Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Suggerimento
Questo contenuto è un estratto dell'eBook Architecting Cloud Native .NET Applications for Azure, disponibile in .NET Docs o come PDF scaricabile gratuito che può essere letto offline.

Come abbiamo visto in questo libro, un approccio nativo del cloud cambia il modo in cui si progettano, distribuiscono e gestiscono le applicazioni. Cambia anche la modalità di gestione e archiviazione dei dati.
La figura 5-1 mette a confronto le differenze.
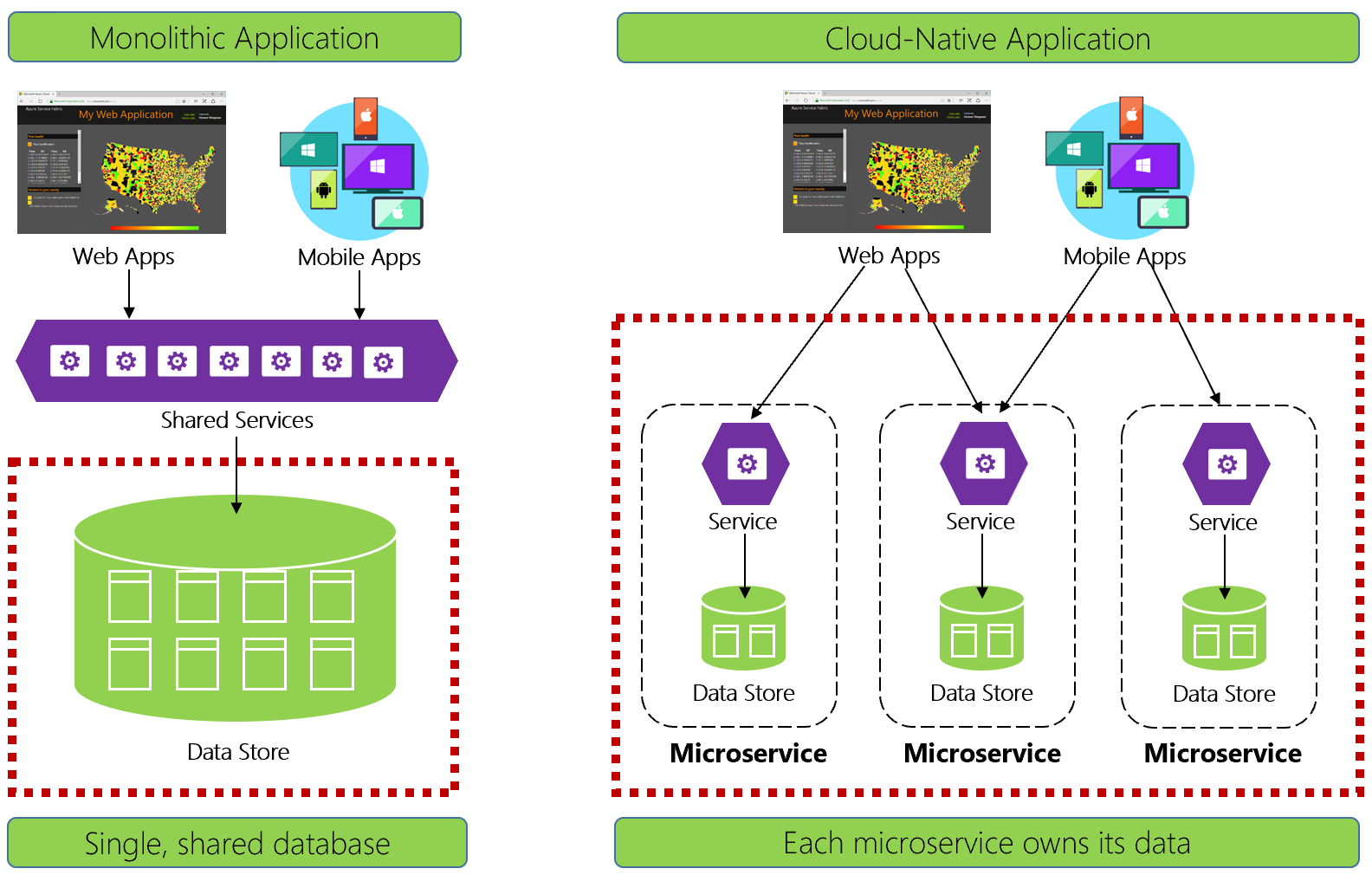
Figura 5-1. Gestione dei dati nelle applicazioni native del cloud
Gli sviluppatori esperti riconosceranno facilmente l'architettura a sinistra della figura 5-1. In questa applicazione monolitica, i componenti del servizio aziendale si collocano insieme in un livello di servizi condivisi, condividendo i dati da un singolo database relazionale.
In molti modi, un singolo database mantiene semplice la gestione dei dati. L'esecuzione di query sui dati tra più tabelle è semplice. Le modifiche ai dati vengono apportate insieme o tutte annullate. Le transazioni ACID garantiscono coerenza assoluta e immediata.
Progettando per il cloud nativo, adottiamo un approccio diverso. Sul lato destro della figura 5-1 si noti come le funzionalità aziendali segregino in microservizi di piccole dimensioni indipendenti. Ogni microservizio incapsula una funzionalità aziendale specifica e i propri dati. Il database monolitico si scompone in un modello di dati distribuito con molti database più piccoli, ognuno allineato a un microservizio. Quando il fumo viene cancellato, viene visualizzata una progettazione che espone un database per ogni microservizio.
Database per microservizio, perché?
Questo database per microservizio offre molti vantaggi, in particolare per i sistemi che devono evolversi rapidamente e supportare scalabilità massiva. Con questo modello...
- I dati di dominio vengono incapsulati all'interno del servizio
- Lo schema dei dati può evolversi senza influire direttamente su altri servizi
- Ogni archivio dati può essere ridimensionato in modo indipendente
- Un errore dell'archivio dati in un servizio non influisce direttamente su altri servizi
La separazione dei dati consente anche a ogni microservizio di implementare il tipo di archivio dati ottimizzato per il carico di lavoro, le esigenze di archiviazione e i modelli di lettura/scrittura. Le scelte includono sistemi di gestione dei dati relazionali, documentali, chiave-valore e persino basati su grafo.
La figura 5-2 presenta il principio della persistenza poliglotta in un sistema nativo del cloud.
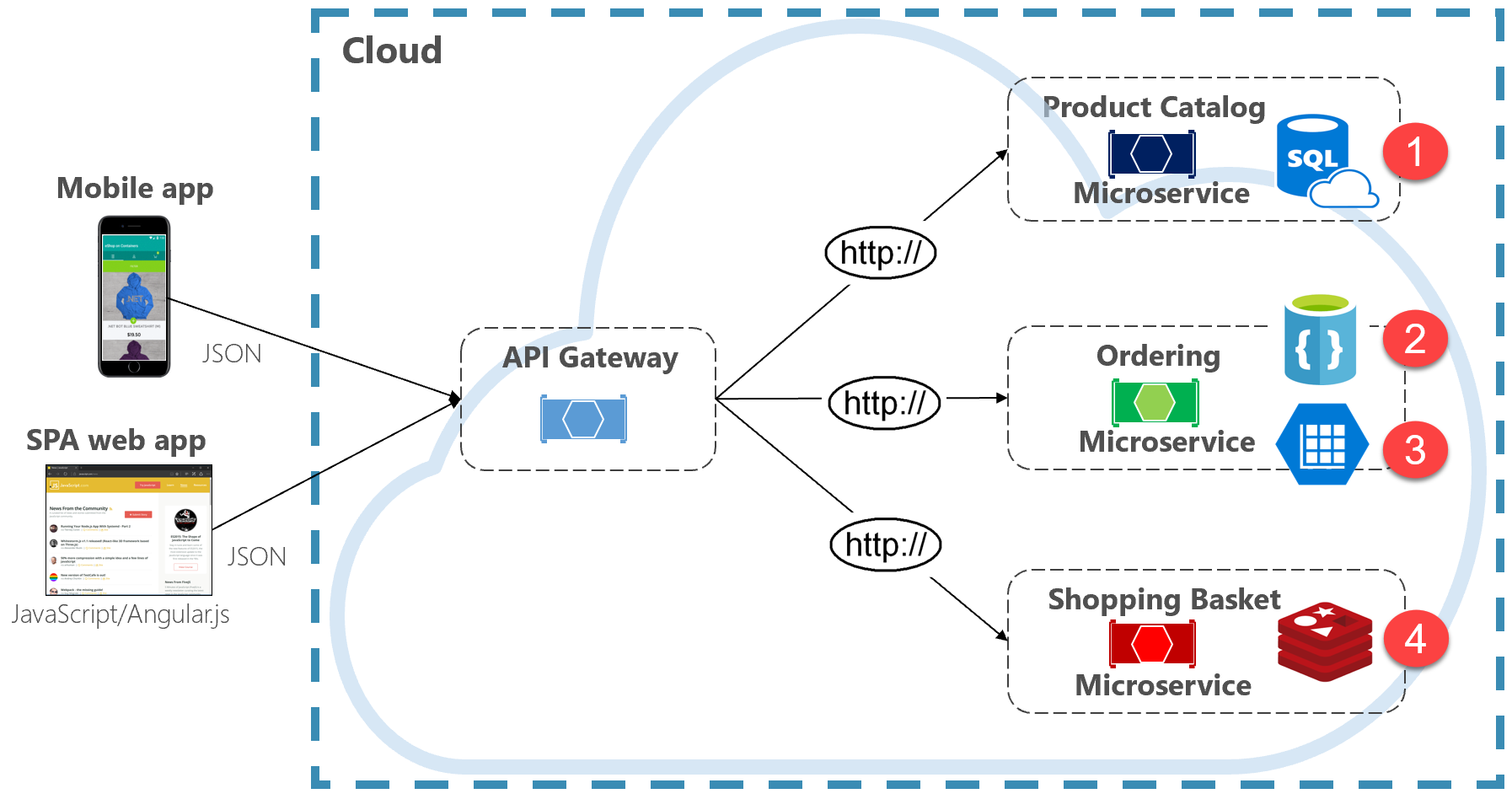
Figura 5-2. Persistenza dei dati poliglotta
Si noti nella figura precedente come ogni microservizio supporta un tipo diverso di archivio dati.
- Il microservizio del catalogo prodotti utilizza un database relazionale per supportare la struttura relazionale avanzata dei dati sottostanti.
- Il microservizio carrello acquisti utilizza una cache distribuita che supporta l'archivio dati semplice chiave-valore.
- Il microservizio di ordinamento utilizza sia un database di documenti NoSql per le operazioni di scrittura insieme a un archivio chiave/valore altamente denormalizzato per supportare volumi elevati di operazioni di lettura.
Sebbene i database relazionali rimangano rilevanti per i microservizi con dati complessi, i database NoSQL hanno guadagnato una notevole popolarità. Offrono scalabilità elevata e disponibilità elevata. La loro natura senza schema consente agli sviluppatori di allontanarsi da un'architettura di classi di dati tipizzata e ORM che rendono le modifiche costose e dispendiose in termini di tempo. Più avanti in questo capitolo vengono illustrati i database NoSQL.
Anche se l'incapsulamento dei dati in microservizi separati può aumentare agilità, prestazioni e scalabilità, presenta anche molte sfide. Nella sezione successiva verranno illustrate queste sfide insieme ai modelli e alle procedure per risolverli.
Interrogazioni tra servizi
Anche se i microservizi sono indipendenti e si concentrano su funzionalità funzionali specifiche, ad esempio inventario, spedizione o ordinamento, spesso richiedono l'integrazione con altri microservizi. Spesso l'integrazione implica un microservizio che esegue query su un altro per i dati. La figura 5-3 illustra lo scenario.
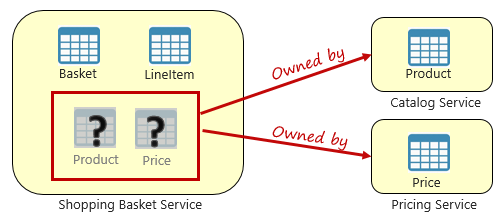
Figura 5-3. Esecuzione di query tra microservizi
Nella figura precedente viene visualizzato un microservizio carrello acquisti che aggiunge un elemento al carrello acquisti di un utente. Mentre l'archivio dati per questo microservizio contiene dati di articoli da carrello e riga, non gestisce i dati relativi a prodotti o prezzi. Questi elementi di dati sono invece di proprietà del catalogo e dei microservizi tariffari. Questo aspetto presenta un problema. In che modo il microservizio shopping basket aggiunge un prodotto al carrello acquisti dell'utente quando non dispone di dati relativi a prodotti né prezzi nel database?
Un'opzione illustrata nel capitolo 4 è una chiamata HTTP diretta dal carrello acquisti ai microservizi di catalogo e prezzi. Tuttavia, nel capitolo 4, abbiamo detto che le chiamate HTTP sincrone associano microservizi, riducendone l'autonomia e riducendone i vantaggi architetturali.
È anche possibile implementare un modello request-reply con code in ingresso e in uscita separate per ogni servizio. Tuttavia, questo modello è complicato e richiede dei collegamenti per correlare i messaggi di richiesta e risposta. Anche se separa le chiamate del microservizio back-end, il servizio chiamante deve comunque attendere in modo sincrono il completamento della chiamata. Congestione della rete, errori temporanei o un microservizio sovraccarico che possono comportare operazioni a esecuzione prolungata e persino non riuscite.
Al contrario, un modello ampiamente accettato per la rimozione delle dipendenze tra servizi è il modello di visualizzazione materializzato, illustrato nella figura 5-4.
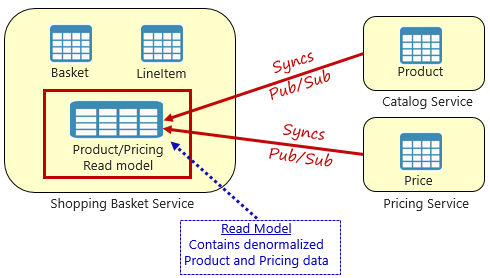
Figura 5-4. Modello di visualizzazione materializzato
Con questo modello, si inserisce una tabella dati locale (nota come modello di lettura) nel servizio carrello acquisti. Questa tabella contiene una copia denormalizzata dei dati necessari dai microservizi di prodotto e prezzi. La copia dei dati direttamente nel microservizio shopping basket elimina la necessità di chiamate tra servizi costosi. Con i dati locali del servizio, è possibile migliorare il tempo di risposta e l'affidabilità del servizio. Inoltre, la presenza di una propria copia dei dati rende il servizio carrello acquisti più resiliente. Se il servizio catalogo non dovrebbe diventare disponibile, non influisce direttamente sul servizio carrello acquisti. Il carrello acquisti può continuare a funzionare con i dati del proprio negozio.
Il problema con questo approccio è che ora sono presenti dati duplicati nel tuo sistema. Tuttavia, la duplicazione strategica dei dati nei sistemi nativi del cloud è una pratica consolidata e non considerata un anti-modello o una pratica non valida. Tenere presente che uno e un solo servizio possono essere proprietari di un set di dati e avere l'autorità su di esso. Sarà necessario sincronizzare i modelli di lettura quando il sistema di record viene aggiornato. La sincronizzazione viene in genere implementata tramite messaggistica asincrona con un modello di pubblicazione/sottoscrizione, come illustrato nella figura 5.4.
Transazioni distribuite
Anche se l'esecuzione di query sui dati tra microservizi è difficile, l'implementazione di una transazione tra più microservizi è ancora più complessa. La sfida intrinseca di mantenere la coerenza dei dati tra origini dati indipendenti in microservizi diversi non può essere sottovalutata. La mancanza di transazioni distribuite nelle applicazioni native del cloud significa che è necessario gestire le transazioni distribuite a livello di codice. Si passa da un mondo di coerenza immediata a quello della coerenza finale.
La figura 5-5 mostra il problema.
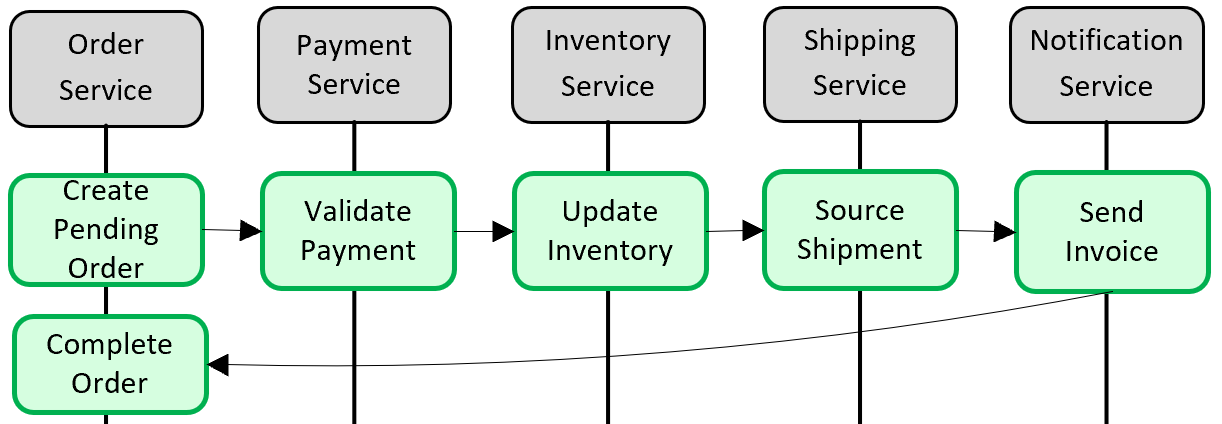
Figura 5-5. Implementazione di una transazione tra microservizi
Nella figura precedente cinque microservizi indipendenti partecipano a una transazione distribuita che crea un ordine. Ogni microservizio gestisce il proprio archivio dati e implementa una transazione locale per il relativo archivio. Per creare l'ordine, la transazione locale per ogni singolo microservizio deve avere esito positivo oppure tutti devono interrompere ed eseguire il rollback dell'operazione. Anche se il supporto transazionale predefinito è disponibile all'interno di ogni microservizio, non è disponibile alcun supporto per una transazione distribuita che si estende su tutti e cinque i servizi per mantenere la coerenza dei dati.
È invece necessario costruire questa transazione distribuita a livello di codice.
Un modello comune per l'aggiunta di supporto transazionale distribuito è il modello Saga. Viene implementato raggruppando le transazioni locali a livello di codice e richiamandole in sequenza. Se una delle transazioni locali ha esito negativo, saga interrompe l'operazione e richiama un set di transazioni di compensazione. Le transazioni di compensazione annullano le modifiche apportate dalle transazioni locali precedenti e ripristinano la coerenza dei dati. La figura 5-6 mostra una transazione non riuscita con il modello Saga.
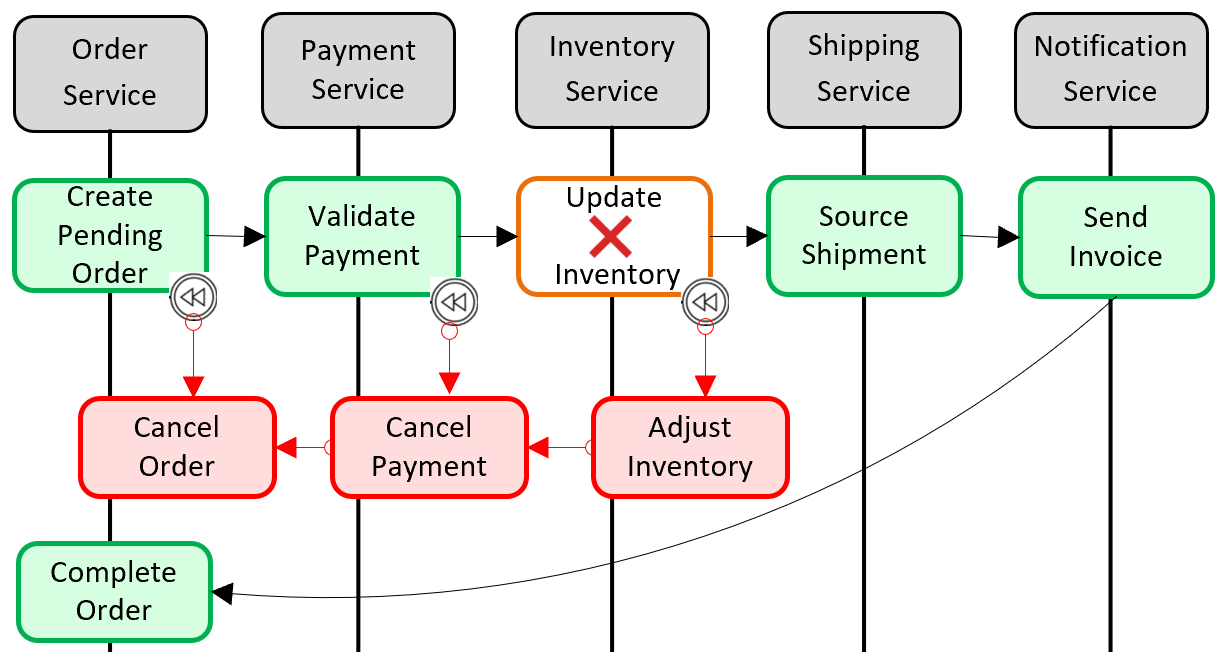
Figura 5-6. Rollback di una transazione
Nella figura precedente l'operazione Aggiorna inventario non è riuscita nel microservizio Inventario. Saga richiama un set di transazioni di compensazione (in rosso) per regolare i conteggi delle scorte, annullare il pagamento e l'ordine e restituire i dati per ogni microservizio a uno stato coerente.
I modelli saga sono in genere coreografati come una serie di eventi correlati o orchestrati come set di comandi correlati. Nel capitolo 4, abbiamo discusso il modello di aggregatore del servizio che sarebbe la base per un'implementazione orchestrata della saga. Abbiamo anche discusso di eventing insieme a Azure Service Bus e Azure Event Grid, che costituirebbero una base per l'implementazione di una saga coreografata.
Dati con volumi elevati
Le applicazioni native del cloud di grandi dimensioni supportano spesso requisiti di dati con volumi elevati. In questi scenari, le tecniche di archiviazione dei dati tradizionali possono causare ostruzioni. Per i sistemi complessi che vengono distribuiti su larga scala, sia Command che Query Responsibility Segregation (CQRS) e Event Sourcing possono migliorare le prestazioni dell'applicazione.
CQRS
CQRS è un modello di architettura che consente di ottimizzare le prestazioni, la scalabilità e la sicurezza. Il modello separa le operazioni che leggono i dati dalle operazioni che scrivono dati.
Per gli scenari normali, lo stesso modello di entità e lo stesso oggetto repository di dati vengono usati sia per le operazioni di lettura che di scrittura.
Tuttavia, uno scenario di dati con volumi elevati può trarre vantaggio da modelli e tabelle dati separati per letture e scritture. Per migliorare le prestazioni, l'operazione di lettura potrebbe eseguire interrogazioni su una rappresentazione dei dati altamente denormalizzata per evitare costosi join di tabelle ripetitivi e blocchi di tabella. L'operazione di scrittura , nota come comando, viene aggiornata in base a una rappresentazione completamente normalizzata dei dati che garantisce la coerenza. È quindi necessario implementare un meccanismo per mantenere sincronizzate entrambe le rappresentazioni. In genere, ogni volta che viene modificata la tabella di scrittura, pubblica un evento che replica la modifica nella tabella di lettura.
La figura 5-7 mostra un'implementazione del modello CQRS.
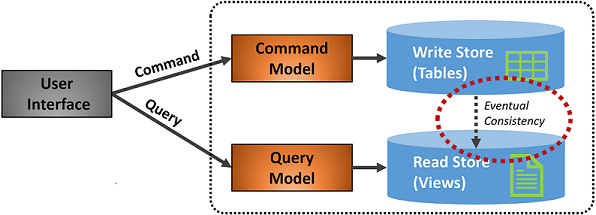
Figura 5-7. Implementazione di CQRS
Nella figura precedente vengono implementati modelli separati per comandi e query. Ogni operazione di scrittura dei dati viene salvata nell'archivio di scrittura e quindi propagata all'archivio di lettura. Prestare particolare attenzione al funzionamento del processo di propagazione dei dati sul principio della coerenza finale. Il modello di lettura viene infine sincronizzato con il modello di scrittura, ma potrebbe verificarsi un certo ritardo nel processo. La coerenza finale verrà discussa nella sezione successiva.
Questa separazione consente la scalabilità indipendente delle operazioni di lettura e scrittura. Le operazioni di lettura usano uno schema ottimizzato per le query, mentre le scritture usano uno schema ottimizzato per gli aggiornamenti. Le query di lettura vengono eseguite sui dati denormalizzati, mentre è possibile applicare una logica di business complessa al modello di scrittura. Inoltre, è possibile imporre una sicurezza più rigorosa per le operazioni di scrittura rispetto alle operazioni di lettura.
L'implementazione di CQRS può migliorare le prestazioni delle applicazioni per i servizi nativi del cloud. Tuttavia, comporta una progettazione più complessa. Applicare questo principio in modo attento e strategico a quelle sezioni dell'applicazione nativa del cloud che ne trarranno vantaggio. Per altre informazioni su CQRS, vedere il libro Microsoft .NET Microservices: Architecture for Containerized .NET Applications (Architettura per applicazioni .NET in contenitori).
Origine degli eventi
Un altro approccio all'ottimizzazione degli scenari di dati con volumi elevati prevede Event Sourcing.
Un sistema archivia in genere lo stato corrente di un'entità dati. Se un utente modifica il numero di telefono, ad esempio, il record del cliente viene aggiornato con il nuovo numero. Lo stato corrente di un'entità dati è sempre noto, ma ogni aggiornamento sovrascrive lo stato precedente.
Nella maggior parte dei casi, questo modello funziona correttamente. Nei sistemi con volumi elevati, tuttavia, il sovraccarico dovuto al blocco transazionale e alle operazioni di aggiornamento frequenti può influire sulle prestazioni del database, sulla velocità di risposta e limitare la scalabilità.
Event Sourcing adotta un approccio differente per l'acquisizione dei dati. Ogni operazione che influisce sui dati viene salvata in modo permanente in un archivio eventi. Invece di aggiornare lo stato di un record di dati, ogni modifica viene aggiunta a un elenco sequenziale di eventi passati, simile al libro mastro di un contabile. L'archivio eventi diventa il sistema di record per i dati. Viene usato per propagare varie viste materializzate all'interno del contesto delimitato di un microservizio. La figura 5.8 mostra il modello.
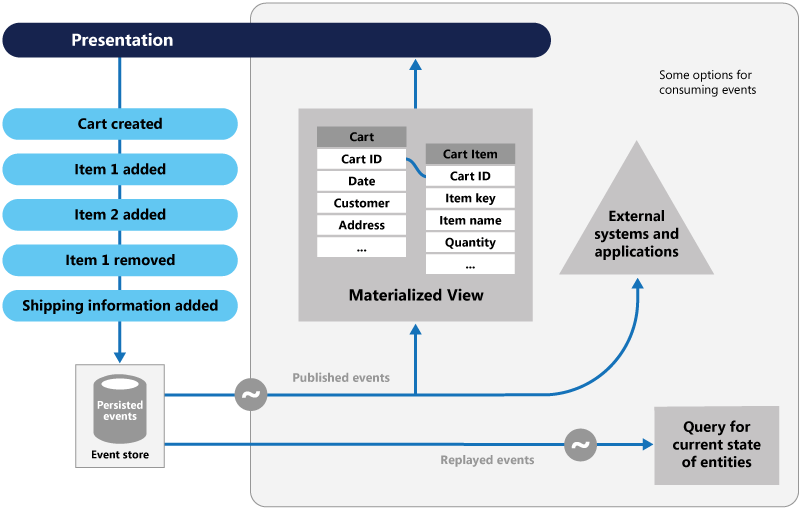
Figura 5-8. Archiviazione degli Eventi
Nella figura precedente si noti come ogni voce (in blu) per il carrello acquisti di un utente venga aggiunta a un archivio eventi sottostante. Nella visualizzazione materializzata adiacente, il sistema proietta lo stato corrente riproducendo tutti gli eventi associati a ogni carrello acquisti. Questa visualizzazione, o modello di lettura, viene quindi esposta di nuovo all'interfaccia utente. Gli eventi possono anche essere integrati con sistemi esterni e applicazioni o sottoposti a query per determinare lo stato corrente di un'entità. Con questo approccio si mantiene la cronologia. Non solo lo stato corrente di un'entità, ma anche il modo in cui è stato raggiunto questo stato.
Meccanicamente, l'event sourcing semplifica il modello di scrittura. Non sono presenti aggiornamenti o eliminazioni. L'aggiunta di ogni voce di dato come evento immutabile riduce al minimo i conflitti di contesa, blocco e concorrenza associati ai database relazionali. La creazione di modelli di lettura con il modello di visualizzazione materializzato consente di separare la visualizzazione dal modello di scrittura e scegliere l'archivio dati migliore per ottimizzare le esigenze dell'interfaccia utente dell'applicazione.
Per questo modello, prendere in considerazione un archivio dati che supporta direttamente il pattern di event sourcing. Azure Cosmos DB, MongoDB, Cassandra, CouchDB e RavenDB sono buoni candidati.
Come per tutti i modelli e le tecnologie, implementare in modo strategico e quando necessario. Sebbene il sourcing degli eventi possa offrire migliori prestazioni e maggiore scalabilità, viene a costo di una maggiore complessità e di una ripida curva di apprendimento.
Collabora con noi su GitHub
L'origine di questo contenuto è disponibile in GitHub, in cui è anche possibile creare ed esaminare i problemi e le richieste pull. Per ulteriori informazioni, vedere la guida per i collaboratori.