Nota
L'accesso a questa pagina richiede l'autorizzazione. Puoi provare ad accedere o a cambiare directory.
L'accesso a questa pagina richiede l'autorizzazione. Puoi provare a cambiare directory.
Usare l'attività Notebook per eseguire i notebook creati in Microsoft Fabric come parte delle pipeline di Data Factory. I notebook consentono di eseguire processi Apache Spark per inserire, pulire o trasformare i dati come parte dei flussi di lavoro dei dati. È facile aggiungere un'attività Notebook alle pipeline in Fabric e questa guida illustra ogni passaggio.
Prerequisiti
Per iniziare, è necessario soddisfare i prerequisiti seguenti:
- Un account locatario con una sottoscrizione attiva. Creare un account gratuito.
- Viene creata un’area di lavoro.
- Un notebook è stato creato nell'area di lavoro. Per creare un nuovo notebook, vedere Come creare notebook di Microsoft Fabric.
Creare un'attività nel quaderno
Creare una nuova pipeline nell'area di lavoro.
Cerca Notebook nel riquadro Attività della pipeline, e selezionalo per aggiungerlo al canvas della pipeline.
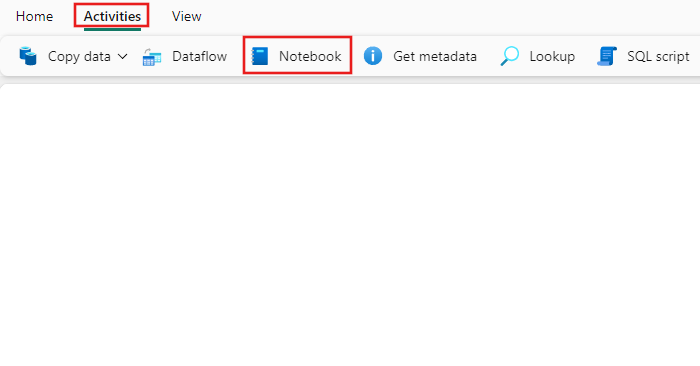
Selezionare la nuova attività Notebook nell’area di disegno, se non è già selezionata.
Fare riferimento alla guida alle impostazioni Generali per configurare la scheda impostazioni Generali.
Configurare le impostazioni del notebook
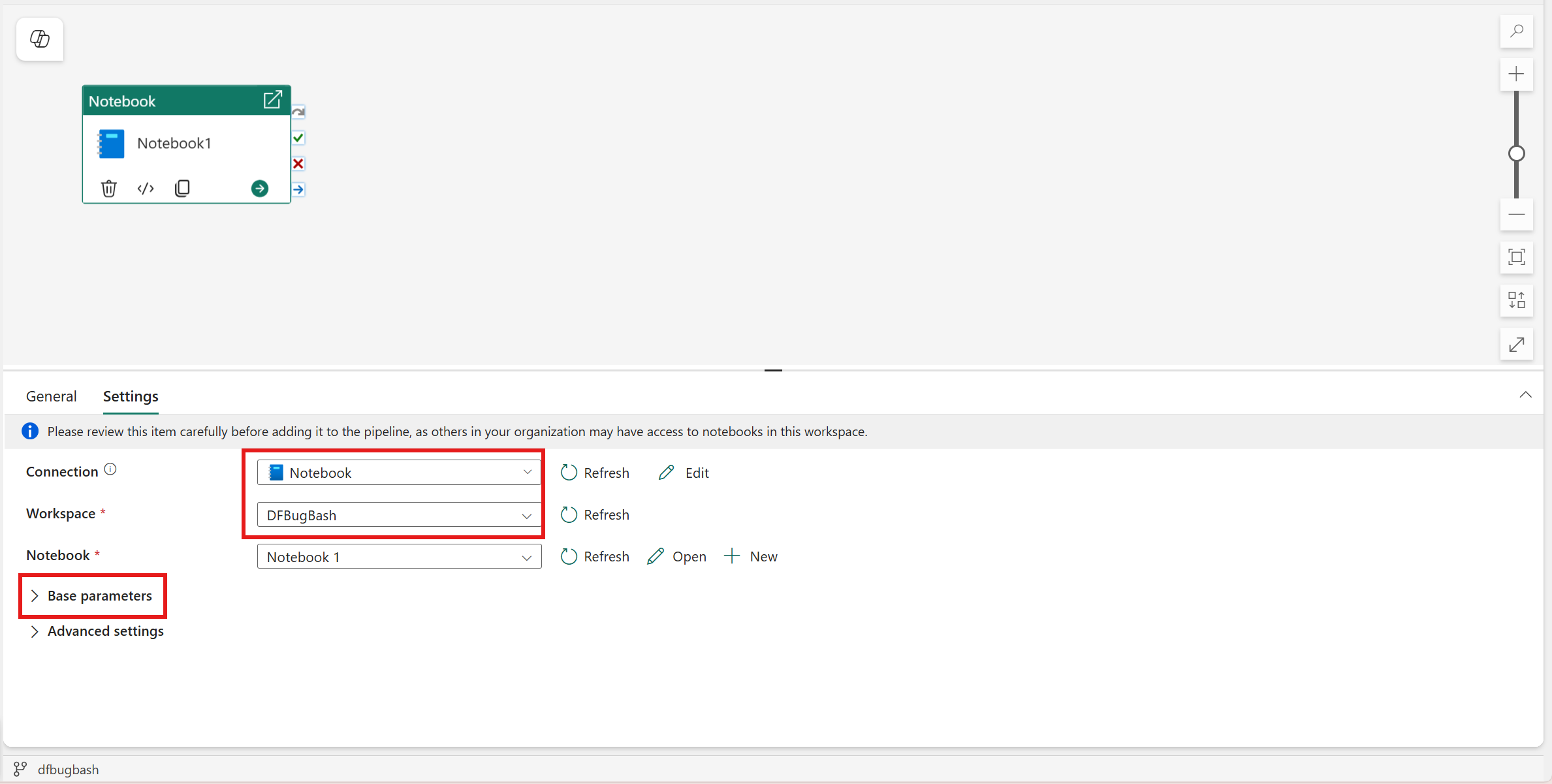
Selezionare la scheda Impostazioni .
In Connessione selezionare il metodo di autenticazione per l'esecuzione del notebook e specificare le credenziali o la configurazione dell'identità necessarie in base alla selezione:
- Entità servizio (SPN): consigliato per scenari di produzione per garantire l'esecuzione sicura e automatizzata senza basarsi sulle credenziali utente.
- Identità dell'area di lavoro : ideale per gli ambienti gestiti in cui è necessaria la governance centralizzata delle identità.
Selezionare un notebook esistente dall'elenco a discesa Notebook e, facoltativamente, specificare eventuali parametri da passare al notebook.
Uso dell'identità dell'area di lavoro di Fabric nell'attività Notebook
Creare l'identità dell'area di lavoro
È necessario abilitare La connessione Wi-On nell'area di lavoro (il caricamento potrebbe richiedere qualche minuto). Crea un'identità di workspace nel tuo workspace Fabric. Si noti che il WI deve essere creato nella stessa area di lavoro della tua pipeline.
Dai un'occhiata alla documentazione su Identità dell'area di lavoro.
Abilitare le impostazioni a livello di tenant
Abilitare l'impostazione del tenant seguente (disabilitata per impostazione predefinita): le entità servizio possono chiamare le API pubbliche di Fabric.
È possibile abilitare questa impostazione nel portale di amministrazione di Fabric. Per altre informazioni su questa impostazione, vedere l'articolo sull'abilitazione dell'autenticazione del servizio principale per le API di amministrazione.
Concedere le autorizzazioni dell'area di lavoro all'identità dell'area di lavoro
Aprire l'area di lavoro, selezionare Gestisci accesso e assegnare le autorizzazioni all'identità dell'area di lavoro. L'accesso come collaboratore è sufficiente nella maggior parte degli scenari. Se il notebook non si trova nella stessa area di lavoro della pipeline, sarà necessario assegnare all'elemento di lavoro (WI) creato nell'area di lavoro della pipeline almeno i permessi da Collaboratore nell'area di lavoro del notebook.
Vedere la documentazione su Concedere agli utenti l'accesso alle aree di lavoro.
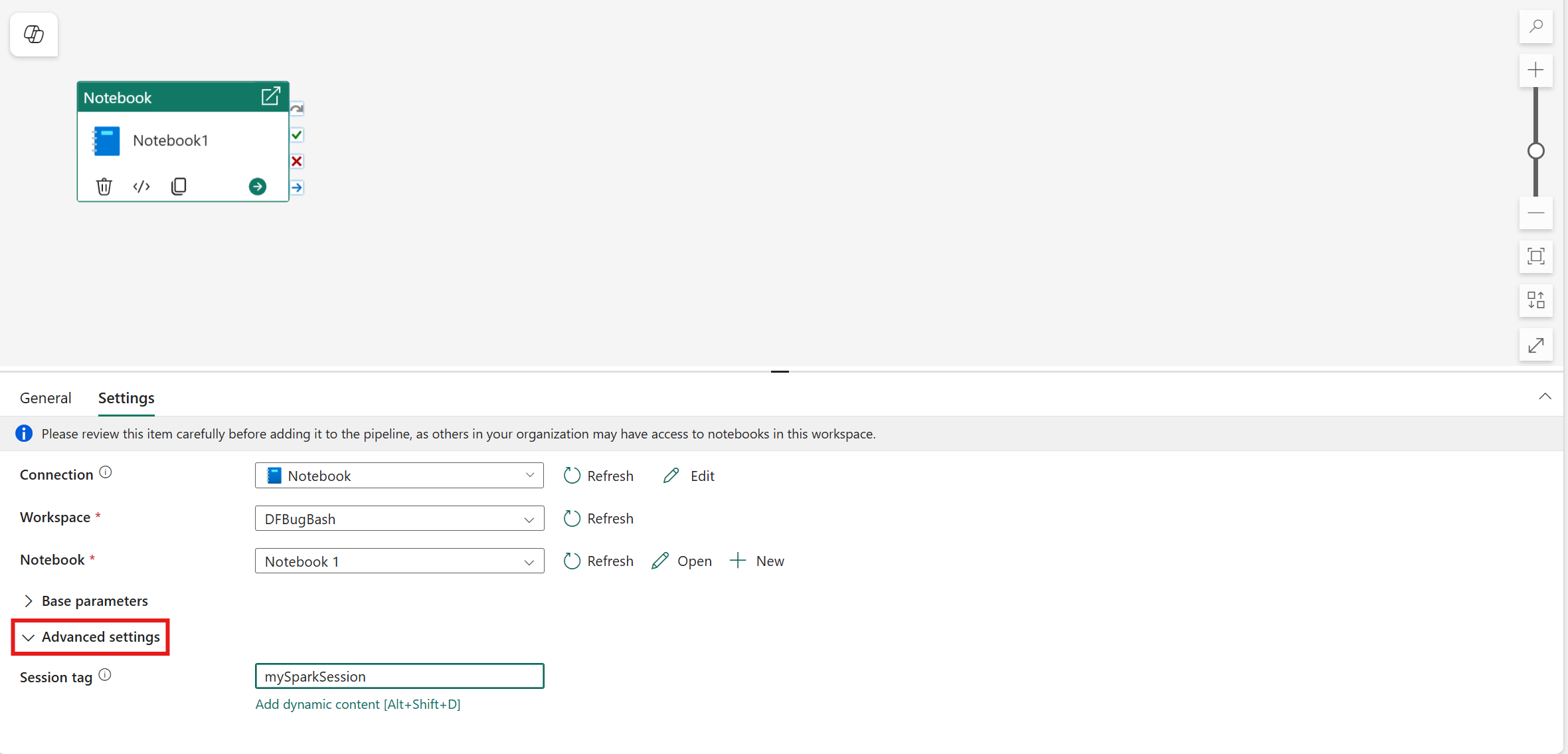
Impostare il tag di sessione
Per ridurre al minimo il tempo necessario per eseguire il processo del notebook, è possibile impostare facoltativamente un tag di sessione. L'impostazione del tag di sessione indica a Spark di riutilizzare qualsiasi sessione Spark esistente, riducendo al minimo il tempo di avvio. Qualsiasi valore stringa arbitrario può essere usato per il tag di sessione. Se non esiste alcuna sessione, ne verrà creato uno nuovo usando il valore del tag.
Nota
Per poter utilizzare il tag di sessione, è necessario attivare l'impostazione di modalità ad alta concorrenza per l'esecuzione di pipeline che coinvolge più notebook. Questa opzione è disponibile nella modalità di concorrenza elevata per le impostazioni di Spark nelle impostazioni dell'area di lavoro
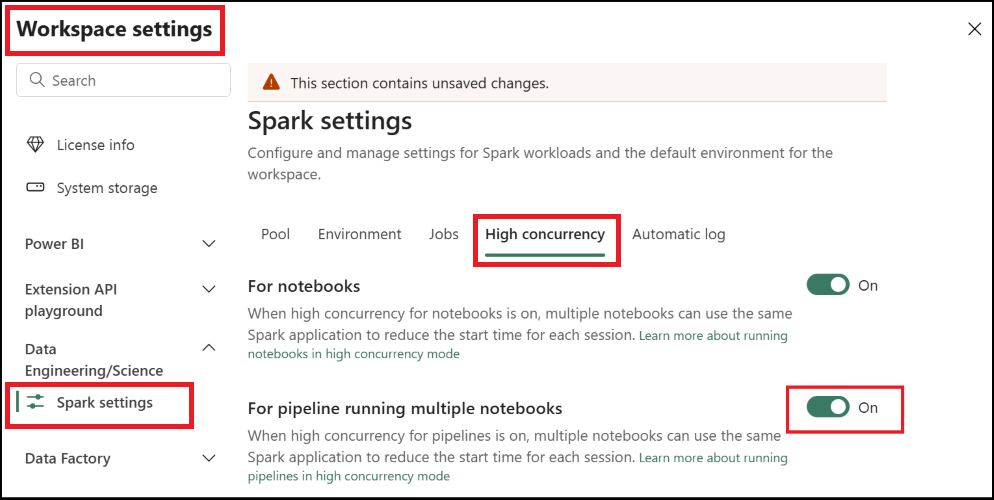
Salvare ed eseguire o pianificare la pipeline
Passare alla scheda Home nella parte superiore dell'editor della pipeline e selezionare il pulsante Salva per salvare la pipeline. Selezionare Esegui per eseguirla direttamente, o Pianifica per pianificarla. È anche possibile visualizzare la cronologia di esecuzione qui o configurare altre impostazioni.

Problemi noti
- L'opzione WI nelle impostazioni delle connessioni non viene visualizzata in alcune istanze. Si tratta di un bug su cui si sta lavorando una correzione.