Nota
L'accesso a questa pagina richiede l'autorizzazione. Puoi provare ad accedere o a cambiare directory.
L'accesso a questa pagina richiede l'autorizzazione. Puoi provare a cambiare directory.
Importante
La scalabilità automatica di Lakebase si trova in Beta nelle aree seguenti: eastus2, westeurope, westus.
La versione più recente di Lakebase Autoscaling include il calcolo autoscalabile, la possibilità di ridurre a zero, il branching e il ripristino istantaneo. Per il confronto delle funzionalità con Lakebase Provisioned, vedere scelta tra le versioni.
L'ETL inverso in Lakebase sincronizza le tabelle del catalogo Unity in Postgres in modo che le applicazioni possano usare direttamente i dati di lakehouse curati. Il lakehouse è ottimizzato per l'analisi e l'arricchimento, mentre Lakebase è progettato per carichi di lavoro operativi che richiedono query veloci e coerenza transazionale.
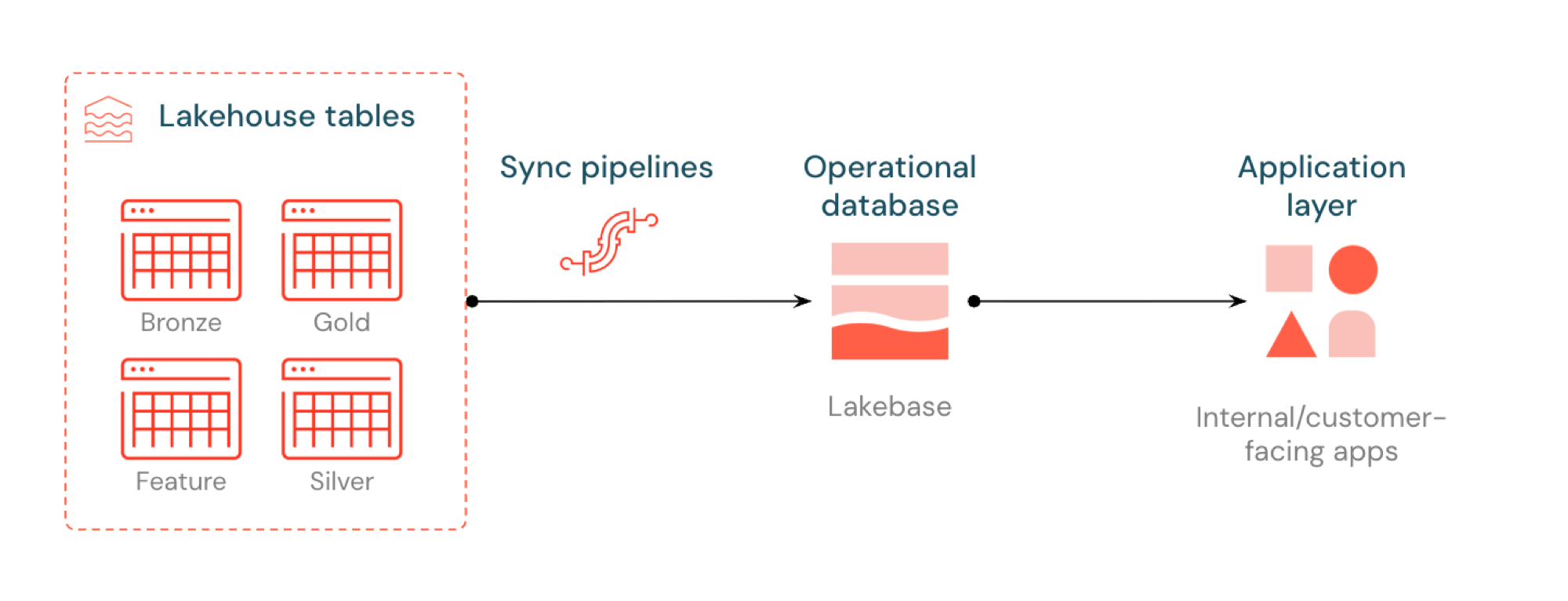
Che cos'è L'ETL inverso?
L'ETL inverso consente di spostare i dati di livello di analisi da Unity Catalog in Lakebase Postgres, in cui è possibile renderli disponibili per le applicazioni che necessitano di query a bassa latenza (sub-10 ms) e transazioni ACID complete. Consente di colmare il divario tra l'archiviazione analitica e i sistemi operativi mantenendo i dati curati utilizzabili nelle applicazioni in tempo reale.
Come funziona
Le tabelle sincronizzate di Databricks creano una copia gestita dei dati di Unity Catalog in Lakebase. Quando si crea una tabella sincronizzata, si ottiene:
- Nuova tabella del catalogo Unity (di sola lettura, gestita dalla pipeline di sincronizzazione)
- Una tabella Postgres in Lakebase (interrogabile dalle tue applicazioni)
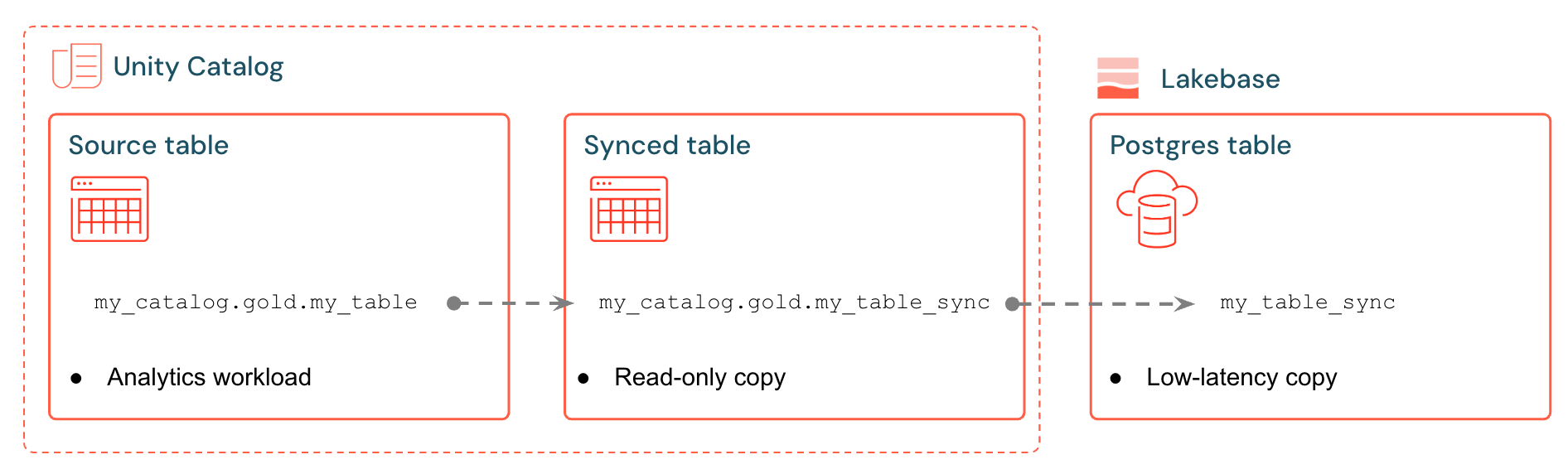
Ad esempio, è possibile sincronizzare tabelle gold, funzionalità ingegneriate o output ml da analytics.gold.user_profiles in una nuova tabella analytics.gold.user_profiles_syncedsincronizzata. In Postgres il nome dello schema del catalogo Unity diventa il nome dello schema Postgres, quindi viene visualizzato come "gold"."user_profiles_synced":
SELECT * FROM "gold"."user_profiles_synced" WHERE "user_id" = 12345;
Le applicazioni si connettono con i driver Postgres standard ed eseguono query sui dati sincronizzati insieme al proprio stato operativo.
Le pipeline di sincronizzazione utilizzano le Lakeflow Spark Declarative Pipelines gestite per aggiornare continuamente sia la tabella sincronizzata di Unity Catalog che la tabella Postgres con le modifiche dalla tabella di origine. Ogni sincronizzazione può usare fino a 16 connessioni al database Lakebase.
Lakebase Postgres supporta fino a 1.000 connessioni simultanee con garanzie transazionali, in modo che le applicazioni possano leggere dati arricchiti gestendo al tempo stesso inserimenti, aggiornamenti ed eliminazioni nello stesso database.
Modalità di sincronizzazione
Scegliere la modalità di sincronizzazione corretta in base alle esigenze dell'applicazione:
| Mode | Description | Ideale per | Performance |
|---|---|---|---|
| Snapshot | Copia monouso di tutti i dati | Configurazione iniziale o analisi cronologica | 10 volte più efficiente se si modificano >10% di dati di origine |
| Attivato | Aggiornamenti pianificati eseguiti su richiesta o a intervalli | Le dashboard, aggiornate ogni ora/giorno | Buon rapporto costo/ritardo. Costoso se si eseguono <intervalli di 5 minuti |
| Continuo | Streaming in tempo reale con secondi di latenza | Applicazioni in tempo reale (costo più elevato a causa del calcolo dedicato) | Ritardo più basso, costo più alto. Intervalli minimi di 15 secondi |
Le modalità attivate e continue richiedono l'abilitazione del feed di dati delle modifiche (CDF) nella tabella di origine. Se CDF non è abilitato, verrà visualizzato un avviso nell'interfaccia utente con il comando esatto ALTER TABLE da eseguire. Per altre informazioni sul feed di dati delle modifiche, vedere Usare il feed di dati delle modifiche Delta Lake in Databricks.
Caso d'uso di esempio
L'ETL inverso con Lakebase supporta scenari operativi comuni:
- Motori di personalizzazione che necessitano di profili utente aggiornati sincronizzati in Databricks Apps
- Applicazioni che gestiscono stime del modello o valori di funzionalità calcolati nella lakehouse
- Dashboard rivolti ai clienti che visualizzano indicatori KPI in tempo reale
- Servizi di rilevamento delle frodi che richiedono punteggi di rischio disponibili per un'azione immediata
- Strumenti di supporto che arricchiscono i record dei clienti con dati curati dal lakehouse
Creare una tabella sincronizzata (UI)
Il flusso di lavoro dell'interfaccia utente è descritto di seguito.
Prerequisiti
È necessario:
- Un'area di lavoro di Databricks con Lakebase abilitata.
- Un progetto Lakebase (vedere Creare un progetto).
- Tabella del catalogo Unity con dati curati.
- Autorizzazioni per creare tabelle sincronizzate.
Per la pianificazione della capacità e la compatibilità dei tipi di dati, vedere Tipi di dati e compatibilità e pianificazione della capacità.
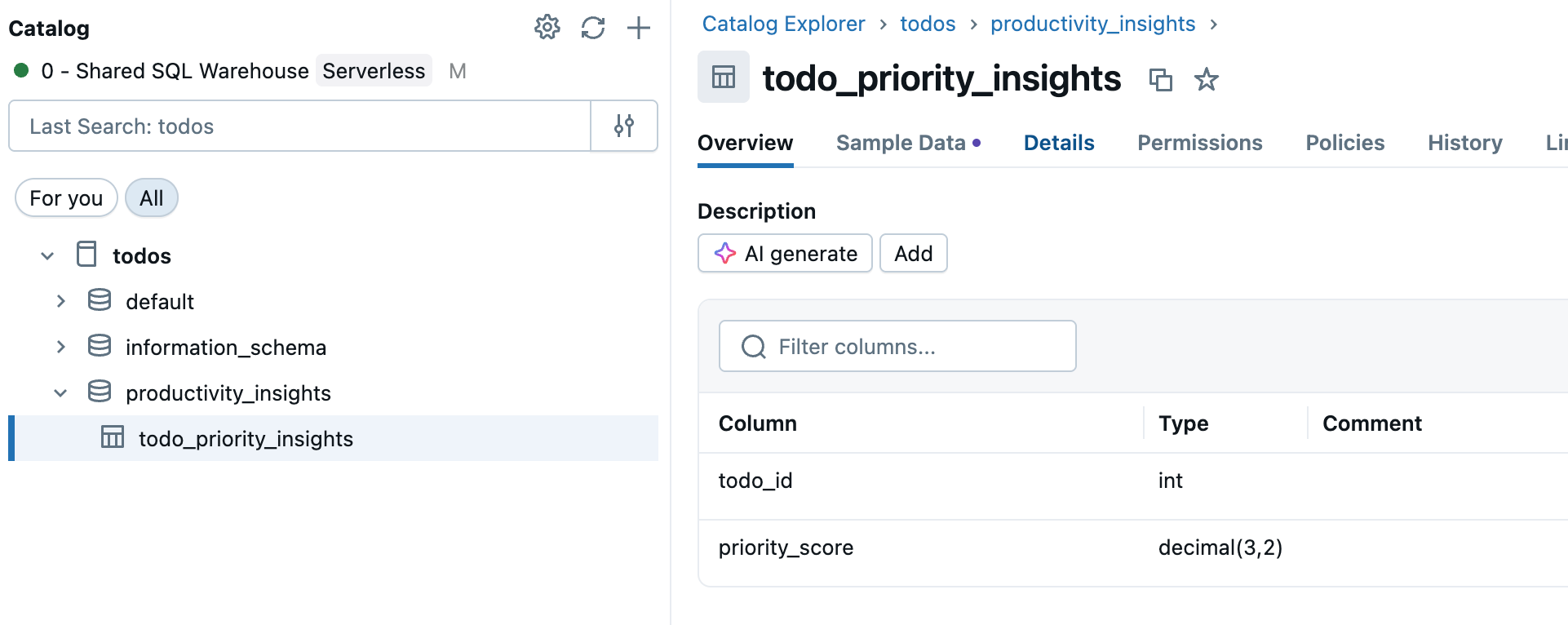
Passaggio 1: Selezionare la tabella di origine
Passare a Catalogo nella barra laterale dell'area di lavoro e selezionare la tabella del catalogo Unity da sincronizzare.
Passaggio 2: Abilitare il feed di dati delle modifiche (se necessario)
Se si prevede di usare le modalità di sincronizzazione Attivate o Continua, la tabella di origine richiede l'abilitazione del feed di dati delle modifiche. Controllare se la tabella dispone già di CDF abilitata oppure eseguire questo comando in un editor SQL o in un notebook:
ALTER TABLE your_catalog.your_schema.your_table
SET TBLPROPERTIES (delta.enableChangeDataFeed = true)
Sostituire your_catalog.your_schema.your_table con il nome effettivo della tabella.
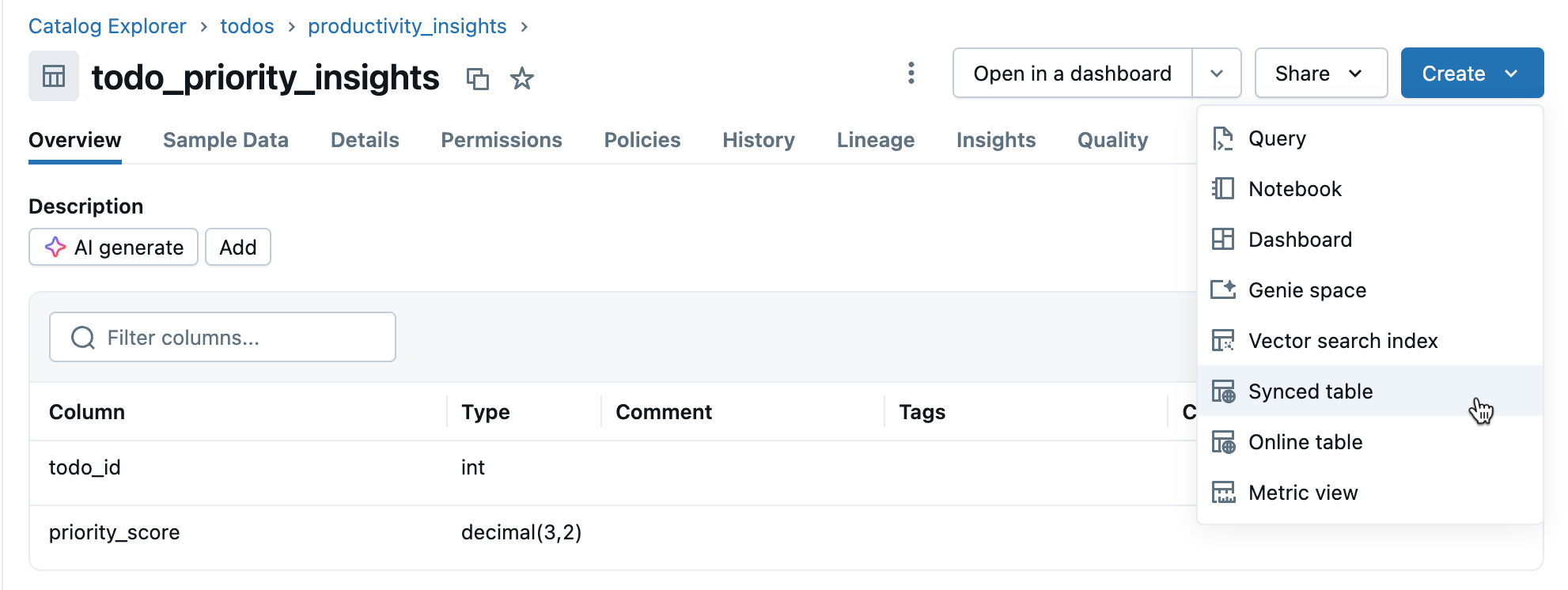
Passaggio 3: Creare una tabella sincronizzata
Fare clic su Crea>tabella sincronizzata nella vista dettagli della tabella.
Passaggio 4: Configurare
Nella finestra di dialogo Crea tabella sincronizzata :
- Nome tabella: immettere un nome per la tabella sincronizzata(viene creato nello stesso catalogo e schema della tabella di origine). In questo modo viene creata sia una tabella sincronizzata del catalogo Unity che una tabella Postgres su cui è possibile eseguire query.
- Tipo di database: scegliere Lakebase Serverless (scalabilità automatica).
- Modalità di sincronizzazione: scegliere Snapshot, Attivato o Continuo in base alle proprie esigenze (vedere le modalità di sincronizzazione precedenti).
- Configurare le selezioni di progetto, ramo e database.
- Verificare che la chiave primaria sia corretta (in genere rilevata automaticamente).
Se hai scelto la modalità Triggered o Continua e non hai ancora abilitato il Feed dati delle modifiche, verrà visualizzato un avviso con il comando esatto da eseguire. Per domande sulla compatibilità dei tipi di dati, vedere Tipi di dati e compatibilità.
Fare clic su Crea per creare la tabella sincronizzata.
Passaggio 5: Monitorare
Dopo la creazione, monitorare la tabella sincronizzata in Catalog. La scheda Panoramica mostra lo stato di sincronizzazione, la configurazione, lo stato della pipeline e il timestamp dell'ultima sincronizzazione. Usare Sincronizzazione ora per l'aggiornamento manuale.
Tipi di dati e compatibilità
I tipi di dati di Unity Catalog vengono mappati ai tipi Postgres durante la creazione di tabelle sincronizzate. I tipi complessi (ARRAY, MAP, STRUCT) vengono archiviati come JSONB in Postgres.
| Tipo di colonna di origine | Tipo di colonna Postgres |
|---|---|
| BIGINT | BIGINT |
| BINARY | BYTEA |
| BOOLEAN | BOOLEAN |
| DATTERO | DATTERO |
| DECIMAL(p,s) | NUMERICO |
| DOPPIO | PRECISIONE DOPPIA |
| FLOAT | REALE |
| INT | INTEGER |
| INTERVAL | INTERVAL |
| SMALLINT | SMALLINT |
| filo | TESTO |
| TIMESTAMP | TIMESTAMP CON FUSO ORARIO |
| TIMESTAMP_NTZ | TIMESTAMP SENZA FUSO ORARIO |
| TINYINT | SMALLINT |
| ARRAY<tipoElemento> | JSONB |
| MAP<keyType,valueType> | JSONB |
| STRUCT<fieldName:fieldType[, ...]> | JSONB |
Annotazioni
I tipi GEOGRAPHY, GEOMETRY, VARIANT e OBJECT non sono supportati.
Gestire caratteri non validi
Alcuni caratteri come byte Null (0x00) sono consentiti nelle colonne STRING, ARRAY, MAP o STRUCT del catalogo Unity, ma non supportate nelle colonne POSTGRES TEXT o JSONB. Ciò può causare errori di sincronizzazione con errori come:
ERROR: invalid byte sequence for encoding "UTF8": 0x00
ERROR: unsupported Unicode escape sequence DETAIL: \u0000 cannot be converted to text
Soluzioni:
Purificare i campi stringa: rimuovere i caratteri non supportati prima della sincronizzazione. Per i byte Null nelle colonne STRING:
SELECT REPLACE(column_name, CAST(CHAR(0) AS STRING), '') AS cleaned_column FROM your_tableConverti in BINARY: per le colonne STRING in cui è necessario conservare i byte non elaborati, convertire in tipo BINARY.
Pianificazione della capacità
Quando si pianifica l'implementazione di ETL inversa, prendere in considerazione i requisiti delle risorse seguenti:
- Utilizzo connessione: ogni tabella sincronizzata usa fino a 16 connessioni al database Lakebase, che vengono conteggiate per il limite di connessione dell'istanza.
- Limiti di dimensioni: il limite totale delle dimensioni dei dati logici in tutte le tabelle sincronizzate è di 8 TB. Le singole tabelle non hanno limiti, ma Databricks consiglia di non superare 1 TB per le tabelle che richiedono aggiornamenti.
-
Requisiti di denominazione: i nomi di database, schema e tabella possono contenere solo caratteri alfanumerici e caratteri di sottolineatura (
[A-Za-z0-9_]+). - Evoluzione dello schema: sono supportate solo le modifiche dello schema additive (ad esempio l'aggiunta di colonne) per le modalità attivate e continue.
- Frequenza di aggiornamento: Lakebase Autoscaling supporta nella pipeline di sincronizzazione scritture continue e con trigger a circa 150 righe al secondo per unità di capacità (CU) e scritture snapshot fino a 2.000 righe al secondo per CU.
Eliminare una tabella sincronizzata
Per eliminare una tabella sincronizzata, è necessario rimuoverla sia dal catalogo unity che da Postgres:
Elimina da Unity Catalog: nel Catalog, trova la tua tabella sincronizzata, fai clic sull'icona del
 , quindi seleziona Elimina. Ciò arresta gli aggiornamenti dei dati ma lascia la tabella in Postgres.
, quindi seleziona Elimina. Ciò arresta gli aggiornamenti dei dati ma lascia la tabella in Postgres.Eliminare da Postgres: connettersi al database Lakebase ed eliminare la tabella per liberare spazio:
DROP TABLE your_database.your_schema.your_table;
È possibile usare l'editor SQL o gli strumenti esterni per connettersi a Postgres.
Ulteriori informazioni
| Task | Description |
|---|---|
| Creare un progetto | Configurare un progetto Lakebase |
| Connettersi al database | Informazioni sulle opzioni di connessione per Lakebase |
| Registrare il database nel catalogo unity | Rendere visibili i dati di Lakebase in Unity Catalog per una governance unificata e le query tra più origini. |
| Integrazione del catalogo Unity | Informazioni sulla governance e sulle autorizzazioni |
Altre opzioni
Per la sincronizzazione dei dati in sistemi non Databricks, vedere Soluzioni ETL inverse di Partner Connect , ad esempio Census o Hightouch.