Nota
L'accesso a questa pagina richiede l'autorizzazione. Puoi provare ad accedere o a cambiare directory.
L'accesso a questa pagina richiede l'autorizzazione. Puoi provare a cambiare directory.
Usare le cartelle Git di Databricks nei flussi CI/CD per mantenere il lavoro nel controllo del codice sorgente e integrarlo con i flussi di lavoro di ingegneria dei dati. Per una panoramica più ampia di CI/CD con Azure Databricks, vedere CI/CD in Azure Databricks.
Flussi di utilizzo
Automazione per le cartelle Git si concentra sulla configurazione iniziale delle cartelle e sull'API REST Azure Databricks Repos per automatizzare le operazioni Git dai processi di Azure Databricks. Prima di creare l'automazione:
- Esaminare i repository Git remoti che verranno usati.
- Scegliere i repository e i rami corretti per ogni fase (sviluppo, integrazione, gestione temporanea, produzione).
Esistono tre flussi principali:
- Flusso di amministrazione: un amministratore dell'area di lavoro di Azure Databricks crea cartelle di primo livello per ospitare cartelle Git di produzione. L'amministratore clona un repository e un ramo durante la creazione di ogni cartella e può denominarli per scopo (ad esempio, "Produzione", "Test" o "Staging"). Vedere Creare una cartella Git di produzione.
-
Flusso utente: un utente crea una cartella
/Workspace/Users/<email>/Git da un repository remoto, lavora su un branch specifico dell'utente e esegue il push dei commit nel repository remoto. Consulta Collaborare con le cartelle Git. - Flusso di Merge: dopo il push da una cartella Git, gli utenti aprono le pull request. Quando un PR viene fuso, l'automazione può estrarre le modifiche nelle cartelle Git di produzione utilizzando l'API Repos di Azure Databricks.
Collaborare con le cartelle Git
Collaborare con altri utenti eseguendo il pull e il push delle modifiche dall'interfaccia utente di Azure Databricks. Un modello comune consiste nell'usare una funzionalità o un ramo di sviluppo per aggregare il lavoro.
Per collaborare a un ramo di funzionalità:
- Clonare il repository Git esistente nell'area di lavoro di Databricks.
- Nell'interfaccia utente delle cartelle Git, crea un branch delle funzionalità a partire dal branch principale. È possibile usare più rami di funzionalità in base alle esigenze.
- Modificare i notebook di Azure Databricks e altri file nel repository.
- Effettua il commit e il push delle modifiche nel repository remoto.
- Altri collaboratori possono clonare il repository nella propria cartella utente. Funzionano in un ramo, modificano notebook e file nella cartella Git, quindi eseguono il commit e il push nel remoto.
- Quando si è pronti, creare una richiesta pull nel provider Git, revisionare con il team e fondere nel ramo di distribuzione.
Annotazioni
Databricks consiglia a ogni sviluppatore di lavorare nel proprio ramo. Per la risoluzione dei conflitti di merge, vedere Risolvere i conflitti di merge.
Scegliere un approccio CI/CD
Databricks consiglia i bundle di asset di Databricks per creare pacchetti e distribuire flussi di lavoro CI/CD. Se si preferisce distribuire solo codice nell'area di lavoro, è possibile usare invece una cartella Git di produzione. Per una panoramica più ampia di CI/CD, vedere CI/CD in Azure Databricks.
Suggerimento
Definire risorse come processi e pipeline nell'origine usando bundle, quindi creare, distribuire e gestirle nelle cartelle Git dell'area di lavoro. Vedere Collaborare ai bundle nell'area di lavoro.
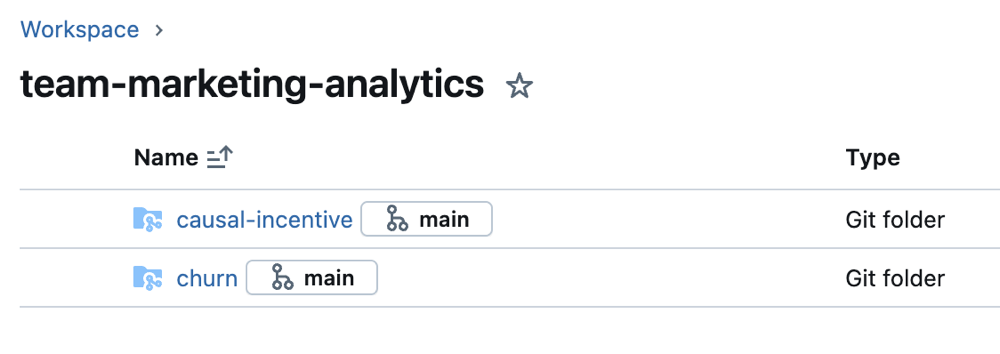
Creare una cartella Git di produzione
Le cartelle Git di produzione sono diverse dalle cartelle Git a livello di utente in /Workspace/Users/. Le cartelle a livello di utente sono checkout locali in cui gli utenti sviluppano e eseguono il push delle modifiche. Le cartelle Git di produzione vengono create dagli amministratori all'esterno delle cartelle utente, contengono rami di distribuzione e sono l'origine per i flussi di lavoro automatizzati. Devono essere aggiornati solo dall'automazione quando le pull request vengono mergeate nei branch di distribuzione. Limitare l'accesso delle cartelle Git di produzione alla sola esecuzione per la maggior parte degli utenti. Consentire solo agli amministratori e alle entità servizio di Azure Databricks di modificarle.
Per creare una cartella Git di produzione:
Scegliere il repository Git e il ramo per la distribuzione.
Creare o usare un principale del servizio e configurare una credenziale Git per consentire l'accesso a tale repository.
Creare una cartella Git di Azure Databricks per il repository e il relativo branch in una sottocartella all'interno di Area di lavoro (ad esempio, per progetto, team o fase).
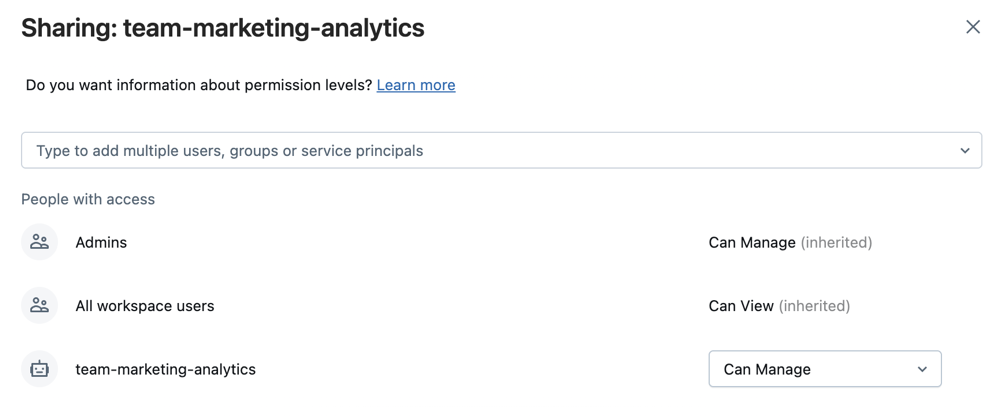
Selezionare la cartella, quindi Condividi (o fare clic con il pulsante destro del mouse su Condividi (autorizzazioni) nell'albero dell'area di lavoro.
Assegnare i livelli di autorizzazione:
- Può essere eseguita per gli utenti del progetto che devono eseguire flussi di lavoro.
- Può essere eseguito per qualsiasi principale del servizio di Azure Databricks che gestisce l'automazione su questa cartella.
- Facoltativamente Può visualizzare per tutti gli utenti dell'area di lavoro, per supportare l'individuazione e la condivisione.
Fare clic su Aggiungi.
Mantenere sincronizzata la cartella Git di produzione con il ramo remoto usando una di queste opzioni:
- CI/CD esterno: usare strumenti come GitHub Actions per recuperare i commit più recenti quando una pull request viene unita al ramo di distribuzione. Per un esempio, vedere Eseguire un flusso di lavoro CI/CD che aggiorna una cartella Git.
- Processo pianificato: se ci/CD esterno non è disponibile, eseguire un processo pianificato che aggiorna la cartella Git. Usare un notebook semplice che funziona secondo una pianificazione.
from databricks.sdk import WorkspaceClient w = WorkspaceClient() w.repos.update(w.workspace.get_status(path="<git-folder-workspace-full-path>").object_id, branch="<branch-name>")
Per altre informazioni sull'automazione con l'API Repos, vedere la documentazione dell'API REST di Databricks per Repos.