Nota
L'accesso a questa pagina richiede l'autorizzazione. Puoi provare ad accedere o a cambiare directory.
L'accesso a questa pagina richiede l'autorizzazione. Puoi provare a cambiare directory.
Creare un agente di intelligenza artificiale e distribuirlo usando Databricks Apps. Databricks Apps offre il controllo completo sul codice dell'agente, sulla configurazione del server e sul flusso di lavoro di distribuzione. Questo approccio è ideale quando è necessario un comportamento del server personalizzato, il controllo delle versioni basato su Git o lo sviluppo di IDE locali.
Requisiti
Abilitare Le app di Databricks nell'area di lavoro. Vedere Configurare l'area di lavoro e l'ambiente di sviluppo di Databricks Apps.
Passaggio 1. Clonare il modello di app agente
Introduzione all'uso di un modello di agente predefinito dal repository dei modelli di app Databricks.
Questa esercitazione usa il modello agent-openai-agents-sdk, che include:
- Un agente creato con OpenAI Agent SDK
- Codice di avvio per un'applicazione agente con un'API REST di conversazione e un'interfaccia utente di chat interattiva
- Codice per valutare l'agente usando MLflow
Scegliere uno dei percorsi seguenti per configurare il modello:
Interfaccia utente dell'area di lavoro
Installare il modello di app usando l'interfaccia utente dell'area di lavoro. In questo modo l'app viene installata e distribuita in una risorsa di calcolo nell'area di lavoro. È quindi possibile sincronizzare i file dell'applicazione nell'ambiente locale per un ulteriore sviluppo.
Nell'area di lavoro di Databricks fare clic su + Nuova>app.
Fare clic su Agenti>Agenti - SDK di OpenAI Agents.
Creare un nuovo esperimento MLflow con il nome
openai-agents-templatee completare il resto della configurazione per installare il modello.Dopo aver creato l'app, fare clic sull'URL dell'app per aprire l'interfaccia utente della chat.
Dopo aver creato l'app, scaricare il codice sorgente nel computer locale per personalizzarlo:
Copiare il primo comando in Sincronizzare i file
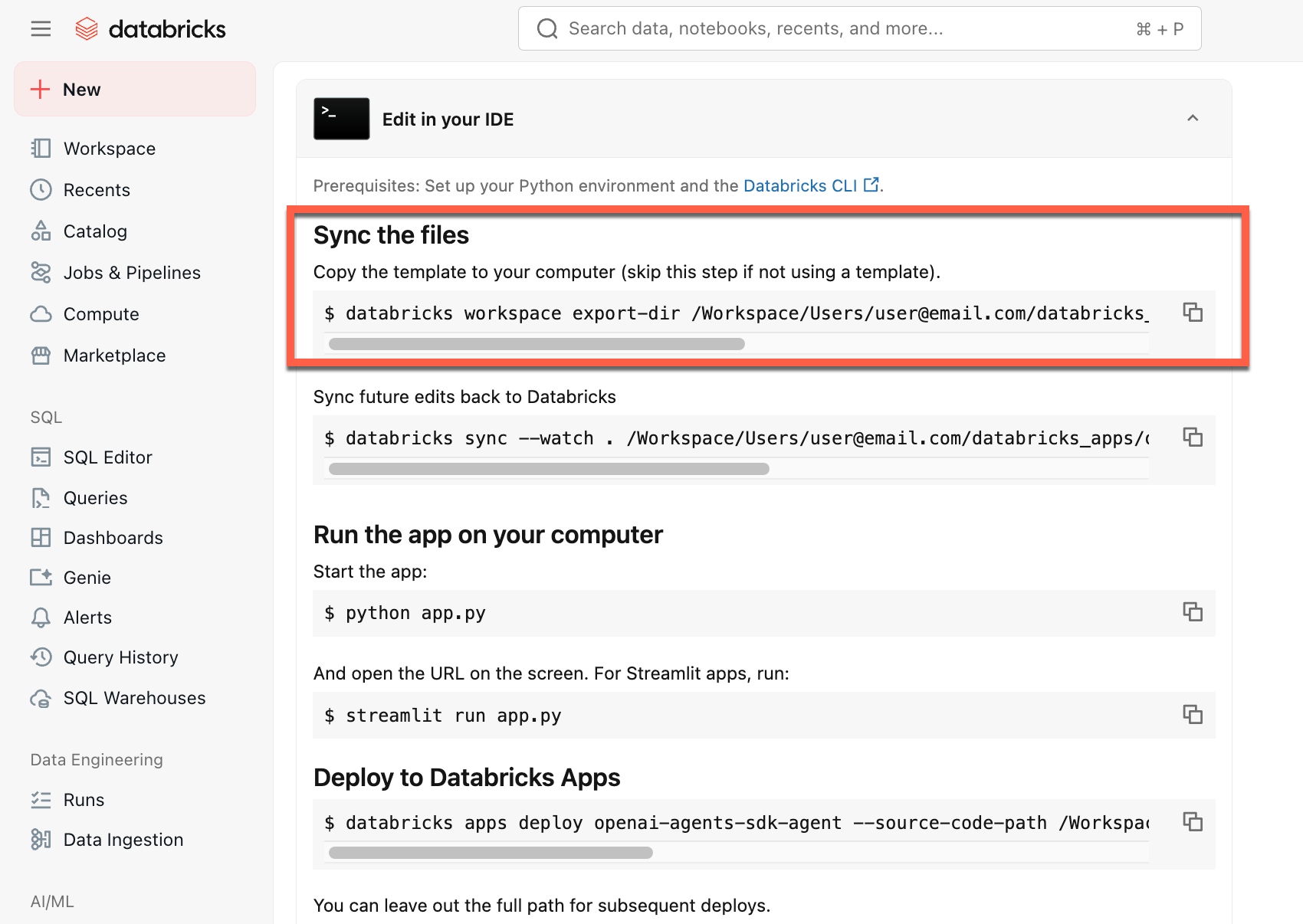
In un terminale locale eseguire il comando copiato.
Clonare da GitHub
Per iniziare da un ambiente locale, clonare il repository dei modelli di agente e aprire la agent-openai-agents-sdk directory:
git clone https://github.com/databricks/app-templates.git
cd app-templates/agent-openai-agents-sdk
Passaggio 2. Informazioni sull'applicazione agente
Il modello di agente illustra un'architettura pronta per la produzione con questi componenti chiave. Aprire le sezioni seguenti per altri dettagli su ogni componente:

Aprire le sezioni seguenti per altri dettagli su ogni componente:
 MLflow AgentServer
MLflow AgentServer
Un server FastAPI asincrono che gestisce le richieste degli agenti con traccia e osservabilità predefinite.
AgentServer fornisce l'endpoint per l'esecuzione di query sull'agente /invocations e gestisce automaticamente il routing delle richieste, la registrazione e la gestione degli errori.

ResponsesAgent Interfaccia
Databricks consiglia MLflow ResponsesAgent per compilare gli agenti.
ResponsesAgent consente di creare agenti con qualsiasi framework di terze parti, quindi integrarlo con le funzionalità di intelligenza artificiale di Databricks per funzionalità di registrazione, traccia, valutazione, distribuzione e monitoraggio affidabili.

Per informazioni su come creare un ResponsesAgent, consultare gli esempi nella documentazione di MLflow - ResponsesAgent for Model Serving.
ResponsesAgent offre i vantaggi seguenti:
Funzionalità avanzate dell'agente
- Supporto multi-agente
- Output di streaming: trasmettere l'output in blocchi più piccoli.
- cronologia completa dei messaggi relativi alla chiamata degli strumenti: restituzione di più messaggi, inclusi quelli intermedi relativi alla chiamata degli strumenti, per migliorare la qualità e la gestione delle conversazioni.
- Supporto per la conferma dell'attivazione degli strumenti
- Supporto per strumenti a esecuzione prolungata
Sviluppo, distribuzione e monitoraggio semplificati
-
Creare agenti usando qualsiasi framework: incapsulare qualsiasi agente esistente usando l'interfaccia
ResponsesAgentper ottenere la compatibilità immediata con AI Playground, Agent Evaluation e Agent Monitoring. - interfacce di authoring tipizzate: scrivere codice dell'agente usando classi Python tipizzate, traendo vantaggio dall'IDE e dal completamento automatico nei notebook.
- Traccia automatica: MLflow aggrega automaticamente le risposte in streaming nelle tracce per facilitare la valutazione e la visualizzazione.
-
Compatibile con lo
Responsesschema OpenAI: vedere OpenAI: Risposte vs. CompletamentoChat.
-
Creare agenti usando qualsiasi framework: incapsulare qualsiasi agente esistente usando l'interfaccia
 OpenAI Agents SDK
OpenAI Agents SDK
Il modello usa OpenAI Agents SDK come framework agente per la gestione delle conversazioni e l'orchestrazione degli strumenti. È possibile creare agenti usando qualsiasi framework. La chiave è eseguire il wrapping del proprio agente con l'interfaccia MLflow ResponsesAgent.
 Server MCP (Model Context Protocol)
Server MCP (Model Context Protocol)
Il modello si connette ai server MCP di Databricks per concedere agli agenti l'accesso a strumenti e origini dati. Vedere Model Context Protocol (MCP) in Databricks.
Creare agenti usando assistenti per la scrittura del codice di intelligenza artificiale
Databricks consiglia di usare assistenti di codifica di intelligenza artificiale come Claude, Cursor e Copilot per creare agenti. Usare le competenze dell'agente fornite, in /.claude/skillse il AGENTS.md file per aiutare gli assistenti di intelligenza artificiale a comprendere la struttura del progetto, gli strumenti disponibili e le procedure consigliate. Gli agenti possono leggere automaticamente tali file per sviluppare e distribuire le app di Databricks.
Argomenti avanzati sull'autoring
Risposte in streaming
Risposte in streaming
Lo streaming consente agli agenti di inviare risposte in blocchi in tempo reale invece di attendere la risposta completa. Per implementare lo streaming con ResponsesAgent, generare una serie di eventi delta seguiti da un evento di completamento finale:
-
Generare eventi differenziali: inviare più
output_text.deltaeventi con lo stessoitem_idper trasmettere blocchi di testo in tempo reale. -
Concludere con l'evento finale: inviare un ultimo evento
response.output_item.donecon lo stessoitem_iddegli eventi delta, contenente il testo dell'output finale completo.
Ogni evento delta trasmette un blocco di testo al client. L'evento completato finale contiene il testo di risposta completo e segnala a Databricks di eseguire le operazioni seguenti:
- Traccia l'output dell'agente con il tracciamento di MLflow
- Aggregare le risposte in streaming nelle tabelle di inferenza del gateway di intelligenza artificiale
- Visualizzare l'output completo nell'interfaccia utente di AI Playground
Propagazione degli errori di streaming
Mosaic AI propaga gli errori riscontrati durante lo streaming sotto l'ultimo token databricks_output.error. Spetta al client chiamante gestire e individuare correttamente questo errore.
{
"delta": …,
"databricks_output": {
"trace": {...},
"error": {
"error_code": BAD_REQUEST,
"message": "TimeoutException: Tool XYZ failed to execute."
}
}
}
Input e output personalizzati
Input e output personalizzati
Alcuni scenari potrebbero richiedere input aggiuntivi da parte dell'agente, come client_type e session_id, o output come collegamenti alle fonti di recupero, che non dovrebbero essere inclusi nella cronologia delle chat destinate a interazioni future.
Per questi scenari, MLflow ResponsesAgent supporta in modo nativo i campi custom_inputs e custom_outputs. È possibile accedere agli input personalizzati tramite request.custom_inputs gli esempi di framework precedenti.
L'app Valutazione agente non supporta il rendering delle tracce per gli agenti con campi di input aggiuntivi.
Fornire custom_inputs in AI Playground ed esaminare l'app
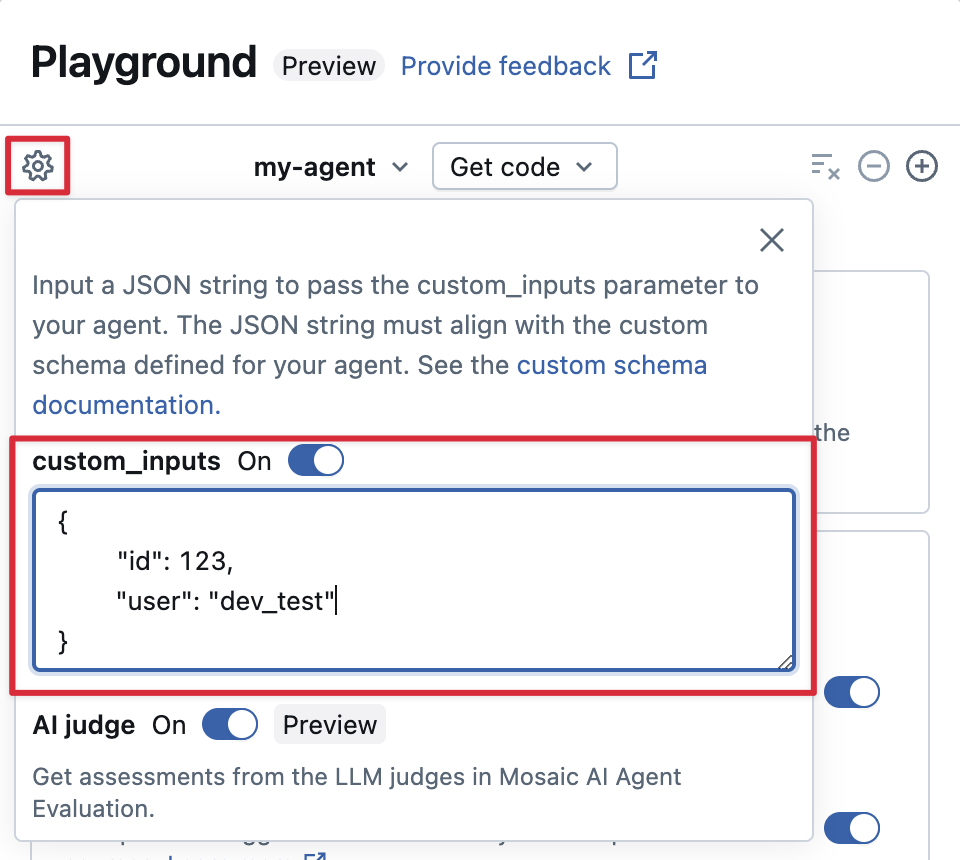
Se l'agente accetta input aggiuntivi usando il custom_inputs campo , è possibile fornire manualmente questi input sia in AI Playground che nell'app di revisione.
Selezionare l'icona a forma di ingranaggio in AI Playground o nell'app di revisione agente.
Abilitare custom_inputs.
Fornire un oggetto JSON che corrisponda allo schema di input definito dell'agente.
Schemi di recupero personalizzati
Schemi di recupero personalizzati
Gli agenti di intelligenza artificiale usano in genere i retriever per trovare ed eseguire query su dati non strutturati da indici di ricerca vettoriali. Ad esempio strumenti di recupero: si veda Connettere gli agenti ai dati non strutturati.
Traccia questi retriever all'interno del tuo agente con le sezioni MLflow RETRIEVER per abilitare le funzionalità del prodotto Databricks, tra cui:
- Visualizzazione automatica dei collegamenti ai documenti di origine recuperati nell'interfaccia utente di AI Playground
- Esecuzione automatica delle valutazioni di radicamento e pertinenza nella valutazione dell'agente.
Nota
Databricks consiglia di usare gli strumenti di recupero forniti da pacchetti di Databricks AI Bridge come databricks_langchain.VectorSearchRetrieverTool e databricks_openai.VectorSearchRetrieverTool perché sono già conformi allo schema del retriever MLflow. Consulta Sviluppa localmente gli strumenti di recupero di ricerca vettoriale con AI Bridge.
Se il vostro agente include intervalli di recupero con uno schema personalizzato, chiamate mlflow.models.set_retriever_schema quando definite l'agente nel codice. Mappa le colonne di output del retriever ai campi attesi di MLflow (primary_key, text_column, doc_uri).
import mlflow
# Define the retriever's schema by providing your column names
# For example, the following call specifies the schema of a retriever that returns a list of objects like
# [
# {
# 'document_id': '9a8292da3a9d4005a988bf0bfdd0024c',
# 'chunk_text': 'MLflow is an open-source platform, purpose-built to assist machine learning practitioners...',
# 'doc_uri': 'https://mlflow.org/docs/latest/index.html',
# 'title': 'MLflow: A Tool for Managing the Machine Learning Lifecycle'
# },
# {
# 'document_id': '7537fe93c97f4fdb9867412e9c1f9e5b',
# 'chunk_text': 'A great way to get started with MLflow is to use the autologging feature. Autologging automatically logs your model...',
# 'doc_uri': 'https://mlflow.org/docs/latest/getting-started/',
# 'title': 'Getting Started with MLflow'
# },
# ...
# ]
mlflow.models.set_retriever_schema(
# Specify the name of your retriever span
name="mlflow_docs_vector_search",
# Specify the output column name to treat as the primary key (ID) of each retrieved document
primary_key="document_id",
# Specify the output column name to treat as the text content (page content) of each retrieved document
text_column="chunk_text",
# Specify the output column name to treat as the document URI of each retrieved document
doc_uri="doc_uri",
# Specify any other columns returned by the retriever
other_columns=["title"],
)
Nota
La doc_uri colonna è particolarmente importante quando si valutano le prestazioni del recuperatore.
doc_uri è l'identificatore principale per i documenti restituiti dal retriever, consentendo di confrontarli con i set di valutazione della verità di base. Vedere Set di valutazione (MLflow 2).
Passaggio 3. Esegui l'app Agente localmente
Configurare l'ambiente locale:
Installare
uv(Gestione pacchetti Python),nvm(Gestione versioni di Node) e l'interfaccia della riga di comando di Databricks:-
uvInstallazione -
nvmInstallazione - Eseguire quanto segue per usare Node 20 LTS:
nvm use 20 -
databricks CLIInstallazione
-
Cambiare directory verso la cartella
agent-openai-agents-sdk.Eseguire gli script di avvio rapido forniti per installare le dipendenze, configurare l'ambiente e avviare l'app.
uv run quickstart uv run start-app
In un browser, vai a http://localhost:8000 per iniziare a chattare con l'agente.
Passaggio 4. Configurare l'autenticazione
L'agente deve eseguire l'autenticazione per accedere alle risorse di Databricks. Databricks Apps offre due metodi di autenticazione:
Autorizzazione dell'app (impostazione predefinita)
L'autorizzazione dell'app usa un'entità servizio creata automaticamente da Azure Databricks per l'app. Tutti gli utenti condividono le stesse autorizzazioni.
Concedere le autorizzazioni all'esperimento MLflow:
- Fare clic su Modifica nella home page dell'app.
- Passare al passaggio Configura .
- Nella sezione Risorse dell'app, aggiungere la risorsa esperimento MLflow con l'autorizzazione
Can Edit.
Per altre risorse (Ricerca vettoriale, Spazi Genie, gestione degli endpoint), aggiungerle allo stesso modo nella sezione Risorse dell'app .
Per altri dettagli, vedere Autorizzazione dell'app .
Autorizzazione utente
L'autorizzazione utente consente all'agente di agire con le singole autorizzazioni di ogni utente. Usare questa opzione quando è necessario il controllo di accesso per utente o audit trail.
Aggiungere questo codice all'agente:
from agent_server.utils import get_user_workspace_client
# In your agent code (inside @invoke or @stream)
user_workspace = get_user_workspace_client()
# Access resources with the user's permissions
response = user_workspace.serving_endpoints.query(name="my-endpoint", inputs=inputs)
Importante: Inizializzare get_user_workspace_client() all'interno delle funzioni @invoke o @stream, non durante l'avvio dell'app. Le credenziali utente esistono solo quando si gestisce una richiesta.
Configurare gli ambiti: Aggiungere ambiti di autorizzazione nell'interfaccia utente di Databricks Apps per definire le API a cui l'agente può accedere per conto degli utenti.
Per istruzioni complete sull'installazione, vedere Autorizzazione utente .
Passaggio 5. Valutare l'agente
Il modello include il codice di valutazione dell'agente. Per altre informazioni, vedere agent_server/evaluate_agent.py. Valutare la pertinenza e la sicurezza delle risposte dell'agente eseguendo quanto segue in un terminale:
uv run agent-evaluate
Passaggio 6. Distribuire l'agente su app Databricks
Dopo aver configurato l'autenticazione, distribuisci l'agente su Databricks. Assicurati di avere il Databricks CLI installato e configurato.
Se il repository è stato clonato in locale, creare l'app Databricks prima di distribuirla. Se l'app è stata creata tramite l'interfaccia utente dell'area di lavoro, ignorare questo passaggio perché l'app e l'esperimento MLflow sono già configurati.
databricks apps create agent-openai-agents-sdkSincronizzare i file locali nell'area di lavoro. Vedere Distribuire l'app.
DATABRICKS_USERNAME=$(databricks current-user me | jq -r .userName) databricks sync . "/Users/$DATABRICKS_USERNAME/agent-openai-agents-sdk"Distribuisci l'applicazione Databricks.
databricks apps deploy agent-openai-agents-sdk --source-code-path /Workspace/Users/$DATABRICKS_USERNAME/agent-openai-agents-sdk
Per gli aggiornamenti futuri dell'agente, sincronizza e riconfigura il tuo agente.
Passaggio 7. Interrogare l'agente distribuito
Gli utenti interrogano l'agente distribuito usando token OAuth. I token di accesso personale (PAT) non sono supportati per le app Databricks.
Generare un token OAuth usando l'interfaccia della riga di comando di Databricks:
databricks auth login --host <https://host.databricks.com>
databricks auth token
Usa il token per eseguire una query sull'agente.
curl -X POST <app-url.databricksapps.com>/invocations \
-H "Authorization: Bearer <oauth token>" \
-H "Content-Type: application/json" \
-d '{ "input": [{ "role": "user", "content": "hi" }], "stream": true }'
Limitazioni
Sono supportate solo le dimensioni di calcolo medie e grandi. Vedere Configurare le dimensioni di calcolo per un'app Databricks.