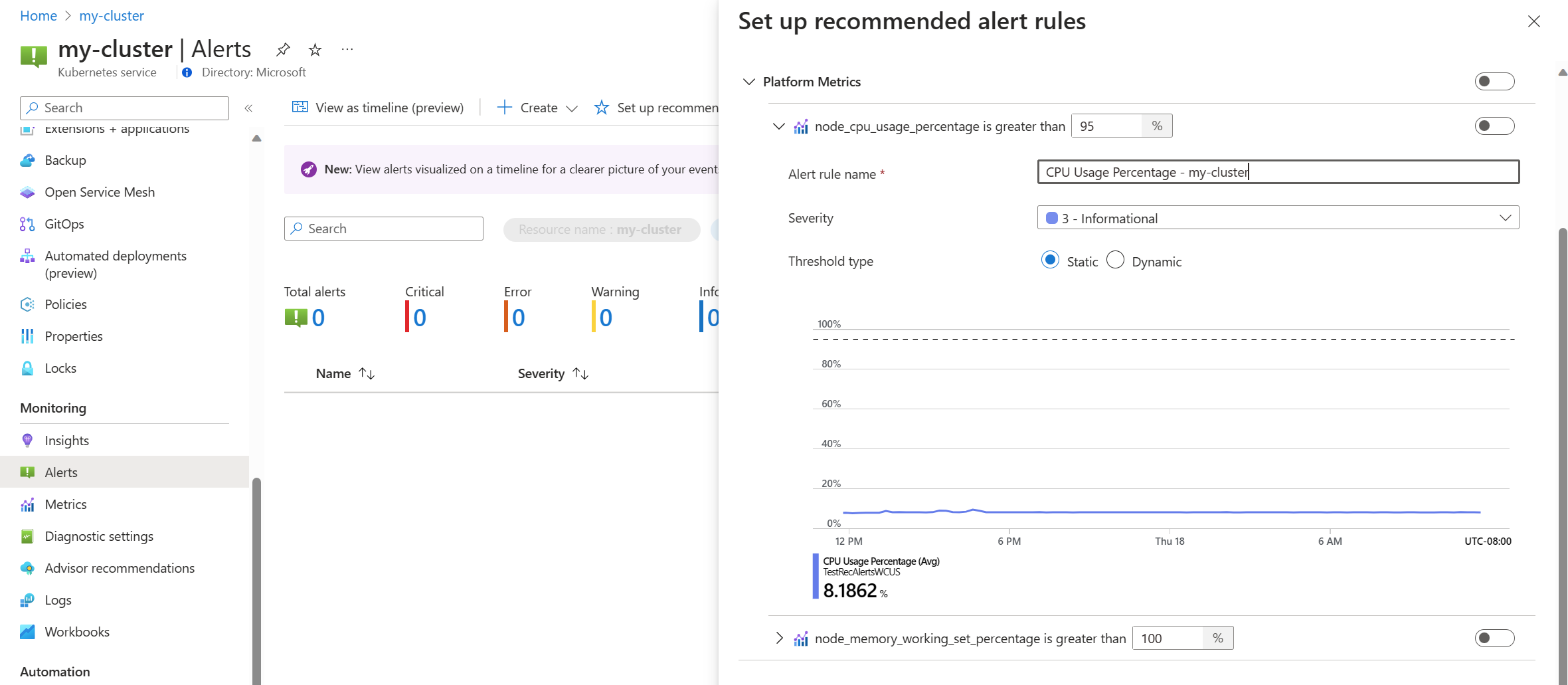
Attivare o disattivare una regola della metrica della piattaforma per abilitare tale regola. È possibile espandere la regola per modificarne i dettagli, ad esempio il nome, la gravità e la soglia.
Selezionare uno o più metodi di notifica per creare un nuovo gruppo di azioni oppure selezionare un gruppo di azioni esistente con i dettagli della notifica per questo set di regole di avviso.
Fare clic su Salva per salvare il gruppo di regole.



Modificare le regole di avviso consigliate
Dopo aver creato il gruppo di regole, non è possibile usare la stessa pagina nel portale per modificare le regole. Per le metriche di Prometheus, è necessario modificare il gruppo di regole per modificare le regole in esso contenute, inclusa l'abilitazione di tutte le regole non già abilitate. Per le metriche della piattaforma, è possibile modificare ogni regola di avviso.
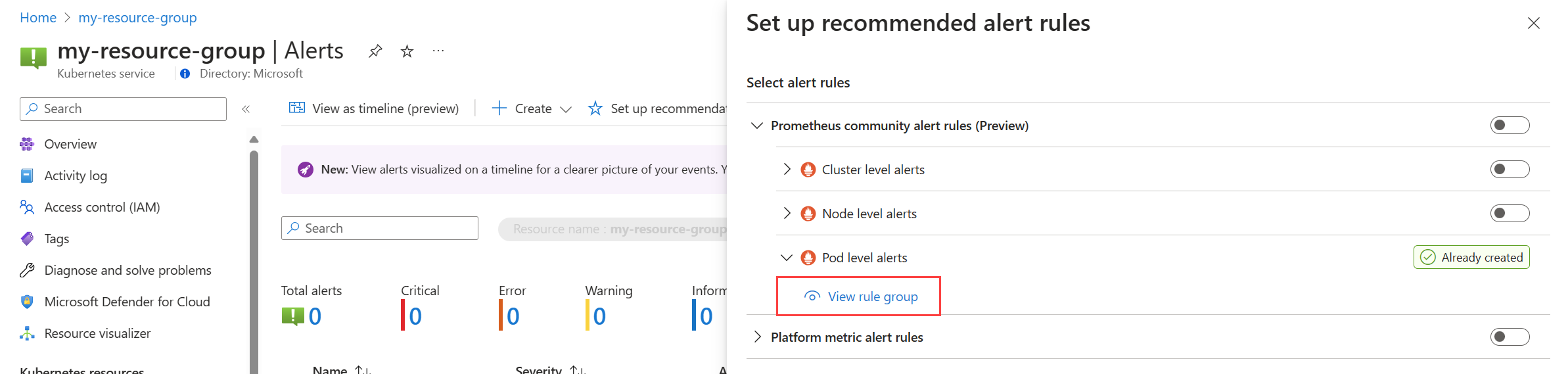
Dal menu Avvisi per il cluster selezionare Configura raccomandazioni. Tutte le regole o i gruppi di regole già creati verranno etichettati come Già creati.
Espandere la regola o il gruppo di regole. Fare clic su Visualizza gruppo di regole per Prometheus e Visualizza regola di avviso per le metriche della piattaforma.
Per i gruppi di regole Prometheus:
selezionare Regole per visualizzare le regole di avviso nel gruppo.
Fare clic sull'icona Modifica accanto a una regola che si desidera modificare. Usare le indicazioni riportate in Creare una regola di avviso per modificare la regola.
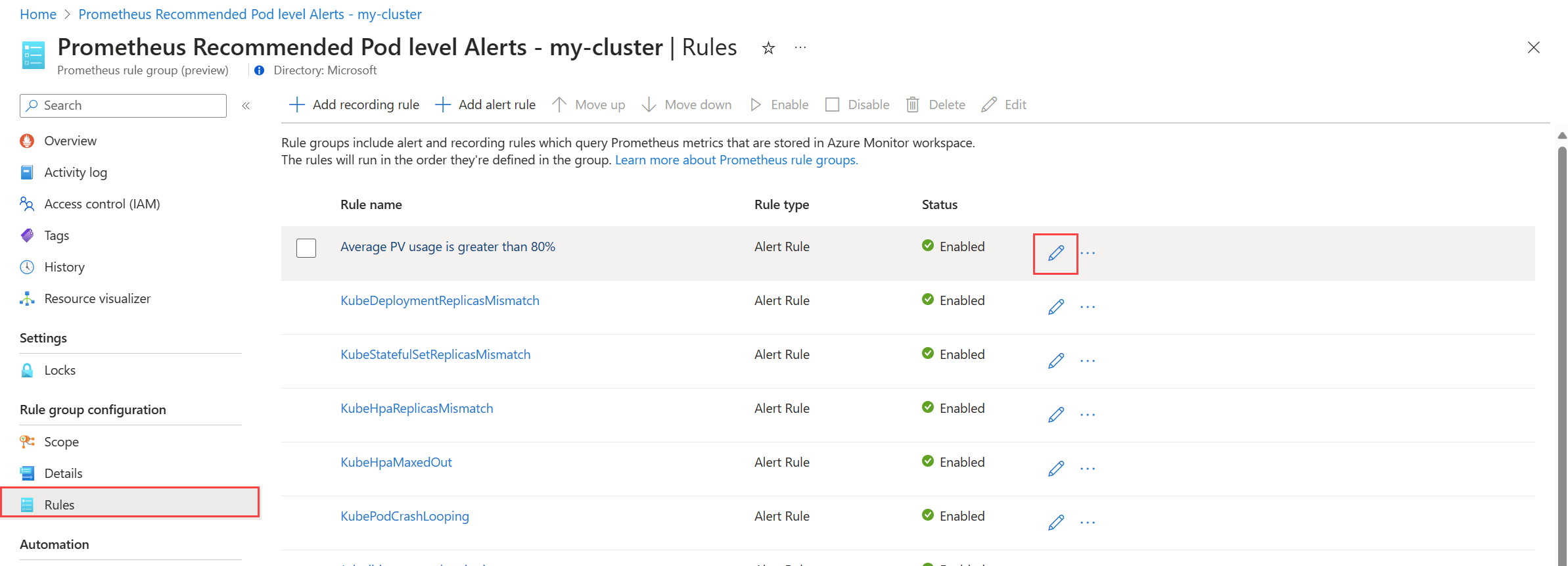
Al termine della modifica delle regole nel gruppo, fare clic su Salva per salvare il gruppo di regole.
Per le metriche della piattaforma:
Fare clic su Modifica per aprire i dettagli per la regola di avviso. Usare le indicazioni riportate in Creare una regola di avviso per modificare la regola.



Disabilitare il gruppo di regole di avviso
Disabilitare il gruppo di regole per interrompere la ricezione di avvisi dalle regole.
Visualizzare il gruppo di regole di avviso Prometheus o la regola di avviso della metrica della piattaforma come descritto in Modificare le regole di avviso consigliate.
Scegliere Disabilita dal menu Panoramica.

Dettagli delle regole di avviso consigliate
Le tabelle seguenti elencano i dettagli di ogni regola di avviso consigliata. Il codice sorgente per ognuno di essi è disponibile in GitHub insieme alle guide alla risoluzione dei problemi della community di Prometheus.
Regole di avviso della community di Prometheus
Avvisi a livello di cluster
| Nome avviso | Descrizione | Soglia predefinita | Intervallo di tempo (minuti) |
|---|---|---|---|
| KubeCPUQuotaOvercommit | La quota di risorse CPU allocata agli spazi dei nomi supera le risorse DELLA CPU disponibili nei nodi del cluster di oltre il 50% per gli ultimi 5 minuti. | >1.5 | 5 |
| KubeMemoryQuotaOvercommit | La quota di risorse di memoria allocata agli spazi dei nomi supera le risorse di memoria disponibili nei nodi del cluster di oltre il 50% per gli ultimi 5 minuti. | >1.5 | 5 |
| Il numero di contenitori terminati OOM è maggiore di 0 | Uno o più contenitori all'interno dei pod sono stati eliminati a causa di eventi di memoria insufficiente (OOM) per gli ultimi 5 minuti. | >0 | 5 |
| KubeClientErrors | La frequenza degli errori client (codici di stato HTTP a partire da 5xx) nelle richieste API Kubernetes supera il 1% della frequenza totale delle richieste API per gli ultimi 15 minuti. | >0.01 | 15 |
| KubePersistentVolumeFillingUp | Il volume persistente sta riempiendo ed è previsto che si esaurisca lo spazio disponibile valutato in base al rapporto di spazio disponibile, allo spazio usato e alla tendenza lineare lineare dello spazio disponibile nelle ultime 6 ore. Queste condizioni vengono valutate negli ultimi 60 minuti. | N/D | 60 |
| KubePersistentVolumeInodesFillingUp | Per gli ultimi 15 minuti sono disponibili meno del 3% degli inodi all'interno di un volume permanente. | <0.03 | 15 |
| KubePersistentVolumeErrors | Uno o più volumi persistenti si trovano in una fase non riuscita o in sospeso per gli ultimi 5 minuti. | >0 | 5 |
| KubeContainerWaiting | Uno o più contenitori all'interno dei pod Kubernetes hanno uno stato di attesa per gli ultimi 60 minuti. | >0 | 60 |
| KubeDaemonSetNotScheduled | Uno o più pod non sono pianificati in alcun nodo per gli ultimi 15 minuti. | >0 | 15 |
| KubeDaemonSetMisScheduled | Uno o più pod non vengono pianificati all'interno del cluster per gli ultimi 15 minuti. | >0 | 15 |
| KubeQuotaAlmostFull | L'utilizzo delle quote di risorse Kubernetes è compreso tra il 90% e il 100% dei limiti rigidi per gli ultimi 15 minuti. | >0,9 <1 | 15 |
Avvisi a livello di nodo
| Nome avviso | Descrizione | Soglia predefinita | Intervallo di tempo (minuti) |
|---|---|---|---|
| KubeNodeUnreachable | Un nodo non è raggiungibile per gli ultimi 15 minuti. | 1 | 15 |
| KubeNodeReadinessFlapping | Lo stato di conformità di un nodo è cambiato più di 2 volte per gli ultimi 15 minuti. | 2 | 15 |
Avvisi a livello di pod
| Nome avviso | Descrizione | Soglia predefinita | Intervallo di tempo (minuti) |
|---|---|---|---|
| L'utilizzo medio del PV è maggiore dell'80% | L'utilizzo medio dei volumi persistenti (PVS) nel pod supera l'80% per gli ultimi 15 minuti. | >0.8 | 15 |
| KubeDeploymentReplicasMismatch | Esiste una mancata corrispondenza tra il numero desiderato di repliche e il numero di repliche disponibili per gli ultimi 10 minuti. | N/D | 10 |
| KubeStatefulSetReplicasMismatch | Il numero di repliche pronte nell'oggetto StatefulSet non corrisponde al numero totale di repliche nell'oggetto StatefulSet per gli ultimi 15 minuti. | N/D | 15 |
| KubeHpaReplicasMismatch | La scalabilità automatica orizzontale dei pod nel cluster non corrisponde al numero desiderato di repliche per gli ultimi 15 minuti. | N/D | 15 |
| KubeHpaMaxedOut | L'utilità di scalabilità automatica orizzontale dei pod nel cluster è stata eseguita al massimo per gli ultimi 15 minuti. | N/D | 15 |
| KubePodCrashLooping | Uno o più pod si trovano in una condizione CrashLoopBackOff, in cui il pod si arresta continuamente in modo anomalo dopo l'avvio e non riesce a eseguire correttamente il ripristino per gli ultimi 15 minuti. | >=1 | 15 |
| KubeJobStale | Almeno un'istanza del processo non è stata completata correttamente per le ultime 6 ore. | >0 | 360 |
| Contenitore pod riavviato nell'ultima ora | Uno o più contenitori all'interno dei pod nel cluster Kubernetes sono stati riavviati almeno una volta nell'ultima ora. | >0 | 15 |
| Lo stato pronto dei pod è inferiore all'80% | La percentuale di pod in uno stato pronto scende al di sotto dell'80% per qualsiasi distribuzione o daemonset nel cluster Kubernetes per gli ultimi 5 minuti. | <0.8 | 5 |
| Il numero di pod in stato di errore è maggiore di 0. | Uno o più pod si trovano in uno stato di errore per gli ultimi 5 minuti. | >0 | 5 |
| KubePodNotReadyByController | Uno o più pod non sono in uno stato pronto (ad esempio, nella fase "In sospeso" o "Sconosciuto") per gli ultimi 15 minuti. | >0 | 15 |
| KubeStatefulSetGenerationMismatch | La generazione osservata di un oggetto Kubernetes StatefulSet non corrisponde alla generazione dei metadati per gli ultimi 15 minuti. | N/D | 15 |
| KubeJobFailed | Uno o più processi Kubernetes hanno avuto esito negativo negli ultimi 15 minuti. | >0 | 15 |
| L'utilizzo medio della CPU per contenitore è maggiore del 95% | L'utilizzo medio della CPU per contenitore supera il 95% per gli ultimi 5 minuti. | >0.95 | 5 |
| L'utilizzo medio della memoria per ogni contenitore è maggiore del 95% | L'utilizzo medio della memoria per contenitore supera il 95% per gli ultimi 5 minuti. | >0.95 | 10 |
| KubeletPodStartUpLatencyHigh | Il 99° percentile della latenza di avvio del pod supera i 60 secondi per gli ultimi 10 minuti. | >60 | 10 |
Regole di avviso per le metriche della piattaforma
| Nome avviso | Descrizione | Soglia predefinita | Intervallo di tempo (minuti) |
|---|---|---|---|
| La percentuale di CPU del nodo è maggiore del 95% | La percentuale di CPU del nodo è maggiore del 95% per gli ultimi 5 minuti. | 95 | 5 |
| Percentuale del working set di memoria del nodo maggiore del 100% | La percentuale del working set di memoria del nodo è maggiore del 95% per gli ultimi 5 minuti. | 100 | 5 |
Avvisi delle metriche delle informazioni dettagliate sui contenitori legacy (anteprima)
Le regole delle metriche in Informazioni dettagliate sui contenitori verranno ritirati il 31 maggio 2024 (annunciato in precedenza il 14 marzo 2026). Queste regole non sono state disponibili per la creazione tramite il portale dal 15 agosto 2023. Queste regole erano in anteprima pubblica, ma verranno ritirate senza raggiungere la disponibilità generale perché sono ora disponibili i nuovi avvisi delle metriche consigliati descritti in questo articolo.
Se queste regole di avviso legacy sono già state abilitate, è necessario disabilitarle e abilitare la nuova esperienza.
Disabilitare le regole di avviso delle metriche
- Dal menu Informazioni dettagliate per il cluster selezionare Avvisi consigliati (anteprima).
- Modificare lo stato per ogni regola di avviso impostando Disabilitato.
Passaggi successivi
- Informazioni sui diversi tipi di regole di avviso in Monitoraggio di Azure.
- Informazioni sui gruppi di regole di avviso nel servizio gestito di Monitoraggio di Azure per Prometheus.