Nota
L'accesso a questa pagina richiede l'autorizzazione. Puoi provare ad accedere o a cambiare directory.
L'accesso a questa pagina richiede l'autorizzazione. Puoi provare a cambiare directory.
Importante
Questa funzionalità è in Anteprima Pubblica.
Questa pagina presenta l'agente di ingegneria dei dati che aggiunge funzionalità all'Assistente Databricks. Per usare l'agente di ingegneria dei dati, selezionare Modalità agente nell'Assistente.
L'agente di ingegneria dei dati è progettato in modo specifico per Le pipeline dichiarative di Lakeflow Spark (SDP) e l'editor di Pipelines Lakeflow, esplora i dati, genera ed esegue il codice della pipeline e corregge gli errori, tutti da un singolo prompt.
Che cos'è l'agente di ingegneria dei dati?
L'Agente di Ingegneria dei Dati è una potente funzionalità nella Modalità Agente dell'Assistente Databricks che trasforma l'Assistente in un partner autonomo in grado di automatizzare interi flussi di lavoro di ingegneria dei dati a più fasi in SDP e nell'Editor delle pipeline di Lakeflow.
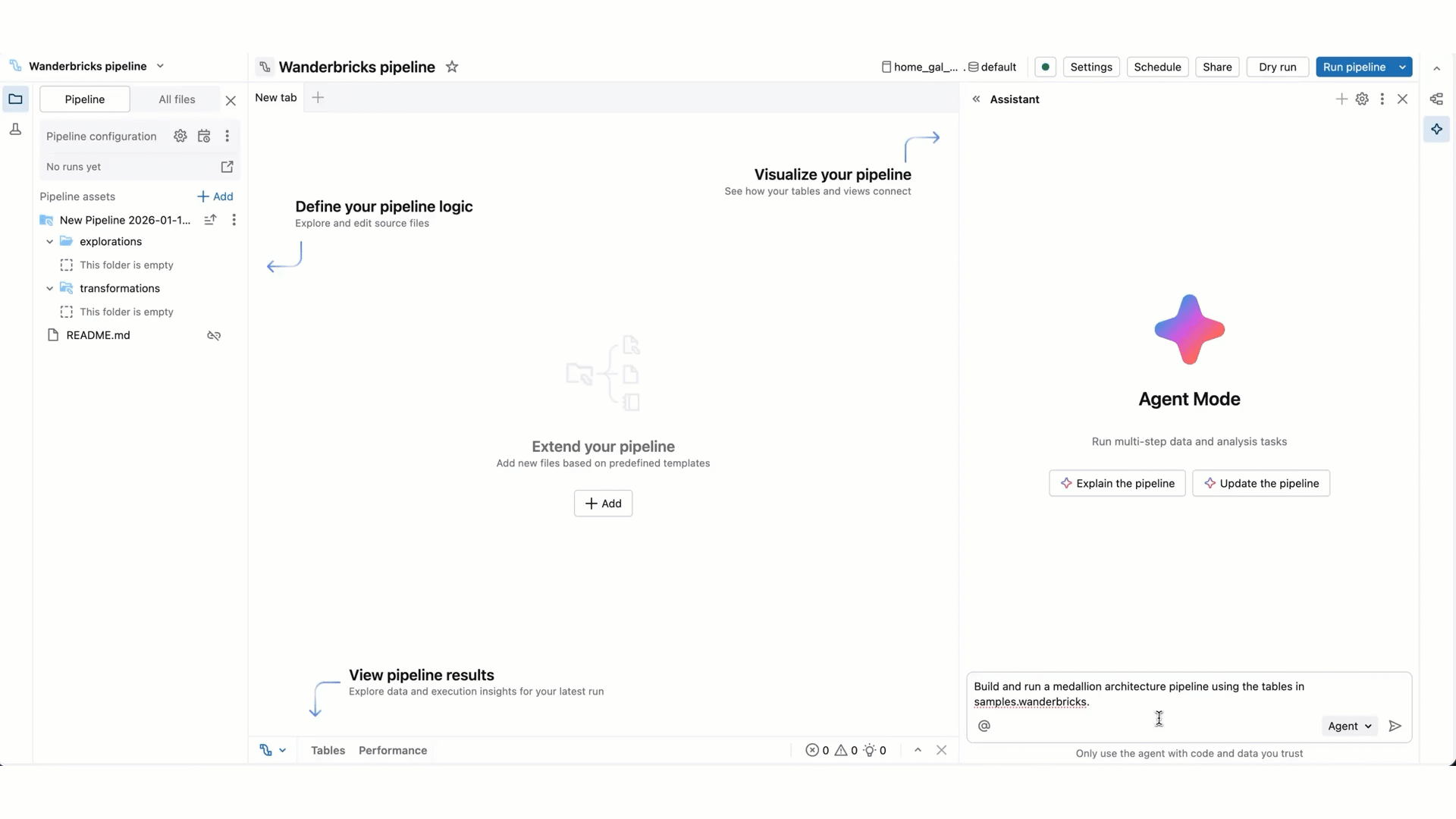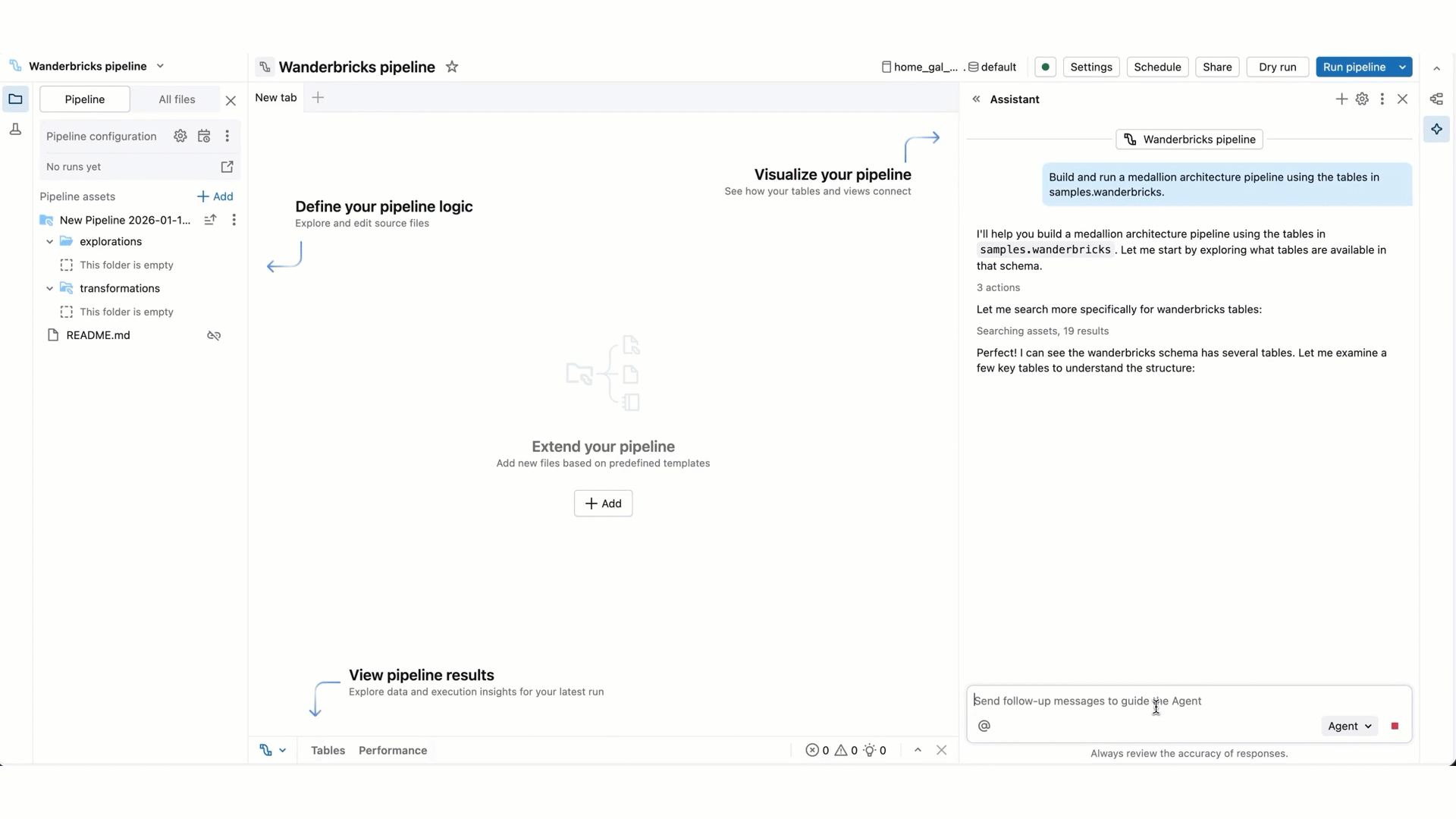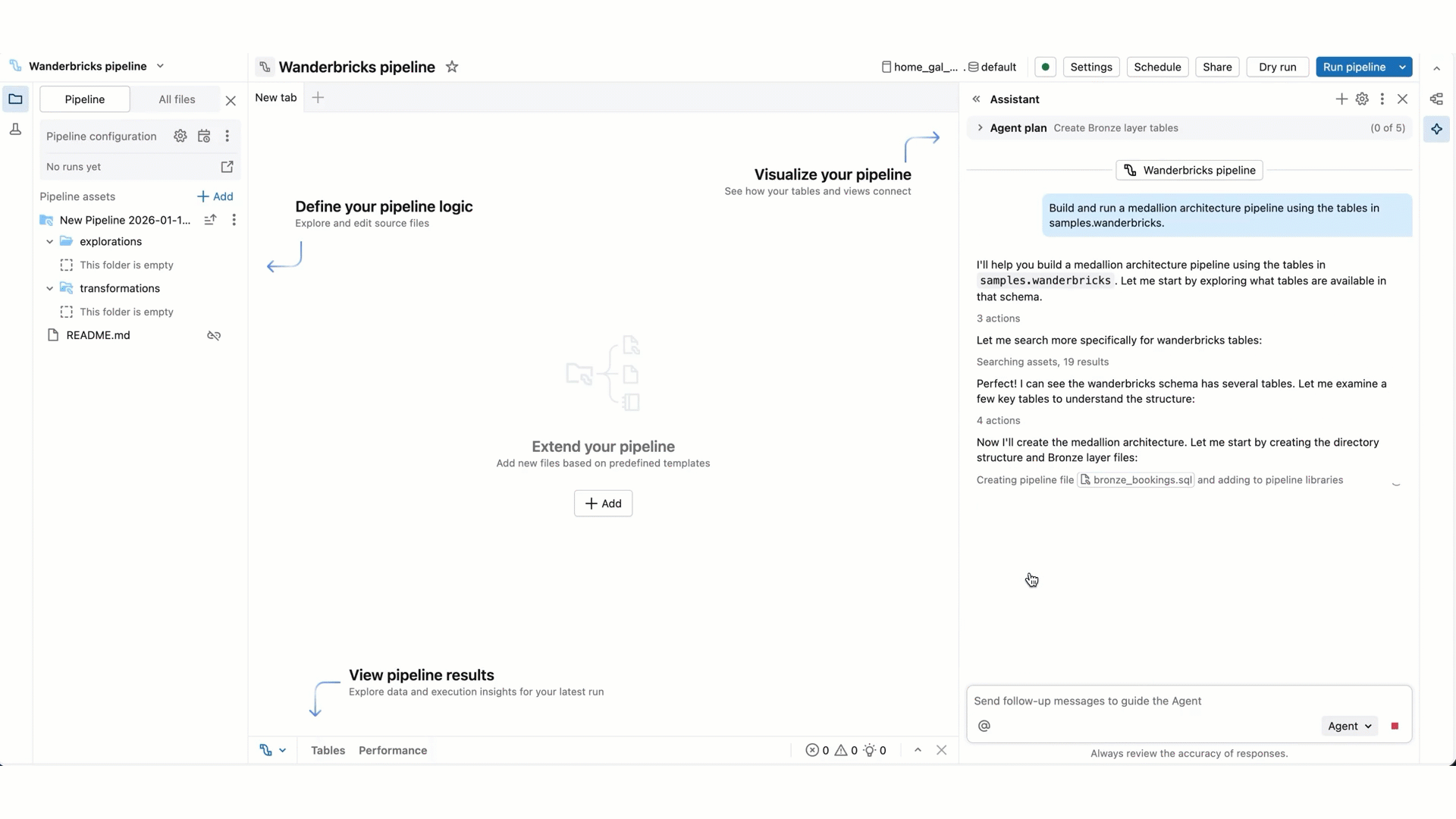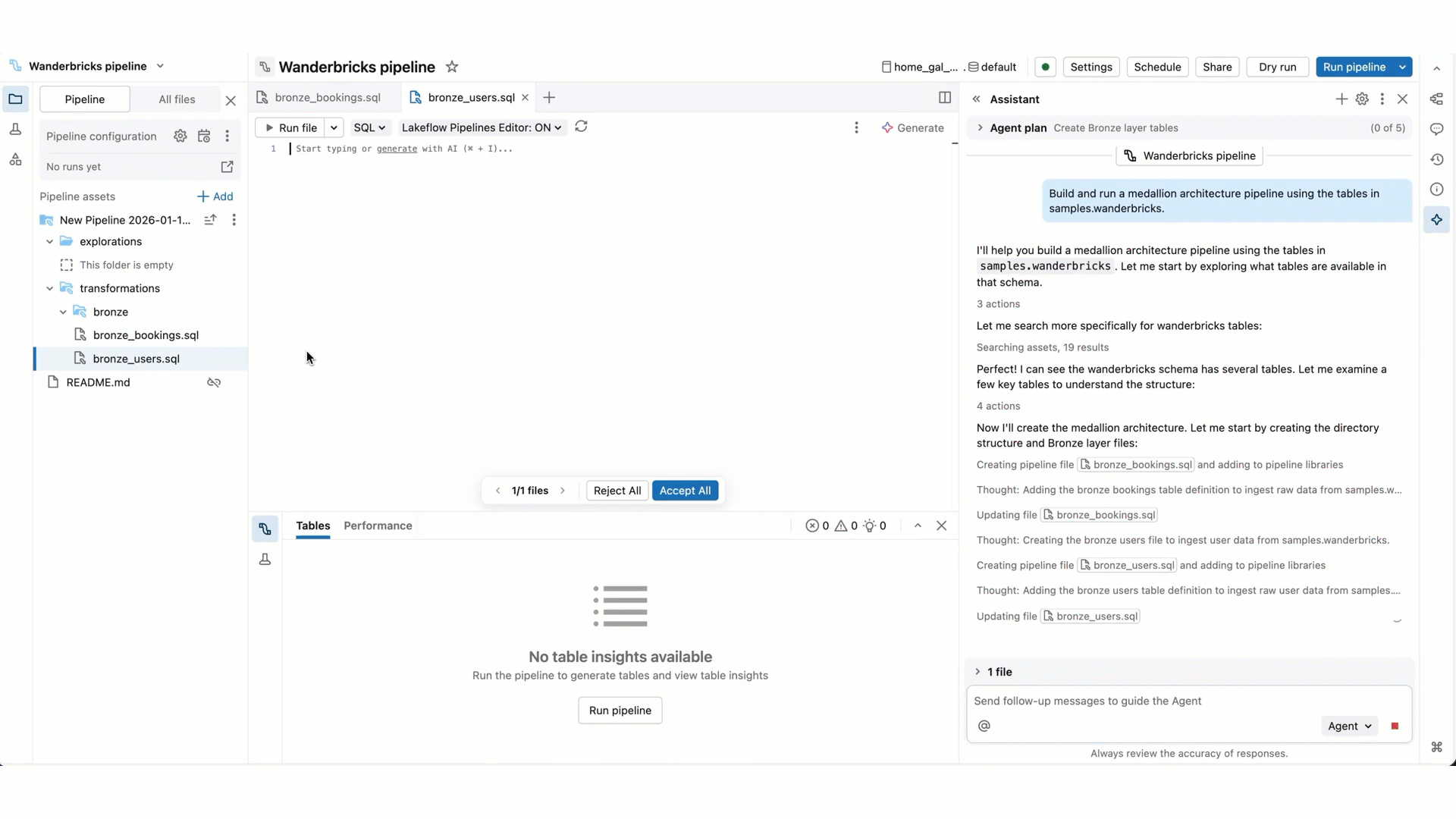
Rispetto alla modalità Chat assistente, la modalità agente ha ampliato le funzionalità: pianificazione di una soluzione, recupero di asset pertinenti, esecuzione di codice, uso di output della pipeline per migliorare i risultati, correggere gli errori automaticamente e altro ancora.
L'agente per la progettazione dei dati può pianificare e creare intere pipeline end-to-end da zero oppure ottimizzare il lavoro su una pipeline esistente. L'agente collabora con l'utente per approvare i piani e confermare i passaggi successivi prima di procedere. Con l'approvazione, l'agente di ingegneria dei dati può usare strumenti per eseguire attività come la ricerca di tabelle, la modifica di un file di origine SQL o Python, l'esecuzione di aggiornamenti della pipeline e la lettura dei set di dati delle pipeline.
L'accesso e le azioni dell'agente di ingegneria dei dati sono regolati dalle autorizzazioni dell'utente. Può accedere solo ai dati a cui si ha accesso ed eseguire operazioni per cui si dispone delle autorizzazioni.
Annotazioni
Quando si attiva la modalità agente nell'Assistente, l'Assistente adatta le funzionalità in base alle funzionalità attualmente in uso in Databricks. Ad esempio, nell'editor di Lakeflow Pipelines l'Assistente è incentrato sulle attività di modifica della pipeline e progettazione dei dati. Nei notebook e nell'editor SQL l'assistente supporta l'esplorazione e l'analisi dei dati. Per altre informazioni, vedere Data Science Agent .
Requisiti
Per usare l'agente di ingegneria dei dati, l'area di lavoro richiede quanto segue:
- Funzionalità di intelligenza artificiale basate su partner abilitate sia per l'account che per l'area di lavoro. Consulta Funzionalità di AI supportate da partner.
- Anteprima della modalità agente assistente Databricks abilitata. Vedere Gestire le anteprime di Azure Databricks.
Usare l'agente di ingegneria dei dati
Per usare l'agente di ingegneria dei dati:
In Lakeflow Pipelines Editor aprire il pannello laterale
 Assistente nell'angolo superiore destro dell'area di lavoro.
Assistente nell'angolo superiore destro dell'area di lavoro.Nell'angolo in basso a destra selezionare Agente. Questa opzione attiva o disattiva la modalità agente dell'Assistente, consentendo di interagire con l'agente di ingegneria dei dati.
Immettere un prompt per l'agente. Ad esempio, è possibile porre delle domande sulla pipeline, come "descrivi questa pipeline". È anche possibile chiedere di aggiungere nuovi set di dati, ad esempio "creare silver_sales_data in un nuovo file che legge da bronze_sales_data e pulisce i dati e aggiunge aspettative di qualità utili".
Annotazioni
L'agente rispetta le autorizzazioni del catalogo Unity dell'utente, in modo che possa accedere solo ai dati e all'origine della pipeline a cui si ha accesso.
Quando l'agente genera la risposta, spesso si sospende per ottenere l'input:
Per attività più complesse, l'agente può creare un piano dettagliato e porre domande chiare. Rispondere alle domande di chiarimento dell'agente per aiutarlo a perfezionare il suo piano.
Quando l'agente deve eseguire il codice o aggiornare una pipeline, richiede l'approvazione prima di procedere. Consenti o Rifiuta la richiesta. È anche possibile selezionare Consenti in questo thread (facendo riferimento al thread di conversazione assistente) o Consenti sempre.
Importante
L'agente di ingegneria dei dati può generare ed eseguire codice nella pipeline. Mentre ha guardrail per prevenire azioni pericolose, c'è ancora rischio. È consigliabile usarlo solo con i dati attendibili ed esaminare il codice prima di eseguirlo.
Quando l'agente continua il proprio lavoro, potrebbe essere richiesto di selezionare Continua o Rifiuta. Esaminare il lavoro esistente dell'agente, quindi selezionare Continua per consentire all'agente di continuare con i passaggi successivi o Rifiuta per indicare all'agente di provare qualcos'altro.
Per arrestare l'agente mentre è in funzione, fare clic sull'icona rossa di Arresta.
L'agente può creare nuovi file, generare testo, query e codice, eseguire i file o le pipeline e accedere ai set di dati di output per interpretare i risultati.
Annotazioni
Per consentire all'agente di ingegneria dei dati di continuare il proprio lavoro ed eseguire i passaggi successivi, è necessario rimanere nella scheda corrente in cui l'agente sta lavorando.
Suggerimento
È possibile aggiungere istruzioni per l'agente da usare nella maggior parte delle risposte. Ad esempio, se si hanno convenzioni di codice da usare o librerie preferite da usare, è possibile aggiungere queste linee guida alle istruzioni per l'agente. È anche possibile creare competenze per estendere l'agente con funzionalità specializzate per le attività specifiche del dominio. Per altri dettagli e altri suggerimenti, vedere Personalizzare e migliorare le risposte di Databricks Assistant.
Capacità
L'agente di ingegneria dei dati può essere utile per la maggior parte delle attività di sviluppo della pipeline. Le funzionalità principali includono:
- Individuazione dati: l'agente può eseguire ricerche nelle tabelle nell'area di lavoro per trovare i dati necessari per un'attività.
- Modifiche al codice della pipeline: l'agente può creare e modificare più file alla volta. Ti informa su quali file vengono modificati e mostra le differenze del codice in ogni file, in modo che tu possa esaminare le modifiche singolarmente o tutte insieme alla fine.
- Esecuzione pipeline: l'agente può eseguire singoli file, simulare/eseguire la pipeline o eseguire un aggiornamento completo. Quando l'agente vuole procedere, richiede la conferma prima di farlo.
- Comprensione e miglioramento del comportamento della pipeline: l'agente può esaminare i set di dati e gli output della pipeline per aiutarti a capire cosa fa una pipeline dal principio alla fine e perché. Ad esempio, può riepilogare le trasformazioni, tracciare il flusso dei dati nelle tabelle downstream ed evidenziare modifiche impreviste nei conteggi delle righe o negli schemi. Quando presenta potenziali problemi di qualità dei dati, l'agente può aiutare a ragionare sulla loro causa e suggerire dove e come risolverli nella pipeline.
Queste funzionalità supportano casi d'uso comuni, ad esempio:
- Creazione di una nuova pipeline: l'Agente di Ingegneria dei Dati assiste in tutti i passaggi della creazione di una nuova pipeline di architettura medallion, dall'inserimento, alla standardizzazione e pulizia, fino alla trasformazione e analisi dei dati.
- Spiegare una pipeline: l'agente può analizzare e spiegare una pipeline esistente per facilitare l'aumento rapido.
- Correzione dei problemi: quando si verificano errori, l'agente può aiutare a diagnosticare e risolvere i problemi, iterando più file fino a quando il problema non viene risolto.
Esempi
Provare le istruzioni seguenti per iniziare:
- Compilare ed eseguire una pipeline dell'architettura medallion per il rilevamento delle frodi utilizzando le tabelle delle transazioni e dei clienti in my_catalog.my_schema.
- Spiega ogni passaggio di questa pipeline.
- Correggi il guasto in questa pipeline.
Passaggi successivi
- Altre informazioni sulle funzionalità assistive di intelligenza artificiale di Databricks
- Ottenere suggerimenti per personalizzare e migliorare le risposte di Databricks Assistant
- Usare l'agente di data science per l'individuazione e l'esplorazione dei dati
- Esplorare l'editor delle pipeline di Lakeflow