Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Windows Machine Learning (ML) consente agli sviluppatori C#, C++e Python di eseguire modelli di intelligenza artificiale ONNX in locale nei PC Windows tramite ONNX Runtime, con gestione automatica del provider di esecuzione per hardware diverso (CPU, GPU, NPU). È possibile usare modelli di PyTorch, Tensorflow/Keras, TFLite, scikit-learn e altri framework con ONNX Runtime.
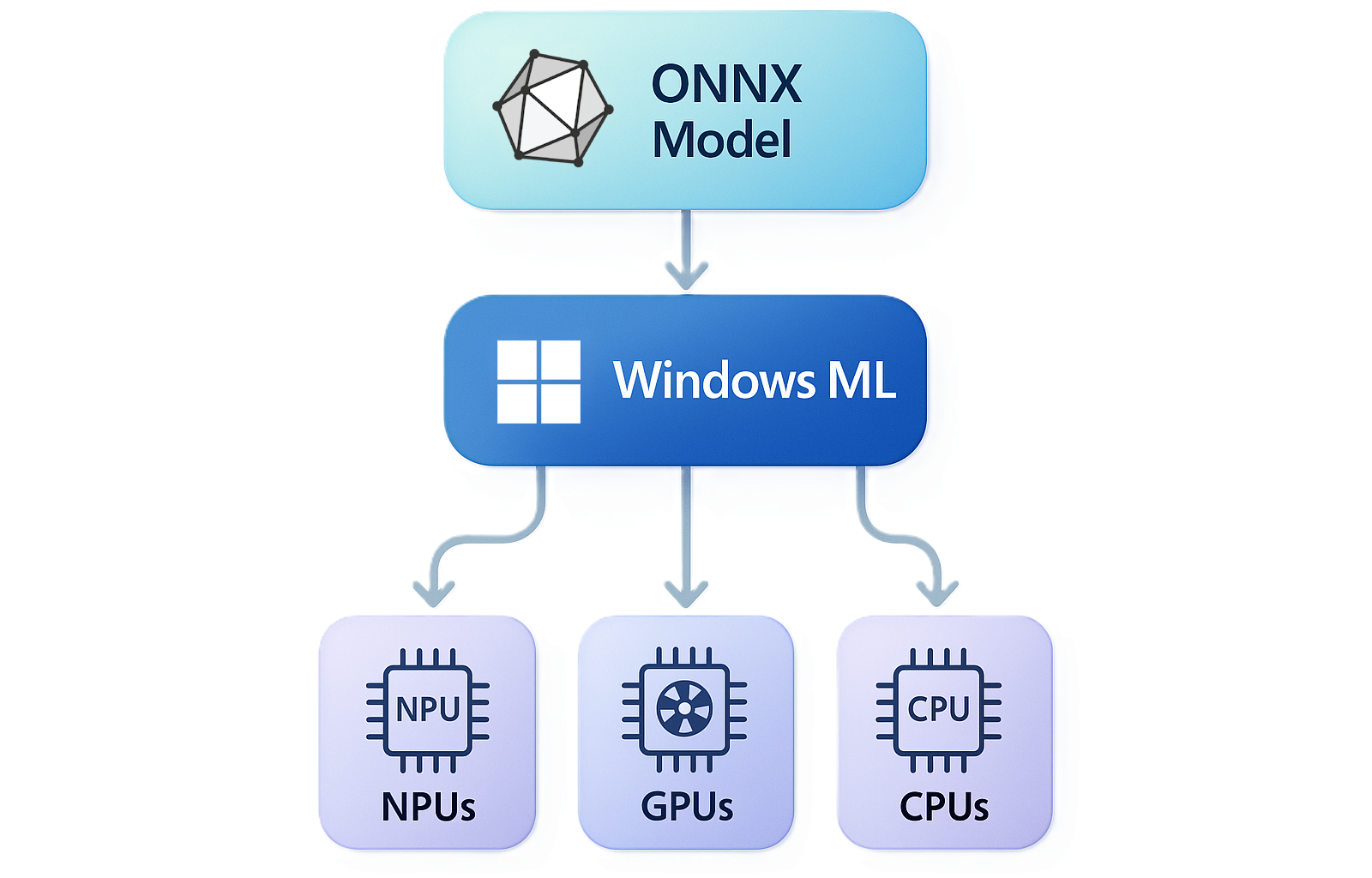
Se non si ha già familiarità con il runtime ONNX, è consigliabile leggere la documentazione sul runtime ONNX. In breve, Windows ML fornisce una copia condivisa a livello di Windows del runtime ONNX, oltre alla possibilità di scaricare dinamicamente i provider di esecuzione (EPS).
Vantaggi principali
- Ottenere dinamicamente gli EP più recenti - scarica e gestisce automaticamente i provider di esecuzione specifici dell'hardware più recenti
- Runtime ONNX condiviso: usa il runtime a livello di sistema invece di creare un bundle personalizzato, riducendo le dimensioni dell'app
- Download/installazioni di dimensioni inferiori : non è necessario includere grandi pacchetti eseguibili e il runtime ONNX nella tua app
- Supporto hardware generale : viene eseguito su PC Windows (x64 e ARM64) e Windows Server con qualsiasi configurazione hardware
Requisiti di sistema
- Sistema operativo: versione di Windows supportata da Windows App SDK
- Architettura: x64 o ARM64
- Hardware: qualsiasi configurazione pc (CPU, GPU integrate/discrete, NPU)
Annotazioni
Il supporto per CPU e GPU (tramite DirectML) è disponibile in tutte le versioni di Windows supportate. I provider di esecuzione ottimizzati per i fornitori per le NPU e hardware GPU specifico richiedono Windows 11 versione 24H2 (build 26100) o superiore. Per informazioni dettagliate, vedere Provider di esecuzione supportati.
Che cos'è un provider di esecuzione?
Un provider di esecuzione (EP) è un componente che consente ottimizzazioni specifiche dell'hardware per le operazioni di Machine Learning (ML). I provider di esecuzione astraggono diversi back-end di calcolo (CPU, GPU, acceleratori specializzati) e forniscono un'interfaccia unificata per il partizionamento dei grafi, la registrazione del kernel e l'esecuzione dell'operatore. Per altre informazioni, vedere la documentazione sul runtime ONNX.
È possibile visualizzare l'elenco di indirizzi IP supportati da Windows ML qui.
Come funziona
Windows ML include una copia del runtime ONNX e consente di scaricare dinamicamente provider di esecuzione specifici del fornitore, in modo che l'inferenza del modello possa essere ottimizzata nell'ampia gamma di CPU, GPU e NPU nell'ecosistema Windows.
Distribuzione automatica
- Installazione dell'app - Programma di avvio automatico di Windows App SDK inizializza Windows ML
- Rilevamento hardware : il runtime identifica i processori disponibili
- Download EP - scarica automaticamente provider di esecuzione ottimali
- Pronto per l'esecuzione : l'app può usare immediatamente i modelli di intelligenza artificiale
In questo modo si elimina la necessità di:
- Bundle execution providers for specific hardware vendors (Provider di esecuzione bundle per fornitori hardware specifici)
- Creare compilazioni di app separate per provider di esecuzione diversi
- Gestire manualmente gli aggiornamenti del provider di esecuzione
Annotazioni
L'utente è comunque responsabile dell'ottimizzazione dei modelli per hardware diverso. Windows ML gestisce la distribuzione del provider di esecuzione, non l'ottimizzazione del modello. Per altre informazioni sull'ottimizzazione, vedere AI Toolkit e onNX Runtime Tutorials (Esercitazioni sul runtime ONNX ).
Ottimizzazione delle prestazioni
La versione più recente di Windows ML funziona direttamente con provider di esecuzione dedicati per GPU e NPU, offrendo prestazioni to-the-metal pari agli SDK dedicati del passato, ad esempio TensorRT per RTX, AI Engine Direct e l'estensione Intel per PyTorch. Windows ML è stato progettato per ottenere prestazioni migliori della categoria per GPU e NPU, mantenendo al tempo stesso i vantaggi di "scrivi una volta, eseguibile ovunque" offerti dalla precedente soluzione basata su DirectML.
Uso dei provider di esecuzione con Windows ML
Windows ML Runtime offre un modo flessibile per accedere ai provider di esecuzione di Machine Learning (ML), che possono ottimizzare l'inferenza del modello di Machine Learning in configurazioni hardware diverse. Tali EP vengono distribuiti come pacchetti separati che possono essere aggiornati indipendentemente dal sistema operativo. Per ulteriori informazioni sul download e l'installazione dinamica degli EP, vedere la documentazione sui provider di esecuzione.
Conversione di modelli in ONNX
È possibile convertire i modelli da altri formati a ONNX in modo da poterli usare con Windows ML. Per altre informazioni, vedere la documentazione di Visual Studio Code AI Toolkit su come convertire i modelli nel formato ONNX . Per altre informazioni sulla conversione di modelli PyTorch, TensorFlow e Hugging Face in ONNX, vedere anche le esercitazioni sul runtime ONNX .
Gestione di modelli
Windows ML offre opzioni flessibili per la gestione dei modelli di intelligenza artificiale:
- Catalogo modelli- Scaricare dinamicamente modelli da cataloghi online senza creare bundle di file di grandi dimensioni
- Modelli locali - Includere i file di modello direttamente nel pacchetto dell'applicazione
Integrazione con l'ecosistema di intelligenza artificiale Windows
Windows ML funge da base per la piattaforma di intelligenza artificiale Windows più ampia:
- API windows per intelligenza artificiale - Modelli predefiniti per le attività comuni
- Foundry Local - Modelli di intelligenza artificiale pronti per l'uso
- Modelli personalizzati - Accesso diretto all'API Windows ML per scenari avanzati
Fornire commenti e suggerimenti
È stato rilevato un problema o si hanno suggerimenti? Cercare o creare problemi in GitHub di Windows App SDK.
Passaggi successivi
- Introduzione: Introduzione a Windows ML
- Gestione dei modelli: Panoramica del catalogo dei modelli
- Altre informazioni: documentazione del runtime ONNX
- Convertire i modelli: conversione del modello di VS Code AI Toolkit