Questo articolo risponde ad alcune domande comuni su come eseguire Azure HDInsight.
Creazione o eliminazione di cluster HDInsight
Come si effettua il provisioning di un cluster HDInsight?
Per esaminare i tipi di cluster HDInsight e i metodi di provisioning, vedere Configurare i cluster in HDInsight con Apache Hadoop, Apache Spark, Apache Kafka e altri.
Come si elimina un cluster HDInsight esistente?
Per altre informazioni sull'eliminazione di un cluster quando non è più in uso, vedere Eliminare un cluster HDInsight.
Lasciar trascorrere almeno 30-60 minuti tra le operazioni di creazione ed eliminazione. In caso contrario, l'operazione potrebbe non riuscire con il messaggio di errore seguente:
Conflict (HTTP Status Code: 409) error when attempting to delete a cluster immediately after creation of a cluster. If you encounter this error, wait until the newly created cluster is in operational state before attempting to delete it.
Come si seleziona il numero corretto di core o nodi per il carico di lavoro?
Il numero appropriato di core e altre opzioni di configurazione dipendono da diversi fattori.
Per altre informazioni, vedere Pianificazione della capacità per i cluster HDInsight.
Quali sono i vari tipi di nodi in un cluster HDInsight?
Quali sono le procedure consigliate per la creazione di cluster HDInsight di grandi dimensioni?
- È consigliabile configurare i cluster HDInsight con un database Ambari personalizzato per migliorare la scalabilità del cluster.
- Usare Azure Data Lake Storage Gen2 per creare cluster HDInsight in grado di sfruttare la maggiore larghezza di banda e altre caratteristiche per le prestazioni di Azure Data Lake Storage Gen2.
- I nodi head devono essere sufficientemente grandi per contenere più servizi master in esecuzione in questi nodi.
- Alcuni carichi di lavoro specifici, ad esempio Interactive Query, necessitano anche di nodi Zookeeper di dimensioni maggiori. Prendere in considerazione almeno otto macchine virtuali core.
- Nel caso di Hive e Spark, usare il metastore Hive esterno.
Singoli componenti
È possibile installare componenti aggiuntivi nel cluster?
Sì. Per installare componenti aggiuntivi o personalizzare la configurazione del cluster, usare:
Script durante o dopo la creazione. Gli script vengono richiamati tramite un'azione script. Un'azione script è un'opzione di configurazione che può essere usata dal portale di Azure, dai cmdlet di Windows PowerShell per HDInsight o da .NET SDK per HDInsight. Questa opzione di configurazione può essere usata dal portale di Azure, dai cmdlet di Windows PowerShell per HDInsight o da .NET SDK per HDInsight.
Piattaforma di applicazioni HDInsight per installare le applicazioni.
Per un elenco dei componenti supportati, vedere Componenti e versioni di Apache Hadoop disponibili in HDInsight
È possibile aggiornare i singoli componenti preinstallati nel cluster?
Se si aggiornano componenti predefiniti o applicazioni preinstallate nel cluster, la configurazione risultante non sarà supportata da Microsoft. Queste configurazioni di sistema non sono state testate da Microsoft. Provare a usare una versione diversa del cluster HDInsight che potrebbe già disporre della versione aggiornata del componente preinstallato.
Ad esempio, l'aggiornamento di Hive come singolo componente non è supportato. HDInsight è un servizio gestito e molti servizi sono integrati con il server Ambari e testati. L'aggiornamento di Hive come singolo componente comporta la modifica dei file binari indicizzati di altri componenti e causerà problemi di integrazione dei componenti nel cluster.
È possibile eseguire Spark e Kafka nello stesso cluster HDInsight?
No, non è possibile eseguire Apache Kafka e Apache Spark nello stesso cluster HDInsight. Creare cluster separati per Kafka e Spark per evitare problemi di contesa delle risorse.
Come si modifica il fuso orario in Ambari?
Accedere all'interfaccia utente Web Ambari all'indirizzo
https://CLUSTERNAME.azurehdinsight.net, dove CLUSTERNAME corrisponde al nome del cluster in uso.Nell'angolo in alto a destra selezionare admin | Settings (Amministrazione | Impostazioni).
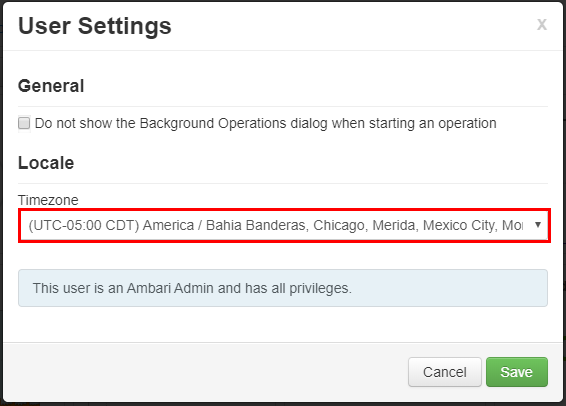
Nella finestra User Settings (Impostazioni utente) selezionare il nuovo fuso orario dall'elenco a discesa Timezone (Fuso orario) e quindi fare clic su Save (Salva).
Metastore
Come è possibile eseguire la migrazione dal metastore esistente al database SQL di Azure?
Per eseguire la migrazione da SQL Server al database SQL di Azure, vedere Esercitazione: Eseguire la migrazione offline di SQL Server a un database singolo o in pool nel database SQL di Azure usando il Servizio Migrazione del database.
Il metastore Hive viene eliminato quando viene eliminato il cluster?
Dipende dal tipo di metastore che è stato configurato per il cluster.
Per un metastore predefinito: il metastore predefinito fa parte del ciclo di vita del cluster. Quando si elimina un cluster verranno eliminati anche il metastore e i metadati corrispondenti.
Per un metastore personalizzato: il ciclo di vita del metastore non è associato al ciclo di vita di un cluster. È quindi possibile creare ed eliminare cluster senza perdere metadati. I metadati come ad esempio gli schemi di Hive verranno mantenuti anche dopo aver eliminato e ricreato il cluster HDInsight.
Per altre informazioni, vedere Use external metadata stores in Azure HDInsight (Usare archivi di metadati esterni in Azure HDInsight).
La migrazione di un metastore Hive include anche la migrazione dei criteri predefiniti del database Ranger?
No, la definizione dei criteri si trova nel database Ranger, quindi per trasferire i criteri sarà necessario eseguire la migrazione del database Ranger.
È possibile eseguire la migrazione di un metastore Hive da un cluster Enterprise Security Package (ESP) a un cluster non Enterprise Security Package e viceversa?
Sì, è possibile eseguire la migrazione di un metastore Hive da un cluster Enterprise Security Package a un cluster non Enterprise Security Package.
Come è possibile stimare le dimensioni di un database metastore Hive?
Un metastore Hive viene usato per archiviare i metadati per le origini dati usate dal server Hive. I requisiti di dimensioni dipendono in parte dal numero e dalla complessità delle origini dati Hive. Questi elementi non possono essere stimati in anticipo. Come descritto in Linee guida per i metastore Hive, è possibile iniziare con un livello S2. Il livello offre 50 DTU e 250 GB di spazio di archiviazione e, se si verifica un collo di bottiglia, aumentare le prestazioni del database.
Come metastore esterno sono supportati anche altri database oltre al database SQL di Azure?
No, Microsoft supporta solo il database SQL di Azure come metastore personalizzato esterno.
È possibile condividere un metastore tra più cluster?
Sì, è possibile condividere metastore personalizzati tra più cluster, purché usino la stessa versione di HDInsight.
Connettività e reti virtuali
Quali sono le implicazioni del blocco delle porte 22 e 23 sulla rete?
Se si bloccano le porte 22 e 23, non si concederà l'accesso SSH al cluster. Queste porte non vengono usate dal servizio HDInsight.
Per altre informazioni, vedere i documenti seguenti:
È possibile distribuire una macchina virtuale aggiuntiva all'interno della stessa subnet di un cluster HDInsight?
Sì, è possibile distribuire una macchina virtuale aggiuntiva all'interno della stessa subnet di un cluster HDInsight. Sono disponibili le configurazioni seguenti:
Nodi perimetrali: è possibile aggiungere un altro nodo perimetrale al cluster, come descritto in Usare nodi perimetrali vuoti nei cluster Apache Hadoop in HDInsight.
Nodi autonomi: è possibile aggiungere una macchina virtuale autonoma alla stessa subnet e accedere al cluster da tale macchina virtuale usando l'endpoint privato
https://<CLUSTERNAME>-int.azurehdinsight.net. Per altre informazioni, vedere Controllare il traffico di rete.
È consigliabile archiviare i dati nel disco locale di un nodo perimetrale?
No, non è consigliabile archiviare i dati in un disco locale. Se si verifica un errore nel nodo, tutti i dati archiviati in locale andranno persi. È consigliabile archiviare i dati in Azure Data Lake Storage Gen2 o nell'archiviazione BLOB di Azure oppure montando una condivisione file di Azure per archiviare i dati.
È possibile aggiungere un cluster HDInsight esistente a un'altra rete virtuale?
No, non è possibile. La rete virtuale deve essere specificata al momento del provisioning. Se durante il provisioning non viene specificata alcuna rete virtuale, la distribuzione crea una rete interna non accessibile dall'esterno. Per altre informazioni, vedere Aggiungere HDInsight a una rete virtuale esistente.
Sicurezza e certificati
Quali sono le raccomandazioni per la protezione da malware nei cluster Azure HDInsight?
Per informazioni sulla protezione da malware, vedere Microsoft Antimalware per Servizi cloud di Azure e macchine virtuali.
Come si crea un file keytab per un cluster ESP (Enterprise Security Package) HDInsight?
Creare un file keytab Kerberos per il nome utente del dominio. Sarà possibile usare il file keytab in un secondo momento per eseguire l'autenticazione a cluster remoti aggiunti a un dominio senza immettere una password. Il nome di dominio è in caratteri maiuscoli:
ktutil
ktutil: addent -password -p <username>@<DOMAIN.COM> -k 1 -e aes256-cts-hmac-sha1-96
Password for <username>@<DOMAIN.COM>: <password>
ktutil: wkt <username>.keytab
ktutil: q
Quando è necessario il salting per la crittografia AES256 durante la creazione del keytab?
Se tenantName e DomainName sono diversi (ad esempio TenantName – bob@CONTOSO.ONMICROSOFT.COM & DomainName – bob@CONTOSOMicrosoft.ONMICROSOFT.COM), è necessario aggiungere un valore SALT usando l'opzione -s.
Ricerca per categorie determinare il valore SALT corretto?
- Usare un account di accesso Kerberos interattivo per determinare il valore salt appropriato per il keytab. Per impostazione predefinita, l'account di accesso Kerberos interattivo userà la crittografia più elevata. La traccia deve essere abilitata per osservare il salt. Di seguito è riportato un esempio di accesso Kerberos:
$ KRB5_TRAACE=/dev/stdout kinit <username> -V
- Esaminare l'output del salt "......." Linea.
- Usare questo valore salt durante la creazione del keytab.
ktutil
ktutil: addent -password -p <username>@<DOMAIN.COM> -k 1 -e aes256-cts-hmac-sha1-96 -s <SALTvalue>
Password for <username>@<DOMAIN.COM>: <password>
ktutil: wkt <username>.keytab
ktutil: q
È possibile usare un tenant Di Microsoft Entra esistente per creare un cluster HDInsight con ESP?
Abilitare Microsoft Entra Domain Services prima di creare un cluster HDInsight con ESP. Hadoop open source si basa su Kerberos per l'autenticazione e la sicurezza, anziché su OAuth.
Per aggiungere macchine virtuali a un dominio, è necessario disporre di un controller di dominio. Microsoft Entra Domain Services è il controller di dominio gestito ed è considerato un'estensione dell'ID Microsoft Entra. Microsoft Entra Domain Services fornisce tutti i requisiti Kerberos per creare un cluster Hadoop sicuro in modo gestito. HDInsight come servizio gestito si integra con Microsoft Entra Domain Services per garantire la sicurezza.
È possibile usare un certificato autofirmato in una configurazione LDAP sicura di Microsoft Entra Domain Services ed effettuare il provisioning di un cluster ESP?
È consigliabile usare un certificato rilasciato da un'autorità di certificazione. Tuttavia, in ESP è supportato anche l'uso di un certificato autofirmato. Per altre informazioni, vedi:
È possibile installare Data Analytics Studio (DAS) come cluster ESP?
No, DAS non è supportato nei cluster ESP.
Come è possibile eseguire il pull dell'attività di accesso visualizzata in Ranger?
Per i requisiti di controllo, Microsoft consiglia di abilitare i log di Monitoraggio di Azure come descritto in Usare i log di Monitoraggio di Azure per monitorare i cluster HDInsight.
È possibile disabilitare 'Clamscan' nel cluster?
Clamscan è il software antivirus che viene eseguito nel cluster HDInsight e usato dal servizio di sicurezza di Azure (azsecd) per proteggere i cluster da attacchi virus. Microsoft consiglia fortemente agli utenti di evitare di apportare modifiche alla configurazione di Clamscan predefinita.
Questo processo non interferisce con altri processi né sottrae cicli da altri processi. Darà sempre la precedenza ad altri processi. I picchi di CPU da Clamscan devono essere visibili solo quando il sistema è inattivo.
Negli scenari in cui è necessario controllare la pianificazione, è possibile seguire questa procedura:
Disabilitare l'esecuzione automatica usando il comando seguente:
sudo
usr/local/bin/azsecd config -s clamav -d Disabledsudo service azsecd restartAggiungere un processo cron che esegue il comando seguente come utente ROOT:
/usr/local/bin/azsecd manual -s clamav
Per altre informazioni su come configurare ed eseguire un processo cron, vedere How do I set up a Cron job? (Come si configura un processo cron).
Perché LLAP è disponibile nei cluster ESP (Enterprise Security Package) Spark?
LLAP è abilitato per motivi di sicurezza (Apache Ranger), non per le prestazioni. Usare macchine virtuali con nodi di dimensioni maggiori per gestire l'utilizzo delle risorse di LLAP (ad esempio, almeno D13V2).
Come è possibile aggiungere altri gruppi di Microsoft Entra dopo la creazione di un cluster ESP?
Esistono due modi per raggiungere questo obiettivo: 1. È possibile ricreare il cluster e aggiungere il gruppo aggiuntivo al momento della creazione del cluster. Se si usa la sincronizzazione con ambito in Microsoft Entra Domain Services, assicurarsi che il gruppo B sia incluso nella sincronizzazione con ambito.
2. Aggiungere il gruppo come sottogruppo annidato del gruppo precedente usato per creare il cluster ESP. Ad esempio, se è stato creato un cluster ESP con il gruppo A, sarà possibile aggiungere in un secondo momento il gruppo B come sottogruppo annidato di A e dopo circa un'ora sarà sincronizzato e disponibile automaticamente nel cluster.
Storage
È possibile aggiungere un'istanza di Azure Data Lake Storage Gen2 a un cluster HDInsight esistente come account di archiviazione aggiuntivo?
No, attualmente non è possibile aggiungere un account di archiviazione Azure Data Lake Storage Gen2 a un cluster con archiviazione BLOB come risorsa di archiviazione primaria. Per altre informazioni, vedere Confrontare le opzioni di archiviazione.
Come è possibile trovare l'entità servizio attualmente collegata per un account Data Lake Storage?
È possibile trovare le impostazioni in Accesso a Data Lake Storage Gen1 nelle proprietà del cluster nel portale di Azure. Per altre informazioni, vedere Verificare la configurazione del cluster.
Come è possibile calcolare l'utilizzo degli account di archiviazione e dei contenitori BLOB per i cluster HDInsight?
Eseguire una di queste azioni:
Trovare le dimensioni della cartella /user/hive/.Trash/ nel cluster HDInsight, usando la riga di comando seguente:
hdfs dfs -du -h /user/hive/.Trash/
Come è possibile configurare il controllo per l'account di archiviazione BLOB?
Per controllare gli account di archiviazione BLOB, configurare il monitoraggio usando la procedura descritta in Monitorare un account di archiviazione nel portale di Azure. Un log di controllo HDFS fornisce solo informazioni di controllo esclusivamente per il file system HDFS locale (hdfs://mycluster). Non include le operazioni eseguite nell'archiviazione remota.
Come è possibile trasferire file tra un contenitore BLOB e un nodo head HDInsight?
Eseguire uno script simile allo script della shell seguente nel nodo head:
for i in cat filenames.txt
do
hadoop fs -get $i <local destination>
done
Nota
Il file filenames.txt avrà il percorso assoluto dei file nei contenitori BLOB.
Sono disponibili plug-in Ranger per l'archiviazione?
Attualmente non esiste alcun plug-in Ranger per l'archiviazione BLOB e Azure Data Lake Storage Gen1 o Gen2. Per i cluster ESP, è consigliabile usare Azure Data Lake Storage. È almeno possibile impostare manualmente le autorizzazioni specifiche al livello del file system usando gli strumenti HDFS. Inoltre, quando si usa Azure Data Lake Archiviazione, i cluster ESP eseguiranno alcuni dei controlli di accesso del file system usando Microsoft Entra ID a livello di cluster.
È possibile assegnare criteri di accesso ai dati ai gruppi di sicurezza degli utenti usando Azure Storage Explorer. Per altre informazioni, vedi:
È possibile aumentare lo spazio di archiviazione HDFS in un cluster senza aumentare le dimensioni del disco dei nodi di lavoro?
No. Non è possibile aumentare le dimensioni del disco di alcun nodo di lavoro. L'unico modo per aumentare le dimensioni del disco è quindi eliminare il cluster e ricrearlo con macchine virtuali con nodi di lavoro di dimensioni più elevate. Non usare HDFS per archiviare i dati di HDInsight, perché se si elimina il cluster i dati verranno eliminati. Archiviare invece i dati in Azure. Anche l'aumento delle prestazioni del cluster può aggiungere ulteriore capacità al cluster HDInsight.
Nodi perimetrali
È possibile aggiungere un nodo perimetrale dopo la creazione del cluster?
Come è possibile connettersi a un nodo perimetrale?
Dopo aver creato un nodo perimetrale, è possibile connettersi ad esso usando SSH sulla porta 22. Il nome del nodo perimetrale è disponibile nel portale del cluster. I nomi terminano in genere con -ed.
Perché gli script persistenti non vengono eseguiti automaticamente nei nodi perimetrali appena creati?
Gli script persistenti vengono usati per personalizzare i nuovi nodi di lavoro aggiunti al cluster tramite operazioni di dimensionamento. Gli script persistenti non si applicano ai nodi perimetrali.
REST API
Quali sono le chiamate API REST per eseguire il pull di una visualizzazione query Tez dal cluster?
È possibile usare gli endpoint REST seguenti per eseguire il pull delle informazioni necessarie in formato JSON. Per effettuare le richieste, usare le intestazioni di autenticazione di base.
Tez Query View: https://< cluster name.azurehdinsight.net/ws/v1/timeline/HIVE_QUERY_ID/>Tez Dag View: https://< cluster name.azurehdinsight.net/ws/v1/timeline/TEZ_DAG_ID/>
Ricerca per categorie recuperare i dettagli di configurazione dal cluster HDI usando un utente di Microsoft Entra?
Per negoziare token di autenticazione appropriati con l'utente di Microsoft Entra, passare attraverso il gateway usando il formato seguente:
- https://
<cluster dnsname>.azurehdinsight.net/api/v1/clusters/testclusterdem/stack_versions/1/repository_versions/1
Ricerca per categorie usare Ambari RESTful per monitorare le prestazioni di YARN?
Se si chiama il comando curl nella stessa rete virtuale o in una rete virtuale con peering, il comando è:
curl -u <cluster login username> -sS -G
http://<headnodehost>:8080/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpu
Se si chiama il comando curl dall'esterno della rete virtuale o da una rete virtuale senza peering, il comando è:
Per un cluster non ESP:
curl -u <cluster login username> -sS -G https://<ClusterName>.azurehdinsight.net/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpuPer un cluster ESP:
curl -u <cluster login username>-sS -G https://<ClusterName>.azurehdinsight.net/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpu
Nota
Curl richiede una password. È necessario immettere una password valida per il nome utente di accesso del cluster.
Fatturazione
Quanto costa distribuire un cluster HDInsight?
Per altre informazioni sui prezzi e sulle domande frequenti relative alla fatturazione, vedere la pagina Prezzi di Azure HDInsight.
Quando inizia e termina la fatturazione di HDInsight?
La fatturazione del cluster HDInsight inizia dopo la creazione del cluster e si interrompe solo quando questo viene eliminato. La fatturazione è calcolata al minuto ripartita su base proporzionale.
Come è possibile annullare la sottoscrizione?
Per informazioni su come annullare la sottoscrizione, vedere Annullare la sottoscrizione di Azure.
Per le sottoscrizioni con pagamento in base al consumo, cosa accade dopo l'annullamento della sottoscrizione?
Per informazioni sulla sottoscrizione dopo l'annullamento, vedere Cosa accade dopo l'annullamento della sottoscrizione?
Hive
Perché la versione di Hive viene visualizzata come 1.2.1000 anziché 2.1 nell'interfaccia utente di Ambari anche se si esegue un cluster HDInsight 3.6?
Anche se nell'interfaccia utente di Ambari viene visualizzata solo la versione 1.2, HDInsight 3.6 contiene sia Hive 1.2 che Hive 2.1.
Altre domande frequenti
Cosa offre HDInsight per le funzionalità di elaborazione dei flussi in tempo reale?
Per informazioni sulle funzionalità di integrazione dell'elaborazione dei flussi, vedere Scelta di una tecnologia di elaborazione dei flussi in Azure.
Esiste un modo per terminare in modo dinamico il nodo head del cluster quando il cluster è inattivo per un periodo di tempo specifico?
Non è possibile eseguire questa azione con i cluster HDInsight. Per questi scenari, è consigliabile usare Azure Data Factory.
Quali sono le offerte di conformità disponibili per HDInsight?
Per informazioni sulla conformità, vedere il Centro protezione Microsoft.