Nota
L'accesso a questa pagina richiede l'autorizzazione. Puoi provare ad accedere o a cambiare directory.
L'accesso a questa pagina richiede l'autorizzazione. Puoi provare a cambiare directory.
I bundle di asset di Databricks possono essere creati e modificati direttamente nell'area di lavoro.
Per i requisiti sull'utilizzo dei pacchetti nell'area di lavoro, consultare Requisiti dell'area di lavoro per i pacchetti di asset di Databricks.
Per altre informazioni sui bundle, vedere Che cosa sono i bundle di asset di Databricks?.
Creare un pacchetto
Per creare un bundle nell'area di lavoro Databricks:
Passare alla cartella Git in cui si vuole creare il bundle.
Fare clic sul pulsante Crea e quindi su Bundle asset. In alternativa, fare clic con il pulsante destro del mouse sulla cartella Git o sul kebab associato nell'albero dell'area di lavoro e scegliere Crea>bundle di asset:
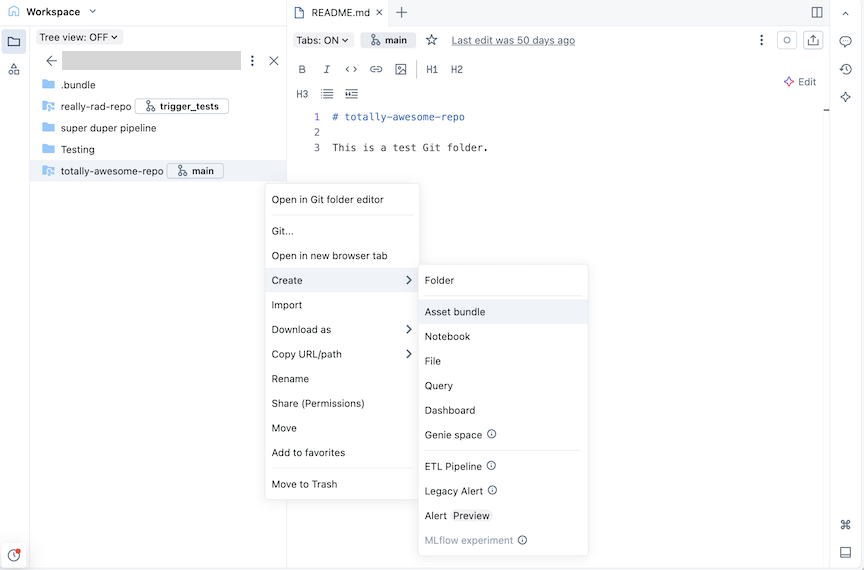
Nella finestra di dialogo Crea un bundle di asset, assegna un nome al bundle di asset, ad esempio totally-awesome-bundle. Il nome del bundle può contenere solo lettere, numeri, trattini e caratteri di sottolineatura.
Per Modello scegliere se si vuole creare un bundle vuoto, un bundle che esegue un notebook Python di esempio o un bundle che esegue SQL. Se l'editor di Pipelines Lakeflow è abilitato, verrà visualizzata anche un'opzione per creare un progetto di pipeline ETL.
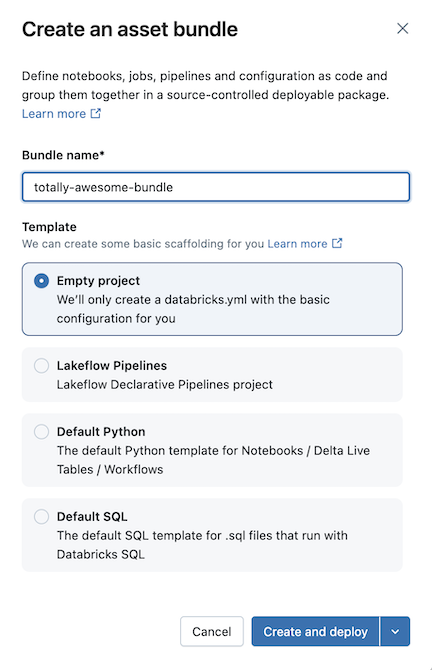
Alcuni modelli richiedono una configurazione aggiuntiva. Fare clic su Avanti per completare la configurazione del progetto.
Template Opzioni di configurazione Pipeline dichiarative di Lakeflow Spark - Catalogo predefinito da usare per i dati della pipeline
- Usare lo schema personale (scelta consigliata) per ogni utente che collabora a questo bundle
- Linguaggio iniziale per i file di codice nella pipeline
Python predefinito - Includere un notebook di esempio
- Includere una pipeline di esempio
- Includere un pacchetto Python di esempio
- Usare l'ambiente di calcolo serverless
SQL predefinito - Percorso del magazzino SQL
- Catalogo iniziale
- Usa schema personale
- Schema iniziale durante lo sviluppo
Fare clic su Crea e distribuisci.
Verrà creato un bundle iniziale nella cartella Git, che include i file per il modello di progetto selezionato, un .gitignore file di configurazione Git e il file di aggregazioni di asset di Databricks databricks.yml richiesto. Il databricks.yml file contiene la configurazione principale per il bundle. Per informazioni dettagliate, vedere Configurazione del bundle di asset di Databricks.
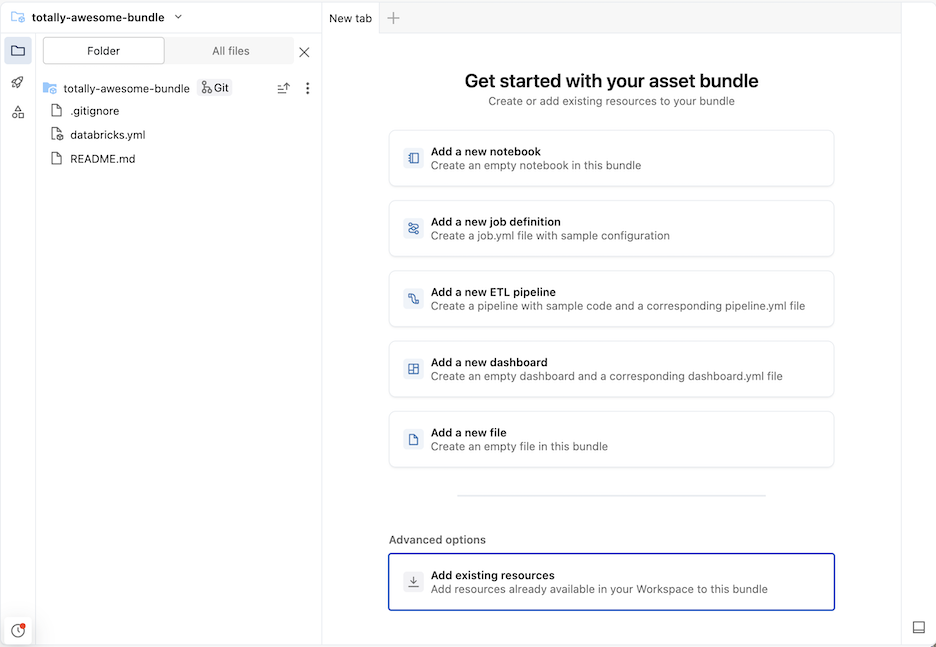
Tutte le modifiche apportate ai file all'interno del bundle possono essere sincronizzate con il repository remoto associato alla cartella Git. Una cartella Git può contenere molti bundle.
Aggiungere nuovi file a un bundle
Un bundle contiene il databricks.yml file che definisce configurazioni di distribuzione e area di lavoro, file di origine, ad esempio notebook, file Python e file di test, nonché definizioni e impostazioni per le risorse di Databricks, ad esempio Processi Lakeflow e Pipeline dichiarative di Lakeflow Spark. Analogamente a qualsiasi cartella dell'area di lavoro, è possibile aggiungere nuovi file al bundle.
Suggerimento
Per aprire una nuova scheda per la visualizzazione bundle che consente di modificare i file di bundle, passare alla cartella bundle nell'area di lavoro, quindi fare clic su Apri nell'editor a destra del nome del bundle.
Aggiungere file di codice sorgente
Per aggiungere nuovi notebook o altri file a un bundle nell'interfaccia utente dell'area di lavoro, passare alla cartella bundle e quindi:
- Fare clic su Crea in alto a destra e scegliere uno dei tipi di file seguenti da aggiungere al bundle: Notebook, File, Query, Dashboard.
- In alternativa, fare clic sul kebab a sinistra di Condividi e importare un file.
Annotazioni
Affinché il file faccia parte della distribuzione del bundle, dopo aver aggiunto un file alla cartella del bundle, è necessario aggiungerlo alla configurazione del databricks.yml bundle oppure creare un file di definizione di processo o pipeline che lo includa. Vedere Aggiungere una risorsa esistente a un bundle.
Creare una definizione di risorsa
I pacchetti contengono definizioni per risorse quali lavori e pipeline da includere nel processo di distribuzione. Quando il bundle viene distribuito, le risorse definite nel bundle vengono create nell'area di lavoro (o aggiornate se sono già state distribuite). Queste definizioni vengono specificate in YAML o Python ed è possibile creare e modificare queste configurazioni direttamente nell'interfaccia utente.
Passare alla cartella bundle nell'area di lavoro in cui si vuole definire una nuova risorsa.
Suggerimento
Se hai aperto in precedenza il bundle nell'editor nell'area di lavoro, puoi usare l'elenco dei contesti di creazione del browser dell'area di lavoro per navigare alla cartella del bundle. Consulta Contesti di creazione.
A destra del nome del bundle, fare clic su Apri nell'editor per passare alla visualizzazione dell'editor di bundle.
Fare clic sull'icona di distribuzione per il bundle per passare al pannello Distribuzioni .
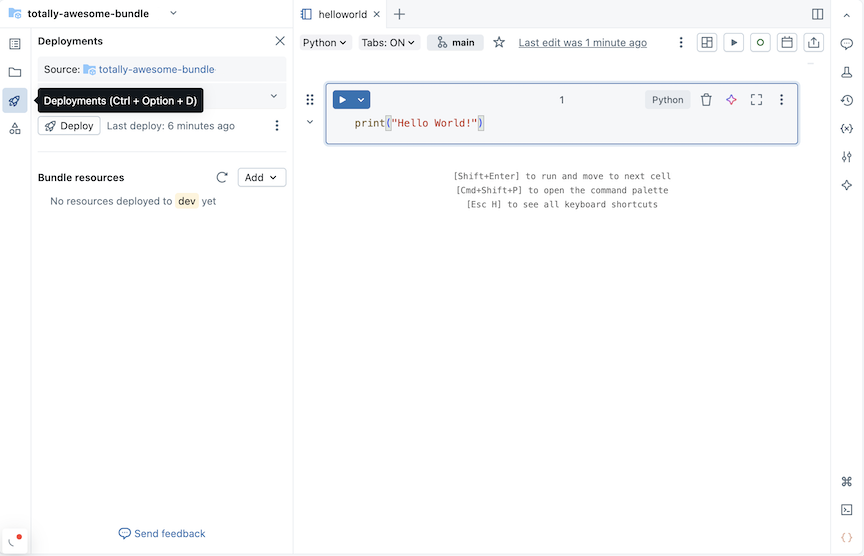
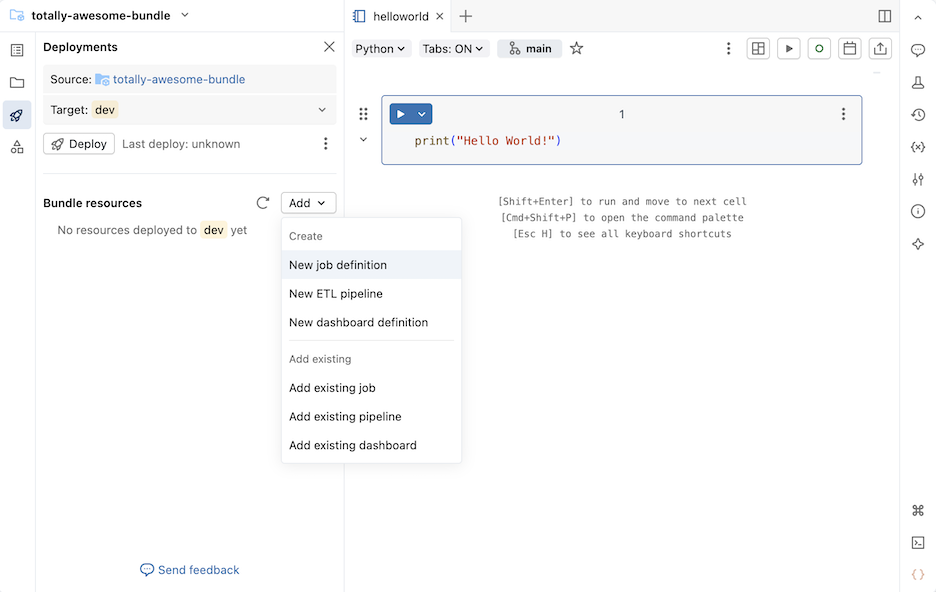
Nella sezione Bundle resources (Risorse bundle ) fare clic su Aggiungi e quindi scegliere una definizione di risorsa da creare.
Nuova definizione di job
Per creare un file di configurazione del bundle che definisce un processo:
Nella sezione Bundle resources (Risorse bundle) del pannello Distribuzioni, fare clic su Aggiungi e quindi su Nuova definizione di lavoro.
Digitare un nome per il lavoro nel campo Nome del lavoro della finestra di dialogo Crea definizione lavoro. Clicca su Crea.
Aggiungere YAML al file di definizione del processo creato. L'esempio YAML seguente definisce un processo che esegue un notebook:
resources: jobs: run_notebook: name: run-notebook queue: enabled: true tasks: - task_key: my-notebook-task notebook_task: notebook_path: ../helloworld.ipynb
Per informazioni dettagliate sulla definizione di un processo in YAML, vedere processo. Per la sintassi YAML per altri tipi di attività di processo supportati, vedere Aggiungere attività ai processi nei bundle di asset di Databricks.
Nuova definizione della pipeline
Annotazioni
Se nell'area di lavoro è stato abilitato l'editor delle pipeline di Lakeflow , vedere Nuova pipeline ETL.
Per aggiungere una definizione di pipeline al bundle:
Nella sezione Bundle resources (Risorse bundle) del pannello Distribuzioni, fare clic su Aggiungi e quindi su Nuova definizione della pipeline.
Digitare un nome per la pipeline nel campo Nome pipeline della finestra di dialogo Aggiungi pipeline al bundle esistente .
Fare clic su Aggiungi e distribuisci.
Per una pipeline con il nome test_pipeline che esegue un notebook, viene creato il codice YAML seguente in un file test_pipeline.pipeline.yml:
resources:
pipelines:
test_pipeline:
name: test_pipeline
libraries:
- notebook:
path: ../test_pipeline.ipynb
serverless: true
catalog: main
target: test_pipeline_${bundle.environment}
È possibile modificare la configurazione per eseguire un notebook esistente. Per informazioni dettagliate sulla definizione di una pipeline in YAML, vedere pipeline.
Nuova pipeline ETL
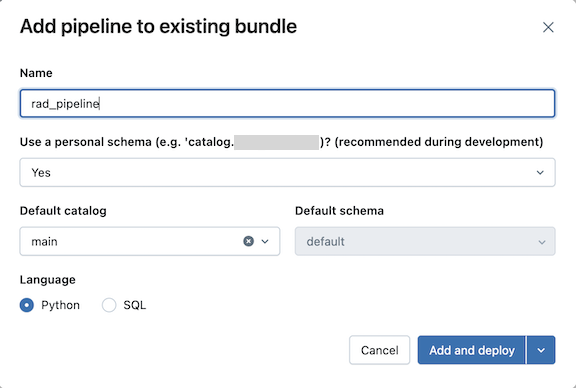
Per aggiungere una nuova definizione di pipeline ETL:
Nella sezione Bundle resources (Risorse bundle) del pannello Distribuzioni, fare clic su Aggiungi, quindi su Nuova pipeline ETL.
Digitare un nome per la pipeline nel campo Nome della finestra di dialogo Aggiungi pipeline al bundle esistente . Il nome deve essere univoco all'interno dell'area di lavoro.
Per il campo Usa schema personale selezionare Sì per gli scenari di sviluppo e No per gli scenari di produzione.
Selezionare un catalogo predefinito e uno schema predefinito per la pipeline.
Scegliere un linguaggio per il codice sorgente della pipeline.
Fare clic su Aggiungi e distribuisci.
Esaminare i dettagli nella finestra di dialogo di conferma della distribuzione allo sviluppo , quindi fare clic su Distribuisci.
Viene creata una pipeline ETL con tabelle di esplorazione e trasformazione di esempio.
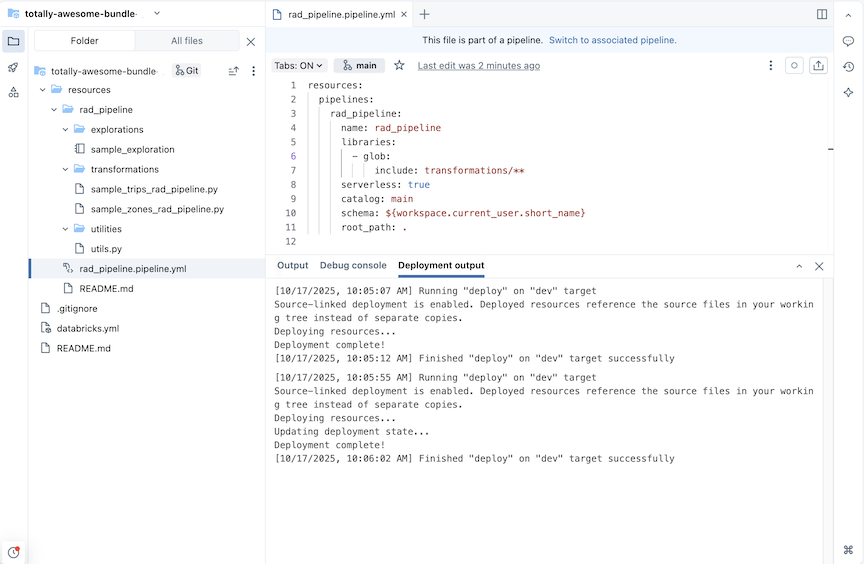
Per una pipeline con il nome rad_pipeline, viene creato il codice YAML seguente in un file rad_pipeline.pipeline.yml. Questa pipeline è configurata per l'esecuzione su calcolo serverless. Per informazioni di riferimento sulla configurazione della pipeline, vedere pipeline.
resources:
pipelines:
rad_pipeline:
name: rad_pipeline
libraries:
- glob:
include: transformations/**
serverless: true
catalog: main
schema: ${workspace.current_user.short_name}
root_path: .
Nuova definizione del dashboard
Per creare un file di configurazione del bundle che definisce un dashboard:
Nella sezione Bundle resources (Risorse bundle) del pannello Distribuzioni fare clic su Aggiungi e quindi su Nuova definizione della dashboard.
Digitare un nome per il dashboard nel campo Nome dashboard della finestra di dialogo Aggiungi dashboard al bundle esistente .
Selezionare un warehouse per il dashboard. Fare clic su Aggiungi e distribuisci.
Nel bundle vengono creati un nuovo dashboard vuoto e un file di configurazione *.dashboard.yml . Il dashboard viene archiviato nel magazzino specificato nel file di configurazione.
Per informazioni dettagliate sui dashboard, vedere Dashboard. Per la sintassi YAML per la configurazione del dashboard, vedere dashboard.
Aggiungere una risorsa esistente a un bundle
È possibile aggiungere risorse esistenti al bundle usando l'interfaccia utente dell'area di lavoro o aggiungendo la configurazione delle risorse al bundle.
Usare l'interfaccia utente dell'area di lavoro bundle
Per aggiungere un processo, una pipeline o un dashboard esistenti a un bundle:
Passare alla cartella bundle nell'area di lavoro in cui si vuole aggiungere una risorsa.
Suggerimento
Se il bundle è stato aperto in precedenza nell'editor nell'area di lavoro, è possibile usare l'elenco dei contesti di creazione del browser dell'area di lavoro per passare alla cartella bundle. Vedere Contesti di creazione.
A destra del nome del bundle, fare clic su Apri nell'editor per passare alla visualizzazione dell'editor di bundle.
Fare clic sull'icona di distribuzione per il bundle per passare al pannello Distribuzioni .
Nella sezione Risorse del bundle, fare clic su Aggiungi, quindi su Aggiungi processo esistente, Aggiungi pipeline esistente o Aggiungi dashboard esistente.
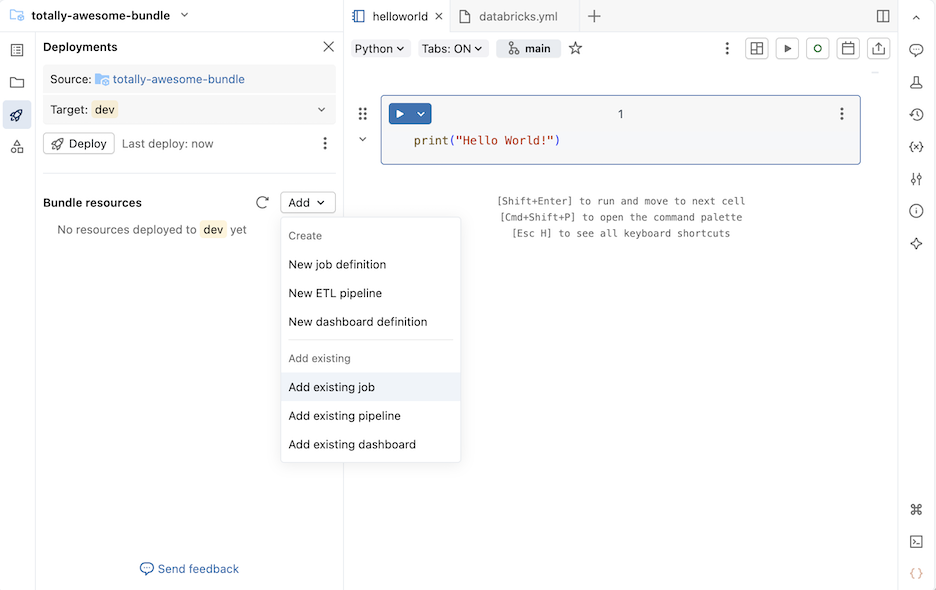
Nella finestra di dialogo Aggiungi esistente..., seleziona la risorsa esistente dall'elenco a discesa.
Quando si aggiunge una risorsa esistente a un bundle, Databricks crea una definizione in un file di configurazione del bundle per questa risorsa. Poiché è possibile modificare questa definizione nel bundle, la risorsa definita nel bundle può differire dalla risorsa usata per crearla.
Scegliere un'opzione per gestire gli aggiornamenti alla configurazione della risorsa bundle:
-
Aggiornamento nelle distribuzioni di produzione: la risorsa esistente viene collegata alla risorsa nel bundle e tutte le modifiche apportate alla risorsa nel bundle vengono applicate alla risorsa esistente quando si esegue la distribuzione nella
proddestinazione. -
Aggiornamento nelle distribuzioni di sviluppo: la risorsa esistente viene collegata alla risorsa nel bundle e tutte le modifiche apportate alla risorsa nel bundle vengono applicate alla risorsa esistente quando si esegue la distribuzione nella
devdestinazione. - (Avanzate) Non aggiornare: la risorsa esistente non è collegata al bundle. Le modifiche apportate alla risorsa nel bundle non vengono mai applicate alla risorsa esistente. Viene invece creata una copia. Per ulteriori informazioni sull'associazione delle risorse del bundle alla loro corrispondente risorsa dell'area di lavoro, vedere databricks bundle deployment bind.
-
Aggiornamento nelle distribuzioni di produzione: la risorsa esistente viene collegata alla risorsa nel bundle e tutte le modifiche apportate alla risorsa nel bundle vengono applicate alla risorsa esistente quando si esegue la distribuzione nella
Fare clic su Aggiungi ... per aggiungere la risorsa esistente al bundle.
Aggiungere la configurazione del bundle
È anche possibile aggiungere una risorsa esistente al bundle definendo la configurazione del bundle da includere nella distribuzione del bundle. Nell'esempio seguente viene aggiunta una pipeline esistente a un bundle.
Supponendo di avere una pipeline denominata taxifilter che esegue il notebook taxifilter.ipynb nell'area di lavoro condivisa:
Nella barra laterale dell'area di lavoro di Azure Databricks fare clic su Processi e pipeline.
Facoltativamente, selezionare i filtri Pipeline e Di mia proprietà.
Selezionare la pipeline esistente
taxifilter.Nella pagina della pipeline fare clic sul kebab a sinistra del pulsante Modalità di distribuzione sviluppo . Fare quindi clic su Visualizza impostazioni YAML.
Fare clic sull'icona di copia per copiare la configurazione del bundle per la pipeline.
Naviga al tuo bundle in Workspace.
Fare clic sull'icona di distribuzione per il bundle per passare al pannello Distribuzioni .
Nella sezione Bundle resources (Risorse bundle) fare clic su Add (Aggiungi), quindi su New pipeline definition (Nuova definizione della pipeline).
Annotazioni
Se invece visualizzi una voce di menu Nuova pipeline ETL, allora hai abilitato l'Editor di Pipelines Lakeflow. Per aggiungere una pipeline ETL a un bundle, vedere Creare una pipeline controllata dal codice sorgente.
Digitare
taxifilternel campo Nome pipeline della finestra di dialogo Aggiungi pipeline al bundle esistente . Clicca su Crea.Incollare la configurazione per la pipeline esistente nel file. Questa pipeline di esempio viene definita per eseguire il
taxifilternotebook:resources: pipelines: taxifilter: name: taxifilter catalog: main libraries: - notebook: path: /Workspace/Shared/taxifilter.ipynb target: taxifilter_${bundle.environment}
È ora possibile distribuire il bundle, quindi eseguire la risorsa della pipeline tramite l'interfaccia utente.