Nota
L'accesso a questa pagina richiede l'autorizzazione. Puoi provare ad accedere o a cambiare directory.
L'accesso a questa pagina richiede l'autorizzazione. Puoi provare a cambiare directory.
Annotazioni
Questo articolo si riferisce principalmente alle esperienze degli utenti distribuite in Windows 10 (versione 1909 e precedenti). Per altre informazioni, vedi Fine del supporto per Cortana.
Cortana, la piattaforma di riconoscimento vocale Windows, supporta tutte le esperienze vocali in Windows 10, ad esempio Cortana e dettatura. L'attivazione vocale è una funzionalità che consente agli utenti di richiamare un motore di riconoscimento vocale da vari stati di alimentazione del dispositivo pronunciando una frase specifica: "Ehi Cortana". Per creare hardware che supporti la tecnologia di attivazione vocale, vedere le informazioni contenute in questo articolo.
Annotazioni
L'implementazione dell'attivazione vocale è un progetto significativo ed è un'attività completata dai fornitori soC. Gli OEM possono contattare il fornitore soC per informazioni sull'implementazione dell'attivazione vocale del SoC.
Esperienza utente finale di Cortana
Per comprendere l'esperienza di interazione vocale disponibile in Windows, vedere questi articoli.
| Article | Descrizione |
|---|---|
| Che cos'è Cortana? | Fornisce una panoramica e istruzioni d'uso per Cortana. |
Introduzione all'attivazione vocale di "Hey Cortana" e "Learn my voice"
Ehi Cortana" Attivazione vocale
La funzionalità di attivazione vocale di "Ehi Cortana" consente agli utenti di interagire rapidamente con l'esperienza cortana al di fuori del contesto attivo (ovvero ciò che è attualmente sullo schermo) usando la propria voce. Gli utenti spesso vogliono poter accedere immediatamente a un'esperienza senza dover interagire fisicamente o toccare un dispositivo. Gli utenti del telefono potrebbero guidare in auto e avere la loro attenzione e le mani impegnate con la guida del veicolo. Un utente Xbox potrebbe non voler trovare e connettere un controller. Gli utenti del PC potrebbero voler accedere rapidamente a un'esperienza senza dover eseguire più azioni tramite mouse, tocco o tastiera. Ad esempio, un computer in cucina utilizzato durante la cottura.
L'attivazione vocale fornisce sempre l'ascolto dell'input vocale tramite frasi chiave predefinite o frasi di attivazione. Le frasi chiave possono essere pronunciate da se stessi ("Ehi Cortana") come comando a fasi o seguite da un'azione vocale, ad esempio "Ehi Cortana, dove è la mia riunione successiva?", un comando concatenato.
Il termine Rilevamento parole chiave descrive il rilevamento della parola chiave da hardware o software.
L'attivazione tramite parola chiave avviene quando si pronuncia solo la parola chiave Cortana; Cortana si attiva e riproduce il suono EarCon, indicando che è entrata in modalità di ascolto.
Un comando concatenato descrive la possibilità di eseguire un comando immediatamente dopo la parola chiave (ad esempio "Ehi Cortana, chiamare John") e avviare Cortana (se non è già stato avviato) e seguire il comando (avviando una chiamata telefonica con John).
Questo diagramma illustra l'attivazione concatenata ed esclusivamente con parole chiave.
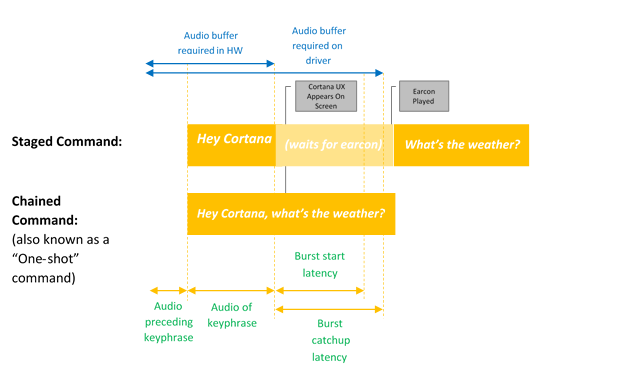
Microsoft fornisce un spotter di parole chiave predefinito del sistema operativo (spotter di parole chiave software) usato per garantire la qualità dei rilevamenti delle parole chiave hardware e fornire l'esperienza Cortana hey nei casi in cui il rilevamento delle parole chiave hardware è assente o non disponibile.
Funzionalità "Learn my voice"
La funzionalità "Impara la mia voce" consente all'utente di addestrare Cortana a riconoscere la loro voce unica. Questa operazione viene eseguita dall'utente selezionando Learn how I say "Hey Cortana" (Ehi Cortana) nella schermata delle impostazioni di Cortana. L'utente ripete quindi sei frasi scelte con attenzione che forniscono un'ampia gamma di modelli fonetici per identificare gli attributi univoci della voce dell'utente.
Quando l'attivazione vocale è associata a "Learn my voice", i due algoritmi interagiscono per ridurre le false attivazioni. Questo è particolarmente utile per lo scenario della sala riunioni, in cui una persona dice "Ehi Cortana" in una stanza piena di dispositivi. Questa funzionalità è disponibile solo per Windows 10 versione 1903 e precedenti.
L'attivazione vocale è basata su un rilevatore di parole chiave (KWS) che reagisce se viene rilevata la frase chiave. Se il KWS deve riattivare il dispositivo da uno stato a basso consumo, la soluzione è nota come Riattivazione vocale (WoV). Per altre informazioni, vedere Riattivazione vocale.
Glossario dei termini
Questo glossario riepiloga i termini correlati all'attivazione vocale.
| Termine | Esempio/definizione |
|---|---|
| Comando a fasi | Esempio: Hey Cortana <metti in pausa, attendi il suono dell’EarCon> Che tempo fa? Questo comando viene talvolta definito "Comando a due colpi" o "Solo parola chiave" |
| Comando concatenato | Esempio: Ehi Cortana qual è il tempo? Questa operazione viene talvolta definita "comando one-shot" |
| Attivazione vocale | Lo scenario della fornitura del rilevamento di parole chiave per una frase di attivazione predefinita. Ad esempio, "Hey Cortana" è lo scenario di attivazione vocale Microsoft. |
| WoV | Riattivazione vocale: tecnologia che consente l'attivazione vocale da uno schermo spento, uno stato di alimentazione inferiore, a uno schermo con stato di alimentazione completa. |
| WoV da Standby moderno | Riattivazione vocale da uno stato di standby moderno (S0ix) con schermo spento a uno stato di schermo acceso con alimentazione completa (S0). |
| Standby moderno | Infrastruttura Windows a basso consumo energetico - successore della modalità Connected Standby (CS) in Windows 10. Il primo stato di standby moderno è quando lo schermo è spento. Lo stato di sospensione più profondo è quando si trova in DRIPS/Resilienza. Per altre informazioni, vedere Modern Standby |
| KWS | Rilevatore di parole chiave: l'algoritmo che rileva "Hey Cortana" |
| SW KWS | Rilevatore software di parole chiave – un'implementazione di KWS che gira sull'host (CPU). Per "Ehi Cortana", SW KWS è incluso come parte di Windows. |
| HW KWS | Riconoscitore di parole chiave scaricato su hardware: un'implementazione di KWS che gira su hardware. |
| Burst Buffer | Buffer circolare usato per archiviare i dati PCM che possono "scoppiare" in un rilevamento KWS, in modo che sia incluso tutto l'audio che ha attivato un rilevamento KWS. |
| Adattatore OEM per Rilevamento di Parole Chiave | Shim a livello driver che consente all'hardware abilitato per WoV di comunicare con Windows e con lo stack di Cortana. |
| Modello | File di dati del modello acustico usato dall'algoritmo KWS. Il file di dati è statico. I modelli vengono localizzati, uno per ogni area geografica. |
Integrazione di un spotter di parole chiave hardware
Per implementare un spotter di parole chiave hardware (HW KWS), completare le attività seguenti.
- Creare un rilevatore di parole chiave personalizzato basato sull'esempio SYSVAD descritto più avanti in questo articolo. Questi metodi verranno implementati in una DLL COM, descritta in Keyword Detector OEM Adapter Interface.
- Implementare miglioramenti WAVE RT descritti in WaveRT Enhancements (Miglioramenti WAVERT).
- Specificare le voci del file INF per descrivere le API personalizzate usate per il rilevamento delle parole chiave.
- PKEY_FX_KeywordDetector_StreamEffectClsid
- PKEY_FX_KeywordDetector_ModeEffectClsid
- PKEY_FX_KeywordDetector_EndpointEffectClsid
- PKEY_SFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- PKEY_MFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- PKEY_EFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- Esaminare le indicazioni per l'hardware e le linee guida per i test in Raccomandazione del dispositivo audio. Questo articolo fornisce indicazioni e consigli per la progettazione e lo sviluppo di dispositivi di input audio destinati all'uso con La piattaforma di riconoscimento vocale di Microsoft.
- Supportare sia i comandi in fase che i comandi concatenati.
- Supporto per "Hey Cortana" in tutte le impostazioni locali supportate di Cortana.
- Le API (Oggetti elaborazione audio) devono fornire gli effetti seguenti:
- AEC
- AGC
- NS
- Gli effetti per la modalità di elaborazione vocale devono essere segnalati dall'APO di MFX.
- L'APO può eseguire la conversione del formato in MFX.
- L'APO deve restituire il formato seguente:
- 16 kHz, mono, FLOAT.
- Facoltativamente, progettare qualsiasi API personalizzata per migliorare il processo di acquisizione audio. Per altre informazioni, vedere Oggetti di elaborazione audio di Windows.
Requisiti WoV per il rilevamento delle parole chiave esternalizzato sull'hardware (HW KWS)
- HW KWS WoV è supportato sia durante lo stato di lavoro S0 che durante lo stato di sospensione S0, noto anche come Standby moderno.
- HW KWS WoV non è supportato da S3.
Requisiti AEC per HW KWS
Per Windows versione 1709
- Per supportare HW KWS WoV nello stato di sospensione S0 (Modern Standby) non è necessario l'AEC.
- HW KWS WoV per lo stato di funzionamento S0 non è supportato nella versione 1709 di Windows.
Per Windows versione 1803
- HW KWS WoV per lo stato di funzionamento S0 è supportato.
- Per abilitare HW KWS WoV per lo stato di funzionamento S0, l'APO deve supportare AEC.
Panoramica del codice di esempio
È disponibile un codice di esempio per un driver audio che implementa l'attivazione vocale in GitHub come parte dell'esempio di adattatore audio virtuale SYSVAD. È consigliabile usare questo codice come punto di partenza. Il codice è disponibile in questa posizione.
https://github.com/Microsoft/Windows-driver-samples/tree/main/audio/sysvad/
Per altre informazioni sul driver audio di esempio SYSVAD, vedere Driver audio di esempio.
Informazioni sul sistema di riconoscimento delle parole chiave
Supporto dello stack audio di attivazione vocale
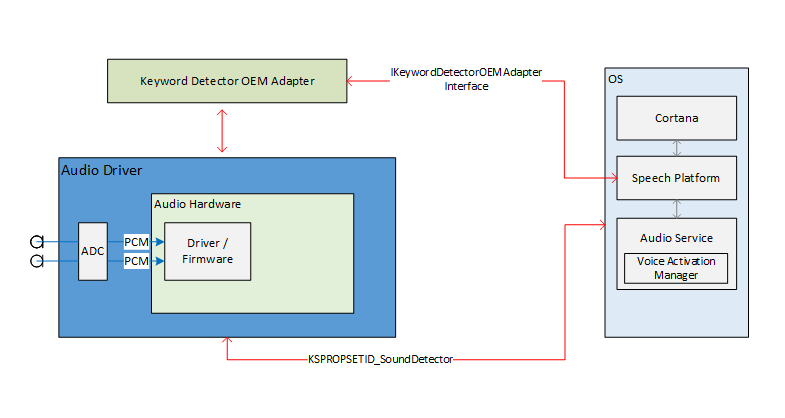
Le interfacce esterne dello stack audio per l'abilitazione dell'attivazione vocale fungono da pipeline di comunicazione per la piattaforma di riconoscimento vocale e i driver audio. Le interfacce esterne sono suddivise in tre parti.
- DDI (Device Driver Interface) del rilevatore di parole chiave. L'interfaccia del driver di dispositivo rilevatore di parole chiave è responsabile della configurazione e dell'arme di HW Keyword Spotter (KWS). Viene usato anche dal driver per notificare al sistema un evento di rilevamento.
- Adattatore DLL del dispositivo OEM di rilevamento delle parole chiave. Questa DLL implementa un'interfaccia COM per adattare i dati opachi specifici del driver da usare dal sistema operativo per facilitare il rilevamento delle parole chiave.
- Miglioramenti dello streaming WaveRT. I miglioramenti consentono al driver audio di trasmettere in streaming i dati audio memorizzati nel buffer dal rilevamento delle parole chiave.
Proprietà dell'endpoint audio
La compilazione del grafico dell'endpoint audio si verifica normalmente. Il grafico è preparato per gestire più velocemente dell'acquisizione in tempo reale. I timestamp nei buffer acquisiti rimangono true. In particolare, i timestamp riflettono correttamente i dati acquisiti in passato e memorizzati nel buffer e sono ora in fase di scoppio.
Teoria del bypass bluetooth dello streaming audio
Il driver espone un filtro KS per il dispositivo di acquisizione come di consueto. Questo filtro supporta diverse proprietà KS e un evento KS per configurare, abilitare e segnalare un evento di rilevamento. Il filtro include anche un'altra fabbrica di pin identificata come rilevatore di parole chiave (KWS). Questo pin viene usato per trasmettere l'audio dal riconoscitore di parole chiave.
Le proprietà sono:
- Tipi di parole chiave supportati: KSPROPERTY_SOUNDDETECTOR_PATTERNS. Il sistema operativo imposta questa proprietà per configurare le parole chiave da rilevare.
- Elenco dei GUID dei modelli di parole chiave : KSPROPERTY_SOUNDDETECTOR_SUPPORTEDPATTERNS. Questa proprietà viene usata per ottenere un elenco di GUID che identificano i tipi di modelli supportati.
- Armato - KSPROPERTY_SOUNDDETECTOR_ARMED. Questa proprietà di lettura/scrittura è uno stato booleano che indica se il rilevatore è armato. Il sistema operativo imposta questa opzione per coinvolgere il rilevatore di parole chiave. Il sistema operativo può cancellare questo problema per disattivare. Il driver cancella automaticamente questo valore quando vengono impostati i modelli di parole chiave e anche dopo che viene rilevata una parola chiave. Il sistema operativo deve riattivarsi.
- Risultato della corrispondenza: KSPROPERTY_SOUNDDETECTOR_MATCHRESULT. Questa proprietà di lettura contiene i dati dei risultati dopo il rilevamento.
L'evento generato quando viene rilevata una parola chiave è un evento KSEVENT_SOUNDDETECTOR_MATCHDETECTED .
Sequenza di operazioni
Avvio del sistema
- Il sistema operativo legge i tipi di parole chiave supportati per verificare che contenga parole chiave in tale formato.
- Il sistema operativo esegue la registrazione per l'evento di modifica dello stato del rilevatore.
- Il sistema operativo imposta i modelli di parole chiave.
- Il sistema operativo armerà il rilevatore.
Durante la ricezione dell'evento KS
- Il conducente disarma il rilevatore.
- Il sistema operativo legge lo stato del rilevatore di parole chiave, analizza i dati restituiti e determina il modello rilevato.
- Il sistema operativo riattiva il rilevatore.
Funzionamento interno di driver e hardware
Mentre il rilevatore è attivato, l'hardware può acquisire e memorizzare costantemente i dati audio in un piccolo buffer FIFO. Le dimensioni di questo buffer FIFO sono determinate dai requisiti al di fuori di questo documento, ma in genere possono essere centinaia di millisecondi fino a diversi secondi. L'algoritmo di rilevamento opera sul flusso di dati tramite questo buffer. La progettazione del driver e dell'hardware è tale che, mentre è armato, non c'è alcuna interazione tra il driver e l'hardware e non vi sono interruzioni ai processori "applicazione" fino a quando non viene rilevata una parola chiave. Ciò consente al sistema di raggiungere uno stato di alimentazione inferiore se non è presente alcuna altra attività.
Quando l'hardware rileva una parola chiave, genera un interrupt. Durante l'attesa del servizio dell'interrupt da parte del driver, l'hardware continua a acquisire l'audio nel buffer, assicurando che non vengano persi dati dopo la perdita della parola chiave, entro i limiti di buffering.
Timestamps delle parole chiave
Dopo aver rilevato una parola chiave, tutte le soluzioni di attivazione vocale devono memorizzare nel buffer tutte le parole chiave pronunciate, incluse le 250 ms prima dell'inizio della parola chiave. Il driver audio deve fornire timestamp che identificano l'inizio e la fine della frase chiave nel flusso.
Per supportare i timestamp di inizio/fine della parola chiave, il software DSP potrebbe dover apporre internamente dei timestamp agli eventi in base a un orologio DSP. Una volta rilevata una parola chiave, il software DSP interagisce con il driver per preparare un evento KS. Il driver e il software DSP devono associare i timestamp DSP a un valore del contatore delle prestazioni di Windows. Il metodo di questa operazione è specifico per la progettazione hardware. Una possibile soluzione consiste nel fatto che il driver legge il contatore delle prestazioni corrente, esegue una query sul timestamp DSP corrente, legge di nuovo il contatore delle prestazioni corrente e quindi stima una correlazione tra il contatore delle prestazioni e l'ora DSP. Una volta stabilita la correlazione, il driver può associare i timestamp della parola chiave DSP ai timestamp del contatore delle prestazioni di Windows.
Interfaccia per adattatore OEM del rilevatore di parole chiave
L'OEM fornisce un'implementazione dell'oggetto COM che funge da intermediario tra il sistema operativo e il driver, consentendo di calcolare o analizzare i dati opachi scritti e letti nel driver audio tramite KSPROPERTY_SOUNDDETECTOR_PATTERNS e KSPROPERTY_SOUNDDETECTOR_MATCHRESULT.
Il CLSID dell'oggetto COM è un GUID del tipo di pattern di rilevamento restituito da KSPROPERTY_SOUNDDETECTOR_SUPPORTEDPATTERNS. Il sistema operativo chiama CoCreateInstance passando il GUID del tipo di pattern per istanziare l'oggetto COM appropriato che è compatibile con il tipo di pattern di parole chiave e invoca i metodi sull'interfaccia IKeywordDetectorOemAdapter dell'oggetto.
Requisiti del modello di threading COM
L'implementazione dell'OEM può scegliere uno dei modelli di threading COM.
IKeywordDetectorOemAdapter
La progettazione dell'interfaccia tenta di mantenere l'implementazione dell'oggetto senza stato. In altre parole, l'implementazione non deve richiedere l'archiviazione di alcuno stato tra le chiamate al metodo. Infatti, le classi C++ interne probabilmente non necessitano di variabili membro oltre a quelle necessarie per implementare un oggetto COM in generale.
Metodi
Implementare i metodi seguenti.
- IKeywordDetectorOemAdapter::BuildArmingPatternData
- IKeywordDetectorOemAdapter::ComputeAndAddUserModelData
- IKeywordDetectorOemAdapter::GetCapabilities
- IKeywordDetectorOemAdapter::ParseDetectionResultData
- IKeywordDetectorOemAdapter::VerifyUserKeyword
KEYWORDID
L'enumerazione KEYWORDID identifica il testo/funzione della frase di una parola chiave e viene usata anche negli adattatori del servizio biometrico di Windows. Per altre informazioni, vedere Cenni preliminari sul framework biometrico - Componenti principali della piattaforma
typedef enum {
KwInvalid = 0,
KwHeyCortana = 1,
KwSelect = 2
} KEYWORDID;
Selettore di Parole Chiave
Lo struct KEYWORDSELECTOR è un set di ID che selezionano in modo univoco una parola chiave e un linguaggio specifici.
typedef struct
{
KEYWORDID KeywordId;
LANGID LangId;
} KEYWORDSELECTOR;
Gestione dei dati del modello
Modello indipendente dall'utente statico : la DLL OEM include in genere alcuni dati del modello indipendente dall'utente statico incorporati nella DLL o in un file di dati separato incluso nella DLL. Il set di ID di parole chiave supportati restituiti dalla routine GetCapabilities dipende da questi dati. Ad esempio, se l'elenco degli ID di parole chiave supportati restituiti da GetCapabilities include KwHeyCortana, i dati del modello indipendente dall'utente statico includerebbero i dati per "Hey Cortana" (o la relativa traduzione) per tutte le lingue supportate.
Modello dipendente dall'utente dinamico : IStream fornisce un modello di archiviazione ad accesso casuale. Il sistema operativo passa un puntatore dell'interfaccia IStream a molti dei metodi nell'interfaccia IKeywordDetectorOemAdapter. Il sistema operativo esegue il backup dell'implementazione IStream con l'archiviazione appropriata per un massimo di 1 MB di dati.
Il contenuto e la struttura dei dati all'interno di questa risorsa di archiviazione sono definiti dall'OEM. Lo scopo previsto è l'archiviazione permanente dei dati del modello dipendente dall'utente calcolati o recuperati dalla DLL OEM.
Il sistema operativo può chiamare i metodi di interfaccia con un IStream vuoto, in particolare se l'utente non ha mai addestrato una parola chiave. Il sistema operativo crea un archivio IStream separato per ogni utente. In altre parole, un determinato IStream archivia i dati del modello per uno e un solo utente.
Lo sviluppatore della DLL OEM decide come gestire i dati indipendenti dall'utente e dipendenti dall'utente. Tuttavia, non archivierà mai i dati utente all'esterno di IStream. Una possibile progettazione di DLL OEM commuterebbe internamente tra l'accesso a IStream e i dati statici indipendenti dall'utente, a seconda dei parametri del metodo corrente. Una progettazione alternativa potrebbe controllare IStream all'inizio di ogni chiamata al metodo e aggiungere i dati indipendenti dall'utente statico a IStream, se non è già presente, consentendo al resto del metodo di accedere solo a IStream per tutti i dati del modello.
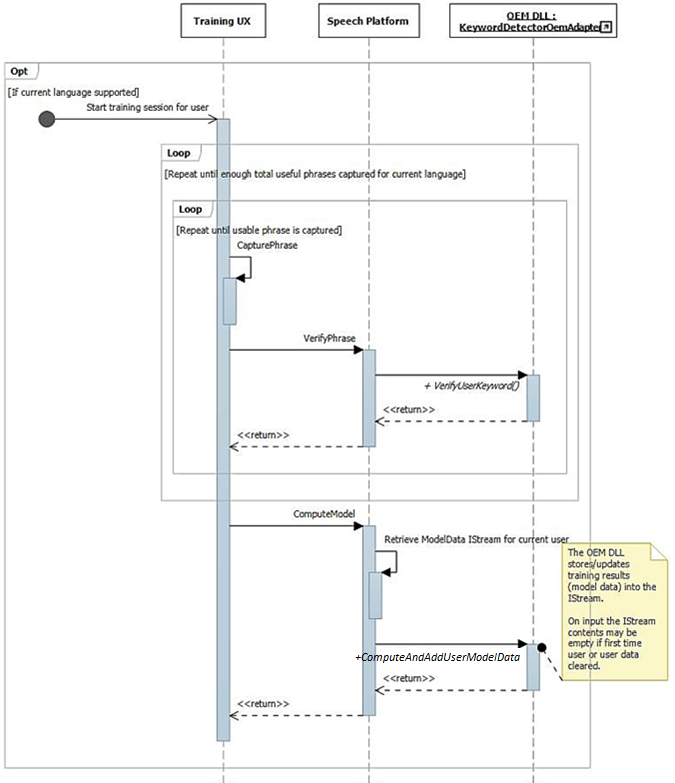
Formazione e operazione di elaborazione audio
Come descritto in precedenza, il flusso dell'interfaccia utente di training comporta la disponibilità di frasi foneticamente ricche e complete nel flusso audio. Ogni frase viene passata singolarmente a IKeywordDetectorOemAdapter::VerifyUserKeyword per verificare che contenga la parola chiave prevista e abbia una qualità accettabile. Dopo che tutte le frasi vengono raccolte e verificate dall'interfaccia utente, vengono passate tutte in una chiamata a IKeywordDetectorOemAdapter::ComputeAndAddUserModelData.
L'audio viene elaborato in modo univoco per il training dell'attivazione vocale. La tabella seguente riepiloga le differenze tra il training di attivazione vocale e l'utilizzo regolare del riconoscimento vocale.
| Allenamento vocale | Riconoscimento vocale | |
|---|---|---|
| Modalità | Crudo | Raw o Speech |
| Pin | Normale | KWS |
| Formato audio | Float a 32 bit (Tipo = Audio, Sottotipo = IEEE_FLOAT, Frequenza di campionamento = 16 kHz, bit = 32) | Gestito dallo stack audio del sistema operativo |
| Microfono | Microfono 0 | Tutti i microfoni in matrice o mono |
Panoramica del sistema di riconoscimento delle parole chiave
Questo diagramma offre una panoramica del sistema di riconoscimento delle parole chiave.
Diagrammi di sequenza di riconoscimento delle parole chiave
In questi diagrammi il modulo del runtime di riconoscimento vocale viene visualizzato come piattaforma di riconoscimento vocale. Come accennato in precedenza, la piattaforma di riconoscimento vocale Windows viene usata per alimentare tutte le esperienze vocali in Windows 10, ad esempio Cortana e dettatura.
Durante l'avvio, le funzionalità vengono raccolte usando IKeywordDetectorOemAdapter::GetCapabilities.
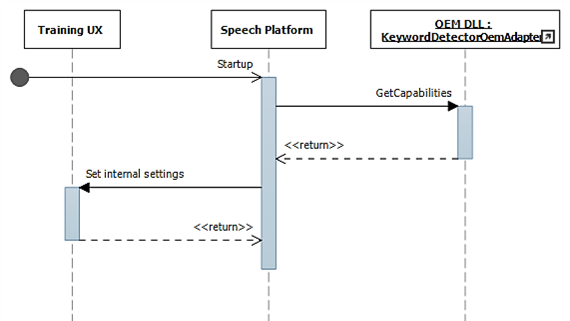
Successivamente, quando l'utente seleziona "Learn my voice", viene richiamato il flusso di training.
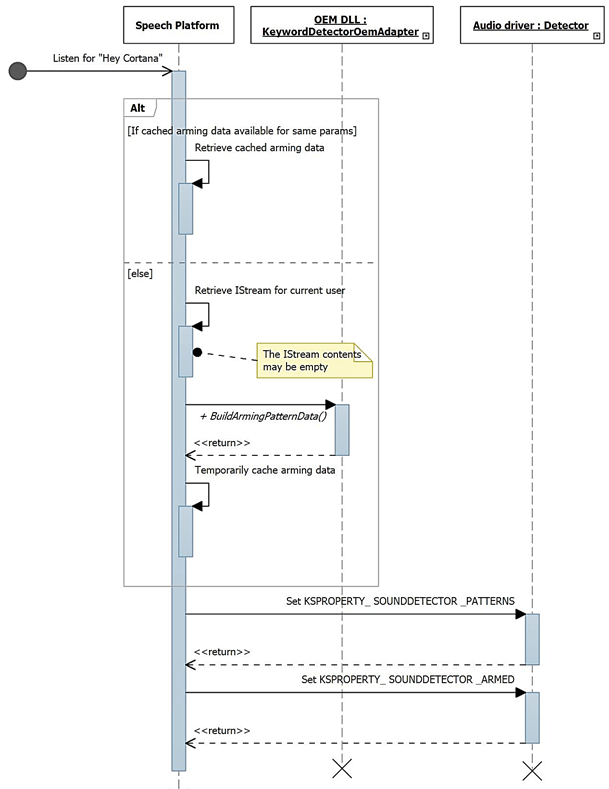
Questo diagramma descrive il processo di configurazione per il rilevamento delle parole chiave.
Miglioramenti di WAVERT
Le interfacce miniport sono definite per essere implementate dai driver miniport WaveRT. Queste interfacce forniscono metodi per semplificare il driver audio, migliorare le prestazioni e l'affidabilità della pipeline audio del sistema operativo o supportare nuovi scenari. Viene definita una nuova proprietà dell'interfaccia del dispositivo PnP che consente al driver di fornire un'espressione statica dei vincoli di dimensione del buffer al sistema operativo.
Dimensioni buffer
Un driver opera in vari vincoli quando si spostano dati audio tra il sistema operativo, il driver e l'hardware. Questi vincoli possono essere dovuti al trasporto hardware fisico che sposta i dati tra memoria e hardware e/o a causa dei moduli di elaborazione dei segnali all'interno dell'hardware o del DSP associato.
HW-KWS soluzioni devono supportare dimensioni di acquisizione audio di almeno 100 ms e fino a 200 ms.
Il driver esprime i vincoli di dimensione del buffer impostando la proprietà del dispositivo DEVPKEY_KsAudio_PacketSize_Constraints sull'interfaccia del dispositivo PnP KSCATEGORY_AUDIO del filtro KS con i pin di streaming KS. Questa proprietà deve rimanere valida e stabile mentre l'interfaccia del filtro KS è abilitata. Il sistema operativo può leggere questo valore in qualsiasi momento senza dover aprire un handle del driver e richiamare il driver.
DEVPKEY_KsAudio_PacketSize_Constraints
Il valore della proprietà DEVPKEY_KsAudio_PacketSize_Constraints contiene una struttura KSAUDIO_PACKETSIZE_CONSTRAINTS che descrive i vincoli hardware fisici, ovvero a causa dei meccanismi di trasferimento dei dati dal buffer WaveRT all'hardware audio. La struttura include una matrice di 0 o più strutture KSAUDIO_PACKETSIZE_PROCESSINGMODE_CONSTRAINT che descrivono vincoli specifici di qualsiasi modalità di elaborazione del segnale. Il driver imposta questa proprietà prima di chiamare PcRegisterSubdevice o abilitare in altro modo l'interfaccia del filtro KS per i pin di streaming.
IMiniportWaveRTInputStream
Un driver implementa questa interfaccia per un migliore coordinamento del flusso di dati audio dal driver al sistema operativo. Se questa interfaccia è disponibile in un flusso di acquisizione, il sistema operativo usa metodi su questa interfaccia per accedere ai dati nel buffer WaveRT. Per altre informazioni, vedere IMiniportWaveRTInputStream::GetReadPacket
IMiniportWaveRTOutputStream
Un miniport WaveRT implementa facoltativamente questa interfaccia per essere avvisata dello stato di avanzamento della scrittura dal sistema operativo e per restituire una posizione precisa del flusso. Per altre informazioni, vedere IMiniportWaveRTOutputStream::SetWritePacket, IMiniportWaveRTOutputStream::GetOutputStreamPresentationPosition e IMiniportWaveRTOutputStream::GetPacketCount.
Marca temporale del contatore di prestazioni
Diverse routine dei driver restituiscono timestamp del contatore delle prestazioni di Windows che riflettono il momento in cui i campioni vengono acquisiti o presentati dal dispositivo.
Nei dispositivi che dispongono di pipeline DSP complesse e di elaborazione dei segnali, il calcolo di un timestamp accurato può essere complesso e deve essere eseguito attentamente. I timestamp non devono riflettere il momento in cui i campioni sono stati trasferiti dal sistema operativo al DSP.
- All'interno del DSP, traccia i timestamp dei campioni utilizzando un orologio interno DSP.
- Tra il driver e il DSP, calcolare una correlazione tra il contatore delle prestazioni di Windows e l'orologio a parete DSP. Le procedure per questo possono variare da semplici (ma meno precise) a piuttosto complesse o nuove (ma più precise).
- Tenere conto di eventuali ritardi costanti dovuti ad algoritmi di elaborazione dei segnali o a trasporti hardware o pipeline, a meno che questi ritardi non vengano altrimenti rilevati.
Operazione di lettura burst
Questa sezione descrive l'interazione tra il sistema operativo e il driver per le letture rapide. La lettura burst può verificarsi all'esterno dello scenario di attivazione vocale, purché il driver supporti il modello WaveRT di streaming basato su pacchetti, inclusa la funzione IMiniportWaveRTInputStream::GetReadPacket .
Si discutono due scenari di lettura di esempio a raffica. In uno scenario, se il miniport supporta un pin con categoria pin KSNODETYPE_AUDIO_KEYWORDDETECTOR , il driver inizia l'acquisizione e il buffering interno dei dati quando viene rilevata una parola chiave. In un altro scenario, il driver può memorizzare internamente i dati all'esterno del buffer WaveRT se il sistema operativo non legge i dati abbastanza rapidamente chiamando IMiniportWaveRTInputStream::GetReadPacket.
Per eseguire il burst dei dati acquisiti prima della transizione a KSSTATE_RUN, il driver deve conservare informazioni accurate sul timestamp del campione insieme ai dati di acquisizione memorizzati nel buffer. I timestamp identificano l'istante di campionamento degli esempi acquisiti.
Dopo che il flusso passa a KSSTATE_RUN, il driver imposta immediatamente l'evento di notifica del buffer perché contiene già dati disponibili.
In questo evento il sistema operativo chiama GetReadPacket() per ottenere informazioni sui dati disponibili.
Il driver restituisce il numero di pacchetti dei dati acquisiti validi (0 per il primo pacchetto dopo la transizione da KSSTATE_STOP a KSSTATE_RUN), da cui il sistema operativo può derivare la posizione del pacchetto all'interno del buffer WaveRT e la posizione del pacchetto rispetto all'inizio del flusso.
Il driver restituisce anche il valore del contatore delle prestazioni che corrisponde all'istante di campionamento del primo campione nel pacchetto. Questo valore del contatore delle prestazioni potrebbe essere relativamente vecchio, a seconda della quantità di dati di acquisizione memorizzati nel buffer hardware o driver (all'esterno del buffer WaveRT).
Se sono disponibili più dati nel buffer che non sono stati letti, il driver:
- Trasferisce immediatamente i dati nello spazio disponibile del buffer WaveRT, ovvero lo spazio non utilizzato dal pacchetto restituito da GetReadPacket, restituisce true per MoreData e imposta l'evento di notifica del buffer prima di tornare da questa routine. O
- Programmi hardware per eseguire il burst del pacchetto successivo nello spazio disponibile del buffer WaveRT, restituisce false per MoreData e successivamente imposta l'evento buffer al termine del trasferimento.
Il sistema operativo legge i dati dal buffer WaveRT usando le informazioni restituite da GetReadPacket().
Il sistema operativo attende l'evento di notifica del buffer successivo. L'attesa potrebbe terminare immediatamente se il driver imposta la notifica del buffer nel passaggio (2c).
Se il driver non ha impostato immediatamente l'evento nel passaggio (2c), il driver imposta l'evento dopo che trasferisce più dati acquisiti nel buffer WaveRT e lo rende disponibile per la lettura del sistema operativo
Vai a (2). Per KSNODETYPE_AUDIO_KEYWORDDETECTOR pin del rilevatore di parole chiave, i driver devono allocare un buffer di burst interno sufficiente per almeno 5000 ms di dati audio. Se il sistema operativo non riesce a creare un flusso sul pin prima dell'overflow del buffer, il driver può terminare l'attività di buffering interna e liberare le risorse associate.
Riattivazione vocale
Riattivazione vocale (WoV) consente all'utente di attivare ed eseguire query su un motore di riconoscimento vocale da uno schermo spento, uno stato a basso consumo energetico, a uno stato a piena potenza, dicendo una determinata parola chiave, ad esempio "Ehi Cortana".
Questa funzionalità consente al dispositivo di essere sempre in ascolto della voce dell'utente mentre il dispositivo è in uno stato di basso consumo, incluso quando lo schermo è spento e il dispositivo è inattivo. A tale scopo, viene usata una modalità di ascolto, ovvero una potenza inferiore rispetto all'utilizzo di energia più elevato rilevato durante la registrazione normale del microfono. Il riconoscimento vocale a basso consumo consente a un utente di pronunciare una frase chiave predefinita come "Ehi Cortana", seguita da una frase vocale concatenata come "qual è il mio prossimo appuntamento" per richiamare il parlato a mani libere. Questo funziona indipendentemente dal fatto che il dispositivo sia in uso o inattiva con lo schermo spento.
Lo stack audio è responsabile della comunicazione dei dati di riattivazione (ID voce, trigger di parole chiave, livello di attendibilità) e notifica ai client interessati che la parola chiave viene rilevata.
Convalida per i sistemi di standby moderni
WoV da uno stato di inattività del sistema può essere convalidato nei sistemi Modern Standby usando il test di base di riattivazione tramite voce su fonte di alimentazione CA e il test di base di riattivazione tramite voce su fonte di alimentazione CC in HLK. Questi test verificano che il sistema disponga di un rilevatore di parole chiave hardware (HW-KWS), sia in grado di entrare nello stato DRIPS (Deepest Runtime Idle Platform State) e possa riattivarsi dalla modalità Modern Standby con un comando vocale, con una latenza di ripresa del sistema inferiore o uguale a un secondo.