Nota
L'accesso a questa pagina richiede l'autorizzazione. Puoi provare ad accedere o a cambiare directory.
L'accesso a questa pagina richiede l'autorizzazione. Puoi provare a cambiare directory.
si applica a:✅ Magazzino di dati in Microsoft Fabric
Le chiavi surrogate sono identificatori usati nel data warehousing per distinguere in modo univoco le righe, indipendentemente dalla loro chiave naturale. In Fabric Data Warehouse le IDENTITY colonne consentono la generazione automatica di queste chiavi surrogate durante l'inserimento di nuove righe in una tabella. Questo articolo illustra come usare IDENTITY le colonne in Fabric Data Warehouse per creare e gestire le chiavi surrogate in modo efficiente.
Perché usare una colonna IDENTITY?
IDENTITY le colonne eliminano la necessità di assegnazione manuale delle chiavi, riducendo il rischio di errori e semplificando l'inserimento dei dati. I valori univoci gestiti dal sistema sono ideali come chiavi surrogate e chiavi primarie. Rispetto agli approcci manuali per produrre chiavi surrogate, IDENTITY le colonne offrono prestazioni superiori perché le chiavi univoche vengono generate automaticamente senza logica aggiuntiva nelle query.
Il tipo di dati bigint , obbligatorio per IDENTITY le colonne, può archiviare fino a 9.223.372.036.854.775.807 valori interi positivi, assicurando che per tutta la durata di una tabella ogni riga riceva un valore univoco nella colonna IDENTITY .
Per un piano di migrazione dei dati con chiavi surrogate da altre piattaforme di database, vedere Eseguire la migrazione di colonne IDENTITY a Fabric Data Warehouse.
Sintassi
Per definire una IDENTITY colonna in Fabric Data Warehouse, la IDENTITY proprietà viene usata con la colonna desiderata. La sintassi è la seguente:
CREATE TABLE { warehouse_name.schema_name.table_name | schema_name.table_name | table_name } (
[column_name] BIGINT IDENTITY,
[ ,... n ]
-- Other columns here
);
Funzionamento delle colonne IDENTITY
All'interno di Fabric Data Warehouse non è possibile specificare un valore iniziale personalizzato o un incremento; il sistema gestisce internamente i valori per garantire l'univocità.
IDENTITY le colonne producono sempre valori integer positivi. Ogni nuova riga riceve un nuovo valore e l'univocità è garantita finché la tabella esiste. Una volta usato un valore, IDENTITY non usa di nuovo lo stesso valore, mantenendo sia l'integrità della chiave che l'univocità. Possono apparire dei vuoti sui valori prodotti dalla colonna IDENTITY.
Allocazione di valori
A causa dell'architettura distribuita del motore di magazzino, la IDENTITY proprietà non garantisce l'ordine in cui vengono allocati i valori surrogati. La proprietà IDENTITY è progettata per espandersi tra i nodi di calcolo al fine di massimizzare il parallelismo, senza influenzare le prestazioni del carico di lavoro. Di conseguenza, gli intervalli di valori in diverse attività di inserimento potrebbero avere intervalli di sequenze diversi.
Per illustrare questo comportamento, considerare l'esempio seguente:
-- Create a table with an IDENTITY column
CREATE TABLE dbo.T1(
C1 BIGINT IDENTITY,
C2 VARCHAR(30) NULL
)
-- Ingestion task A
INSERT INTO dbo.T1
VALUES (NULL), (NULL), (NULL), (NULL);
-- Ingestion task B
INSERT INTO dbo.T1
VALUES (NULL), (NULL), (NULL), (NULL);
-- Reviewing the data
SELECT * FROM dbo.T1;
Risultato di esempio:
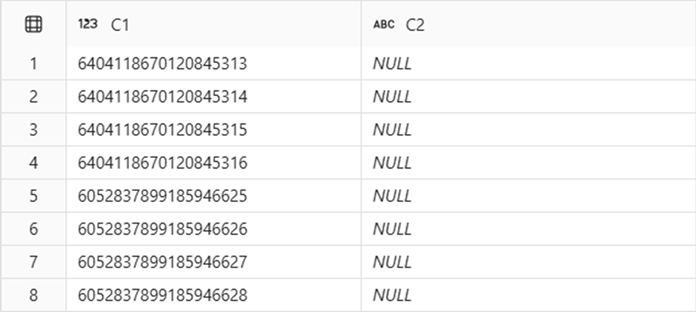
In questo esempio Ingestion task A e Ingestion task B vengono eseguiti in sequenza, come attività indipendenti. Anche se le attività sono state eseguite consecutivamente, le prime e le ultime quattro righe hanno intervalli di chiavi Identity diversi in dbo.T1.C1. Oltre a questo, come osservato in questo esempio, possono verificarsi lacune tra gli intervalli assegnati per l'attività A e l'attività B.
IDENTITY in Fabric Data Warehouse garantisce che tutti i valori di una IDENTITY colonna siano univoci, ma possono verificarsi lacune negli intervalli generati per una determinata attività di inserimento.
Visualizzazioni di sistema
La vista del catalogo sys.identity_columns può essere usata per elencare tutte le colonne Identity in un magazzino. Nell'esempio seguente vengono elencate tutte le tabelle che contengono una IDENTITY colonna nella relativa definizione, con il rispettivo nome dello schema e il nome della IDENTITY colonna nella tabella:
SELECT
s.name AS SchemaName,
t.name AS TableName,
c.name AS IdentityColumnName
FROM
sys.identity_columns AS ic
INNER JOIN
sys.columns AS c ON ic.[object_id] = c.[object_id]
AND ic.column_id = c.column_id
INNER JOIN
sys.tables AS t ON ic.[object_id] = t.[object_id]
INNER JOIN
sys.schemas AS s ON t.[schema_id] = s.[schema_id]
ORDER BY
s.name, t.name;
Limitazioni
- Solo il tipo di dati bigint è supportato nelle colonne in
IDENTITYFabric Data Warehouse. Il tentativo di usare altri tipi di dati genera un errore. -
IDENTITY_INSERTnon è supportato in Fabric Data Warehouse. Gli utenti non possono aggiornare o inserire manualmente i valori di colonna nelle colonne Identity in Fabric Data Warehouse. - La definizione di
seedeincrementnon è supportata. Di conseguenza, la reinizializzazione della colonnaIDENTITYnon è supportata. - L'aggiunta di una nuova
IDENTITYcolonna a una tabella esistente conALTER TABLEnon è supportata. Prendere in considerazione l'uso di CREATE TABLE AS SELECT (CTAS) o SELECT... INTO come alternative per creare una copia di una tabella esistente che aggiunge unaIDENTITYcolonna alla relativa definizione. - Alcune limitazioni si applicano alla modalità
IDENTITYdi conservazione delle colonne durante la creazione di una nuova tabella in seguito a una selezione da una tabella diversa conCREATE TABLE AS SELECT (CTAS)oSELECT... INTO. Per altre informazioni, vedere la sezione Tipi di dati della clausola SELECT - INTO (Transact-SQL).
Esempi
A. Creare una tabella con una colonna IDENTITY
CREATE TABLE Employees (
EmployeeID BIGINT IDENTITY,
FirstName VARCHAR(50),
LastName VARCHAR(50)
);
Questa istruzione crea una tabella Employees in cui ogni nuova riga riceve automaticamente un identificatore univoco EmployeeID come valore di tipo bigint.
B. INSERT in una tabella con una colonna di tipo identity
Quando la prima colonna è una IDENTITY colonna, non è necessario specificarla nell'elenco di colonne.
INSERT INTO Employees (FirstName, LastName) VALUES ('Ensi','Vasala')
È anche possibile generare i nomi delle colonne, se vengono forniti valori per tutte le colonne della tabella di destinazione (ad eccezione della colonna Identity):
INSERT INTO Employees VALUES ('Quarantino', 'Esposito')
C. Creare una nuova tabella con una colonna IDENTITY usando CREATE TABLE AS SELECT (CTAS)
Si consideri una tabella semplice come esempio:
CREATE TABLE Employees (
EmployeeID BIGINT IDENTITY,
FirstName VARCHAR(50),
LastName VARCHAR(50)
);
È possibile usare CREATE TABLE AS SELECT (CTAS) per creare una copia di questa tabella, salvando in modo permanente la IDENTITY proprietà nella tabella di destinazione:
CREATE TABLE RetiredEmployees
AS SELECT * FROM Employees
La colonna sulla tabella target eredita la IDENTITY proprietà dalla tabella sorgente. Per un elenco delle limitazioni che si applicano a questo scenario, si riferisce alla sezione Tipi di Dati della clausola SELECT - INTO.
D. Creare una nuova tabella con una colonna IDENTITY usando SELECT... IN
Si consideri una tabella semplice come esempio:
CREATE TABLE dbo.Employees (
EmployeeID BIGINT IDENTITY,
FirstName VARCHAR(50),
LastName VARCHAR(50),
Retired BIT
);
È possibile usare SELECT... INTO per creare una copia di questa tabella, salvando in modo permanente la IDENTITY proprietà nella tabella di destinazione:
SELECT *
INTO dbo.RetiredEmployees
FROM dbo.Employees
WHERE Retired = 1;
La colonna sulla tabella target eredita la IDENTITY proprietà dalla tabella sorgente. Per un elenco delle limitazioni che si applicano a questo scenario, si riferisce alla sezione Tipi di Dati della clausola SELECT - INTO.