Nota
L'accesso a questa pagina richiede l'autorizzazione. Puoi provare ad accedere o a cambiare directory.
L'accesso a questa pagina richiede l'autorizzazione. Puoi provare a cambiare directory.
si applica a:✅ Magazzino di dati in Microsoft Fabric
Questo articolo illustra le funzionalità e le innovazioni nell'architettura di Fabric Data Warehouse che ne alimentano le prestazioni, la scalabilità e l'efficienza dei costi.
Fabric Data Warehouse viene eseguito su un'architettura pronta per il futuro in una piattaforma dati convergente. Con un formato di archiviazione Delta aperto e l'integrazione di OneLake, i dati in Fabric Data Warehouse sono pronti per l'analisi.
Architettura di alto livello

Fabric Data Warehouse è progettato per l'analisi su larga scala con i blocchi predefiniti seguenti:
| Blocco di costruzione | Descrizione |
|---|---|
| Ottimizzatore di query unificato | Genera un piano di esecuzione ottimale per gli ambienti cloud distribuiti, indipendentemente dalla qualità delle query SQL create dall'utente. |
| Elaborazione di query distribuite | Supporta l'esecuzione di query parallele massicce con scalabilità automatica rapida dell'infrastruttura cloud, fornendo immediatamente le risorse di calcolo necessarie per le query. I carichi di lavoro SELECT e DML separati usano pool distinti per l'esecuzione efficiente e isolata. |
| Motore di esecuzione di query | Motore basato su SQL per l'esecuzione di query di analisi su grandi quantità di dati con prestazioni veloci e concorrenza elevata. |
| Gestione dei metadati e delle transazioni | I metadati si trovano nel front-end, nel back-end e nella cache SSD locale e nell'archiviazione OneLake remota. Supporta transazioni simultanee e garantisce la conformità ACID. |
| Archiviazione in OneLake | Log Structured Tables implementato usando il formato di tabella Delta aperto, un modello lakehouse con archiviazione aperta sicura. |
| Piattaforma Fabric | La piattaforma infrastruttura fornisce un modello di autenticazione e sicurezza unificato, monitoraggio e controllo. Il data warehouse di Fabric è automaticamente disponibile per altri servizi della piattaforma Fabric per soddisfare le esigenze aziendali, tra cui Power BI, pipeline di dati in Data Factory, Real-Time Intelligence e altro. |
Motore ottimizzatore di query unificato
L'Unified Query Optimizer di Fabric Data Warehouse è il motore che decide il modo più efficace per eseguire le query SQL.
Quando si invia una query, Query Optimizer unificato esamina i possibili modi per eseguirlo: come unire tabelle, dove spostare i dati e come usare risorse come CPU, memoria e rete. L'ottimizzatore di query unificato non sceglie solo la prima opzione, ma sceglie il piano ottimale entro il tempo a disposizione valutando i costi rispetto a questi fattori e ai metadati e alle statistiche disponibili.
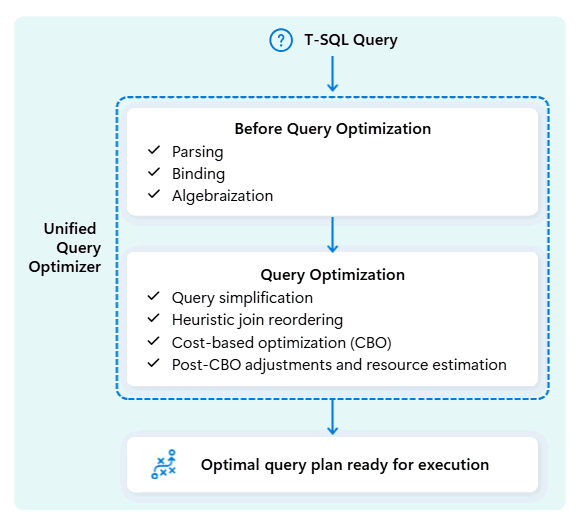
Quando si ottimizza il piano di esecuzione di una query, Query Optimizer unificato considera tutti gli elementi in un'unica operazione: la forma della query, la distribuzione dei dati delle tabelle e il costo dello spostamento dei dati rispetto all'elaborazione locale. Il Query Optimizer unificato può fare compromessi intelligenti, ad esempio a decidere se la trasmissione di una piccola tabella è più economica rispetto al riordinare una grande. Ciò significa un minor numero di shuffle di dati non necessari, un uso migliore delle risorse di calcolo e prestazioni più veloci, anche per query T-SQL complesse o poco scritte.
Prestazioni coerenti non richiede agli sviluppatori di dedicare tempo all'ottimizzazione manuale delle query T-SQL. Ad esempio, non è necessario determinare manualmente l'ordine migliore JOIN nelle query. Se SQL elenca prima la tabella di grandi dimensioni e una tabella di dati più piccola e altamente selettiva, l'utilità di ottimizzazione può cambiare automaticamente le proprie posizioni per ottenere prestazioni migliori. Userà la tabella più piccola come punto di partenza per le righe corrispondenti (lato "build") e la tabella più grande come quella in cui eseguire la ricerca (lato "probe", verificata la presenza di corrispondenze). Questo approccio riduce al minimo l'utilizzo della memoria, riduce lo spostamento dei dati e migliora il parallelismo, pur offrendo risultati accurati.
Query Optimizer unificato apprende continuamente dalle esecuzioni di query precedenti man mano che i carichi di lavoro si evolvono, affinando l'algoritmo di ottimizzazione per offrire le migliori prestazioni possibili. Gli utenti traggono vantaggio dall'esecuzione rapida delle query, indipendentemente dalla complessità e senza dover intervenire.
Motore di elaborazione di query distribuite
In Fabric Data Warehouse il motore di elaborazione delle query distribuite alloca le risorse di calcolo alle attività nei piani di query. Il motore di elaborazione delle query distribuite può pianificare attività tra nodi di calcolo, in modo che ogni nodo esegua parte di un piano di query, consentendo l'esecuzione parallela per prestazioni più veloci. I report complessi su set di dati di grandi dimensioni possono trarre vantaggio dall'elaborazione di query distribuite.
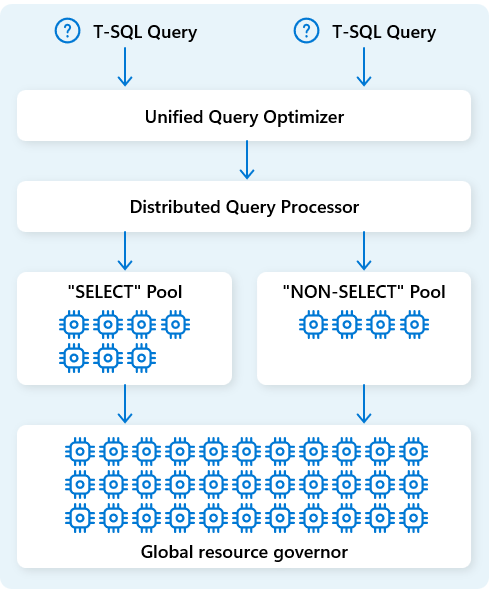
Per ottimizzare ulteriormente le risorse, il motore di elaborazione delle query distribuite separa le risorse di calcolo in due pool: per SELECT le query e per le attività di inserimento dati (NON-SELECT query). Ogni carico di lavoro riceve risorse dedicate in base alle esigenze. Ciò significa, ad esempio, che i processi ETL notturni non ritarderanno i dashboard della mattina.
Con il provisioning rapido dei nodi nel cloud, il motore di elaborazione delle query distribuite ridimensiona automaticamente le risorse di calcolo verso l'alto o verso il basso in risposta alle modifiche apportate al volume di query, alle dimensioni dei dati e alla complessità delle query. Fabric Data Warehouse offre funzionalità di elaborazione parallela per set di dati di piccole dimensioni o dati su scala multi-petabyte.
Motore di esecuzione di query
Il motore di esecuzione di query è un processo che esegue parti del piano di esecuzione distribuito assegnato ai singoli nodi di calcolo. Il motore di esecuzione delle query si basa sullo stesso motore usato da SQL Server e dal database SQL di Azure per usare formati di dati in modalità batch e di colonne per un'analisi efficiente dei Big Data a un costo ottimale.
Il motore di esecuzione delle query legge i dati direttamente dai file Parquet Delta archiviati in Fabric OneLake e sfrutta più livelli di memorizzazione nella cache (memoria e SSD) per accelerare le prestazioni delle query e garantire che le query vengano eseguite a velocità ottimale. Il motore di esecuzione delle query elabora i dati in memoria e, quando necessario, recupera dati aggiuntivi dalla cache SSD o dall'archiviazione OneLake.
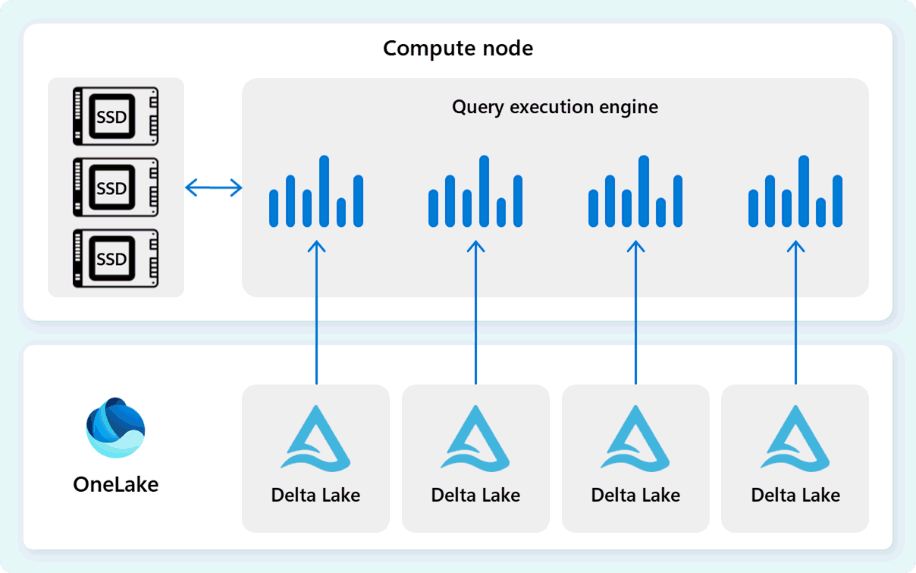
Durante l'elaborazione dei dati, il motore di esecuzione delle query esegue l'eliminazione di gruppi di righe e colonne per ignorare i segmenti che non sono rilevanti per la query. Questa ottimizzazione riduce la quantità di dati analizzati dai file e dalla cache di memoria, consentendo di ridurre al minimo l'utilizzo delle risorse e migliorare il tempo di esecuzione complessivo.
Il motore di esecuzione delle query si distingue per filtrare e aggregare miliardi di righe, supportando i modelli analitici di dati generici usati nelle soluzioni moderne del data warehouse. L'esecuzione in modalità batch sfrutta la capacità moderna della CPU di elaborare più righe in parallelo, riducendo notevolmente il sovraccarico e rendendo le query eseguite fino a centinaia di volte più velocemente rispetto all'esecuzione tradizionale di righe per riga.
Gestione dei metadati e delle transazioni
Il motore di warehouse usa i metadati per descrivere lo schema della tabella, l'organizzazione dei file, la cronologia delle versioni e gli stati transazionali. Questi metadati consentono al motore di warehouse di gestire ed eseguire query sui dati in modo efficiente. Fabric Data Warehouse offre un'architettura affidabile e completa di metadati e gestione delle transazioni, estendendo un gestore transazioni OLTP per orchestrare operazioni di metadati altamente simultanee e garantire la conformità ACID.
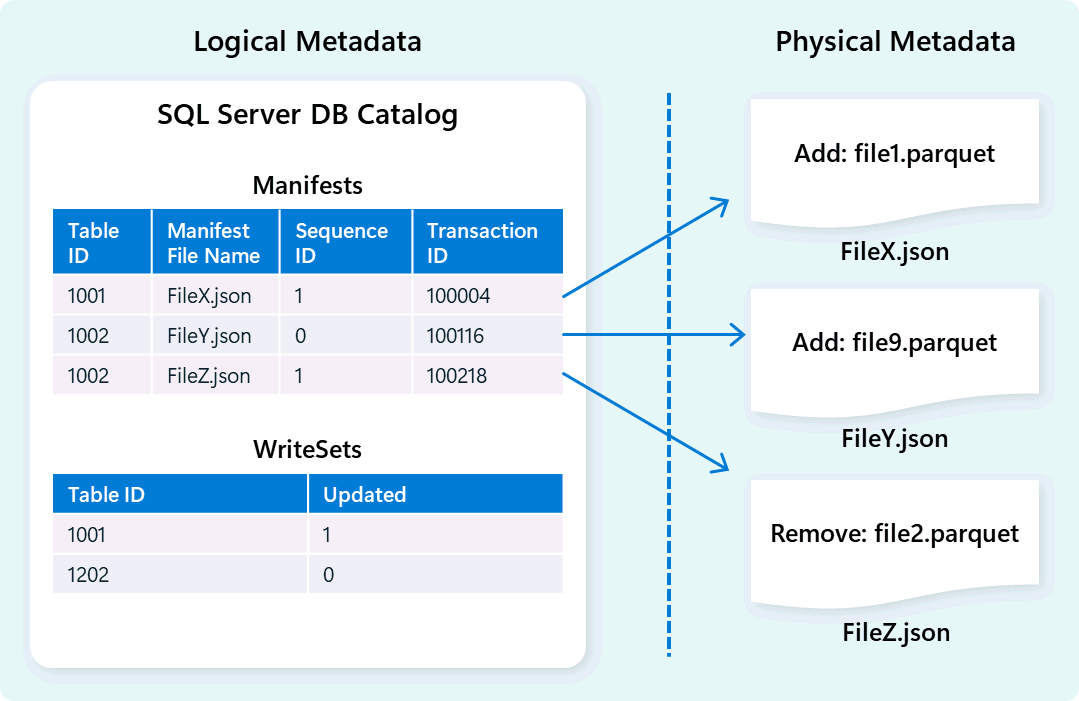
Questa progettazione consente un spostamento rapido e affidabile degli stati transazionali, supportando i carichi di lavoro con concorrenza elevata garantendo al tempo stesso la coerenza.
Archiviazione e inserimento dati
Fabric Data Warehouse usa un'architettura lakehouse con il formato Delta open source per l'archiviazione scalabile, sicura e ad alte prestazioni. Il formato di tabella Delta supporta il controllo delle versioni dei dati, consentendo l'accesso istantaneo agli snapshot cronologici tramite il viaggio in tempo e la clonazione senza copia per operazioni di test e rollback sicure. I dati utente vengono archiviati all'interno di OneLake, consentendo a tutti i motori fabric di accedere in modo efficiente ai dati condivisi senza ridondanza.
Basandosi su questa base, Fabric Data Warehouse è progettato per offrire prestazioni ottimali di inserimento dati con particolare attenzione alla semplicità e alla flessibilità. Il motore gestisce in modo efficiente l'archiviazione dei dati delle tabelle tramite la compattazione automatica dei dati, che consolida i file frammentati in background per ridurre l'analisi dei dati non necessaria. Il metodo di distribuzione intelligente dei dati divide e organizza i dati in celle con micro partizionamento per migliorare l'elaborazione parallela e migliorare i risultati delle query. Queste funzionalità funzionano in modo autonomo, senza la necessità di regolazioni manuali.