Risolvere i problemi di latenza di replica in Database di Azure per MySQL - Server flessibile
SI APPLICA A: Database di Azure per MySQL - Server singolo Database di Azure per MySQL - Server flessibile
Database di Azure per MySQL - Server singolo Database di Azure per MySQL - Server flessibile
Importante
Database di Azure per MySQL server singolo si trova nel percorso di ritiro. È consigliabile eseguire l'aggiornamento a Database di Azure per MySQL server flessibile. Per altre informazioni sulla migrazione a Database di Azure per MySQL server flessibile, vedere Che cosa accade a Database di Azure per MySQL server singolo?
Nota
Questo articolo fa riferimento a un termine che Microsoft non usa più. Quando il termine verrà rimosso dal software, verrà rimosso anche dall'articolo.
La funzionalità di replica in lettura consente di replicare i dati da un server Database di Azure per MySQL a un server di replica di sola lettura. È possibile aumentare le istanze dei carichi di lavoro instradando le query di lettura e creazione di report dall'applicazione ai server di replica. Questa configurazione riduce la pressione sul server di origine e migliora le prestazioni e la latenza complessive dell'applicazione durante la scalabilità.
Le repliche vengono aggiornate in modo asincrono usando la tecnologia di replica basata sulla posizione del file binario nativo del motore MySQL (binlog). Per altre informazioni, vedere Panoramica della configurazione della replica basata sulla posizione del file binlog mySQL.
Il ritardo di replica nelle repliche di lettura secondarie dipende da diversi fattori. Questi fattori includono, ma non sono limitati a:
- Latenza di rete.
- Volume delle transazioni nel server di origine.
- Livello di calcolo del server di origine e del server di replica in lettura secondario.
- Query in esecuzione nel server di origine e nel server secondario.
Questo articolo illustra come risolvere i problemi di latenza di replica in Database di Azure per MySQL. Si otterrà anche un'idea migliore di alcune cause comuni di una maggiore latenza di replica nei server di replica.
Nota
Questo articolo contiene riferimenti al termine slave, che Microsoft non usa più. Quando il termine verrà rimosso dal software, verrà rimosso anche dall'articolo.
Concetti relativi alla replica
Quando un log binario è abilitato, il server di origine scrive le transazioni di cui è stato eseguito il commit nel log binario. Il log binario viene usato per la replica. È attivato per impostazione predefinita per tutti i server di cui è stato appena effettuato il provisioning che supportano fino a 16 TB di spazio di archiviazione. Nei server di replica due thread vengono eseguiti in ogni server di replica. Un thread è il thread di I/O e l'altro è il thread SQL:
- Il thread di I/O si connette al server di origine e richiede log binari aggiornati. Questo thread riceve gli aggiornamenti del log binario. Tali aggiornamenti vengono salvati in un server di replica, in un log locale denominato log di inoltro.
- Il thread SQL legge il log di inoltro e quindi applica le modifiche ai dati nei server di replica.
Monitoraggio della latenza di replica
Database di Azure per MySQL fornisce la metrica per il ritardo della replica in secondi Monitoraggio di Azure. Questa metrica è disponibile solo nei server di replica in lettura. Viene calcolato dalla metrica seconds_behind_master disponibile in MySQL.
Per comprendere la causa di una maggiore latenza di replica, connettersi al server di replica usando MySQL Workbench o Azure Cloud Shell. Eseguire quindi il comando seguente.
Nota
Nel codice sostituire i valori di esempio con il nome del server di replica e il nome utente amministratore. Il nome utente amministratore richiede @\<servername> per Database di Azure per MySQL.
mysql --host=myreplicademoserver.mysql.database.azure.com --user=myadmin@mydemoserver -p
Ecco come si presenta l'esperienza nel terminale di Cloud Shell:
Requesting a Cloud Shell.Succeeded.
Connecting terminal...
Welcome to Azure Cloud Shell
Type "az" to use Azure CLI
Type "help" to learn about Cloud Shell
user@Azure:~$mysql -h myreplicademoserver.mysql.database.azure.com -u myadmin@mydemoserver -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 64796
Server version: 5.6.42.0 Source distribution
Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
Nello stesso terminale di Cloud Shell eseguire il comando seguente:
mysql> SHOW SLAVE STATUS;
Ecco un output tipico:
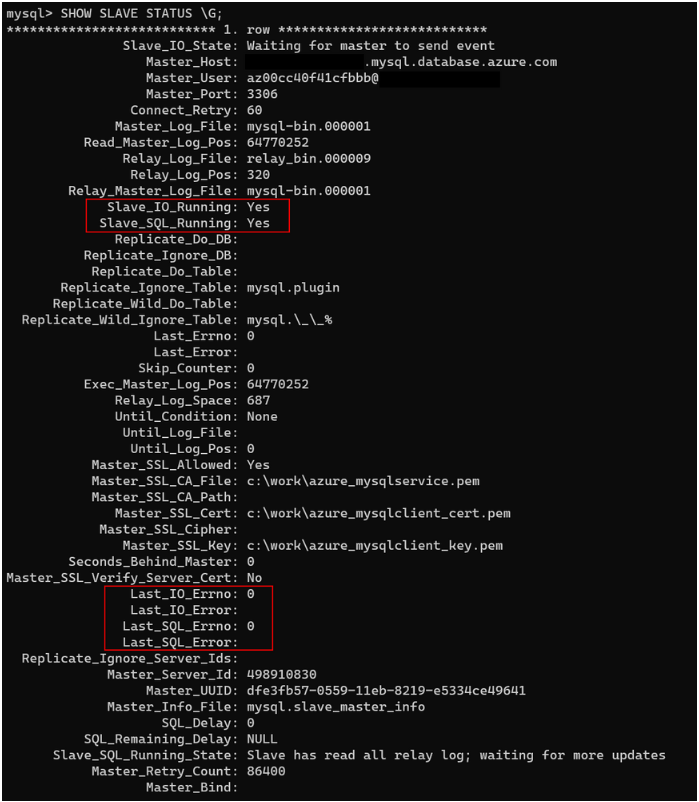
L'output contiene numerose informazioni. In genere, è necessario concentrarsi solo sulle righe descritte nella tabella seguente.
| Metrico | Descrizione |
|---|---|
| Slave_IO_State | Rappresenta lo stato corrente del thread di I/O. In genere, lo stato è "In attesa dell'invio dell'evento master" se il server di origine (master) sta sincronizzando. Uno stato come "Connessione ing to master" indica che la replica ha perso la connessione al server di origine. Verificare che il server di origine sia in esecuzione o verificare se un firewall blocca la connessione. |
| Master_Log_File | Rappresenta il file di log binario in cui sta scrivendo il server di origine. |
| Read_Master_Log_Pos | Indica dove il server di origine sta scrivendo nel file di log binario. |
| Relay_Master_Log_File | Rappresenta il file di log binario che il server di replica sta leggendo dal server di origine. |
| Slave_IO_Running | Indica se il thread di I/O è in esecuzione. Il valore deve essere Yes. Se il valore è NO, è probabile che la replica venga interrotta. |
| Slave_SQL_Running | Indica se il thread SQL è in esecuzione. Il valore deve essere Yes. Se il valore è NO, è probabile che la replica venga interrotta. |
| Exec_Master_Log_Pos | Indica la posizione del Relay_Master_Log_File che la replica sta applicando. Se è presente una latenza, questa sequenza di posizione deve essere inferiore a Read_Master_Log_Pos. |
| Relay_Log_Space | Indica la dimensione totale combinata di tutti i file di log di inoltro esistenti. È possibile controllare le dimensioni massime del limite eseguendo SHOW GLOBAL VARIABLES query come relay_log_space_limit. |
| Seconds_Behind_Master | Visualizza la latenza di replica in secondi. |
| Last_IO_Errno | Visualizza il codice di errore del thread di I/O, se presente. Per altre informazioni su questi codici, vedere le informazioni di riferimento sui messaggi di errore del server MySQL. |
| Last_IO_Error | Visualizza il messaggio di errore del thread di I/O, se presente. |
| Last_SQL_Errno | Visualizza il codice di errore del thread SQL, se presente. Per altre informazioni su questi codici, vedere le informazioni di riferimento sui messaggi di errore del server MySQL. |
| Last_SQL_Error | Visualizza il messaggio di errore del thread SQL, se presente. |
| Slave_SQL_Running_State | Indica lo stato corrente del thread SQL. In questo stato, System lock è normale. È anche normale visualizzare lo stato di Waiting for dependent transaction to commit. Questo stato indica che la replica è in attesa di altri thread di lavoro SQL per aggiornare le transazioni di cui è stato eseguito il commit. |
Se Slave_IO_Running è Yes e Slave_SQL_Running è Yes, la replica viene eseguita correttamente.
Selezionare quindi Last_IO_Errno, Last_IO_Error, Last_SQL_Errno e Last_SQL_Error. Questi campi visualizzano il numero di errore e il messaggio di errore dell'errore più recente che ha causato l'arresto del thread SQL. Un numero di errore di 0 e un messaggio vuoto indica che non è presente alcun errore. Esaminare qualsiasi valore di errore diverso da zero controllando il codice di errore nel riferimento al messaggio di errore del server MySQL.
Scenari comuni per la latenza di replica elevata
Le sezioni seguenti illustrano gli scenari in cui la latenza di replica elevata è comune.
Latenza di rete o utilizzo elevato della CPU nel server di origine
Se vengono visualizzati i valori seguenti, è probabile che la latenza di replica sia causata da una latenza di rete elevata o da un utilizzo elevato della CPU nel server di origine.
Slave_IO_State: Waiting for master to send event
Master_Log_File: the binary file sequence is larger then Relay_Master_Log_File, e.g. mysql-bin.00020
Relay_Master_Log_File: the file sequence is smaller than Master_Log_File, e.g. mysql-bin.00010
In questo caso, il thread di I/O è in esecuzione e è in attesa nel server di origine. Il server di origine è già stato scritto nel file di log binario numero 20. La replica ha ricevuto solo fino al numero di file 10. I fattori principali per una latenza di replica elevata in questo scenario sono la velocità di rete o l'utilizzo elevato della CPU nel server di origine.
In Azure la latenza di rete all'interno di un'area può in genere essere misurata in millisecondi. Tra aree, la latenza varia da millisecondi a secondi.
Nella maggior parte dei casi, il ritardo di connessione tra i thread di I/O e il server di origine è causato da un utilizzo elevato della CPU nel server di origine. I thread di I/O vengono elaborati lentamente. È possibile rilevare questo problema usando Monitoraggio di Azure per controllare l'utilizzo della CPU e il numero di connessioni simultanee nel server di origine.
Se non viene visualizzato un utilizzo elevato della CPU nel server di origine, il problema potrebbe essere latenza di rete. Se la latenza di rete è improvvisamente elevata, controllare la pagina relativa allo stato di Azure per individuare problemi noti o interruzioni.
Picchi elevati di transazioni nel server di origine
Se vengono visualizzati i valori seguenti, è probabile che un picco elevato di transazioni nel server di origine causi la latenza di replica.
Slave_IO_State: Waiting for the slave SQL thread to free enough relay log space
Master_Log_File: the binary file sequence is larger then Relay_Master_Log_File, e.g. mysql-bin.00020
Relay_Master_Log_File: the file sequence is smaller then Master_Log_File, e.g. mysql-bin.00010
L'output mostra che la replica può recuperare il log binario dietro il server di origine. Tuttavia, il thread di I/O di replica indica che lo spazio del log di inoltro è già pieno.
La velocità di rete non causa il ritardo. La replica sta tentando di recuperare. Tuttavia, le dimensioni del log binario aggiornate superano il limite superiore dello spazio del log di inoltro.
Per risolvere questo problema, abilitare il log delle query lente nel server di origine. Usare i log di query lente per identificare le transazioni a esecuzione prolungata nel server di origine. Ottimizzare quindi le query identificate per ridurre la latenza nel server.
La latenza di replica di questo ordinamento è in genere causata dal caricamento dei dati nel server di origine. Quando i server di origine hanno carichi di dati settimanali o mensili, la latenza di replica è purtroppo inevitabile. I server di replica alla fine si aggiornano al termine del caricamento dei dati nel server di origine.
Lentezza nel server di replica
Se si osservano i valori seguenti, il problema potrebbe trovarsi nel server di replica.
Slave_IO_State: Waiting for master to send event
Master_Log_File: The binary log file sequence equals to Relay_Master_Log_File, e.g. mysql-bin.000191
Read_Master_Log_Pos: The position of master server written to the above file is larger than Relay_Log_Pos, e.g. 103978138
Relay_Master_Log_File: mysql-bin.000191
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Exec_Master_Log_Pos: The position of slave reads from master binary log file is smaller than Read_Master_Log_Pos, e.g. 13468882
Seconds_Behind_Master: There is latency and the value here is greater than 0
In questo scenario, l'output mostra che sia il thread di I/O che il thread SQL sono in esecuzione correttamente. La replica legge lo stesso file di log binario scritto dal server di origine. Tuttavia, una certa latenza nel server di replica riflette la stessa transazione dal server di origine.
Le sezioni seguenti descrivono le cause comuni di questo tipo di latenza.
Nessuna chiave primaria o chiave univoca in una tabella
Database di Azure per MySQL usa la replica basata su righe. Il server di origine scrive gli eventi nel log binario, registrando le modifiche nelle singole righe della tabella. Il thread SQL replica quindi tali modifiche alle righe di tabella corrispondenti nel server di replica. Quando una tabella non dispone di una chiave primaria o di una chiave univoca, il thread SQL analizza tutte le righe nella tabella di destinazione per applicare le modifiche. Questa analisi può causare la latenza di replica.
In MySQL la chiave primaria è un indice associato che garantisce prestazioni di query veloci perché non può includere valori NULL. Se si usa il motore di archiviazione InnoDB, i dati della tabella sono organizzati fisicamente per eseguire ricerche e ordinamenti ultra veloci in base alla chiave primaria.
È consigliabile aggiungere una chiave primaria nelle tabelle nel server di origine prima di creare il server di replica. Aggiungere chiavi primarie nel server di origine e quindi ricreare le repliche di lettura per migliorare la latenza di replica.
Usare la query seguente per scoprire quali tabelle mancano una chiave primaria nel server di origine:
select tab.table_schema as database_name, tab.table_name
from information_schema.tables tab left join
information_schema.table_constraints tco
on tab.table_schema = tco.table_schema
and tab.table_name = tco.table_name
and tco.constraint_type = 'PRIMARY KEY'
where tco.constraint_type is null
and tab.table_schema not in('mysql', 'information_schema', 'performance_schema', 'sys')
and tab.table_type = 'BASE TABLE'
order by tab.table_schema, tab.table_name;
Query con esecuzione prolungata nel server di replica
Il carico di lavoro nel server di replica può fare in modo che il thread SQL si trovi dietro il thread di I/O. Le query con esecuzione prolungata nel server di replica sono una delle cause comuni della latenza di replica elevata. Per risolvere questo problema, abilitare il log di query lento nel server di replica.
Le query lente possono aumentare il consumo delle risorse o rallentare il server in modo che la replica non riesca a raggiungere il server di origine. In questo scenario, ottimizzare le query lente. Le query più veloci impediscono il blocco del thread SQL e migliorano significativamente la latenza di replica.
Query DDL nel server di origine
Nel server di origine un comando DDL (Data Definition Language) può ALTER TABLE richiedere molto tempo. Mentre il comando DDL è in esecuzione, migliaia di altre query potrebbero essere in esecuzione in parallelo nel server di origine.
Quando il DDL viene replicato, per garantire la coerenza del database, il motore MySQL esegue il DDL in un singolo thread di replica. Durante questa attività, tutte le altre query replicate vengono bloccate e devono attendere il completamento dell'operazione DDL nel server di replica. Anche le operazioni DDL online causano questo ritardo. Le operazioni DDL aumentano la latenza di replica.
Se è stato abilitato il log delle query lente nel server di origine, è possibile rilevare questo problema di latenza controllando la presenza di un comando DDL eseguito nel server di origine. Tramite l'eliminazione dell'indice, la ridenominazione e la creazione, è possibile usare l'algoritmo INPLACE per ALTER TABLE. Potrebbe essere necessario copiare i dati della tabella e ricompilare la tabella.
In genere, il linguaggio DML simultaneo è supportato per l'algoritmo INPLACE. Tuttavia, è possibile eseguire brevemente un blocco esclusivo dei metadati nella tabella quando si prepara ed esegue l'operazione. Pertanto, per l'istruzione CREATE INDEX, è possibile usare le clausole ALGORITHM e LOCK per influenzare il metodo per la copia della tabella e il livello di concorrenza per la lettura e la scrittura. È comunque possibile impedire operazioni DML aggiungendo un indice FULLTEXT o un indice SPATIAL.
Nell'esempio seguente viene creato un indice utilizzando clausole ALGORITHM e LOCK.
ALTER TABLE table_name ADD INDEX index_name (column), ALGORITHM=INPLACE, LOCK=NONE;
Sfortunatamente, per un'istruzione DDL che richiede un blocco, non è possibile evitare la latenza di replica. Per ridurre i potenziali effetti, eseguire questi tipi di operazioni DDL durante le ore di minore attività, ad esempio durante la notte.
Server di replica con downgrade
In Database di Azure per MySQL le repliche in lettura usano la stessa configurazione del server di origine. È possibile modificare la configurazione del server di replica dopo la creazione.
Se viene effettuato il downgrade del server di replica, il carico di lavoro può usare più risorse, che a sua volta può causare la latenza di replica. Per rilevare questo problema, usare Monitoraggio di Azure per controllare il consumo di CPU e memoria del server di replica.
In questo scenario è consigliabile mantenere la configurazione del server di replica con valori uguali o superiori ai valori del server di origine. Questa configurazione consente alla replica di rimanere al passo con il server di origine.
Miglioramento della latenza di replica ottimizzando i parametri del server di origine
In Database di Azure per MySQL, per impostazione predefinita, la replica è ottimizzata per l'esecuzione con thread paralleli nelle repliche. Quando i carichi di lavoro a concorrenza elevata nel server di origine causano il calo del server di replica, è possibile migliorare la latenza di replica configurando il parametro binlog_group_commit_sync_delay nel server di origine.
Il parametro binlog_group_commit_sync_delay controlla il numero di microsecondi di attesa del commit del log binario prima della sincronizzazione del file di log binario. Il vantaggio di questo parametro è che invece di applicare immediatamente ogni transazione di cui è stato eseguito il commit, il server di origine invia gli aggiornamenti del log binario in blocco. Questo ritardo riduce l'I/O nella replica e consente di migliorare le prestazioni.
Potrebbe essere utile impostare il parametro binlog_group_commit_sync_delay su 1000 o così via. Monitorare quindi la latenza di replica. Impostare questo parametro con cautela e usarlo solo per carichi di lavoro a concorrenza elevata.
Importante
Nel server di replica binlog_group_commit_sync_delay parametro è consigliabile essere 0. Questa operazione è consigliata perché, a differenza del server di origine, il server di replica non avrà concorrenza elevata e l'aumento del valore per binlog_group_commit_sync_delay nel server di replica potrebbe causare inavvertitamente un aumento del ritardo della replica.
Per i carichi di lavoro a bassa concorrenza che includono molte transazioni singleton, l'impostazione binlog_group_commit_sync_delay può aumentare la latenza. La latenza può aumentare perché il thread di I/O attende gli aggiornamenti del log binario bulk anche se viene eseguito il commit solo di alcune transazioni.
Opzioni avanzate per la risoluzione dei problemi
Se si usa il comando show slave status non fornisce informazioni sufficienti per risolvere i problemi di latenza di replica, provare a visualizzare queste opzioni aggiuntive per informazioni sui processi attivi o in attesa.
Visualizzare la tabella thread
La performance_schema.threads tabella mostra lo stato del processo. Un processo con lo stato In attesa di lock_type blocco indica che è presente un blocco su una delle tabelle, impedendo al thread di replica di aggiornare la tabella.
SELECT name, processlist_state, processlist_time FROM performance_schema.threads WHERE name LIKE '%slave%';
Per altre informazioni, vedere General Thread States.For more information, see General Thread States.
Visualizzare la tabella replication_connection_status
La tabella performance_schema.replication_connection_status mostra lo stato corrente del thread di I/O di replica che gestisce la connessione della replica all'origine e cambia più frequentemente. La tabella contiene valori che variano durante la connessione.
SELECT * FROM performance_schema.replication_connection_status;
Visualizzare la tabella replication_applier_status_by_worker
La performance_schema.replication_applier_status_by_worker tabella mostra lo stato dei thread di lavoro, Ultima transazione visualizzata insieme all'ultimo numero di errore e messaggio, che consentono di trovare la transazione con problemi e identificare la causa radice.
È possibile eseguire i comandi seguenti nella replica dati in modo da ignorare errori o transazioni:
az_replication_skip_counter
oppure
az_replication_skip_gtid_transaction
SELECT * FROM performance_schema.replication_applier_status_by_worker;
Visualizzare l'istruzione SHOW RELAYLOG EVENTS
L'istruzione show relaylog events mostra gli eventi nel log di inoltro di una replica.
· Per la replica basata su GITD (replica in lettura), l'istruzione mostra la transazione GTID e il file binlog e la relativa posizione, è possibile usare mysqlbinlog per ottenere il contenuto e le istruzioni in esecuzione. · Per la replica della posizione binlog di MySQL (usata per la replica di dati in ingresso), vengono visualizzate le istruzioni in esecuzione, che consentono di sapere in quali transazioni di tabella vengono eseguite
Controllare l'output di Monitoraggio standard e monitoraggio blocchi innoDB
È anche possibile provare a controllare l'output di Monitoraggio standard innoDB e Monitoraggio blocchi per risolvere i blocchi e i deadlock e ridurre al minimo il ritardo della replica. Il monitoraggio blocchi è uguale a Quello standard, ad eccezione del fatto che include informazioni aggiuntive sul blocco. Per visualizzare queste informazioni aggiuntive sul blocco e sul deadlock, eseguire il comando show engine innodb status\G.
Passaggi successivi
Vedere la panoramica della replica binlog di MySQL.