Monitorare le macchine virtuali con Monitoraggio di Azure: Avvisi
Questo articolo fa parte della guida Monitorare le macchine virtuali e i relativi carichi di lavoro in Monitoraggio di Azure. Gli avvisi in Monitoraggio di Azure notificano in modo proattivo dati e modelli interessanti nei dati di monitoraggio. Non esistono regole di avviso preconfigurate per le macchine virtuali, ma è possibile crearne di personalizzate in base ai dati raccolti dall'agente di Monitoraggio di Azure. Questo articolo presenta i concetti di avviso specifici per le macchine virtuali e le regole di avviso comuni usate da altri clienti di Monitoraggio di Azure.
Questo scenario descrive come implementare il monitoraggio completo dell'ambiente di macchine virtuali ibride e di Azure:
Per iniziare a monitorare la prima macchina virtuale di Azure, vedere Monitorare le macchine virtuali di Azure.
Per abilitare rapidamente un set consigliato di avvisi, vedere Abilitare le regole di avviso consigliate per una macchina virtuale di Azure.
Importante
La maggior parte delle regole di avviso ha un costo che dipende dal tipo di regola, dal numero di dimensioni incluse e dalla frequenza con cui viene eseguita. Prima di creare regole di avviso, vedere la sezione Regole di avviso in Prezzi di Monitoraggio di Azure.
Raccolta dati
Le regole di avviso controllano i dati già raccolti in Monitoraggio di Azure. È necessario assicurarsi che i dati vengano raccolti per uno scenario specifico prima di poter creare una regola di avviso. Vedere Monitorare le macchine virtuali con Monitoraggio di Azure: raccogliere dati per indicazioni sulla configurazione della raccolta dati per diversi scenari, incluse tutte le regole di avviso in questo articolo.
Regole di avviso consigliate
Monitoraggio di Azure offre un set di regole di avviso consigliate che è possibile abilitare rapidamente per qualsiasi macchina virtuale di Azure. Queste regole sono un ottimo punto di partenza per il monitoraggio di base. Ma da solo, non forniscono avvisi sufficienti per la maggior parte delle implementazioni aziendali per i motivi seguenti:
- Gli avvisi consigliati si applicano solo alle macchine virtuali di Azure e non alle macchine ibride.
- Gli avvisi consigliati includono solo metriche host e non metriche guest o log. Queste metriche sono utili per monitorare l'integrità del computer stesso. Ma offrono visibilità minima sui carichi di lavoro e sulle applicazioni in esecuzione nel computer.
- Gli avvisi consigliati sono associati a singoli computer che creano un numero eccessivo di regole di avviso. Anziché basarsi su questo metodo per ogni computer, vedere Ridimensionare le regole di avviso per le strategie sull'uso di un numero minimo di regole di avviso per più computer.
Tipi di avviso
I tipi più comuni di regole di avviso in Monitoraggio di Azure sono gli avvisi delle metriche e gli avvisi di ricerca log. Il tipo di regola di avviso creata per uno scenario specifico dipende dalla posizione in cui si trovano i dati a cui si sta avvisando.
Potrebbero verificarsi casi in cui i dati per uno scenario di avviso specifico sono disponibili sia in Metriche che in Log. In tal caso, è necessario determinare il tipo di regola da usare. Si potrebbe anche avere flessibilità nel modo in cui si raccolgono determinati dati e si consente alla decisione del tipo di regola di avviso di guidare la decisione per il metodo di raccolta dati.
Avvisi delle metriche
Usi comuni per gli avvisi delle metriche:
- Avvisa quando una determinata metrica supera una soglia. Un esempio è quando la CPU di un computer è in esecuzione elevata.
Origini dati per gli avvisi delle metriche:
- Metriche host per le macchine virtuali di Azure, raccolte automaticamente
- Metriche raccolte dall'agente di Monitoraggio di Azure dal sistema operativo guest
Avvisi di ricerca log
Usi comuni per gli avvisi di ricerca log:
- Avvisa quando viene trovato un evento o un modello specifico di eventi dal registro eventi di Windows o Syslog. Queste regole di avviso misurano in genere le righe della tabella restituite dalla query.
- Avviso basato su un calcolo di dati numerici in più computer. Queste regole di avviso misurano in genere il calcolo di una colonna numerica nei risultati della query.
Origini dati per gli avvisi di ricerca log:
- Tutti i dati raccolti in un'area di lavoro Log Analytics
Regole di avviso di ridimensionamento
Poiché potrebbero essere presenti molte macchine virtuali che richiedono lo stesso monitoraggio, non è necessario creare singole regole di avviso per ognuna di esse. Si vuole anche assicurarsi che siano disponibili strategie diverse per limitare il numero di regole di avviso da gestire, a seconda del tipo di regola. Ognuna di queste strategie dipende dalla comprensione della risorsa di destinazione della regola di avviso.
Regole di avviso per le metriche
Le macchine virtuali supportano più regole di avviso delle metriche delle risorse, come descritto in Monitorare più risorse. Questa funzionalità consente di creare una singola regola di avviso delle metriche applicabile a tutte le macchine virtuali in un gruppo di risorse o una sottoscrizione all'interno della stessa area.
Iniziare con gli avvisi consigliati e creare una regola corrispondente per ognuna usando la sottoscrizione o un gruppo di risorse come risorsa di destinazione. Se sono presenti computer in più aree, è necessario creare regole duplicate per ogni area.
Quando si identificano i requisiti per più regole di avviso delle metriche, seguire questa stessa strategia usando una sottoscrizione o un gruppo di risorse come risorsa di destinazione per:
- Ridurre al minimo il numero di regole di avviso che è necessario gestire.
- Assicurarsi che vengano applicati automaticamente a tutti i nuovi computer.
Regole di avviso di ricerca log
Se si imposta la risorsa di destinazione di una regola di avviso di ricerca log su un computer specifico, le query sono limitate ai dati associati a tale computer, che fornisce singoli avvisi. Questa disposizione richiede una regola di avviso separata per ogni computer.
Se si imposta la risorsa di destinazione di una regola di avviso di ricerca log su un'area di lavoro Log Analytics, è possibile accedere a tutti i dati nell'area di lavoro. Per questo motivo, è possibile inviare avvisi sui dati di tutti i computer del gruppo di lavoro con una singola regola. Questa disposizione consente di creare un singolo avviso per tutti i computer. È quindi possibile usare le dimensioni per creare un avviso separato per ogni computer.
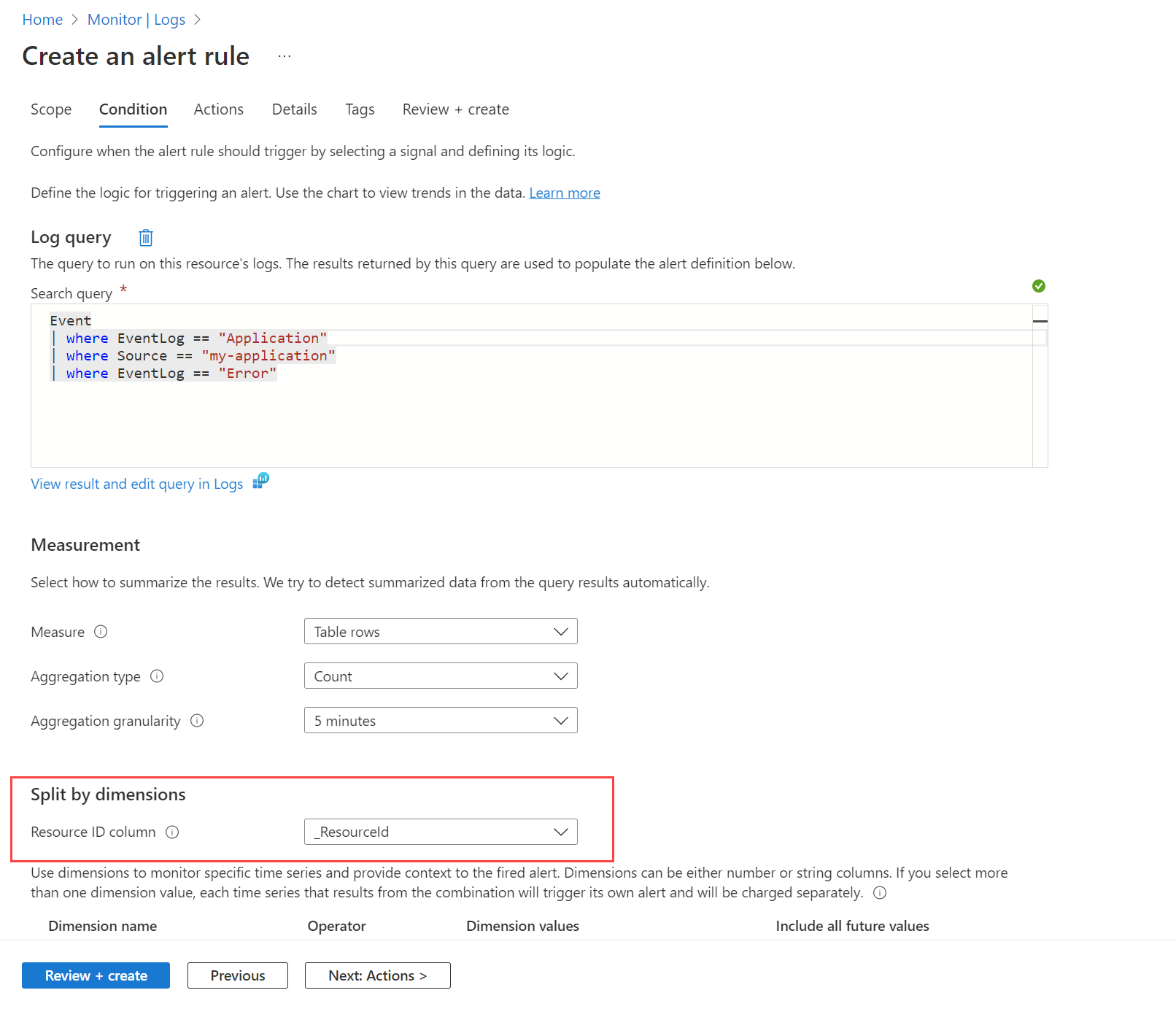
Ad esempio, è possibile inviare un avviso quando viene creato un evento di errore nel registro eventi di Windows da qualsiasi computer. È prima necessario creare una regola di raccolta dati come descritto in Raccogliere eventi e contatori delle prestazioni dalle macchine virtuali con l'agente di Monitoraggio di Azure per inviare questi eventi alla Event tabella nell'area di lavoro Log Analytics. Si crea quindi una regola di avviso che esegue una query in questa tabella usando l'area di lavoro come risorsa di destinazione e la condizione illustrata nell'immagine seguente.
La query restituisce un record per tutti i messaggi di errore in qualsiasi computer. Usare l'opzione Dividi per dimensioni e specificare _ResourceId per indicare alla regola di creare un avviso per ogni computer se nei risultati vengono restituiti più computer.
Dimensioni
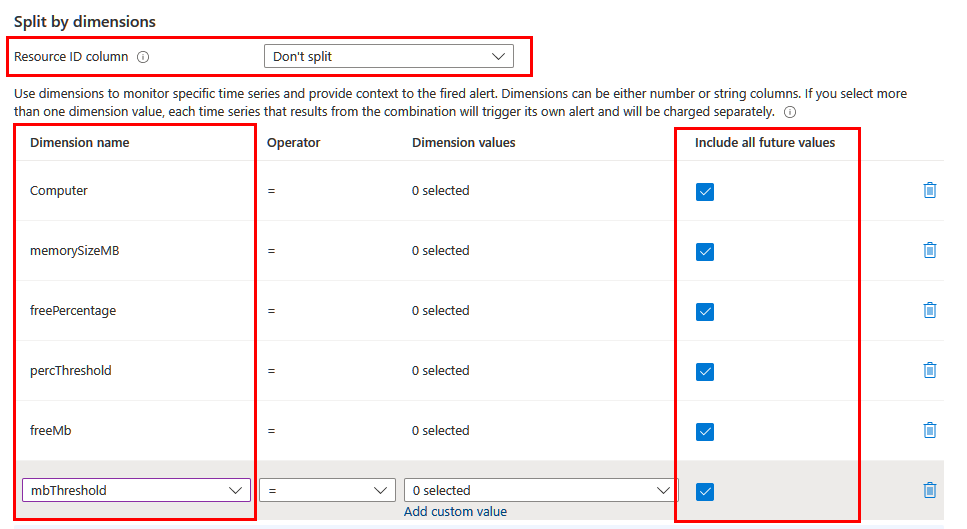
A seconda delle informazioni che si desidera includere nell'avviso, potrebbe essere necessario suddividere usando dimensioni diverse. In questo caso, assicurarsi che le dimensioni necessarie vengano proiettate nella query usando il progetto o l'operatore extend. Impostare il campo Colonna ID risorsa su Non dividere e includere tutte le dimensioni significative nell'elenco. Assicurarsi che l'opzione Includi tutti i valori futuri sia selezionata in modo che sia incluso qualsiasi valore restituito dalla query.
Soglie dinamiche
Un altro vantaggio dell'uso delle regole di avviso di ricerca log è la possibilità di includere logica complessa nella query per determinare il valore soglia. È possibile impostare come hardcoded la soglia, applicarla a tutte le risorse o calcolarla in modo dinamico in base a un campo o a un valore calcolato. La soglia viene applicata alle risorse solo in base a condizioni specifiche. Ad esempio, è possibile creare un avviso basato sulla memoria disponibile, ma solo per i computer con una determinata quantità di memoria totale.
Regole di avviso comuni
La sezione seguente elenca le regole di avviso comuni per le macchine virtuali in Monitoraggio di Azure. I dettagli per gli avvisi delle metriche e gli avvisi di ricerca log vengono forniti per ognuno di essi. Per indicazioni sul tipo di avviso da usare, vedere Tipi di avviso. Se non si ha familiarità con il processo di creazione di regole di avviso in Monitoraggio di Azure, vedere le istruzioni per creare una nuova regola di avviso.
Nota
I dettagli per gli avvisi di ricerca log forniti qui usano i dati raccolti usando Informazioni dettagliate macchina virtuale, che fornisce un set di contatori delle prestazioni comuni per il sistema operativo client. Questo nome è indipendente dal tipo di sistema operativo.
Computer non disponibile
Uno dei requisiti di monitoraggio più comuni per una macchina virtuale consiste nel creare un avviso se si interrompe l'esecuzione. Il metodo migliore consiste nel creare una regola di avviso delle metriche in Monitoraggio di Azure usando la metrica di disponibilità della macchina virtuale, attualmente in anteprima pubblica. Per una procedura dettagliata su questa metrica, vedere Creare una regola di avviso di disponibilità per la macchina virtuale di Azure.
Come descritto in Ridimensionamento delle regole di avviso, creare una regola di avviso di disponibilità usando una sottoscrizione o un gruppo di risorse come risorsa di destinazione. La regola si applica a più macchine virtuali, incluse le nuove macchine create dopo la regola di avviso.
Heartbeat dell'agente
L'heartbeat dell'agente è leggermente diverso dall'avviso del computer non disponibile perché si basa sull'agente di Monitoraggio di Azure per inviare un heartbeat. L'heartbeat dell'agente può avvisare se il computer è in esecuzione, ma l'agente non risponde.
Regole di avviso per le metriche
Una metrica denominata Heartbeat è inclusa in ogni area di lavoro Log Analytics. Ogni macchina virtuale connessa all'area di lavoro invia un valore della metrica heartbeat ogni minuto. Poiché il computer è una dimensione nella metrica, è possibile generare un avviso quando un computer non riesce a inviare un heartbeat. Impostare Il tipo di aggregazione su Count e il valore Threshold in modo che corrispondano alla granularità di valutazione.
Regole di avviso di ricerca log
Gli avvisi di ricerca log usano la tabella Heartbeat, che deve avere un record heartbeat ogni minuto da ogni computer.
Usare una regola con la query seguente:
Heartbeat
| summarize TimeGenerated=max(TimeGenerated) by Computer, _ResourceId
| extend Duration = datetime_diff('minute',now(),TimeGenerated)
| summarize MinutesSinceLastHeartbeat = min(Duration) by Computer, bin(TimeGenerated,5m), _ResourceId
Avvisi cpu
Questa sezione descrive gli avvisi della CPU.
Regole di avviso per le metriche
| Destinazione | Metric |
|---|---|
| Host | Percentuale CPU (inclusi negli avvisi consigliati) |
| Guest di Windows | \Informazioni processore(_Total)% tempo processore |
| Guest Linux | cpu/usage_active |
Regole di avviso di ricerca log
Cpu
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Processor" and Name == "UtilizationPercentage"
| summarize CPUPercentageAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Avvisi di memoria
Questa sezione descrive gli avvisi di memoria.
Regole di avviso per le metriche
| Destinazione | Metric |
|---|---|
| Host | Byte di memoria disponibili (anteprima) (inclusi negli avvisi consigliati) |
| Guest di Windows | \Memory% Commit byte in uso \Memory\Available Bytes |
| Guest Linux | mem/available mem/available_percent |
Regole di avviso di ricerca log
Memoria disponibile in MB
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| summarize AvailableMemoryInMBAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Memoria disponibile in percentuale
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| extend TotalMemory = toreal(todynamic(Tags)["vm.azm.ms/memorySizeMB"]) | extend AvailableMemoryPercentage = (toreal(Val) / TotalMemory) * 100.0
| summarize AvailableMemoryInPercentageAverage = avg(AvailableMemoryPercentage) by bin(TimeGenerated, 15m), Computer, _ResourceId
Avvisi del disco
Questa sezione descrive gli avvisi del disco.
Regole di avviso per le metriche
| Destinazione | Metric |
|---|---|
| Guest di Windows | \Disco logico (_Total)% spazio disponibile \Disco logico (_Total)\Megabyte liberi |
| Guest Linux | disco/libero disco/free_percent |
Regole di avviso di ricerca log
Disco logico usato: tutti i dischi in ogni computer
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Disco logico usato: singoli dischi
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Operazioni di I/O al secondo del disco logico
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "TransfersPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskIOPSAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Frequenza dei dati dei dischi logici
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "BytesPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskBytesPerSecondAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Avvisi di rete
Regole di avviso per le metriche
| Destinazione | Metric |
|---|---|
| Host | Network In Total, Network Out Total (incluso negli avvisi consigliati) |
| Guest di Windows | \Interfaccia di rete\Byte inviati/sec \Disco logico (_Total)\Megabyte liberi |
| Guest Linux | disco/libero disco/free_percent |
Regole di avviso di ricerca log
Byte delle interfacce di rete ricevute: tutte le interfacce
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| summarize BytesReceivedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Byte delle interfacce di rete ricevuti: singole interfacce
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesReceievedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
Byte delle interfacce di rete inviate: tutte le interfacce
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Byte delle interfacce di rete inviate: singole interfacce
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
Eventi di Windows e Linux
L'esempio seguente crea un avviso quando viene creato un evento di Windows specifico. Usa una regola di avviso per la misurazione delle metriche per creare un avviso separato per ogni computer.
Creare una regola di avviso per un evento di Windows specifico. Questo esempio mostra un evento nel registro applicazioni. Specificare una soglia di 0 e violazioni consecutive superiori a 0.
Event | where EventLog == "Application" | where EventID == 123 | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)Creare una regola di avviso per gli eventi Syslog con una gravità particolare. L'esempio seguente mostra gli eventi di autorizzazione degli errori. Specificare una soglia di 0 e violazioni consecutive superiori a 0.
Syslog | where Facility == "auth" | where SeverityLevel == "err" | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)
Contatori delle prestazioni personalizzati
Creare un avviso sul valore massimo di un contatore.
Perf | where CounterName == "My Counter" | summarize AggregatedValue = max(CounterValue) by ComputerCreare un avviso sul valore medio di un contatore.
Perf | where CounterName == "My Counter" | summarize AggregatedValue = avg(CounterValue) by Computer
Passaggi successivi
Analizzare i dati di monitoraggio raccolti per le macchine virtuali