Procedure consigliate per l'uso dell'API univariata Rilevamento anomalie
Importante
A partire dal 20 settembre 2023 non sarà possibile creare nuove risorse Rilevamento anomalie. Il servizio Rilevamento anomalie viene ritirato il 1° ottobre 2026.
L'API Rilevamento anomalie è un servizio di rilevamento anomalie senza stato. L'accuratezza e le prestazioni dei risultati possono essere influenzate da:
- Modalità di preparazione dei dati delle serie temporali.
- Parametri dell'API Rilevamento anomalie usati.
- Numero di punti dati nella richiesta API.
Usare questo articolo per informazioni sulle procedure consigliate per l'uso dell'API per ottenere i risultati migliori per i dati.
Quando usare il rilevamento anomalie in batch (intero) o più recente (ultimo)
L'endpoint di rilevamento batch dell'API Rilevamento anomalie consente di rilevare le anomalie tramite i dati dell'intera serie temporale. In questa modalità di rilevamento viene creato e applicato un singolo modello statistico a ogni punto del set di dati. Se la serie temporale presenta le caratteristiche seguenti, è consigliabile usare il rilevamento batch per visualizzare in anteprima i dati in una chiamata API.
- Serie temporale stagionale, con anomalie occasionali.
- Una serie temporale di tendenza piatta, con picchi/immersioni occasionali.
Non è consigliabile usare il rilevamento anomalie batch per il monitoraggio dei dati in tempo reale o usarlo nei dati delle serie temporali che non hanno le caratteristiche precedenti.
Il rilevamento batch crea e applica un solo modello, il rilevamento per ogni punto viene eseguito nel contesto dell'intera serie. Se le tendenze dei dati delle serie temporali aumentano e rallentano senza stagionalità, alcuni punti di modifica (cali e picchi nei dati) potrebbero non essere rilevati dal modello. Analogamente, alcuni punti di modifica meno significativi di quelli successivi nel set di dati potrebbero non essere considerati sufficientemente significativi da essere incorporati nel modello.
Il rilevamento batch è più lento rispetto al rilevamento dello stato anomalie dell'ultimo punto quando si esegue il monitoraggio dei dati in tempo reale, a causa del numero di punti analizzati.
Per il monitoraggio dei dati in tempo reale, è consigliabile rilevare solo lo stato anomalie del punto dati più recente. Applicando continuamente il rilevamento dei punti più recente, il monitoraggio dei dati di streaming può essere eseguito in modo più efficiente e accurato.
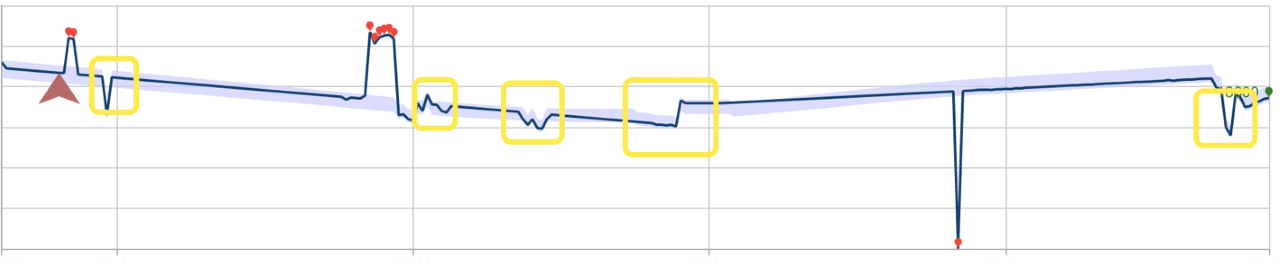
L'esempio seguente descrive l'impatto che queste modalità di rilevamento possono avere sulle prestazioni. La prima immagine mostra il risultato del rilevamento continuo dell'ultimo punto di stato anomalie lungo 28 punti dati precedentemente visualizzati. I punti rossi sono anomalie.

Di seguito è riportato lo stesso set di dati usando il rilevamento anomalie batch. Il modello compilato per l'operazione ha ignorato diverse anomalie, contrassegnate da rettangoli.
Preparazione dei dati
L'API Rilevamento anomalie accetta i dati delle serie temporali formattati in un oggetto richiesta JSON. Una serie temporale può essere qualsiasi dato numerico registrato nel tempo in ordine sequenziale. È possibile inviare finestre dei dati delle serie temporali all'endpoint API Rilevamento anomalie per migliorare le prestazioni dell'API. Il numero minimo di punti dati che è possibile inviare è 12 e il massimo è 8640 punti. La granularità è definita come frequenza con cui vengono campionati i dati.
I punti dati inviati all'API Rilevamento anomalie devono avere un timestamp UTC (Coordinated Universal Time) valido e un valore numerico.
{
"granularity": "daily",
"series": [
{
"timestamp": "2018-03-01T00:00:00Z",
"value": 32858923
},
{
"timestamp": "2018-03-02T00:00:00Z",
"value": 29615278
},
]
}
Se i dati vengono campionati a intervalli di tempo non standard, è possibile specificarli aggiungendo l'attributo customInterval nella richiesta. Ad esempio, se la serie viene campionata ogni 5 minuti, è possibile aggiungere quanto segue alla richiesta JSON:
{
"granularity" : "minutely",
"customInterval" : 5
}
Punti dati mancanti
I punti dati mancanti sono comuni nei set di dati time series distribuiti in modo uniforme, in particolare quelli con una granularità fine (un intervallo di campionamento ridotto. Ad esempio, i dati campionati ogni pochi minuti. Manca meno del 10% del numero previsto di punti nei dati non dovrebbe avere un impatto negativo sui risultati del rilevamento. Valutare la possibilità di colmare le lacune nei dati in base alle relative caratteristiche, ad esempio la sostituzione dei punti dati da un periodo precedente, l'interpolazione lineare o una media mobile.
Aggregare i dati distribuiti
L'API Rilevamento anomalie funziona meglio in una serie temporale distribuita uniformemente. Se i dati vengono distribuiti in modo casuale, è consigliabile aggregarli in base a un'unità di tempo, ad esempio Al minuto, ogni ora o ogni giorno.
Rilevamento anomalie sui dati con modelli stagionali
Se si sa che i dati delle serie temporali hanno un modello stagionale (uno che si verifica a intervalli regolari), è possibile migliorare l'accuratezza e il tempo di risposta dell'API.
La specifica di quando period si costruisce la richiesta JSON può ridurre la latenza di rilevamento anomalie fino al 50%. period è un numero intero che specifica approssimativamente il numero di punti dati impiegato dalla serie temporale per ripetere un criterio. Ad esempio, una serie temporale con un punto dati al giorno avrà come period7e una serie temporale con un punto all'ora (con lo stesso modello settimanale) avrà un valore period pari 7*24a . Se non si è certi dei modelli dei dati, non è necessario specificare questo parametro.
Per ottenere risultati ottimali, fornire quattro periodpunti dati, più uno aggiuntivo. Ad esempio, i dati orari con un modello settimanale come descritto in precedenza devono fornire 673 punti dati nel corpo della richiesta (7 * 24 * 4 + 1).
Dati di campionamento per il monitoraggio in tempo reale
Se i dati di streaming vengono campionati a un breve intervallo (ad esempio secondi o minuti), l'invio del numero consigliato di punti dati può superare il numero massimo consentito dell'API di Rilevamento anomalie (8640 punti dati). Se i dati mostrano un modello stagionale stabile, è consigliabile inviare un campione dei dati delle serie temporali a un intervallo di tempo più ampio, ad esempio ore. Il campionamento dei dati in questo modo può anche migliorare notevolmente il tempo di risposta dell'API.