Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Informazioni su come orchestrare i notebook e modularizzare il codice nei notebook. Guarda esempi e comprendi quando usare metodi alternativi per l'orchestrazione dei notebook.
Metodi di orchestrazione e modularizzazione del codice
La tabella seguente confronta i metodi disponibili per orchestrare i notebook e modularizzare il codice nei notebook.
| Metodo | Caso d'uso | Note |
|---|---|---|
| Attività Lakeflow | Orchestrazione notebook (scelta consigliata) | Metodo consigliato per orchestrare i notebook. Supporta flussi di lavoro complessi con dipendenze delle attività, pianificazione e trigger. Fornisce un approccio affidabile e scalabile per i carichi di lavoro di produzione, ma richiede l'installazione e la configurazione. |
| dbutils.notebook.run() | Orchestrazione dei notebook | Utilizza dbutils.notebook.run() se i job non possono supportare il tuo caso d'uso, ad esempio quando è necessario eseguire dinamicamente un notebook basato su un file di metadati (ETL basato sui metadati).Avvia un nuovo job temporaneo per ogni chiamata, che può aumentare il sovraccarico ed è privo di funzionalità di pianificazione avanzate. |
| file dell'area di lavoro | Modularizzazione del codice (scelta consigliata) | Metodo consigliato per la modularizzazione del codice. Modularizzare il codice in file di codice riutilizzabili archiviati nell'area di lavoro. Supporta il controllo della versione con repository e integrazione con gli IDE per migliorare il debug e gli unit test. Richiede un'installazione aggiuntiva per gestire i percorsi e le dipendenze dei file. |
| %run | Modularizzazione del codice | Usare %run se non è possibile accedere ai file dell'area di lavoro.Importare funzioni o variabili da altri notebook eseguendoli inline. Utile per la creazione di prototipi, ma può portare a codice strettamente associato che è più difficile da gestire. Non supporta il passaggio di parametri o il controllo della versione. |
%run contro dbutils.notebook.run()
Il comando %run consente di includere un altro notebook all'interno di un notebook. È possibile usare %run per modularizzare il codice inserendo le funzioni di supporto in un notebook separato. È anche possibile usarlo per concatenare i notebook che implementano i passaggi in un'analisi. Quando si usa %run, il notebook richiamato viene eseguito immediatamente e le funzioni e le variabili definite in esso diventano disponibili nel notebook chiamante.
L'API dbutils.notebook integra %run perché consente di passare i parametri a e restituire valori da un notebook. In questo modo è possibile creare flussi di lavoro e pipeline complessi con dipendenze. Ad esempio, è possibile ottenere un elenco di file in una directory e passare i nomi a un altro notebook, che è impossibile con %run. È anche possibile creare flussi di lavoro if-then-else in base ai valori restituiti.
A differenza di %run, il metodo dbutils.notebook.run() avvia un nuovo processo per eseguire il notebook.
Come tutte le API dbutils, questi metodi sono disponibili solo in Python e Scala. Tuttavia, è possibile usare dbutils.notebook.run() per richiamare un notebook R.
Usare %run per importare un notebook
In questo esempio il primo notebook definisce una funzione, reverse, disponibile nel secondo notebook dopo aver usato il comando magic %run per eseguire shared-code-notebook.
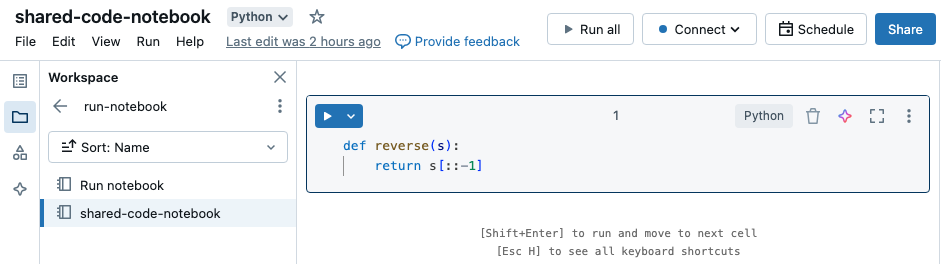
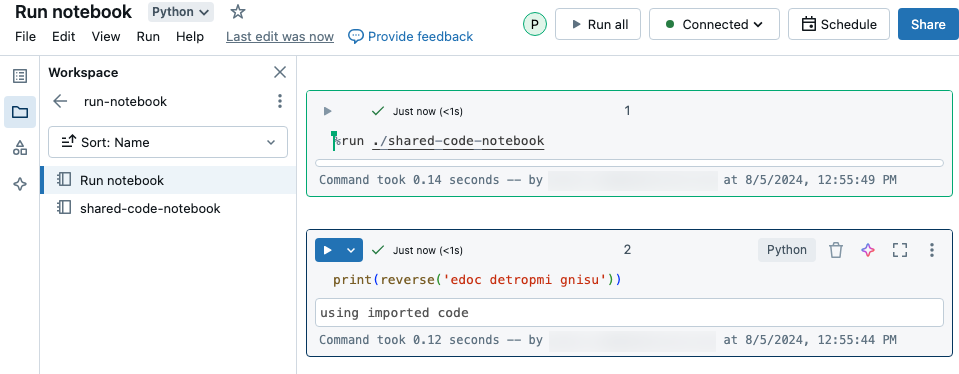
Poiché entrambi i notebook si trovano nella stessa directory nell'area di lavoro, usare il prefisso ./ in ./shared-code-notebook per indicare che il percorso deve essere risolto in relazione al notebook attualmente in esecuzione. È possibile organizzare i notebook in directory, ad esempio %run ./dir/notebook, o usare un percorso assoluto, ad esempio %run /Users/username@organization.com/directory/notebook.
Nota
- Il comando
%rundeve trovarsi in una cella da solo, perché esegue l'intero notebook inline. - Non puoi usare per eseguire un file Python e importare le entità definite in tale file in un notebook. Per importare da un file Python, vedere Modularizzare il codice utilizzando i file. In alternativa, impacchetta il file in una libreria Python, crea una library Azure Databricks da tale libreria Python e installa la libreria nel cluster che usi per eseguire il tuo notebook.
- Quando si usa
%runper eseguire un notebook che contiene widget, per impostazione predefinita il notebook specificato viene eseguito con i valori predefiniti del widget. È anche possibile passare valori ai widget; vedere Usare i widget di Databricks con %run.
Utilizzare dbutils.notebook.run per avviare un nuovo lavoro
Eseguire un notebook e restituirne il valore di uscita. Il metodo avvia un lavoro effimero che viene eseguito immediatamente.
I metodi disponibili nell'API dbutils.notebook sono run e exit. Entrambi i parametri e i valori restituiti devono essere stringhe.
run(path: String, timeout_seconds: int, arguments: Map): String
Il parametro timeout_seconds controlla il timeout dell'esecuzione (0 indica che non viene eseguito alcun timeout). La chiamata a run genera un'eccezione se non viene completata entro l'ora specificata. Se Azure Databricks è inattivo per più di 10 minuti, l'esecuzione del notebook ha esito negativo indipendentemente dal timeout_seconds.
Il parametro arguments imposta i valori del widget del notebook di destinazione. In particolare, se il notebook in esecuzione ha un widget chiamato A, e si passa una coppia chiave-valore ("A": "B") come argomento della chiamata run(), recuperare il valore del widget A restituirà "B". È possibile trovare le istruzioni per la creazione e l'uso dei widget nella pagina dei widget di Databricks .
Nota
- Il parametro
argumentsaccetta solo caratteri latini (set di caratteri ASCII). L'utilizzo di caratteri non ASCII restituisce un errore. - I processi creati con l'API
dbutils.notebookdevono essere completati entro 30 giorni o meno.
run Utilizzo
Python
dbutils.notebook.run("notebook-name", 60, {"argument": "data", "argument2": "data2", ...})
Linguaggio di programmazione Scala
dbutils.notebook.run("notebook-name", 60, Map("argument" -> "data", "argument2" -> "data2", ...))
Passare dati strutturati tra notebook
Questa sezione illustra come passare dati strutturati tra notebook.
Python
# Example 1 - returning data through temporary views.
# You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
# return a name referencing data stored in a temporary view.
## In callee notebook
spark.range(5).toDF("value").createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
# Example 2 - returning data through DBFS.
# For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
## In callee notebook
dbutils.fs.rm("/tmp/results/my_data", recurse=True)
spark.range(5).toDF("value").write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(spark.read.format("parquet").load(returned_table))
# Example 3 - returning JSON data.
# To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
## In callee notebook
import json
dbutils.notebook.exit(json.dumps({
"status": "OK",
"table": "my_data"
}))
## In caller notebook
import json
result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
print(json.loads(result))
Linguaggio di programmazione Scala
// Example 1 - returning data through temporary views.
// You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
// return a name referencing data stored in a temporary view.
/** In callee notebook */
sc.parallelize(1 to 5).toDF().createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
val global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
// Example 2 - returning data through DBFS.
// For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
/** In callee notebook */
dbutils.fs.rm("/tmp/results/my_data", recurse=true)
sc.parallelize(1 to 5).toDF().write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(sqlContext.read.format("parquet").load(returned_table))
// Example 3 - returning JSON data.
// To return multiple values, use standard JSON libraries to serialize and deserialize results.
/** In callee notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
// Exit with json
dbutils.notebook.exit(jsonMapper.writeValueAsString(Map("status" -> "OK", "table" -> "my_data")))
/** In caller notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
val result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
println(jsonMapper.readValue[Map[String, String]](result))
Gestione degli errori
Questa sezione spiega come gestire gli errori.
Python
# Errors throw a WorkflowException.
def run_with_retry(notebook, timeout, args = {}, max_retries = 3):
num_retries = 0
while True:
try:
return dbutils.notebook.run(notebook, timeout, args)
except Exception as e:
if num_retries > max_retries:
raise e
else:
print("Retrying error", e)
num_retries += 1
run_with_retry("LOCATION_OF_CALLEE_NOTEBOOK", 60, max_retries = 5)
Linguaggio di programmazione Scala
// Errors throw a WorkflowException.
import com.databricks.WorkflowException
// Since dbutils.notebook.run() is just a function call, you can retry failures using standard Scala try-catch
// control flow. Here, we show an example of retrying a notebook a number of times.
def runRetry(notebook: String, timeout: Int, args: Map[String, String] = Map.empty, maxTries: Int = 3): String = {
var numTries = 0
while (true) {
try {
return dbutils.notebook.run(notebook, timeout, args)
} catch {
case e: WorkflowException if numTries < maxTries =>
println("Error, retrying: " + e)
}
numTries += 1
}
"" // not reached
}
runRetry("LOCATION_OF_CALLEE_NOTEBOOK", timeout = 60, maxTries = 5)
Eseguire più notebook simultaneamente
È possibile eseguire più notebook contemporaneamente usando costrutti scala e Python standard, ad esempio thread (ScalaPython) e Futures (Scala, Python). I notebook di esempio illustrano come usare questi costrutti.
- Scaricare i quattro notebook seguenti. I notebook sono scritti in Scala.
- Importare i notebook in una singola cartella nell'area di lavoro.
- Eseguire il notebook Esegui contemporaneamente.