Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Per creare applicazioni client resilienti e efficaci, è fondamentale comprendere il failover nel Azure Managed Redisservice. Un failover può far parte delle operazioni di gestione pianificate oppure può essere causato da errori hardware o di rete non pianificati. Un uso comune del failover della cache si verifica quando il servizio di gestione applica patch ai file binari di Managed Redis di Azure.
In questo articolo sono disponibili queste informazioni:
- Cos'è un failover?
- Modalità di esecuzione del failover durante l'applicazione di patch.
- Come creare un'applicazione client resiliente.
Cos'è un failover?
Iniziamo con una panoramica del failover per Managed Redis di Azure.
Riepilogo rapido dell'architettura cache
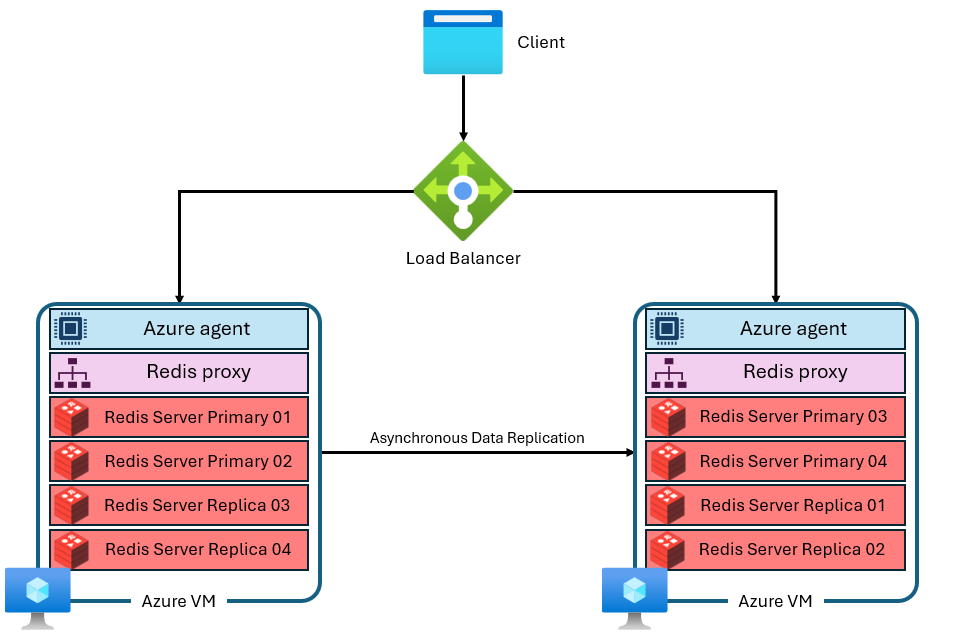
Una cache viene costruita da più macchine virtuali con indirizzi IP separati e privati. Ogni macchina virtuale (o "nodo") esegue più processi del server Redis (denominati "partizioni") in parallelo. Più partizioni consentono un utilizzo più efficiente delle vCPU in ogni macchina virtuale e prestazioni superiori. Non tutte le partizioni Redis primarie si trovano nello stesso nodo/macchina virtuale. Le partizioni primarie e di replica vengono invece distribuite in entrambi i nodi. Poiché le partizioni primarie usano più risorse della CPU rispetto alle partizioni di replica, questo approccio consente l'esecuzione in parallelo di più partizioni primarie. In ogni nodo è presente un processo proxy ad alte prestazioni per gestire le partizioni e la gestione delle connessioni e attivare la riparazione automatica. Una partizione potrebbe essere inattiva mentre le altre rimangono disponibili.
Per informazioni dettagliate sull'architettura redis gestita di Azure, vedere here.
Spiegazione di un failover
Un failover si verifica quando una o più partizioni di replica si autopromuovono per diventare partizioni primarie. In questi casi, le partizioni primarie precedenti chiudono le connessioni esistenti. Un failover potrebbe essere pianificato o non pianificato.
Un failover pianificato viene eseguito in due momenti diversi:
- Aggiornamenti di sistema, come l'applicazione di patch a Redis o gli aggiornamenti del sistema operativo.
- Operazioni di gestione, come ridimensionamento e riavvio.
Poiché i nodi ricevono una notifica anticipata dell'aggiornamento, possono scambiare in modo cooperativo i ruoli e aggiornare rapidamente il servizio di bilanciamento del carico della modifica. Un failover pianificato termina in genere in meno di un secondo.
Un failover non pianificato può verificarsi a causa di un errore hardware, di un errore di rete o di altre interruzioni impreviste di uno o più nodi nel cluster. La partizione o le partizioni di replica nel nodo o nei nodi rimanenti si autopromuoveranno a primarie per mantenere la disponibilità, ma il processo richiede più tempo. Una partizione di replica deve innanzitutto rilevare che la partizione primaria non è disponibile prima di avviare il processo di failover. La partizione di replica deve anche verificare che questo errore non pianificato non sia temporaneo o locale per evitare un failover non necessario. Questo ritardo nel rilevamento significa che un failover non pianificato termina in genere entro 10-15 secondi.
Come vengono applicate le patch?
Il servizio Azure Redis gestito aggiorna regolarmente la cache con le funzionalità e le correzioni più recenti della piattaforma. Per applicare patch a una cache, il servizio segue questa procedura:
- Il servizio crea nuove macchine virtuali aggiornate per sostituire tutte le macchine virtuali a cui applicare la patch.
- Promuove quindi una delle nuove macchine virtuali come macchina principale del cluster.
- Uno per uno, tutti i nodi a cui viene applicata la patch vengono rimossi dal cluster. Tutte le partizioni in queste macchine virtuali verranno abbassate di livello e ne verrà eseguita la migrazione a una delle nuove macchine virtuali.
- Infine, tutte le macchine virtuali sostituite vengono eliminate.
A ogni partizione di una cache in cluster viene applicata una patch separatamente e la partizione non chiude le connessioni ad altre partizioni.
Annotazioni
È possibile applicare patch a più cache nella stessa area contemporaneamente. Se ciò influisce sull'applicazione, configurare le pianificazioni di manutenzione in modo che ogni cache venga applicata a patch in un momento diverso.
Poiché la sincronizzazione completa dei dati avviene prima della ripetizione del processo, è improbabile che nella cache si verifichi una perdita di dati. È possibile proteggersi ulteriormente dalla perdita di dati esportando i dati e abilitando la persistenza.
Caricamento della cache aggiuntivo
Ogni volta che si verifica un failover, le cache devono replicare i dati da un nodo all'altro. Questa replica causa un aumento del carico sia nella memoria del server che nella CPU. Se l'istanza della cache è già caricata pesantemente, le applicazioni client potrebbero riscontrare un aumento della latenza. In casi estremi, le applicazioni client potrebbero ricevere eccezioni di timeout.
In che modo un failover influisce sull'applicazione client?
Le applicazioni client potrebbero ricevere alcuni errori dall'istanza di Redis gestita su Azure. Il numero di errori rilevati da un’applicazione client dipende dal numero di operazioni in sospeso nella connessione al momento del failover. Per tutte le connessioni instradate tramite il nodo che ha chiuso le rispettive connessioni si verificheranno errori.
Molte librerie client possono generare diversi tipi di errori in caso di interruzione delle connessioni, tra cui:
- Eccezioni di timeout
- Eccezioni di connessione
- Eccezioni socket
Il numero e il tipo di eccezioni dipendono dalla posizione della richiesta nel percorso del codice nel momento in cui la cache chiude le connessioni. Ad esempio, un'operazione che invia una richiesta ma non ha ricevuto una risposta quando si verifica il failover potrebbe ricevere un'eccezione di timeout. Le nuove richieste sull'oggetto connessione chiusa ricevono eccezioni di connessione fino a quando la riconnessione non viene eseguita correttamente.
La maggior parte delle librerie client tenta di riconnettersi alla cache, se configurate per farlo. Tuttavia, i bug imprevisti possono occasionalmente mettere gli oggetti della libreria in uno stato di irreversibilità. Se gli errori vengono mantenuti per più tempo rispetto a un periodo di tempo preconfigurato, l'oggetto connessione deve essere ricreato. In Microsoft.NET e in altri linguaggi orientati agli oggetti, è possibile ricreare la connessione senza riavviare l'applicazione usando un modello ForceReconnect.
Quali sono gli aggiornamenti inclusi nella manutenzione?
La manutenzione include questi aggiornamenti:
- Aggiornamenti del server Redis: qualsiasi aggiornamento o patch dei file binari del server Redis.
- Aggiornamenti delle macchine virtuali: tutti gli aggiornamenti della macchina virtuale che ospitano il servizio Redis. Gli aggiornamenti delle macchine virtuali includono l'applicazione di patch ai componenti software nell'ambiente host, l'aggiornamento dei componenti di rete o la rimozione delle autorizzazioni.
La cronologia di manutenzione viene visualizzata nel portale di Azure?
Per informazioni sulla cronologia di manutenzione nel portale di Azure, controllare il log Azure Activity per l'istanza della cache. L'evento "healthevent" viene generato all'inizio della manutenzione.
Per ricevere automaticamente le notifiche, configurare un avviso nel log attività.
Modifiche di rete/configurazione client
Alcune modifiche alla configurazione della rete lato client possono causare l'errore Nessuna connessione disponibile. Tali modifiche possono includere:
- Scambio dell'indirizzo IP virtuale di un'applicazione client tra slot di staging e di produzione.
- Ridimensionamento delle dimensioni o del numero di istanze dell'applicazione.
Queste modifiche possono causare un problema di connettività che in genere dura meno di un minuto. L'applicazione client probabilmente perde la connessione ad altre risorse di rete esterne, ma anche al servizio Redis gestito Azure.
Creare resilienza integrata
Non è possibile evitare completamente i failover. Invece è bene scrivere le applicazioni client in modo che siano resilienti alle interruzioni di connessione e alle richieste non riuscite. La maggior parte delle librerie client si riconnette automaticamente all'endpoint della cache, ma alcuni di essi tentano di ripetere le richieste non riuscite. A seconda dello scenario dell'applicazione, potrebbe essere opportuno usare la logica di ripetizione dei tentativi con il backoff.
Come si rende resiliente l'applicazione?
Fare riferimento a questi modelli di progettazione per creare client resilienti, in particolare l'interruttore e i modelli di ripetizione dei tentativi:
- Modelli di affidabilità - Modelli di progettazione cloud
- Indicazioni sulla ripetizione dei tentativi per i servizi di Azure - Procedure consigliate per le applicazioni cloud
- Implementare nuovi tentativi con backoff esponenziale