Partizionamento in Azure Cosmos DB for Apache Cassandra
SI APPLICA A: ![]() Cassandra
Cassandra
Questo articolo descrive il funzionamento del partizionamento in Azure Cosmos DB for Apache Cassandra.
L'API per Cassandra usa il partizionamento per dimensionare le singole tabelle in un keyspace in modo da soddisfare le esigenze di prestazioni dell'applicazione. Le partizioni vengono create in base al valore di un chiave di partizione associata a ogni record di una tabella. Tutti i record di una partizione hanno lo stesso valore della chiave di partizione. Azure Cosmos DB gestisce il posizionamento delle partizioni in modo trasparente e automatico nelle risorse fisiche per soddisfare con efficienza le esigenze di scalabilità e prestazioni della tabella. Quando i requisiti di velocità effettiva e archiviazione di un'applicazione aumentano, Azure Cosmos DB sposta e bilancia i dati tra un numero maggiore di computer fisici.
Dal punto di vista dello sviluppatore, il comportamento del partizionamento in Azure Cosmos DB for Apache Cassandra è uguale a quello di Apache Cassandra nativo. Tuttavia, dietro le quinte esistono alcune differenze.
Differenze tra Apache Cassandra e Azure Cosmos DB
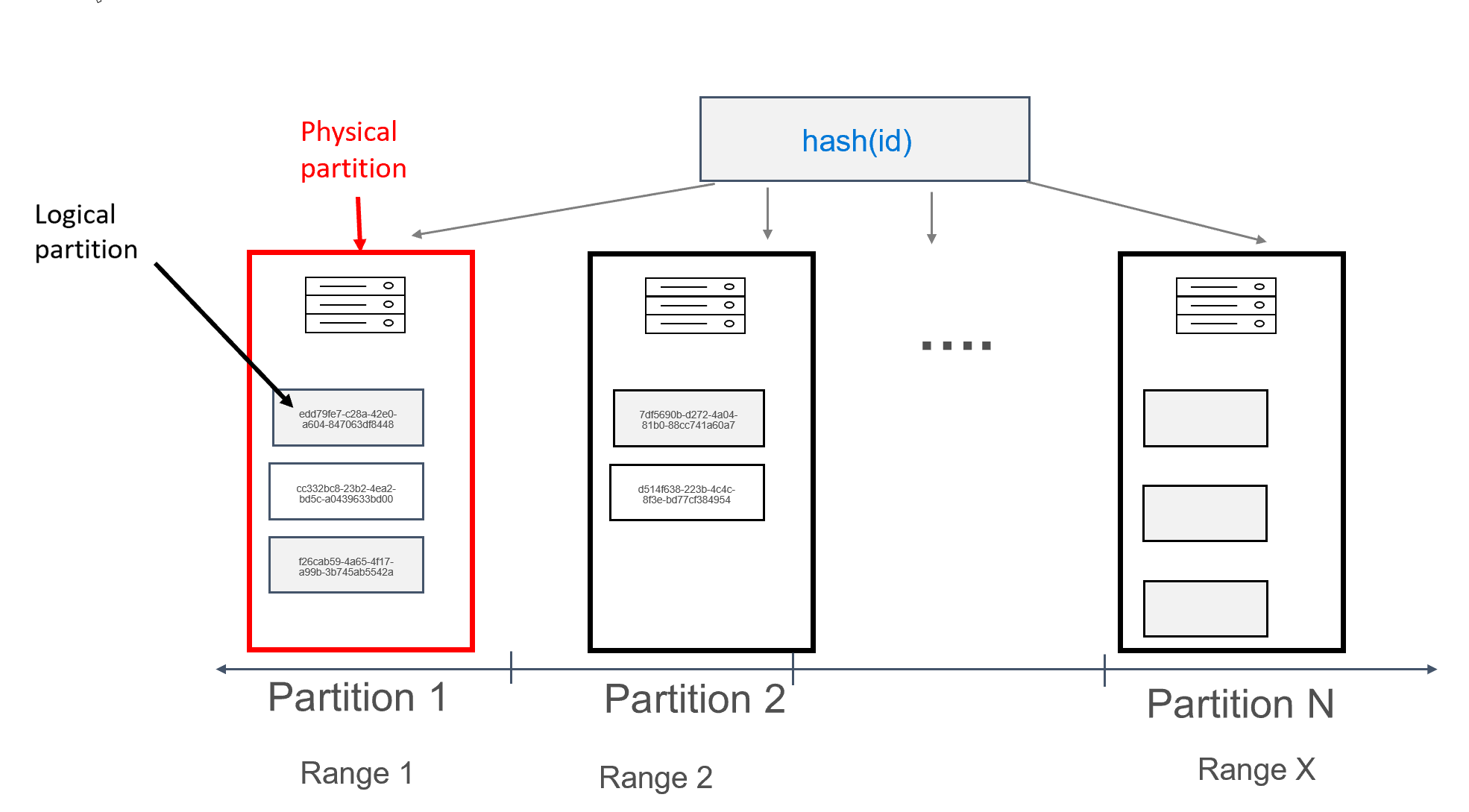
In Azure Cosmos DB ogni computer in cui vengono archiviate le partizioni viene definito partizione fisica. La partizione fisica è simile a una macchina virtuale, ovvero un'unità di calcolo dedicata o un set di risorse fisiche. Ogni partizione archiviata in questa unità di calcolo viene definita partizione logica in Azure Cosmos DB. Se si ha già familiarità con Apache Cassandra, le partizioni logiche possono essere paragonate alle normali partizioni in Cassandra.
Apache Cassandra consiglia un limite di 100 MB per le dimensioni dei dati che è possibile archiviare in una partizione. L'API per Cassandra per Azure Cosmos DB consente fino a 20 GB di dati per partizione logica e fino a 30 GB per partizione fisica. In Azure Cosmos DB, a differenza di Apache Cassandra, la capacità di calcolo disponibile nella partizione fisica viene espressa usando una singola metrica denominata unità richiesta, che consente di considerare il carico di lavoro in termini di numero di richieste (letture o scritture) al secondo, anziché di quantità di core, memoria o operazioni di I/O al secondo. Una volta compreso il costo di ogni richiesta, diventa quindi più semplice pianificare la capacità. Per ogni partizione fisica possono essere disponibili fino a 10000 UR di calcolo. Per altre informazioni sulle opzioni di scalabilità, vedere l'articolo sulla scalabilità elastica nell'API per Cassandra.
In Azure Cosmos DB ogni partizione fisica è costituita da un set di repliche, con almeno 4 repliche per partizione. Viceversa, in Apache Cassandra è possibile impostare un fattore di replica 1. Questo, però, determina una disponibilità bassa se l'unico nodo con i dati non funziona. Nell'API per Cassandra è sempre presente un fattore di replica 4 (quorum di 3). Azure Cosmos DB gestisce automaticamente i set di repliche, mentre invece in Apache Cassandra devono essere gestiti con vari strumenti.
Apache Cassandra prevede il concetto di token, ovvero hash di chiavi di partizione. I token sono basati su un hash a 64 byte murmur3, con valori compresi tra -2^63 e -2^63 - 1. Questo intervallo viene comunemente definito "Token Ring" in Apache Cassandra. Il Token Ring è distribuito in intervalli di token, che vengono divisi tra i nodi presenti in un cluster nativo di Apache Cassandra. Il partizionamento per Azure Cosmos DB viene implementato in modo analogo, ad eccezione del fatto che viene usato un algoritmo hash diverso e che il Token Ring interno è più grande. Tuttavia, esternamente viene esposto lo stesso intervallo di token di Apache Cassandra, ad esempio -2^63 a -2^63 - 1.
Chiave primaria
Tutte le tabelle nell'API per Cassandra devono avere un valore di primary key definito. La sintassi per una chiave primaria è illustrata di seguito:
column_name cql_type_definition PRIMARY KEY
Si supponga di voler creare una tabella utente in cui archiviare i messaggi per utenti diversi:
CREATE TABLE uprofile.user (
id UUID PRIMARY KEY,
user text,
message text);
In questa struttura è stato definito il campo id come chiave primaria. La chiave primaria funge da identificatore per il record nella tabella e viene usata anche come chiave di partizione in Azure Cosmos DB. Se la chiave primaria è definita nel modo descritto in precedenza, in ogni partizione sarà presente un singolo record. Il risultato sarà una distribuzione perfettamente orizzontale e scalabile per la scrittura di dati nel database, una soluzione ideale per i casi d'uso di ricerca di coppie chiave-valore. L'applicazione dovrà fornire la chiave primaria ogni volta che legge i dati dalla tabella per ottimizzare le prestazioni di lettura.
Chiave primaria composta
Apache Cassandra prevede anche il concetto di compound keys. Una primary key composta è costituita da più colonne; la prima colonna è la partition key e tutte le colonne aggiuntive sono clustering keys. La sintassi per compound primary key è illustrata di seguito:
PRIMARY KEY (partition_key_column_name, clustering_column_name [, ...])
Si supponga di voler cambiare la struttura precedente e di consentire il recupero efficiente di messaggi per un dato utente:
CREATE TABLE uprofile.user (
user text,
id int,
message text,
PRIMARY KEY (user, id));
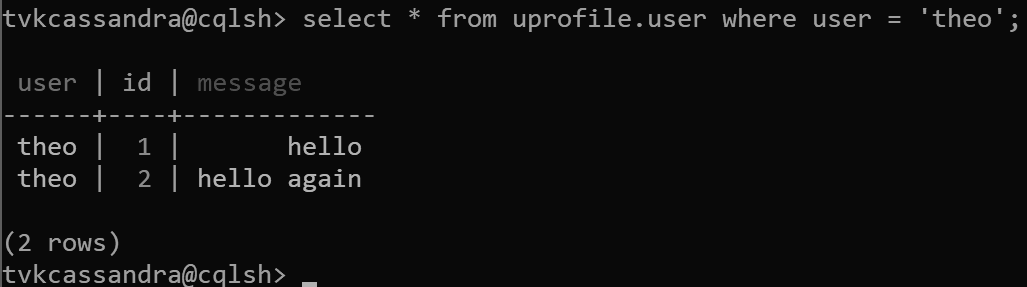
In questa struttura viene definito user come chiave di partizione e id come chiave di clustering. È possibile definire un numero qualsiasi di chiavi di clustering, ma ogni valore (o combinazione di valori) per la chiave di clustering deve essere univoco per fare in modo che più record vengano aggiunti alla stessa partizione, ad esempio:
insert into uprofile.user (user, id, message) values ('theo', 1, 'hello');
insert into uprofile.user (user, id, message) values ('theo', 2, 'hello again');
Quando vengono restituiti, i dati vengono ordinati in base alla chiave di clustering, come previsto in Apache Cassandra:
Avviso
Quando si eseguono query sui dati di una tabella con una chiave primaria composta, se si desidera filtrare in base alla chiave di partizione e in base a qualsiasi altro campo non indicizzato oltre alla chiave di clustering, assicurarsi di aggiungere in modo esplicito un indice secondario nella chiave di partizione:
CREATE INDEX ON uprofile.user (user);
Azure Cosmos DB for Apache Cassandra non applica indici alle chiavi di partizione per impostazione predefinita e l'indice in questo scenario può migliorare significativamente le prestazioni delle query. Per altre informazioni, vedere l'articolo sull'indicizzazione secondaria.
Con i dati modellati in questo modo, è possibile assegnare più record a ogni partizione, raggruppati per utente. È quindi possibile eseguire una query indirizzata in modo efficiente da partition key (in questo caso user) per ottenere tutti i messaggi per un determinato utente.
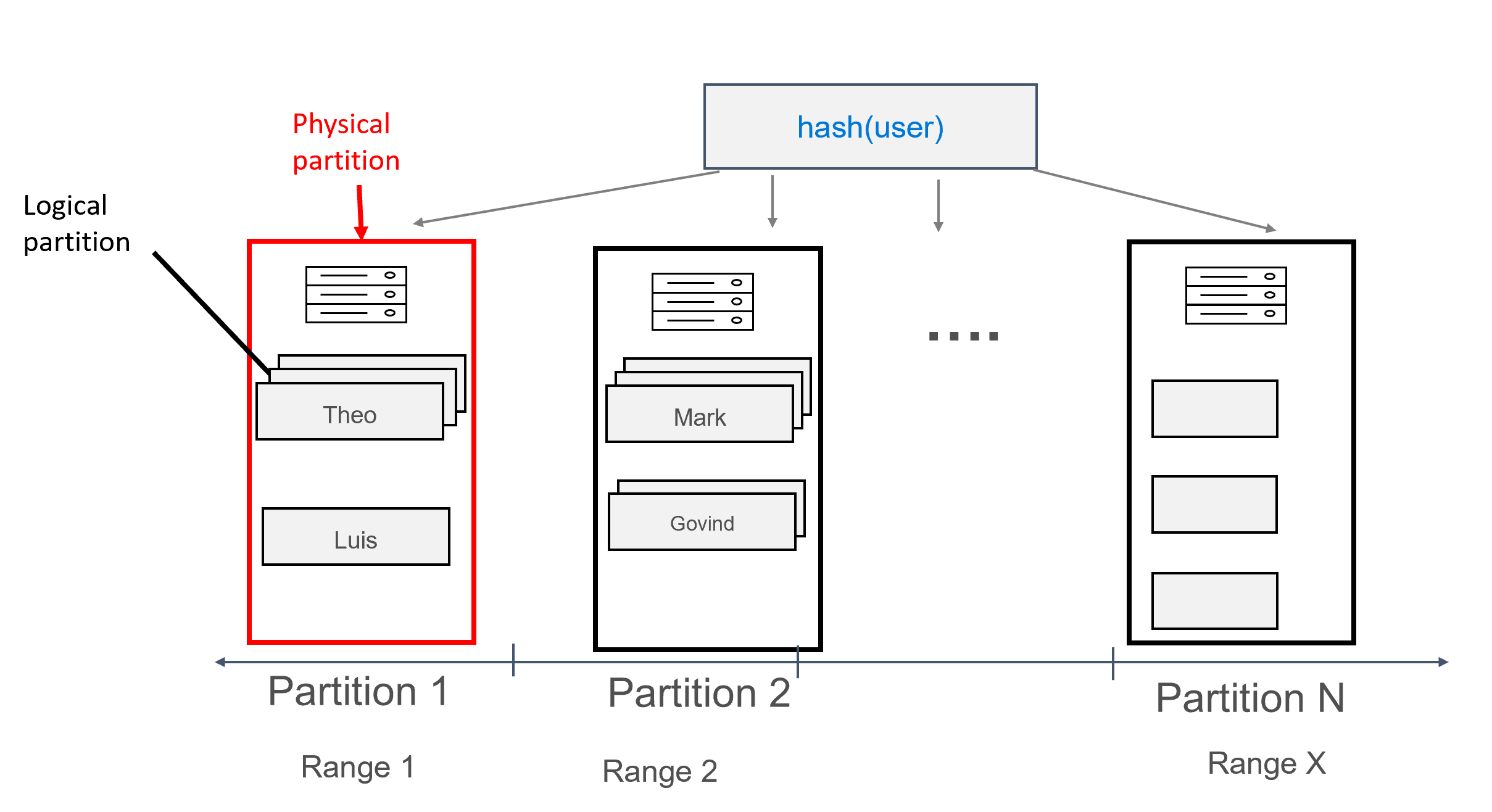
Chiave di partizione composita
Le chiavi di partizione composite funzionano essenzialmente come chiavi composte, con la differenza che è possibile specificare più colonne come chiave di partizione composita. La sintassi delle chiavi di partizione composite è illustrata di seguito:
PRIMARY KEY (
(partition_key_column_name[, ...]),
clustering_column_name [, ...]);
Ad esempio, è possibile definire quanto segue, dove la combinazione univoca di firstname e lastname costituisce la chiave di partizione e id è la chiave di clustering:
CREATE TABLE uprofile.user (
firstname text,
lastname text,
id int,
message text,
PRIMARY KEY ((firstname, lastname), id) );
Passaggi successivi
- Per altre informazioni, vedere Partizionamento e scalabilità orizzontale in Azure Cosmos DB.
- Informazioni sulla velocità effettiva con provisioning in Azure Cosmos DB.
- Informazioni sulla distribuzione globale in Azure Cosmos DB.