Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
La Cache intelligente funziona perfettamente in background e memorizza nella cache i dati per velocizzare l'esecuzione di Spark durante la lettura dal data lake ADLS Gen2. Rileva automaticamente anche le modifiche apportate ai file sottostanti e aggiorna automaticamente i file nella cache, fornendo i dati più recenti e quando la dimensione della cache raggiunge il limite, la cache rilascia automaticamente i dati meno letti per creare spazio per i dati più recenti. Questa funzionalità riduce il costo totale di proprietà migliorando le prestazioni fino a 65% nelle letture successive dei file archiviati nella cache disponibile per i file Parquet e 50% per i file CSV.
Quando si esegue una query su un file o una tabella dal data lake, il motore Apache Spark in Synapse eseguirà una chiamata all'archiviazione ADLS Gen2 remota per leggere i file sottostanti. Con ogni richiesta di query per leggere gli stessi dati, il motore Spark deve effettuare una chiamata all'archiviazione ADLS Gen2 remota. Questo processo ridondante aggiunge latenza al tempo di elaborazione totale. Spark offre una funzionalità di memorizzazione nella cache che è necessario impostare manualmente la cache e rilasciare la cache per ridurre al minimo la latenza e migliorare le prestazioni complessive. Tuttavia, ciò può causare la presenza di dati non aggiornati se i dati sottostanti cambiano.
Synapse Intelligent Cache semplifica questo processo memorizzando nella cache automaticamente ogni lettura all'interno dello spazio di archiviazione della cache allocato in ogni nodo Spark. Ogni richiesta di un file verificherà se il file esiste nella cache e confronterà il tag dalla risorsa di archiviazione remota per determinare se il file non è aggiornato. Se il file non esiste o se il file non è aggiornato, Spark leggerà il file e lo archivierà nella cache. Quando la cache diventa piena, il file con l'ora dell'ultimo accesso meno recente verrà rimosso dalla cache per consentire file più recenti.
La cache Synapse è una singola cache per nodo. Se si usa un nodo di dimensioni medie ed eseguito con due executor di piccole dimensioni in un singolo nodo di dimensioni medie, questi due executor condividono la stessa cache.
Abilitare o disabilitare la cache
Le dimensioni della cache possono essere modificate in base alla percentuale delle dimensioni totali del disco disponibili per ogni pool di Apache Spark. Per impostazione predefinita, la cache è disabilitata, ma è semplice come spostare la barra del dispositivo di scorrimento da 0 (disabilitato) alla percentuale desiderata per la dimensione della cache per abilitarla. Riserviamo almeno il 20% dello spazio su disco disponibile per i rimescolamenti dei dati. Per i carichi di lavoro con elevata intensità di shuffle, è possibile ridurre al minimo le dimensioni della cache o disabilitare la cache. È consigliabile iniziare con una dimensione della cache di 50% e regolare in base alle esigenze. È importante notare che se il carico di lavoro richiede molto spazio su disco nell'unità SSD locale per la memorizzazione casuale o la memorizzazione nella cache RDD, è consigliabile ridurre le dimensioni della cache per ridurre la probabilità di errore a causa di un'archiviazione insufficiente. Le dimensioni effettive dell'archiviazione disponibile e delle dimensioni della cache in ogni nodo dipendono dalla famiglia di nodi e dalle dimensioni del nodo.
Abilitazione della cache per i nuovi pool di Spark
Quando si crea un nuovo Spark pool, passare nella scheda Impostazioni aggiuntive per trovare il cursore Intelligent Cache da spostare alla dimensione preferita per abilitare la funzionalità.

Abilitazione/disabilitazione della cache per i pool di Spark esistenti
Per i pool di Spark esistenti, accedere alle impostazioni di scalabilità del pool di Apache Spark a scelta per abilitarlo, spostando il cursore su un valore maggiore di 0, o disabilitarlo, spostando il cursore su 0.
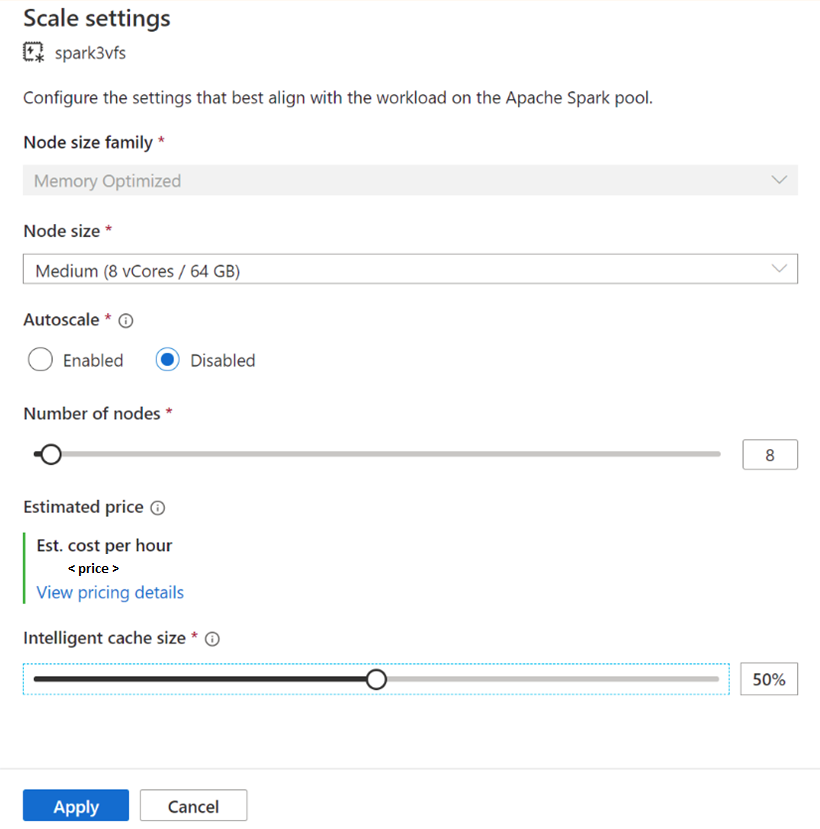
Modifica delle dimensioni della cache per i pool di Spark esistenti
Per modificare le dimensioni della cache intelligente di un pool, è necessario forzare un riavvio se il pool dispone di sessioni attive. Se il pool di Spark ha una sessione attiva, verrà mostrata l'opzione Forza nuove impostazioni. Fare clic sulla casella di controllo e selezionare Applica per riavviare automaticamente la sessione.

Abilitazione e disabilitazione della cache all'interno della sessione
Disabilitare facilmente la cache intelligente all'interno di una sessione eseguendo il codice seguente nel notebook:
%spark
spark.conf.set("spark.synapse.vegas.useCache", "false")
%pyspark
spark.conf.set('spark.synapse.vegas.useCache', 'false')
Abilitalo eseguendo:
%spark
spark.conf.set("spark.synapse.vegas.useCache", "true")
%pyspark
spark.conf.set('spark.synapse.vegas.useCache', 'true')
Quando usare la cache intelligente e quando no?
Questa funzionalità sarà utile se:
Il carico di lavoro richiede la lettura dello stesso file più volte e le dimensioni del file possono rientrare nella cache.
Il carico di lavoro utilizza tabelle Delta, formati di file Parquet e file CSV.
Stai utilizzando Apache Spark 3 o una versione più recente su Azure Synapse.
Non si noterà il vantaggio di questa funzionalità se:
Si sta leggendo un file che supera le dimensioni della cache, poiché l'inizio dei file potrebbe essere rimosso e le query successive dovranno recuperare i dati dalla memoria di archiviazione remota. In questo caso, non si noterà alcun vantaggio dalla cache intelligente ed è possibile aumentare le dimensioni della cache e/o le dimensioni del nodo.
Il carico di lavoro richiede grandi quantità di shuffle, quindi la disabilitazione della cache intelligente libera spazio disponibile per evitare che il processo non riesca a causa di spazio di archiviazione insufficiente.
Si usa un pool di Spark 3.3, è necessario aggiornare il pool alla versione più recente di Spark.
Ulteriori informazioni
Per altre informazioni su Apache Spark, vedere gli articoli seguenti:
- Che cos'è Apache Spark
- Concetti di base di Apache Spark
- Dimensioni e configurazioni del pool di Apache Spark
Per informazioni sulla configurazione delle impostazioni della sessione Spark
- Configurare le impostazioni della sessione Spark
- Come impostare configurazioni personalizzate di Spark/Pyspark
Passaggi successivi
Un pool di Apache Spark offre funzionalità di calcolo big data open source in cui i dati possono essere caricati, modellati, elaborati e distribuiti per ottenere informazioni analitiche più veloci. Per altre informazioni su come crearne uno per eseguire i carichi di lavoro Spark, vedere le esercitazioni seguenti: