Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A: Tutti i livelli di Gestione API
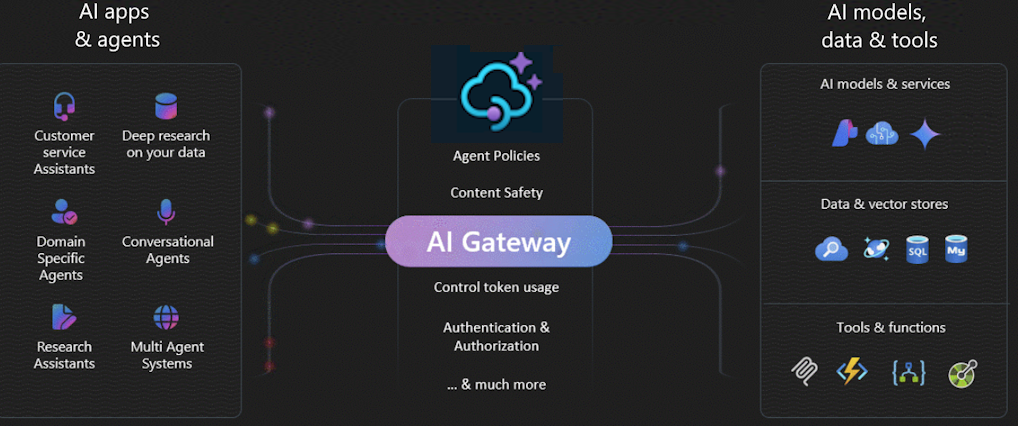
Il gateway AI in Gestione API di Azure è un set di funzionalità che consentono di gestire efficacemente i back-end di intelligenza artificiale. Usare queste funzionalità per proteggere, ridimensionare, monitorare e gestire modelli, agenti e strumenti di intelligenza artificiale che consentono di eseguire il backup di app e carichi di lavoro intelligenti.
Usare il gateway di intelligenza artificiale per gestire un'ampia gamma di endpoint di intelligenza artificiale, tra cui:
- Distribuzioni di Microsoft Foundry e di Azure OpenAI in Microsoft Foundry Models
- Distribuzioni di API Inferenza del modello Azure AI
- Server MCP remoti e API agente A2A
- Modelli e endpoint compatibili con OpenAI ospitati da provider non Microsoft
- Modelli ed endpoint self-hosted
Nota
Il gateway di intelligenza artificiale, incluse le funzionalità del server MCP, estende il gateway API esistente di Gestione API; non è un'offerta separata. Le funzionalità correlate per la governance e gli sviluppatori si trovano in Azure Centro API.
Nota
New! Il gateway di intelligenza artificiale può ora essere integrato direttamente in Microsoft Foundry, consentendo di gestire modelli, agenti e strumenti di intelligenza artificiale dall'ambiente Foundry. Per altre informazioni, vedere la sezione AI gateway in Microsoft Foundry.
Perché usare un gateway di intelligenza artificiale?
L'adozione dell'IA nelle organizzazioni prevede diverse fasi:
- Definizione dei requisiti e valutazione dei modelli di intelligenza artificiale
- Creazione di app e agenti di intelligenza artificiale che devono accedere a modelli e servizi di intelligenza artificiale
- Operazionalizzazione e distribuzione di app e back-end di intelligenza artificiale nell'ambiente di produzione
Con la maturità dell'adozione dell'IA, soprattutto nelle aziende di grandi dimensioni, il gateway di intelligenza artificiale consente di affrontare le sfide principali. Ti aiuta a:
- Autenticare e autorizzare l'accesso ai servizi di intelligenza artificiale
- Bilanciamento del carico tra più endpoint di intelligenza artificiale
- Monitorare e registrare le interazioni con intelligenza artificiale
- Gestire l'utilizzo e le quote dei token tra più applicazioni
- Abilitare self-service per i team di sviluppo
Mediazione e controllo del traffico
Usando il gateway di intelligenza artificiale, è possibile:
- Importare e configurare rapidamente endpoint LLM compatibili con OpenAI o pass-through come API
- Gestire i modelli distribuiti in Microsoft Foundry o presso provider come Amazon Bedrock
- Gestire i completamenti delle chat, le risposte e le API in tempo reale
- Esporre le API REST esistenti come server MCP e supportare il pass-through ai server MCP
- Importare e gestire le API dell'agente A2A (anteprima)
Ad esempio, per eseguire l'onboarding di un modello distribuito in Microsoft Foundry o in un altro provider, Gestione API offre procedure guidate semplificate per importare lo schema e configurare l'autenticazione nell'endpoint di intelligenza artificiale usando un'identità gestita, eliminando la necessità di una configurazione manuale. All'interno della stessa esperienza intuitiva, è possibile preconfigurare i criteri per scalabilità, sicurezza e osservabilità delle API.

Ulteriori informazioni:
- Importare l'API Foundry di Microsoft
- Importare un'API del modello linguistico
- Esporre un'API REST in qualità di server MCP
- Esporre e gestire un server MCP esistente
- Importare un'API dell'agente A2A
Scalabilità e prestazioni
Una delle risorse principali nei servizi di intelligenza artificiale generativa è token. Microsoft Foundry e altri provider assegnano quote per la distribuzione modelli come token al minuto (TPM). Questi token vengono distribuiti tra i consumer del modello, ad esempio applicazioni diverse, team di sviluppatori o reparti all'interno dell'azienda.
Se si dispone di una singola app che si connette a un back-end del servizio di intelligenza artificiale, è possibile gestire l'utilizzo dei token con un limite TPM impostato direttamente nella distribuzione del modello. Tuttavia, quando il portfolio di applicazioni aumenta, potrebbero essere presenti più app che chiamano endpoint di servizio di intelligenza artificiale singoli o multipli. Questi endpoint possono essere istanze con pagamento in base al consumo o Unità elaborate con provisioning (PTU). È necessario assicurarsi che un'app non usi l'intera quota TPM e impedisca ad altre app di accedere ai back-end necessari.
Limitazione della frequenza dei token e quote
Configurare un criterio di limite di token per le API LLM per gestire e applicare limiti per ogni consumer di API in base all'uso dei token del servizio di intelligenza artificiale. Usando questo criterio, è possibile impostare un limite TPM o una quota di token in un periodo specificato, ad esempio ogni ora, giornaliera, settimanale, mensile o annuale.
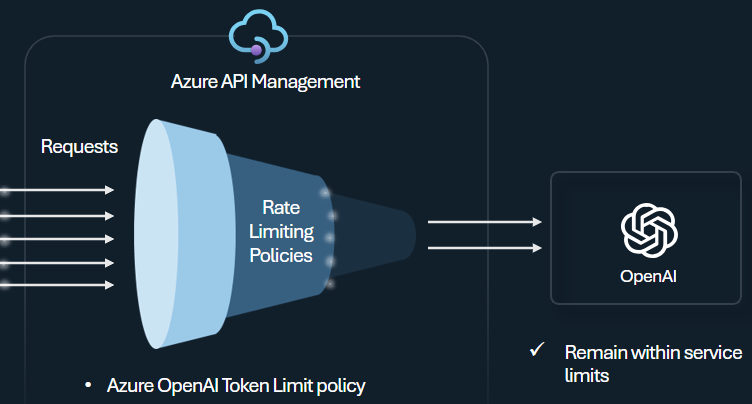
Questo criterio offre flessibilità per assegnare limiti basati su token su qualsiasi chiave del contatore, ad esempio la chiave di sottoscrizione, l'indirizzo IP di origine o una chiave arbitraria definita tramite un'espressione di criteri. Il criterio abilita anche il calcolo anticipato dei token di prompt da parte di Gestione API di Azure, minimizzando le richieste inutili al backend del servizio di intelligenza artificiale se il prompt supera già il limite.
L'esempio di base seguente illustra come impostare un limite TPM di 500 per ogni chiave di sottoscrizione:
<llm-token-limit counter-key="@(context.Subscription.Id)"
tokens-per-minute="500" estimate-prompt-tokens="false" remaining-tokens-variable-name="remainingTokens">
</llm-token-limit>
Ulteriori informazioni:
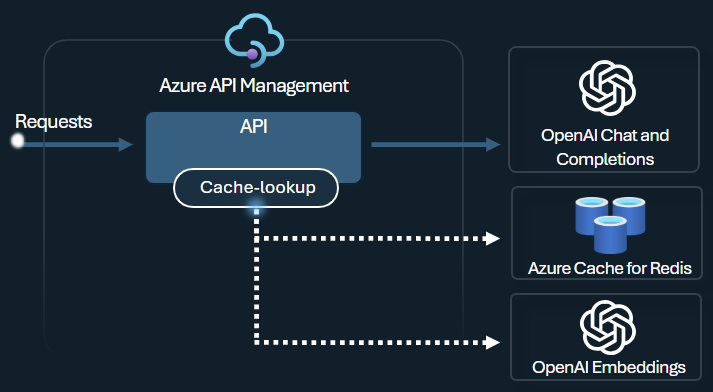
Memorizzazione nella cache semantica
La memorizzazione nella cache semantica è una tecnica che migliora le prestazioni delle API LLM memorizzando nella cache i risultati (completamenti) delle richieste precedenti e riutilizzandoli confrontando la prossimità vettoriale della richiesta alle richieste precedenti. Questa tecnica riduce il numero di chiamate effettuate al back-end del servizio di intelligenza artificiale, migliora i tempi di risposta per gli utenti finali e consente di ridurre i costi.
In Gestione delle API, abilitare la memorizzazione nella cache semantica usando Azure Managed Redis o un'altra cache esterna compatibile con RediSearch e integrata in Gestione API di Azure. Usando l'API Embeddings, i criteri llm-semantic-cache-store e llm-semantic-cache-lookup archiviano e recuperano completamenti di prompt semanticamente simili dalla cache. Questo approccio garantisce il riutilizzo dei completamenti, con conseguente riduzione del consumo di token e prestazioni di risposta migliorate.
Ulteriori informazioni:
- Impostare una cache esterna in Gestione API di Azure
- Abilita la memorizzazione nella cache semantica per le API AI in Gestione API di Azure
Funzionalità di scalabilità nativa in Gestione API
Gestione API offre anche funzionalità di scalabilità predefinite che consentono al gateway di gestire volumi elevati di richieste alle API di intelligenza artificiale. Queste funzionalità includono l'aggiunta automatica o manuale delle unità di scala del gateway e l'aggiunta di gateway regionali per le distribuzioni con più aree. Le funzionalità specifiche dipendono dal livello di servizio Gestione API.
Ulteriori informazioni:
- Aggiornare e ridimensionare un'istanza di Gestione API
- Distribuire un'istanza di Gestione API in più aree
Nota
Anche se Gestione API è in grado di ridimensionare la capacità del gateway, è anche necessario ridimensionare e distribuire il traffico ai back-end di intelligenza artificiale per supportare un aumento del carico (vedere la sezione Resilienza ). Ad esempio, per sfruttare la distribuzione geografica del sistema in una configurazione multiregione, distribuire i servizi di intelligenza artificiale back-end nelle stesse aree dei gateway di Gestione API.
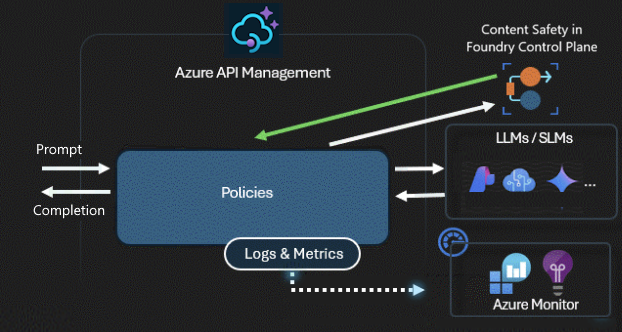
Sicurezza e sicurezza
Un gateway di intelligenza artificiale protegge e controlla l'accesso alle API di intelligenza artificiale. Usando il gateway di intelligenza artificiale, è possibile:
- Usare le identità gestite per eseguire l'autenticazione ai servizi di intelligenza artificiale in Azure, quindi non sono necessarie chiavi API per l'autenticazione
- Configurare l'autorizzazione OAuth per le app e gli agenti di intelligenza artificiale per accedere alle API o ai server MCP utilizzando il gestore delle credenziali di API Management.
- Applicare criteri per moderare automaticamente le richieste LLM usando Sicurezza dei contenuti di Azure AI
Ulteriori informazioni:
- Autenticare e autorizzare l'accesso alle API LLM
- Informazioni sulle credenziali API e sulla gestione delle credenziali
- Applicare controlli di sicurezza del contenuto alle richieste LLM
- Proteggere l'accesso ai server MCP
Resiliency
Una sfida per la creazione di applicazioni intelligenti consiste nel garantire che le applicazioni siano resilienti agli errori back-end e possano gestire carichi elevati. Configurando gli endpoint LLM con backends in Gestione API di Azure, è possibile bilanciare il carico tra di essi. È anche possibile definire regole di interruttore per interrompere l'inoltro delle richieste ai back-end del servizio di intelligenza artificiale se non sono reattive.
Bilanciamento del carico
Il servizio di bilanciamento del carico backend supporta il bilanciamento del carico di tipo round-robin, ponderato, basato sulla priorità e sulla sessione. È possibile definire una strategia di distribuzione del carico che soddisfi i requisiti specifici. Ad esempio, definire le priorità all'interno della configurazione del servizio di bilanciamento del carico per garantire un utilizzo ottimale di endpoint specifici Microsoft Foundry, in particolare quelli acquistati come istanze PTU.
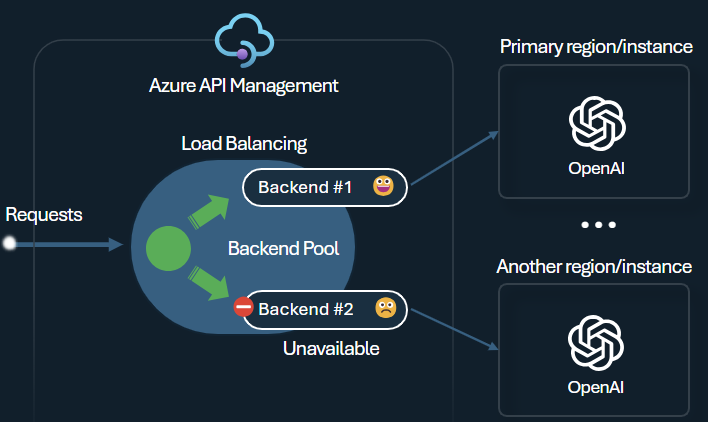
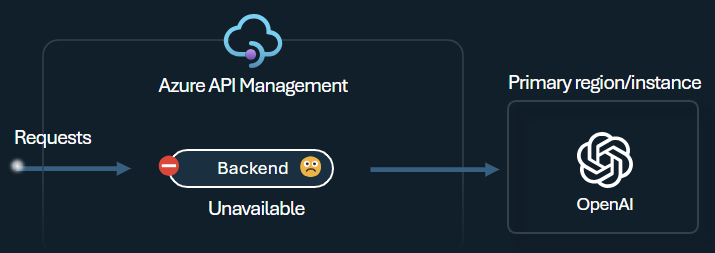
Interruttore automatico
L'interruttore del back-end include la durata dinamica di intervento, applicando i valori dell'intestazione Retry-After fornita dal back-end. Questa funzionalità garantisce un ripristino preciso e tempestivo dei back-end, ottimizzando l'utilizzo dei back-end prioritari.
Ulteriori informazioni:
Osservabilità e governance
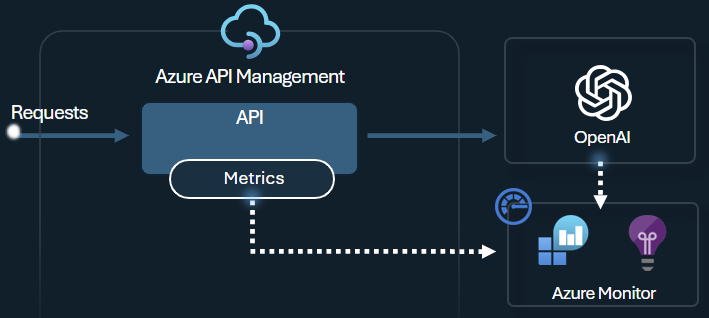
Gestione API offre funzionalità complete di monitoraggio e analisi per tenere traccia dei modelli di utilizzo dei token, ottimizzare i costi, garantire la conformità ai criteri di governance dell'intelligenza artificiale e risolvere i problemi con le API di intelligenza artificiale. Usare queste funzionalità per:
- Registra le richieste e i completamenti in Monitoraggio di Azure.
- Monitorare le metriche dei token per ogni consumatore in Application Insights.
- Visualizzare il dashboard di monitoraggio predefinito.
- Configurare i criteri con espressioni personalizzate.
- Gestire le quote di token tra le applicazioni.
Ad esempio, è possibile generare metriche dei token usando il criterio llm-emit-token-metric e aggiungere dimensioni personalizzate che è possibile usare per filtrare la metrica in Monitoraggio di Azure. L'esempio seguente genera metriche di token con dimensioni per l'indirizzo IP del client, l'ID API e l'ID utente (da un'intestazione personalizzata):
<llm-emit-token-metric namespace="llm-metrics">
<dimension name="Client IP" value="@(context.Request.IpAddress)" />
<dimension name="API ID" value="@(context.Api.Id)" />
<dimension name="User ID" value="@(context.Request.Headers.GetValueOrDefault("x-user-id", "N/A"))" />
</llm-emit-token-metric>
Abilitare anche la registrazione per le API LLM in Gestione API di Azure per tenere traccia dell'utilizzo, delle richieste e dei completamenti dei token per la fatturazione e il controllo. Dopo aver abilitato la registrazione, è possibile analizzare i log in Application Insights e usare un dashboard predefinito in Gestione API per visualizzare i modelli di utilizzo dei token nelle API di intelligenza artificiale.

Ulteriori informazioni:
- Registrazione dell'utilizzo, delle richieste e dei completamenti dei token
- Generare metriche relative al consumo di token
Esperienza sviluppatore
Usare il gateway di intelligenza artificiale e Azure Centro API per semplificare lo sviluppo e la distribuzione delle API di intelligenza artificiale e dei server MCP. Oltre alle esperienze intuitive di configurazione dei criteri e importazione per scenari di intelligenza artificiale comuni nella Gestione delle API, è possibile sfruttare i vantaggi seguenti:
- Registrazione semplificata delle API e dei server MCP in un catalogo aziendale nel Centro API di Azure
- Accesso self-service all'API e al server MCP tramite i portali per sviluppatori in Gestione API e Centro API
- Strumenti di personalizzazione dei criteri di gestione delle API
- Connettore di Copilot Studio dell'API Center per estendere le funzionalità degli agenti di intelligenza artificiale
Ulteriori informazioni:
- Registrare e individuare i server MCP nel Centro API
- Sincronizzare le API e i server MCP tra Gestione API e Centro API
- Portale per sviluppatori di Gestione API
- Portale di Centro API
- Gestione API di Azure policy toolkit
- Connettore di Copilot Studio dell'API Center
Gateway di intelligenza artificiale in Microsoft Foundry (anteprima)
È ora possibile integrare il gateway di intelligenza artificiale direttamente in Microsoft Foundry, consentendo di gestire il traffico di intelligenza artificiale dall'ambiente Foundry. Quando si crea o si associa un'istanza del gateway di intelligenza artificiale alla risorsa Foundry, è possibile gestire, proteggere e monitorare le risorse Foundry tramite il gateway.
Models: configurare le quote dei token e i limiti di frequenza direttamente nell'interfaccia Foundry per tutte le distribuzioni di modelli, tra cui Azure OpenAI e altri provider.
Agenti: registrano gli agenti in esecuzione ovunque (su Azure, altri cloud o in locale) nel piano di controllo di Foundry per un inventario e una governance centralizzati. Visualizzare i dati di telemetria in Foundry o Application Insights e applicare criteri come la limitazione o la sicurezza dei contenuti.
Strumenti: registrare gli strumenti MCP ospitati in qualsiasi ambiente per la governance e l'individuazione automatica. Gli strumenti vengono visualizzati nell'inventario Foundry, pronti per l'utilizzo da parte degli agenti.
Per scenari avanzati, ad esempio criteri personalizzati, reti aziendali o gateway federati, accedere all'esperienza di Gestione API di Azure completa mantenendo al tempo stesso la continuità con le risorse gestite da Foundry.
Ulteriori informazioni:
- Abilitare gateway di intelligenza artificiale in Microsoft Foundry
- Registrare agenti personalizzati in Foundry
- Gestire gli strumenti con il gateway di intelligenza artificiale
- Connettere un gateway di intelligenza artificiale al servizio Foundry Agent
Accesso anticipato alle funzionalità del gateway di intelligenza artificiale
I clienti di Gestione API possono accedere in anticipo a nuove funzionalità e funzionalità tramite il canale di rilascio del gateway di intelligenza artificiale. Questo accesso consente di provare le innovazioni più recenti del gateway di intelligenza artificiale prima che siano disponibili a livello generale e fornire commenti e suggerimenti per modellare il prodotto.
Ulteriori informazioni:
Lab ed esempi di codice
- Lab di funzionalità del gateway di IA
- Workshop sul gateway AI
- Azure OpenAI con Gestione API (Node.js)
- Python codice di esempio
- Schema di progettazione del gateway AI unificato
Architettura e progettazione
- Architettura di riferimento del gateway di intelligenza artificiale con Gestione API
- Acceleratore per la zona di destinazione del gateway di hub IA
- Progettazione e l'implementazione di una soluzione gateway con risorse Azure OpenAI
- Usare un gateway davanti a più distribuzioni di Azure OpenAI
Contenuto correlato
- Blog: il gateway di intelligenza artificiale in Gestione API di Azure è ora disponibile in Microsoft Foundry
- Blog: Introduzione alle funzionalità di intelligenza artificiale in Gestione API di Azure
- Blog: Integrazione di Azure Content Safety con Gestione API
- Training: gestire le API di intelligenza artificiale generative
- Bilanciamento del carico intelligente per gli endpoint OpenAI