Accelerare l'analisi dei Big Data in tempo reale usando il connettore Spark
Si applica a:![]() database SQL di Azure Istanza gestita di SQL di Azure
database SQL di Azure Istanza gestita di SQL di Azure![]()
Nota
A partire da settembre 2020, questo connettore non viene mantenuto attivamente. Tuttavia, Apache Spark Connessione or per SQL Server e Azure SQL è ora disponibile, con il supporto per le associazioni Python e R, un'interfaccia più semplice da usare per l'inserimento bulk dei dati e molti altri miglioramenti. È consigliabile valutare e usare il nuovo connettore anziché questo. Le informazioni sul connettore precedente (questa pagina) vengono conservate solo a scopo di archiviazione.
Il connettore Spark consente ai database in database SQL di Azure, Istanza gestita di SQL di Azure e SQL Server di fungere da origine dati di input o sink di dati di output per i processi Spark. Consente di usare dati transazionali in tempo reale nell'analisi dei Big Data e rendere persistenti i risultati per query o report ad hoc. Rispetto al connettore JDBC predefinito, questo connettore consente di inserire in blocco i dati nel database. Può migliorare l'inserimento di righe per riga con prestazioni da 10x a 20 volte superiore. Il connettore Spark supporta l'autenticazione con Microsoft Entra ID (in precedenza Azure Active Directory) per connettersi a database SQL di Azure e Istanza gestita di SQL di Azure, consentendo di connettere il database da Azure Databricks usando l'account Microsoft Entra. Fornisce interfacce simili al connettore JDBC incorporato. È facile eseguire la migrazione dei processi Spark esistenti per l'utilizzo di questo nuovo connettore.
Nota
Microsoft Entra ID era precedentemente noto come Azure Active Directory (Azure AD).
Scaricare e compilare un connettore Spark
Il repository GitHub per il connettore precedentemente collegato a da questa pagina non viene gestito attivamente. È invece consigliabile valutare e usare il nuovo connettore.
Versioni ufficiali supportate
| Componente | Versione |
|---|---|
| Apache Spark | 2.0.2 o versione successiva |
| Scala | 2.10 o versione successiva |
| Driver Microsoft JDBC per SQL Server | 6.2 o versione successiva |
| Microsoft SQL Server | SQL Server 2008 o versione successiva |
| Database SQL di Azure | Supportata |
| Istanza gestita di SQL di Azure | Supportata |
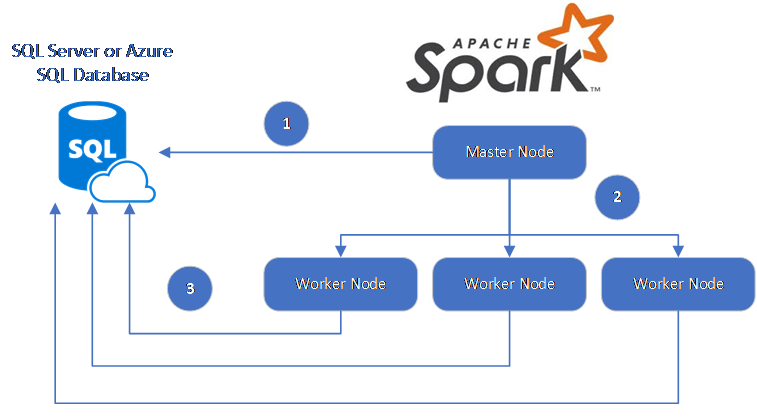
Il connettore Spark usa Microsoft JDBC Driver per SQL Server per spostare i dati tra nodi di lavoro Spark e database:
Il flusso di dati è il seguente:
- Il nodo master Spark si connette ai database in database SQL o SQL Server e carica i dati da una tabella specifica o usando una query SQL specifica.
- Il nodo principale Spark distribuisce i dati ai nodi di lavoro per la trasformazione.
- Il nodo Worker si connette ai database che si connettono a database SQL e SQL Server e scrive i dati nel database. L'utente può scegliere se utilizzare l'inserimento riga per riga o l'inserimento in blocco.
Il diagramma seguente illustra il flusso di dati.
Compilare il connettore Spark
Attualmente il progetto del connettore usa Maven. Per creare il connettore senza le dipendenze, è possibile eseguire:
- mvn clean package
- Scaricare le versioni più recenti del file JAR dalla cartella release
- Includere il file JAR spark database SQL
Connessione e leggere i dati usando il connettore Spark
È possibile connettersi ai database in database SQL e SQL Server da un processo Spark per leggere o scrivere dati. È anche possibile eseguire una query DML o DDL nei database in database SQL e SQL Server.
Leggere i dati da SQL di Azure e SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********",
"connectTimeout" -> "5", //seconds
"queryTimeout" -> "5" //seconds
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Leggere i dati da SQL di Azure e SQL Server con la query SQL specificata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"queryCustom" -> "SELECT TOP 100 * FROM dbo.Clients WHERE PostalCode = 98074" //Sql query
"user" -> "username",
"password" -> "*********",
))
//Read all data in table dbo.Clients
val collection = sqlContext.read.sqlDB(config)
collection.show()
Scrivere dati in SQL di Azure e SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
// Aquire a DataFrame collection (val collection)
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"dbTable" -> "dbo.Clients",
"user" -> "username",
"password" -> "*********"
))
import org.apache.spark.sql.SaveMode
collection.write.mode(SaveMode.Append).sqlDB(config)
Eseguire query DML o DDL in SQL di Azure e SQL Server
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.query._
val query = """
|UPDATE Customers
|SET ContactName = 'Alfred Schmidt', City = 'Frankfurt'
|WHERE CustomerID = 1;
""".stripMargin
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"queryCustom" -> query
))
sqlContext.sqlDBQuery(config)
Connessione da Spark con l'autenticazione di Microsoft Entra
È possibile connettersi a database SQL e Istanza gestita di SQL usando l'autenticazione Di Microsoft Entra. Usare l'autenticazione Microsoft Entra per gestire centralmente le identità degli utenti del database e come alternativa all'autenticazione SQL.
Connessione tramite la modalità di autenticazione ActiveDirectoryPassword
Requisito di installazione
Se si usa la modalità di autenticazione ActiveDirectoryPassword, è necessario scaricare microsoft-authentication-library-for-java e le relative dipendenze e includerle nel percorso di compilazione Java.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"authentication" -> "ActiveDirectoryPassword",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Connessione tramite un token di accesso
Requisito di installazione
Se si usa la modalità di autenticazione basata su token di accesso, è necessario scaricare microsoft-authentication-library-for-java e le relative dipendenze e includerle nel percorso di compilazione Java.
Vedere Usare l'autenticazione di Microsoft Entra per informazioni su come ottenere un token di accesso al database in database SQL di Azure o Istanza gestita di SQL di Azure.
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
val config = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"accessToken" -> "access_token",
"hostNameInCertificate" -> "*.database.windows.net",
"encrypt" -> "true"
))
val collection = sqlContext.read.sqlDB(config)
collection.show()
Scrivere dati usando BULK INSERT
Il connettore jdbc tradizionale scrive i dati nel database usando l'inserimento di righe per riga. È possibile usare il connettore Spark per scrivere dati in AZURE SQL e SQL Server usando l'inserimento bulk. Migliora significativamente le prestazioni di scrittura durante il caricamento di set di dati di grandi dimensioni o il caricamento di dati in tabelle in cui viene usato un indice columnstore.
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
/**
Add column Metadata.
If not specified, metadata is automatically added
from the destination table, which may suffer performance.
*/
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "Title", java.sql.Types.NVARCHAR, 128, 0)
bulkCopyMetadata.addColumnMetadata(2, "FirstName", java.sql.Types.NVARCHAR, 50, 0)
bulkCopyMetadata.addColumnMetadata(3, "LastName", java.sql.Types.NVARCHAR, 50, 0)
val bulkCopyConfig = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"dbTable" -> "dbo.Clients",
"bulkCopyBatchSize" -> "2500",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
df.bulkCopyToSqlDB(bulkCopyConfig, bulkCopyMetadata)
//df.bulkCopyToSqlDB(bulkCopyConfig) if no metadata is specified.
Passaggi successivi
Se non è già stato fatto, scaricare il connettore Spark dal repository GitHub azure-sqldb-spark ed esplorare le risorse aggiuntive nel repository:
È possibile anche esaminare la guida ad Apache Spark SQL, DataFrame e set di dati e la documentazione Azure Databricks.
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per