Esercitazione: Eseguire il training del primo modello di Machine Learning (SDK v1, parte 2 di 3)
SI APPLICA A: Python SDK azureml v1
Python SDK azureml v1
Questa esercitazione illustra come eseguire il training di un modello di Machine Learning in Azure Machine Learning. Questa esercitazione è la parte 2 di una serie di esercitazioni in due parti.
Nella Parte 1: Eseguire "Hello world!" della serie, si è appreso come usare uno script di controllo per eseguire un processo nel cloud.
In questa esercitazione si eseguirà il passaggio successivo inviando uno script che esegue il training di un modello di Machine Learning. Questo esempio consente di comprendere in che modo Azure Machine Learning semplifica il comportamento coerente tra il debug locale e le esecuzioni remote.
In questa esercitazione:
- Creare uno script di training.
- Usare Conda per definire un ambiente di Azure Machine Learning.
- Creare uno script di controllo.
- Comprendere le classi di Azure Machine Learning (
Environment,Run,Metrics). - Inviare ed eseguire lo script di training.
- Visualizzare l'output del codice nel cloud.
- Registrare le metriche in Azure Machine Learning.
- Visualizzare le metriche nel cloud.
Prerequisiti
- Completamento della parte 1 della serie.
Creare gli script di training
Per prima cosa, è necessario definire l'architettura della rete neurale in un file model.py. Tutto il codice di training viene inserito nella src sottodirectory, inclusa model.py.
Il codice di training è tratto da questo esempio introduttivo di PyTorch. I concetti di Azure Machine Learning si applicano a qualsiasi codice di Machine Learning, non solo a PyTorch.
Creare un file model.py nella sottocartella src. Copiare questo codice nel file:
import torch.nn as nn import torch.nn.functional as F class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(3, 6, 5) self.pool = nn.MaxPool2d(2, 2) self.conv2 = nn.Conv2d(6, 16, 5) self.fc1 = nn.Linear(16 * 5 * 5, 120) self.fc2 = nn.Linear(120, 84) self.fc3 = nn.Linear(84, 10) def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return xSelezionare Salva sulla barra degli strumenti per salvare il file. Chiudere la scheda, se lo si desidera.
Definire quindi lo script di training, anche nella sottocartella src. Questo script scarica il set di dati CIFAR10 usando le API
torchvision.datasetdi PyTorch, configura la rete definita in model.py e ne esegue il training per due periodi usando il metodo SGD standard e la perdita di entropia incrociata.Creare uno script train.py nella sottocartella src:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root="../data", train=True, download=True, transform=torchvision.transforms.ToTensor(), ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 print(f"epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}") running_loss = 0.0 print("Finished Training")A questo punto è disponibile la struttura di cartelle seguente:

Test in locale
Selezionare Salva ed esegui script nel terminale per eseguire lo script train.py direttamente nell'istanza di ambiente di calcolo.
Al completamento dello script, selezionare Aggiorna sopra le cartelle di file. Viene visualizzata la nuova cartella dati denominata get-started/data Espandi questa cartella per visualizzare i dati scaricati.

Creare un ambiente Python
Azure Machine Learning si basa sul concetto di ambiente per rappresentare un ambiente Python riproducibile e dotato di versione per l'esecuzione di esperimenti. La creazione di un ambiente da un ambiente Conda o pip locale è semplice.
Prima di tutto si crea un file con le dipendenze del pacchetto.
Creare un nuovo file nella cartella get-started denominato
pytorch-env.yml:name: pytorch-env channels: - defaults - pytorch dependencies: - python=3.7 - pytorch - torchvisionSelezionare Salva sulla barra degli strumenti per salvare il file. Chiudere la scheda, se lo si desidera.
Creare lo script di controllo
Rispetto allo script di controllo usato per inviare "Hello World", nello script seguente sono state aggiunte altre due righe per impostare l'ambiente.
Creare un nuovo file Python nella cartella get-started denominato run-pytorch.py:
# run-pytorch.py
from azureml.core import Workspace
from azureml.core import Experiment
from azureml.core import Environment
from azureml.core import ScriptRunConfig
if __name__ == "__main__":
ws = Workspace.from_config()
experiment = Experiment(workspace=ws, name='day1-experiment-train')
config = ScriptRunConfig(source_directory='./src',
script='train.py',
compute_target='cpu-cluster')
# set up pytorch environment
env = Environment.from_conda_specification(
name='pytorch-env',
file_path='pytorch-env.yml'
)
config.run_config.environment = env
run = experiment.submit(config)
aml_url = run.get_portal_url()
print(aml_url)
Suggerimento
Se è stato usato un nome diverso al momento della creazione del cluster di elaborazione, assicurarsi di modificare il nome anche nel codice compute_target='cpu-cluster'.
Informazioni sulle modifiche al codice
env = ...
Fa riferimento al file delle dipendenze creato in precedenza.
config.run_config.environment = env
Aggiunge l'ambiente a ScriptRunConfig.
Inviare l'esecuzione ad Azure Machine Learning
Selezionare Salva ed esegui script nel terminale per eseguire lo script run-pytorch.py.
Viene visualizzato un collegamento nella finestra del terminale visualizzata. Selezionare il collegamento per visualizzare il processo.
Nota
È possibile che vengano visualizzati alcuni avvisi che iniziano con Errore durante il caricamento di azureml_run_type_providers. È possibile ignorare tali avvisi. Usare il collegamento presente nella parte inferiore di questi avvisi per visualizzare l'output.
Visualizzare l'output
- Nella pagina visualizzata viene visualizzato lo stato del processo. La prima volta che si esegue questo script, Azure Machine Learning compila una nuova immagine Docker dall'ambiente PyTorch. Il completamento dell'intero processo può richiedere circa 10 minuti. Questa immagine verrà riutilizzata in processi futuri per velocizzarne l'esecuzione.
- È possibile visualizzare i log di compilazione di Docker nello studio di Azure Machine Learning. per visualizzare i log di compilazione:
- Selezionare la scheda Output e log.
- Selezionare la cartella azureml-logs .
- Selezionare 20_image_build_log.txt.
- Quando lo stato del processo è Completato, selezionare Output e log.
- Selezionare user_logs, quindi std_log.txt per visualizzare l'output del processo.
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ../data/cifar-10-python.tar.gz
Extracting ../data/cifar-10-python.tar.gz to ../data
epoch=1, batch= 2000: loss 2.19
epoch=1, batch= 4000: loss 1.82
epoch=1, batch= 6000: loss 1.66
...
epoch=2, batch= 8000: loss 1.51
epoch=2, batch=10000: loss 1.49
epoch=2, batch=12000: loss 1.46
Finished Training
Se viene visualizzato l'errore Your total snapshot size exceeds the limit, significa che la cartella data si trova nel valore source_directory usato in ScriptRunConfig.
Selezionare ... alla fine della cartella e quindi selezionare Sposta per spostare data nella cartella get-started.
Registrare le metriche di training
Dopo aver creato un training del modello in Azure Machine Learning, è possibile iniziare a tenere traccia di alcune metriche delle prestazioni.
Lo script di training corrente stampa le metriche nel terminale. Azure Machine Learning offre un meccanismo per registrare le metriche con più funzionalità. Aggiungendo alcune righe di codice, è possibile visualizzare le metriche nello studio e confrontarle tra più processi.
Modificare train.py per includere la registrazione
Modificare lo script train.py in modo da includere altre due righe di codice:
import torch import torch.optim as optim import torchvision import torchvision.transforms as transforms from model import Net from azureml.core import Run # ADDITIONAL CODE: get run from the current context run = Run.get_context() # download CIFAR 10 data trainset = torchvision.datasets.CIFAR10( root='./data', train=True, download=True, transform=torchvision.transforms.ToTensor() ) trainloader = torch.utils.data.DataLoader( trainset, batch_size=4, shuffle=True, num_workers=2 ) if __name__ == "__main__": # define convolutional network net = Net() # set up pytorch loss / optimizer criterion = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # train the network for epoch in range(2): running_loss = 0.0 for i, data in enumerate(trainloader, 0): # unpack the data inputs, labels = data # zero the parameter gradients optimizer.zero_grad() # forward + backward + optimize outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() # print statistics running_loss += loss.item() if i % 2000 == 1999: loss = running_loss / 2000 # ADDITIONAL CODE: log loss metric to AML run.log('loss', loss) print(f'epoch={epoch + 1}, batch={i + 1:5}: loss {loss:.2f}') running_loss = 0.0 print('Finished Training')Fare clic su Salva per salvare il file e quindi chiudere la scheda, se lo si desidera.
Informazioni sulle due righe di codice aggiuntive
In train.py si accede all'oggetto run dall'interno dello script di training tramite il metodo Run.get_context() e lo si usa per registrare le metriche:
# ADDITIONAL CODE: get run from the current context
run = Run.get_context()
...
# ADDITIONAL CODE: log loss metric to AML
run.log('loss', loss)
Le metriche in Azure Machine Learning sono:
- Organizzate per esperimento ed esecuzione, per cui è facile tenerne traccia e confrontarle.
- Dotate di interfaccia utente per poter visualizzare le prestazioni del training in Studio.
- Progettate per la scalabilità, per continuare a sfruttare questi vantaggi anche quando si eseguono centinaia di esperimenti.
Aggiornare il file dell'ambiente Conda
Lo script train.py ha appena acquisito una nuova dipendenza da azureml.core. Aggiornare pytorch-env.yml in modo da riflettere questa modifica:
name: pytorch-env
channels:
- defaults
- pytorch
dependencies:
- python=3.7
- pytorch
- torchvision
- pip
- pip:
- azureml-sdk
Assicurarsi di salvare il file prima di inviare l'esecuzione.
Inviare l'esecuzione ad Azure Machine Learning
Selezionare la scheda per lo script run-pytorch.py , quindi selezionare Salva ed esegui script nel terminale per eseguire nuovamente lo script run-pytorch.py . Assicurarsi di salvare prima le modifiche apportate pytorch-env.yml .
Questa volta, quando si visita Studio, passare alla scheda Metriche, dove è ora possibile visualizzare gli aggiornamenti dinamici sulla perdita di training del modello. Potrebbero essere necessari 1 o 2 minuti prima che il training abbia inizio.

Pulire le risorse
Se si prevede di continuare ora a un'altra esercitazione o di avviare i propri processi di training, passare a Risorse correlate.
Arrestare l'istanza di ambiente di calcolo
Se non si intende usarla, arrestare l'istanza di ambiente di calcolo:
- Nello studio, a sinistra, selezionare Ambiente di calcolo.
- Nelle schede in alto selezionare Istanze di ambiente di calcolo
- Selezionare l'istanza di ambiente di calcolo nell'elenco.
- Sulla barra degli strumenti in alto selezionare Arresta.
Eliminare tutte le risorse
Importante
Le risorse create possono essere usate come prerequisiti per altre esercitazioni e procedure dettagliate per Azure Machine Learning.
Se le risorse create non servono più, eliminarle per evitare addebiti:
Nel portale di Azure fare clic su Gruppi di risorse all'estrema sinistra.
Nell'elenco selezionare il gruppo di risorse creato.
Selezionare Elimina gruppo di risorse.
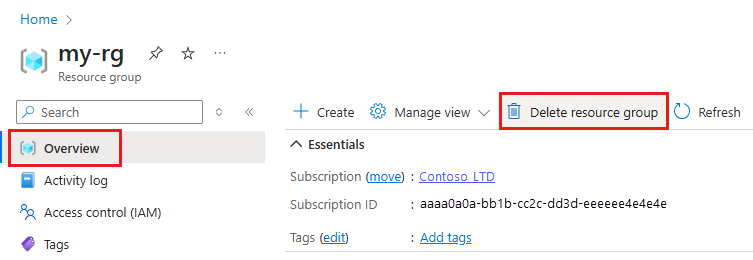
Immettere il nome del gruppo di risorse. Quindi seleziona Elimina.
È anche possibile mantenere il gruppo di risorse ma eliminare una singola area di lavoro. Visualizzare le proprietà dell'area di lavoro e selezionare Elimina.
Risorse correlate
In questa sessione si è passati da uno script "Hello world!" di base a uno script di training più realistico che per l'esecuzione ha richiesto un ambiente Python specifico. Si è visto anche come usare ambienti di Azure Machine Learning curati. Si è infine visto come con poche righe di codice sia possibile registrare le metriche in Azure Machine Learning.
Esistono altri modi per creare ambienti di Azure Machine Learning, ad esempio da un file pip requirements.txt o anche da un ambiente Conda locale esistente.