Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa guida è un'introduzione allo sviluppo di Funzioni di Azure con Python. Questo articolo presuppone che l'utente abbia già letto il Manuale dello sviluppatore di Funzioni di Azure.
Importante
Questo articolo supporta sia il modello di programmazione v1 che v2 per Python in Funzioni di Azure. Il modello Python v1 usa un file functions.json per definire le funzioni e il nuovo modello v2 consente invece di usare un approccio basato su decorator. Questo nuovo approccio comporta una struttura di file più semplice ed è più incentrato sul codice. Scegliere il selettore v2 nella parte superiore dell'articolo per informazioni su questo nuovo modello di programmazione.
Gli sviluppatori Python potrebbero essere interessati anche a questi articoli:
- Visual Studio Code: creare la prima app Python con Visual Studio Code.
- Terminale o prompt dei comandi: creare la prima app Python dal prompt dei comandi usando Azure Functions Core Tools.
- Esempi: esaminare alcune app Python esistenti nel browser di esempi di Learn.
- Visual Studio Code: creare la prima app Python con Visual Studio Code.
- Terminale o prompt dei comandi: creare la prima app Python dal prompt dei comandi usando Azure Functions Core Tools.
- Esempi: esaminare alcune app Python esistenti nel browser di esempi di Learn.
Opzioni di sviluppo
Entrambi i modelli di programmazione di Funzioni Python supportano lo sviluppo locale in uno degli ambienti seguenti:
Modello di programmazione Python v2:
Modello di programmazione Python v1:
È anche possibile creare funzioni Python nel portale di Azure.
Suggerimento
Sebbene sia possibile sviluppare funzioni di Azure basate su Python in locale in Windows, Python è supportato solo in un piano di hosting basato su Linux quando è in esecuzione in Azure. Per altre informazioni, vedere l'elenco delle combinazioni di sistema operativo/runtime supportate.
Modello di programmazione
Funzioni di Azure si aspetta che una funzione sia un metodo senza stato nello script di Python che elabora l'input e genera l'output. Per impostazione predefinita, il runtime si aspetta che il metodo venga implementato come metodo globale denominato main() nel file __init__.py. È anche possibile specificare un punto di ingresso alternativo.
I dati vengono associati alla funzione da trigger e associazioni tramite attributi del metodo che usano la proprietà name definita nel file function.json. Ad esempio, il file function.json seguente descrive una funzione semplice attivata da una richiesta HTTP denominata req:
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
In base a questa definizione, il file __init__.py che contiene il codice della funzione potrebbe essere simile all'esempio seguente:
def main(req):
user = req.params.get('user')
return f'Hello, {user}!'
È anche possibile dichiarare esplicitamente i tipi di attributi e il tipo restituito nella funzione usando le annotazioni di tipo di Python. In questo modo è possibile usare le funzionalità di IntelliSense e di completamento automatico fornite da molti editor di codice Python.
import azure.functions
def main(req: azure.functions.HttpRequest) -> str:
user = req.params.get('user')
return f'Hello, {user}!'
Usare le annotazioni Python incluse nel pacchetto azure.functions.* per associare input e output ai metodi dell'utente.
Funzioni di Azure si aspetta che una funzione sia un metodo senza stato nello script di Python che elabora l'input e genera l'output. Per impostazione predefinita, il runtime si aspetta che il metodo venga implementato come metodo globale nel file function_app.py.
I trigger e le associazioni possono essere dichiarati e usati in una funzione in un approccio basato su Decorator. Sono definiti nello stesso file function_app.py delle funzioni. Ad esempio, il file function_app.py seguente rappresenta un trigger di funzione da una richiesta HTTP.
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req):
user = req.params.get("user")
return f"Hello, {user}!"
È anche possibile dichiarare esplicitamente i tipi di attributi e il tipo restituito nella funzione usando le annotazioni di tipo di Python. In questo modo è possibile usare le funzionalità di IntelliSense e di completamento automatico fornite da molti editor di codice Python.
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req: func.HttpRequest) -> str:
user = req.params.get("user")
return f"Hello, {user}!"
Per informazioni sulle limitazioni note con il modello v2 e le relative soluzioni alternative, vedere Risolvere gli errori Python in Funzioni di Azure.
Punto di ingresso alternativo
È possibile cambiare il comportamento predefinito di una funzione specificando facoltativamente le proprietà scriptFile e entryPoint nel file function.json. Ad esempio, il file function.json seguente indica al runtime di usare il metodo customentry() nel file main.py come punto di ingresso per la funzione di Azure.
{
"scriptFile": "main.py",
"entryPoint": "customentry",
"bindings": [
...
]
}
Il punto di ingresso si trova solo nel file function_app.py. Tuttavia, è possibile fare riferimento a funzioni all'interno del progetto in function_app.py usando progetti o importando.
Struttura di cartelle
La struttura di cartelle per consigliata per un progetto di Funzioni per Python è simile all'esempio seguente:
<project_root>/
| - .venv/
| - .vscode/
| - my_first_function/
| | - __init__.py
| | - function.json
| | - example.py
| - my_second_function/
| | - __init__.py
| | - function.json
| - shared_code/
| | - __init__.py
| | - my_first_helper_function.py
| | - my_second_helper_function.py
| - tests/
| | - test_my_second_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
La cartella principale del progetto, <project_root>, può contenere i file seguenti:
- local.settings.json: viene usato per archiviare le impostazioni dell'app e le stringhe di connessione durante l'esecuzione in locale. Questo file non viene pubblicato in Azure. Per altre informazioni, vedere local.settings.file.
- requirements.txt: contiene l'elenco dei pacchetti Python installati dal sistema durante la pubblicazione in Azure.
- host.json: contiene opzioni di configurazione che influiscono su tutte le funzioni in un'istanza dell'app per le funzioni. Questo file viene pubblicato in Azure. Non tutte le opzioni sono supportate durante l'esecuzione in locale. Per altre informazioni, vedere host.json.
- .vscode/: (facoltativo) contiene la configurazione di Visual Studio Code archiviata. Per altre informazioni, vedere Impostazioni di Visual Studio Code.
- .venv/: (facoltativo) contiene un ambiente virtuale Python usato dallo sviluppo locale.
- Dockerfile: (facoltativo) viene usato per la pubblicazione del progetto in un contenitore personalizzato.
- tests/: (facoltativo) contiene i test case dell'app per le funzioni.
- .funcignore: (facoltativo) dichiara i file che non devono essere pubblicati in Azure. In genere, questo file contiene .vscode/ per ignorare l'impostazione dell'editor, .venv/ per ignorare l'ambiente virtuale Python, tests/ per ignorare i test case e local.settings.json per impedire la pubblicazione delle impostazioni dell'app locale.
Ogni funzione ha il proprio file di codice e il file di configurazione delle associazioni, function.json.
La struttura di cartelle per consigliata per un progetto di Funzioni per Python è simile all'esempio seguente:
<project_root>/
| - .venv/
| - .vscode/
| - function_app.py
| - additional_functions.py
| - tests/
| | - test_my_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
La cartella principale del progetto, <project_root>, può contenere i file seguenti:
- .venv/: (facoltativo) contiene un ambiente virtuale Python usato dallo sviluppo locale.
- .vscode/: (facoltativo) contiene la configurazione di Visual Studio Code archiviata. Per altre informazioni, vedere Impostazioni di Visual Studio Code.
- function_app.py: percorso predefinito per tutte le funzioni e i relativi trigger e associazioni correlati.
- additional_functions.py: (facoltativo) qualsiasi altro file Python che contiene funzioni (in genere per il raggruppamento logico) a cui viene fatto riferimento in function_app.py tramite progetti.
- tests/: (facoltativo) contiene i test case dell'app per le funzioni.
- .funcignore: (facoltativo) dichiara i file che non devono essere pubblicati in Azure. In genere, questo file contiene .vscode/ per ignorare l'impostazione dell'editor, .venv/ per ignorare l'ambiente virtuale Python, tests/ per ignorare i test case e local.settings.json per impedire la pubblicazione delle impostazioni dell'app locale.
- host.json: contiene opzioni di configurazione che influiscono su tutte le funzioni in un'istanza dell'app per le funzioni. Questo file viene pubblicato in Azure. Non tutte le opzioni sono supportate durante l'esecuzione in locale. Per altre informazioni, vedere host.json.
- local.settings.json: usato per archiviare le impostazioni dell'app e le stringhe di connessione quando viene eseguito in locale. Questo file non viene pubblicato in Azure. Per altre informazioni, vedere local.settings.file.
- requirements.txt: contiene l'elenco dei pacchetti Python installati dal sistema durante la pubblicazione in Azure.
- Dockerfile: (facoltativo) viene usato per la pubblicazione del progetto in un contenitore personalizzato.
Quando si distribuisce il progetto in un'app per le funzioni in Azure, l'intero contenuto della cartella principale del progetto, <project_root>, deve essere incluso nel pacchetto, ma non nella cartella stessa, il che significa che host.json deve trovarsi nella radice del pacchetto. È consigliabile gestire i test in una cartella insieme ad altre funzioni (in questo esempio test/). Per altre informazioni, vedere Testing unità.
Connettersi a un database
Funzioni di Azure si integra bene con Azure Cosmos DB per molti casi d'uso, tra cui IoT, e-commerce, giochi e così via.
Ad esempio, per origine eventi i due servizi sono integrati nelle architetture basate su eventi di alimentazione usando la funzionalità del feed di modifiche di Azure Cosmos DB. Il feed delle modifiche consente ai microservizi downstream di leggere in modo affidabile e incrementale gli inserimenti e aggiornamenti (ad esempio, gli eventi di ordine). Questa funzionalità può essere sfruttata per ottenere un archivio di eventi permanente come broker messaggi per eventi di modifica dello stato e gestire il flusso di lavoro per l'elaborazione degli ordini tra molti microservizi, che possono essere implementati come Funzioni di Azure senza server.
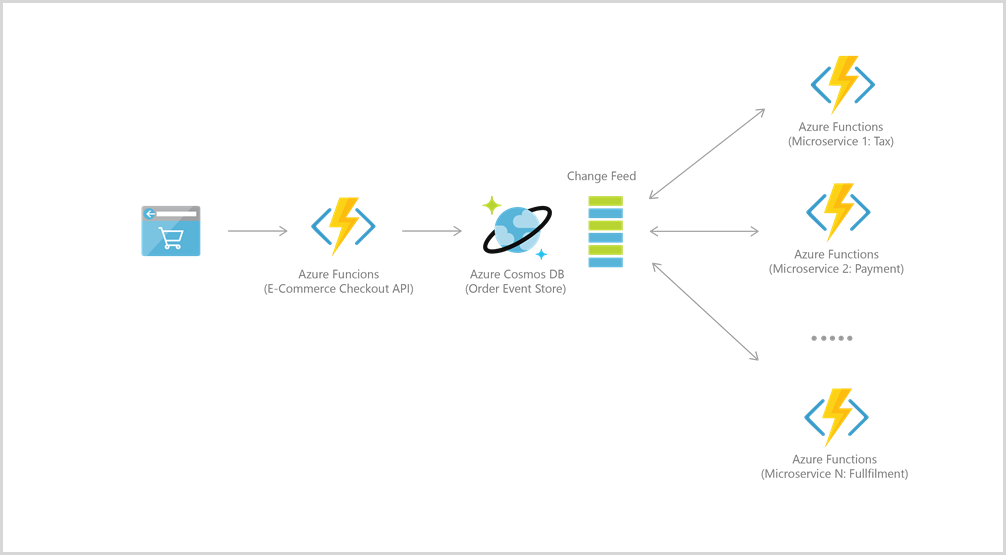
Per connettersi ad Azure Cosmos DB, prima di tutto creare un account, un database e un contenitore. È quindi possibile connettere il codice della funzione ad Azure Cosmos DB usando trigger e associazioni, come questo esempio.
Per implementare una logica di app più complessa, è anche possibile usare la libreria Python per Cosmos DB. Un'implementazione di I/O asincrona è simile alla seguente:
pip install azure-cosmos
pip install aiohttp
from azure.cosmos.aio import CosmosClient
from azure.cosmos import exceptions
from azure.cosmos.partition_key import PartitionKey
import asyncio
# Replace these values with your Cosmos DB connection information
endpoint = "https://azure-cosmos-nosql.documents.azure.com:443/"
key = "master_key"
database_id = "cosmicwerx"
container_id = "cosmicontainer"
partition_key = "/partition_key"
# Set the total throughput (RU/s) for the database and container
database_throughput = 1000
# Singleton CosmosClient instance
client = CosmosClient(endpoint, credential=key)
# Helper function to get or create database and container
async def get_or_create_container(client, database_id, container_id, partition_key):
database = await client.create_database_if_not_exists(id=database_id)
print(f'Database "{database_id}" created or retrieved successfully.')
container = await database.create_container_if_not_exists(id=container_id, partition_key=PartitionKey(path=partition_key))
print(f'Container with id "{container_id}" created')
return container
async def create_products():
container = await get_or_create_container(client, database_id, container_id, partition_key)
for i in range(10):
await container.upsert_item({
'id': f'item{i}',
'productName': 'Widget',
'productModel': f'Model {i}'
})
async def get_products():
items = []
container = await get_or_create_container(client, database_id, container_id, partition_key)
async for item in container.read_all_items():
items.append(item)
return items
async def query_products(product_name):
container = await get_or_create_container(client, database_id, container_id, partition_key)
query = f"SELECT * FROM c WHERE c.productName = '{product_name}'"
items = []
async for item in container.query_items(query=query, enable_cross_partition_query=True):
items.append(item)
return items
async def main():
await create_products()
all_products = await get_products()
print('All Products:', all_products)
queried_products = await query_products('Widget')
print('Queried Products:', queried_products)
if __name__ == "__main__":
asyncio.run(main())
Progetti
Il modello di programmazione Python v2 introduce il concetto di progetti. Un progetto è una nuova classe di cui viene creata un'istanza per registrare funzioni all'esterno dell'applicazione di funzione principale. Le funzioni registrate nelle istanze del progetto non vengono indicizzate direttamente dal runtime della funzione. Per ottenere l'indicizzazione di queste funzioni di progetto, l'app per le funzioni deve registrare le funzioni dalle istanze del progetto.
L'uso dei progetti offre i vantaggi seguenti:
- Consente di suddividere l'app per le funzioni in componenti modulari, al fine di definire funzioni in più file Python e di dividerle in componenti diversi per ogni file.
- Fornisce interfacce estendibili di app per le funzioni pubbliche per compilare e riutilizzare le proprie API.
L'esempio seguente illustra come usare i progetti:
Prima di tutto, in un file http_blueprint.py viene definita una funzione attivata tramite HTTP e aggiunta a un oggetto progetto.
import logging
import azure.functions as func
bp = func.Blueprint()
@bp.route(route="default_template")
def default_template(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(
f"Hello, {name}. This HTTP-triggered function "
f"executed successfully.")
else:
return func.HttpResponse(
"This HTTP-triggered function executed successfully. "
"Pass a name in the query string or in the request body for a"
" personalized response.",
status_code=200
)
Quindi, nel file function_app.py l'oggetto progetto viene importato e le relative funzioni vengono registrate nell'app per le funzioni.
import azure.functions as func
from http_blueprint import bp
app = func.FunctionApp()
app.register_functions(bp)
Annotazioni
Durable Functions supporta anche i progetti. Per creare progetti per le app Durable Functions, registrare trigger di orchestrazione, attività ed entità e associazioni client usando la classe azure-functions-durableBlueprint, come illustrato qui. Il progetto risultante può quindi essere registrato normalmente. Per un esempio, vedere il campione.
Importare il comportamento
È possibile importare moduli nel codice della funzione usando riferimenti assoluti e relativi. In base alla struttura di cartelle descritta in precedenza, le importazioni seguenti funzionano dall'interno del file di funzione <project_root>\my_first_function\__init__.py:
from shared_code import my_first_helper_function #(absolute)
import shared_code.my_second_helper_function #(absolute)
from . import example #(relative)
Annotazioni
Quando si usa la sintassi di importazione assoluta, la cartella shared_code/ deve contenere un file __init__.py per contrassegnarlo come pacchetto Python.
L'importazione dell'__app__ seguente e degli elementi al di là del livello generale relativo è deprecata perché non è supportata dal correttore dei tipi statici e dai framework di test Python:
from __app__.shared_code import my_first_helper_function #(deprecated __app__ import)
from ..shared_code import my_first_helper_function #(deprecated beyond top-level relative import)
Trigger e input
In Funzioni di Azure, gli input vengono suddivisi in due categorie, ovvero l'input del trigger e un altro input. Anche se sono diversi nel file function.json, l'utilizzo è identico nel codice Python. Le stringhe di connessione o i segreti per le origini di trigger e input vengono mappati ai valori del file local.settings.json durante l'esecuzione in locale e alle impostazioni dell'applicazione durante l'esecuzione in Azure.
Ad esempio, il codice seguente dimostra la differenza tra i due input:
// function.json
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous",
"route": "items/{id}"
},
{
"name": "obj",
"direction": "in",
"type": "blob",
"path": "samples/{id}",
"connection": "STORAGE_CONNECTION_STRING"
}
]
}
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",
"AzureWebJobsStorage": "<azure-storage-connection-string>"
}
}
# __init__.py
import azure.functions as func
import logging
def main(req: func.HttpRequest, obj: func.InputStream):
logging.info(f'Python HTTP-triggered function processed: {obj.read()}')
Quando viene richiamata questa funzione, la richiesta HTTP viene passata alla funzione come req. Verrà recuperata una voce dall'account Archiviazione BLOB di Azure in base all'ID nell'URL di route e verrà resa disponibile come obj nel corpo della funzione. In questo caso, l'account di archiviazione specificato è la stringa di connessione presente nell'impostazione dell'app <*_CONNECTION_STRING>. Per altre informazioni, vedere Connessioni.
In Funzioni di Azure, gli input vengono suddivisi in due categorie, ovvero l'input del trigger e un altro input. Anche se sono definiti usando elementi Decorator diversi, l'utilizzo è simile nel codice Python. Le stringhe di connessione o i segreti per le origini di trigger e input vengono mappati ai valori del file local.settings.json durante l'esecuzione in locale e alle impostazioni dell'applicazione durante l'esecuzione in Azure.
Ad esempio, il codice seguente illustra come definire un'associazione di input di archiviazione BLOB:
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",
"AzureWebJobsStorage": "<azure-storage-connection-string>"
}
}
# function_app.py
import azure.functions as func
import logging
app = func.FunctionApp()
@app.route(route="req")
@app.blob_input(arg_name="obj", path="samples/{id}",
connection="STORAGE_CONNECTION_STRING")
def main(req: func.HttpRequest, obj: func.InputStream):
logging.info(f'Python HTTP-triggered function processed: {obj.read()}')
Quando viene richiamata questa funzione, la richiesta HTTP viene passata alla funzione come req. Verrà recuperata una voce dall'account Archiviazione BLOB di Azure in base all'ID nell'URL di route e verrà resa disponibile come obj nel corpo della funzione. In questo caso, l'account di archiviazione specificato è la stringa di connessione presente nell'impostazione dell'app <*_CONNECTION_STRING>. Per altre informazioni, vedere Connessioni.
Per le operazioni di data binding a elevato utilizzo di dati, è consigliabile usare un account di archiviazione separato. Per altre informazioni, vedere Linee guida dell'account di archiviazione.
Associazioni dei tipi di SDK
Per selezionare trigger e associazioni, è possibile usare i tipi di dati implementati dagli SDK e dai framework di Azure sottostanti. Questi binding di tipi SDK consentono di interagire con i dati di associazione come se si usasse l'SDK del servizio sottostante.
Importante
L'uso delle associazioni di tipi SDK richiede il modello di programmazione Python v2.
Importante
Il supporto delle associazioni dei tipi di SDK per Python è disponibile solo nel modello di programmazione Python v2.
Prerequisiti
- Runtime di Funzioni di Azure versione 4.34 o successiva.
- Python versione 3.10 o successiva supportata.
Tipi supportati
| Extension | Tipi | Livello di supporto | Esempi |
|---|---|---|---|
| Archiviazione BLOB di Azure | BlobClientContainerClientStorageStreamDownloader |
Trigger: GA Input: GA |
Avvio rapidoBlobClientContainerClientStorageStreamDownloader |
| Azure Cosmos DB | CosmosClientDatabaseProxyContainerProxy |
Input: anteprima |
Avvio rapidoContainerProxyCosmosClientDatabaseProxy |
| Hub eventi di Azure | EventData |
Attivatore: anteprima |
Avvio rapidoEventData |
| Bus di servizio di Azure | ServiceBusReceivedMessage |
Trigger: anteprima |
Avvio rapidoServiceBusReceivedMessage |
Considerazioni per i tipi di SDK:
- Per gli scenari di output in cui è possibile usare un tipo di SDK, creare e usare direttamente i client SDK anziché usare un'associazione di output.
- Il trigger di Azure Cosmos DB usa il feed di modifiche di Azure Cosmos DB ed espone gli elementi del feed di modifiche come tipi serializzabili JSON. Di conseguenza, i tipi SDK non sono supportati per questo trigger.
Flussi HTTP
I flussi HTTP sono una funzionalità che consente di accettare e restituire dati dagli endpoint HTTP usando le FastAPI di richiesta e le API di risposta abilitate nelle funzioni. Queste API consentono all'host di elaborare dati di grandi dimensioni nei messaggi HTTP come blocchi anziché leggere un intero messaggio in memoria.
Questa funzionalità consente di gestire flussi di dati di grandi dimensioni e integrazioni OpenAI, di distribuire contenuto dinamico e di supportare altri scenari HTTP principali che richiedono interazioni in tempo reale su HTTP. È anche possibile usare i tipi di risposta FastAPI con flussi HTTP. Senza flussi HTTP, le dimensioni delle richieste e delle risposte HTTP sono limitate dalle restrizioni di memoria rilevabili durante l'elaborazione di interi payload di messaggi in memoria.
Per altre informazioni, tra cui come abilitare i flussi HTTP nel progetto, vedere Flussi HTTP.
Importante
Il supporto per i flussi HTTP richiede il modello di programmazione Python v2.
Importante
Il supporto dei flussi HTTP per Python è disponibile a livello generale e richiede l'uso del modello di programmazione Python v2.
Output
Gli output possono essere espressi sia nel valore restituito che nei parametri di output. Se è presente un solo output, è consigliabile usare il valore restituito. Per più output, è necessario usare i parametri di output.
Per usare il valore restituito di una funzione come valore di un'associazione di output, la proprietà name dell'associazione deve essere impostata su $return nel file function.json.
Per generare più output, usare il metodo set() fornito dall'interfaccia azure.functions.Out per assegnare un valore all'associazione. Ad esempio, la funzione seguente può eseguire il push di un messaggio in una coda e anche restituire una risposta HTTP.
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous"
},
{
"name": "msg",
"direction": "out",
"type": "queue",
"queueName": "outqueue",
"connection": "STORAGE_CONNECTION_STRING"
},
{
"name": "$return",
"direction": "out",
"type": "http"
}
]
}
import azure.functions as func
def main(req: func.HttpRequest,
msg: func.Out[func.QueueMessage]) -> str:
message = req.params.get('body')
msg.set(message)
return message
Gli output possono essere espressi sia nel valore restituito che nei parametri di output. Se è presente un solo output, è consigliabile usare il valore restituito. Per più output, è necessario usare invece i parametri di output.
Per generare più output, usare il metodo set() fornito dall'interfaccia azure.functions.Out per assegnare un valore all'associazione. Ad esempio, la funzione seguente può eseguire il push di un messaggio in una coda e anche restituire una risposta HTTP.
# function_app.py
import azure.functions as func
app = func.FunctionApp()
@app.write_blob(arg_name="msg", path="output-container/{name}",
connection="CONNECTION_STRING")
def test_function(req: func.HttpRequest,
msg: func.Out[str]) -> str:
message = req.params.get('body')
msg.set(message)
return message
Registrazione
L'accesso al logger di runtime di Funzioni di Azure è disponibile tramite un gestore radice logging nell'app per le funzioni. Il logger è associato ad Application Insights e consente di contrassegnare avvisi ed errori rilevati durante l'esecuzione della funzione.
L'esempio seguente registra un messaggio informativo quando la funzione viene richiamata tramite un trigger HTTP.
import logging
def main(req):
logging.info('Python HTTP trigger function processed a request.')
Sono disponibili altri metodi di registrazione che consentono di scrivere nella console a livelli di traccia diversi:
| Metodo | Descrizione |
|---|---|
critical(_message_) |
Scrive un messaggio con livello critico nel logger radice. |
error(_message_) |
Scrive un messaggio con livello errore nel logger radice. |
warning(_message_) |
Scrive un messaggio con livello avviso nel logger radice. |
info(_message_) |
Scrive un messaggio con livello informativo nel logger radice. |
debug(_message_) |
Scrive un messaggio con livello debug nel logger radice. |
Per altre informazioni sulla registrazione, vedere Monitorare Funzioni di Azure.
Registrazione da thread creati
Per visualizzare i log provenienti dai thread creati, includere l'argomento context nella firma della funzione. Questo argomento contiene un attributo thread_local_storage che archivia un invocation_id locale. Questa opzione può essere impostata su invocation_id corrente della funzione per assicurarsi che il contesto venga modificato.
import azure.functions as func
import logging
import threading
def main(req, context):
logging.info('Python HTTP trigger function processed a request.')
t = threading.Thread(target=log_function, args=(context,))
t.start()
def log_function(context):
context.thread_local_storage.invocation_id = context.invocation_id
logging.info('Logging from thread.')
Log della telemetria personalizzata
Per impostazione predefinita, il runtime di Funzioni raccoglie i log e altri dati di telemetria generati dalle funzioni. Questi dati di telemetria finiscono come tracce in Application Insights. I dati di telemetria delle richieste e delle dipendenze per determinati servizi di Azure vengono raccolti anche per impostazione predefinita da trigger e associazioni.
Per raccogliere dati di telemetria delle dipendenze e richieste personalizzate all'esterno delle associazioni, è possibile usare le estensioni OpenCensus Python. Questa estensione invia dati di telemetria personalizzati all'istanza di Application Insights. È possibile trovare un elenco delle estensioni supportate nel repository OpenCensus.
Annotazioni
Per usare le estensioni OpenCensus Python, è necessario abilitare le estensioni del ruolo di lavoro Python nell'app per le funzioni impostando PYTHON_ENABLE_WORKER_EXTENSIONS su 1. È anche necessario passare all'uso della stringa di connessione di Application Insights aggiungendo l'impostazione APPLICATIONINSIGHTS_CONNECTION_STRING alle impostazioni dell'applicazione, se non è già presente.
// requirements.txt
...
opencensus-extension-azure-functions
opencensus-ext-requests
import json
import logging
import requests
from opencensus.extension.azure.functions import OpenCensusExtension
from opencensus.trace import config_integration
config_integration.trace_integrations(['requests'])
OpenCensusExtension.configure()
def main(req, context):
logging.info('Executing HttpTrigger with OpenCensus extension')
# You must use context.tracer to create spans
with context.tracer.span("parent"):
response = requests.get(url='http://example.com')
return json.dumps({
'method': req.method,
'response': response.status_code,
'ctx_func_name': context.function_name,
'ctx_func_dir': context.function_directory,
'ctx_invocation_id': context.invocation_id,
'ctx_trace_context_Traceparent': context.trace_context.Traceparent,
'ctx_trace_context_Tracestate': context.trace_context.Tracestate,
'ctx_retry_context_RetryCount': context.retry_context.retry_count,
'ctx_retry_context_MaxRetryCount': context.retry_context.max_retry_count,
})
Trigger HTTP
Il trigger HTTP è definito nel file function.json. Il valore name del binding deve corrispondere al parametro denominato nella funzione.
Negli esempi precedenti viene usato il nome di binding req. Questo parametro è un oggetto HttpRequest e viene restituito un oggetto HttpResponse.
Dall'oggetto HttpRequest è possibile ottenere intestazioni di richieste, parametri di query, parametri di route e il corpo del messaggio.
L'esempio seguente fa riferimento al modello di trigger HTTP per Python.
def main(req: func.HttpRequest) -> func.HttpResponse:
headers = {"my-http-header": "some-value"}
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello {name}!", headers=headers)
else:
return func.HttpResponse(
"Please pass a name on the query string or in the request body",
headers=headers, status_code=400
)
In questa funzione il valore del parametro di query name si ottiene dal parametro params dell'oggetto HttpRequest. Il corpo del messaggio con codifica JSON viene letto usando il metodo get_json.
Allo stesso modo, è possibile impostare status_code e headers per il messaggio di risposta nell'oggetto HttpResponse restituito.
Il trigger HTTP viene definito come metodo che accetta un parametro di associazione denominato, che è un oggetto HttpRequest e restituisce un oggetto HttpResponse. Si applica il decorator function_name al metodo per definire il nome della funzione, mentre l'endpoint HTTP viene impostato applicando il decorator route.
Questo esempio proviene dal modello di trigger HTTP per il modello di programmazione Python v2, in cui il nome del parametro di associazione è req. Si tratta del codice di esempio fornito quando si crea una funzione tramite Azure Functions Core Tools o Visual Studio Code.
@app.function_name(name="HttpTrigger1")
@app.route(route="hello")
def test_function(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello, {name}. This HTTP-triggered function executed successfully.")
else:
return func.HttpResponse(
"This HTTP-triggered function executed successfully. Pass a name in the query string or in the request body for a personalized response.",
status_code=200
)
Dall'oggetto HttpRequest è possibile ottenere intestazioni di richieste, parametri di query, parametri di route e il corpo del messaggio. In questa funzione il valore del parametro di query name si ottiene dal parametro params dell'oggetto HttpRequest. Il corpo del messaggio con codifica JSON viene letto usando il metodo get_json.
Allo stesso modo, è possibile impostare status_code e headers per il messaggio di risposta nell'oggetto HttpResponse restituito.
Per passare un nome in questo esempio, incollare l'URL fornito quando si esegue la funzione e quindi aggiungerlo con "?name={name}".
Framework Web
È possibile usare framework compatibili con Web Server Gateway Interface (WSGI) e ASGI (Asynchronous Server Gateway Interface), ad esempio Flask e FastAPI, con le funzioni Python attivate da HTTP. Questa sezione illustra come modificare le funzioni per supportare questi framework.
Prima di tutto, il file function.json deve essere aggiornato per includere un route nel trigger HTTP, come illustrato nell'esempio seguente:
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "anonymous",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
],
"route": "{*route}"
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Il file host.json deve essere aggiornato anche per includere un routePrefix HTTP, come illustrato nell'esempio seguente:
{
"version": "2.0",
"logging":
{
"applicationInsights":
{
"samplingSettings":
{
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"extensionBundle":
{
"id": "Microsoft.Azure.Functions.ExtensionBundle",
"version": "[4.*, 5.0.0)"
},
"extensions":
{
"http":
{
"routePrefix": ""
}
}
}
Aggiornare il file di codice Python init.py, a seconda dell'interfaccia usata dal framework. L'esempio seguente illustra un approccio del gestore ASGI o un approccio wrapper WSGI per Flask:
È possibile usare framework compatibili con ASGI (Asynchronous Server Gateway Interface) e WSGI (Web Server Gateway Interface), ad esempio Flask e FastAPI, con le funzioni Python attivate da HTTP. È prima necessario aggiornare il file host.json per includere un routePrefix HTTP, come illustrato nell'esempio seguente:
{
"version": "2.0",
"logging":
{
"applicationInsights":
{
"samplingSettings":
{
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"extensionBundle":
{
"id": "Microsoft.Azure.Functions.ExtensionBundle",
"version": "[4.*, 5.0.0)"
},
"extensions":
{
"http":
{
"routePrefix": ""
}
}
}
Il codice del framework è simile all'esempio seguente:
AsgiFunctionApp è la classe di app per le funzioni generale per la costruzione di funzioni HTTP ASGI.
# function_app.py
import azure.functions as func
from fastapi import FastAPI, Request, Response
fast_app = FastAPI()
@fast_app.get("/return_http_no_body")
async def return_http_no_body():
return Response(content="", media_type="text/plain")
app = func.AsgiFunctionApp(app=fast_app,
http_auth_level=func.AuthLevel.ANONYMOUS)
Ridimensionamento e prestazioni
Per le procedure consigliate per la scalabilità e le prestazioni per le app per le funzioni Python, vedere l'articolo Scalabilità e prestazioni di Python.
Context
Per ottenere il contesto di chiamata di una funzione quando è in esecuzione, includere l'argomento context nella relativa firma.
Ad esempio:
import azure.functions
def main(req: azure.functions.HttpRequest,
context: azure.functions.Context) -> str:
return f'{context.invocation_id}'
La classe Context prevede gli attributi di stringa seguenti:
| Attributo | Descrizione |
|---|---|
function_directory |
Directory in cui la funzione è in esecuzione. |
function_name |
Nome della funzione. |
invocation_id |
L'ID della chiamata di funzione corrente. |
thread_local_storage |
Archiviazione thread-local della funzione. Contiene un invocation_id locale per la registrazione da thread creati. |
trace_context |
Contesto per la traccia distribuita. Per altre informazioni, vedere Trace Context. |
retry_context |
Contesto per i tentativi alla funzione. Per altre informazioni, vedere retry-policies. |
Variabili globali
Non è garantito che lo stato dell'app verrà preservato per le esecuzioni future. Tuttavia, il runtime di Funzioni di Azure spesso riutilizza lo stesso processo per più esecuzioni della stessa app. Per memorizzare nella cache i risultati di un calcolo oneroso, dichiararli come variabile globale.
CACHED_DATA = None
def main(req):
global CACHED_DATA
if CACHED_DATA is None:
CACHED_DATA = load_json()
# ... use CACHED_DATA in code
Variabili di ambiente
In Funzioni di Azure le impostazioni dell'applicazione, come le stringhe di connessione al servizio, vengono esposte come variabili di ambiente durante l'esecuzione. Esistono due modi principali per accedere a queste impostazioni nel codice.
| Metodo | Descrizione |
|---|---|
os.environ["myAppSetting"] |
Prova a ottenere l'impostazione dell'applicazione in base al nome della chiave e genera un errore in caso di esito negativo. |
os.getenv("myAppSetting") |
Prova a ottenere l'impostazione dell'applicazione in base al nome della chiave e restituisce None in caso di esito negativo. |
Entrambi questi modi richiedono di dichiarare import os.
L'esempio seguente usa os.environ["myAppSetting"] per ottenere l'impostazione dell'applicazione, con la chiave denominata myAppSetting:
import logging
import os
import azure.functions as func
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
Per lo sviluppo locale, le impostazioni dell'applicazione vengono mantenute nel file local.settings.json.
In Funzioni di Azure le impostazioni dell'applicazione, come le stringhe di connessione al servizio, vengono esposte come variabili di ambiente durante l'esecuzione. Esistono due modi principali per accedere a queste impostazioni nel codice.
| Metodo | Descrizione |
|---|---|
os.environ["myAppSetting"] |
Prova a ottenere l'impostazione dell'applicazione in base al nome della chiave e genera un errore in caso di esito negativo. |
os.getenv("myAppSetting") |
Prova a ottenere l'impostazione dell'applicazione in base al nome della chiave e restituisce None in caso di esito negativo. |
Entrambi questi modi richiedono di dichiarare import os.
L'esempio seguente usa os.environ["myAppSetting"] per ottenere l'impostazione dell'applicazione, con la chiave denominata myAppSetting:
import logging
import os
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
Per lo sviluppo locale, le impostazioni dell'applicazione vengono mantenute nel file local.settings.json.
Versione Python
Funzioni di Azure supporta le versioni di Python seguenti:
| Versioni 1 di Python | Livello di supporto |
|---|---|
| 3.13 | Disponibile a livello generale (GA)2 |
| 3.12 | GA |
| 3.11 | GA |
| 3.10 | GA |
- Distribuzioni ufficiali di Python
- Python 3.13 non è supportato quando l'app viene eseguita nel piano a consumo.
Importante
Il supporto di Python 3.13 introduce alcuni miglioramenti e alcune modifiche di rilievo. Per altre informazioni, vedere Python 3.13+ in Funzioni di Azure.
Per richiedere una versione specifica di Python quando si crea l'app per le funzioni in Azure, usare l'opzione --runtime-version del comando az functionapp create. La versione del runtime di Funzioni è impostata dall'opzione --functions-version. La versione di Python viene impostata quando viene creata l'app per le funzioni e non può essere modificata per le app in esecuzione in un piano a consumo.
Per l'esecuzione in locale, il runtime usa la versione di Python disponibile.
Modifica della versione di Python
Per impostare un'app per le funzioni Python su una versione specifica del linguaggio, è necessario specificare la lingua e la versione del linguaggio nel campo LinuxFxVersion della configurazione del sito. Ad esempio, per modificare l'app Python per usare Python 3.12, impostare linuxFxVersion su python|3.12.
Per informazioni su come visualizzare e modificare l'impostazione del sito linuxFxVersion, vedere Come impostare come destinazione le versioni di runtime di Funzioni di Azure.
Per altre informazioni generali, vedere i Criteri di supporto del runtime di Funzioni di Azure e i Linguaggi supportati in Funzioni di Azure.
Gestione dei pacchetti
Quando si sviluppa in locale usando Core Tools o Visual Studio Code, aggiungere i nomi e le versioni dei pacchetti necessari al file requirements.txt e quindi installarli usando pip.
Ad esempio, è possibile usare il file requirements.txt seguente e il comando pip per installare il pacchetto requests da PyPI.
requests==2.19.1
pip install -r requirements.txt
Quando si eseguono le funzioni in un piano di servizio app, le dipendenze definite in requirements.txt hanno la precedenza sui moduli Python predefiniti, ad esempio logging. Questa precedenza può causare conflitti quando i moduli predefiniti hanno gli stessi nomi delle directory nel codice. Quando si esegue in un piano a consumo o un piano Elastic Premium, i conflitti sono meno probabili perché le dipendenze non sono classificate in ordine di priorità per impostazione predefinita.
Per evitare problemi di esecuzione in un piano di servizio app, non assegnare alle directory lo stesso nome dei moduli nativi Python e non includere librerie native Python nel file requirements.txt del progetto.
Pubblicazione in Azure
Quando si è pronti per la pubblicazione, assicurarsi che tutte le dipendenze disponibili pubblicamente siano elencate nel file requirements.txt. È possibile individuare questo file nella radice della directory del progetto.
È possibile trovare i file di progetto e le cartelle esclusi dalla pubblicazione, inclusa la cartella dell'ambiente virtuale, nella directory radice del progetto.
Sono supportate tre azioni di compilazione per la pubblicazione del progetto Python in Azure: compilazione remota, compilazione locale e compilazione con dipendenze personalizzate.
È anche possibile usare Azure Pipelines per compilare le dipendenze e pubblicare usando il recapito continuo (CD). Per altre informazioni, vedere Recapito continuo con Azure Pipelines.
Compilazione remota
Quando si usa la compilazione remota, le dipendenze ripristinate nel server e le dipendenze native corrispondono all'ambiente di produzione. In questo modo si genera un pacchetto di distribuzione più piccolo da caricare. Usare la compilazione remota quando si sviluppano app Python in Windows. Se il progetto ha dipendenze personalizzate, è possibile usare la compilazione remota con URL di indice aggiuntivo.
Le dipendenze si ottengono in remoto in base al contenuto del file requirements.txt.
La compilazione remota è il metodo di compilazione consigliato. Per impostazione predefinita, Core Tools richiede una compilazione remota quando si usa il comando func azure functionapp publish seguente per pubblicare il progetto Python in Azure.
func azure functionapp publish <APP_NAME>
Ricordare di sostituire <APP_NAME> con il nome dell'app per le funzioni in Azure.
Anche l'estensione Funzioni di Azure per Visual Studio Code richiede una compilazione remota per impostazione predefinita.
Compilazione locale
Le dipendenze si ottengono in locale in base al contenuto del file requirements.txt. È possibile evitare l'esecuzione di una compilazione remota usando il comando func azure functionapp publish per pubblicare con una compilazione locale:
func azure functionapp publish <APP_NAME> --build local
Ricordare di sostituire <APP_NAME> con il nome dell'app per le funzioni in Azure.
Usando l'opzione --build local, le dipendenze del progetto vengono lette dal file requirements.txt e i pacchetti dipendenti vengono scaricati e installati localmente. I file e le dipendenze del progetto vengono distribuiti dal computer locale in Azure. Questo comporta il caricamento di un pacchetto di distribuzione di dimensioni maggiori in Azure. Se per qualche motivo non è possibile ottenere il file requirements.txt usando Core Tools, è necessario usare l'opzione delle dipendenze personalizzate per la pubblicazione.
Non è consigliabile usare build locali quando si sviluppa in locale in Windows.
Dipendenze personalizzate
Quando il progetto presenta dipendenze che non vengono trovate nell'indice dei pacchetti Python, esistono due modi per compilare il progetto. Il primo modo, il metodo di compilazione, dipende dalla modalità di compilazione del progetto.
Compilazione remota con URL di indice aggiuntivo
Quando i pacchetti sono disponibili da un indice di pacchetto personalizzato accessibile, usare una compilazione remota. Prima di pubblicare, assicurarsi di creare un'impostazione dell'app denominata PIP_EXTRA_INDEX_URL. Il valore di questa impostazione è l'URL dell'indice del pacchetto personalizzato. L'uso di questa impostazione indica alla compilazione remota di eseguire pip install usando l'opzione --extra-index-url. Per altre informazioni, vedere la documentazione pip install Python.
È anche possibile usare le credenziali di autenticazione di base con gli URL di indice del pacchetto aggiuntivi. Per altre informazioni, vedere Credenziali di autenticazione di base nella documentazione di Python.
Installare i pacchetti locali
Se il progetto usa pacchetti non disponibili pubblicamente per gli strumenti di Azure, è possibile renderli disponibili nell'app inserendoli nella directory __app__/.python_packages. Prima della pubblicazione, eseguire il comando seguente per installare le dipendenze in locale:
pip install --target="<PROJECT_DIR>/.python_packages/lib/site-packages" -r requirements.txt
Quando si usano dipendenze personalizzate, è consigliabile usare l'opzione di pubblicazione --no-build, perché le dipendenze sono già state installate nella cartella del progetto.
func azure functionapp publish <APP_NAME> --no-build
Ricordare di sostituire <APP_NAME> con il nome dell'app per le funzioni in Azure.
Testing unità
Test unitari con pytest
Le funzioni scritte in Python possono essere testate come qualsiasi altro codice Python usando framework di test standard. Per la maggior parte dei binding, è possibile creare un oggetto di input fittizio creando un'istanza di una classe appropriata dal pacchetto azure.functions. Poiché il pacchetto azure.functions non è immediatamente disponibile, assicurarsi di installarlo tramite il file requirements.txt come descritto nella sezione gestione dei pacchetti precedente.
Con my_second_function come esempio, di seguito è riportato un test fittizio di una funzione attivata tramite HTTP:
Creare prima di tutto un file <project_root>/my_second_function/function.json e quindi definire questa funzione come trigger HTTP.
{
"scriptFile": "__init__.py",
"entryPoint": "main",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Successivamente, è possibile implementare my_second_function e shared_code.my_second_helper_function.
# <project_root>/my_second_function/__init__.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
# Define an HTTP trigger that accepts the ?value=<int> query parameter
# Double the value and return the result in HttpResponse
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
È possibile iniziare a scrivere test case per il trigger HTTP.
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from my_second_function import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
resp = main(req)
# Check the output.
self.assertEqual(resp.get_body(), b'21 * 2 = 42',)
All'interno della cartella dell'ambiente virtuale Python .venv installare il framework di test Python preferito, ad esempio pip install pytest. Eseguire quindi pytest tests per controllare il risultato del test.
Creare prima di tutto il file <project_root>/function_app.py e implementare la funzione my_second_function come trigger HTTP e shared_code.my_second_helper_function.
# <project_root>/function_app.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
app = func.FunctionApp()
# Define the HTTP trigger that accepts the ?value=<int> query parameter
# Double the value and return the result in HttpResponse
@app.function_name(name="my_second_function")
@app.route(route="hello")
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
È possibile iniziare a scrivere test case per il trigger HTTP.
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from function_app import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
func_call = main.build().get_user_function()
resp = func_call(req)
# Check the output.
self.assertEqual(
resp.get_body(),
b'21 * 2 = 42',
)
All'interno della cartella dell'ambiente virtuale Python .venv installare il framework di test Python preferito, ad esempio pip install pytest. Eseguire quindi pytest tests per controllare il risultato del test.
Esecuzione di test unitari invocando direttamente la funzione
Con azure-functions >= 1.21.0, le funzioni possono anche essere chiamate direttamente usando l'interprete Python. Questo esempio illustra come eseguire unit test di un trigger HTTP usando il modello di programmazione v2:
# <project_root>/function_app.py
import azure.functions as func
import logging
app = func.FunctionApp(http_auth_level=func.AuthLevel.ANONYMOUS)
@app.route(route="http_trigger")
def http_trigger(req: func.HttpRequest) -> func.HttpResponse:
return "Hello, World!"
print(http_trigger(None))
Con questo approccio, non sono necessari pacchetti e configurazioni aggiuntivi. La funzione può essere testata chiamando python function_app.pye restituisce l'output Hello, World! nel terminale.
Annotazioni
Durable Functions richiede una sintassi speciale per gli unit test. Per altre informazioni, vedere Unit Testing Durable Functions in Python
File temporanei
Il metodo tempfile.gettempdir() restituisce una cartella temporanea, che in Linux è /tmp. L'applicazione può usare questa directory per archiviare i file temporanei generati e usati dalle funzioni durante l'esecuzione.
Importante
Non è garantito che i file scritti nella directory temporanea vengano mantenuti tra le chiamate. Durante lo scale-out i file temporanei non vengono condivisi tra istanze.
L'esempio seguente crea un file temporaneo denominato nella directory temporanea (/tmp):
import logging
import azure.functions as func
import tempfile
from os import listdir
#---
tempFilePath = tempfile.gettempdir()
fp = tempfile.NamedTemporaryFile()
fp.write(b'Hello world!')
filesDirListInTemp = listdir(tempFilePath)
È consigliabile mantenere i test in una cartella separata da quella del progetto. In questo modo si evita di distribuire il codice di test con l'app.
Librerie preinstallate
Alcune librerie sono disponibili con il runtime delle funzioni Python.
Libreria standard Python
La libreria standard Python contiene un elenco di moduli Python predefiniti forniti con ogni distribuzione Python. La maggior parte di queste librerie consente di accedere alle funzionalità di sistema, ad esempio input/output dei file (I/O). Nei sistemi Windows queste librerie vengono installate con Python. Nei sistemi basati su Unix, vengono forniti dalle raccolte di pacchetti.
Per visualizzare la libreria per la versione di Python, passare a:
- Libreria standard Python 3.10
- Libreria standard Python 3.11
- Libreria standard Python 3.12
- Libreria standard Python 3.13
Dipendenze del ruolo di lavoro Python di Funzioni di Azure
Il ruolo di lavoro Python per Funzioni di Azure richiede un set specifico di librerie. È anche possibile usare queste librerie nelle funzioni, ma non fanno parte dello standard Python. Se le funzioni si basano su una di queste librerie, potrebbero non essere disponibili per il codice quando è in esecuzione all'esterno di Funzioni di Azure.
Annotazioni
Se il file requirements.txt dell'app per le funzioni contiene una voce azure-functions-worker, rimuoverla. Il ruolo di lavoro delle funzioni viene gestito automaticamente dalla piattaforma Funzioni di Azure e viene aggiornato regolarmente con nuove funzionalità e correzioni di bug. L'installazione manuale di una versione precedente del ruolo di lavoro nel file requirements.txt potrebbe causare problemi imprevisti.
Annotazioni
Se il pacchetto contiene alcune librerie che potrebbero essere in conflitto con le dipendenze del ruolo di lavoro (ad esempio protobuf, TensorFlow o grpcio), configurare PYTHON_ISOLATE_WORKER_DEPENDENCIES su 1 nelle impostazioni dell'app per impedire all'applicazione di fare riferimento alle dipendenze del ruolo di lavoro.
Libreria Python di Funzioni di Azure
Ogni aggiornamento del ruolo di lavoro Python include una nuova versione della libreria Python di Funzioni di Azure (azure.functions). Questo approccio semplifica l'aggiornamento continuo delle app per le funzioni Python, perché ogni aggiornamento è compatibile con le versioni precedenti. Per un elenco delle versioni di questa libreria, vedere azure-functions PyPi.
La versione della libreria di runtime è impostata da Azure e non può essere sostituita da requirements.txt. La voce azure-functions in requirements.txt è destinata solo al linting e alla consapevolezza dei clienti.
Usare il codice seguente per tenere traccia della versione effettiva della libreria di funzioni Python nel runtime:
getattr(azure.functions, '__version__', '< 1.2.1')
Librerie di sistema di runtime
Per un elenco delle librerie di sistema preinstallate nelle immagini Docker del ruolo di lavoro Python, vedere quanto segue:
| Runtime di Funzioni | Versione Debian | Versioni di Python |
|---|---|---|
| Versione 3.x | Buster | Python 3.7 Python 3.8 Python 3.9 |
Estensioni del ruolo di lavoro Python
Il processo di lavoro Python eseguito in Funzioni di Azure consente di integrare librerie di terze parti nell'app per le funzioni. Queste librerie di estensioni fungono da middleware in grado di inserire operazioni specifiche durante il ciclo di vita dell'esecuzione della funzione.
Le estensioni vengono importate nel codice della funzione in modo analogo a un modulo di libreria Python standard. Le estensioni vengono eseguite in base agli ambiti seguenti:
| Scope | Descrizione |
|---|---|
| Livello applicazione | Quando viene importata in un qualsiasi trigger di funzione, l'estensione si applica a ogni esecuzione di funzione nell'app. |
| Livello di funzione | L'esecuzione è limitata solo al trigger di funzione specifico in cui viene importata. |
Esaminare le informazioni per ogni estensione per altre informazioni sull'ambito in cui viene eseguita l'estensione.
Le estensioni implementano un'interfaccia di estensione del ruolo di lavoro Python. Questa azione consente al processo di lavoro Python di chiamare il codice di estensione durante il ciclo di vita di esecuzione della funzione. Per altre informazioni, vedere Creare estensioni.
Uso delle estensioni
È possibile usare una libreria di estensioni del ruolo di lavoro Python nelle funzioni Python seguendo questa procedura:
- Aggiungere il pacchetto di estensione nel file requirements.txt per il progetto.
- Installare la libreria nell'app.
- Aggiungere le impostazioni dell'applicazione seguenti:
- Localmente: immettere
"PYTHON_ENABLE_WORKER_EXTENSIONS": "1"nella sezioneValuesdel file local.settings.json. - Azure: immettere
PYTHON_ENABLE_WORKER_EXTENSIONS=1nelle impostazioni dell'app.
- Localmente: immettere
- Importare il modulo di estensione nel trigger di funzione.
- Configurare l'istanza dell'estensione, se necessario. I requisiti di configurazione devono essere indicati nella documentazione dell'estensione.
Importante
Le librerie delle estensioni del ruolo di lavoro Python di terze parti non sono supportate o garantite da Microsoft. È necessario assicurarsi che tutte le estensioni usate nell'app per le funzioni siano attendibili e si rischia di usare un'estensione dannosa o scritta in modo non appropriato.
Le terze parti devono fornire documentazione specifica su come installare e usare le estensioni nell'app per le funzioni. Per un esempio di base su come usare un'estensione, vedere Uso dell'estensione.
Ecco alcuni esempi di uso delle estensioni in un'app per le funzioni, in base all'ambito:
# <project_root>/requirements.txt
application-level-extension==1.0.0
# <project_root>/Trigger/__init__.py
from application_level_extension import AppExtension
AppExtension.configure(key=value)
def main(req, context):
# Use context.app_ext_attributes here
Creazione di estensioni
Le estensioni vengono create da sviluppatori di librerie di terze parti che hanno creato funzionalità integrabili in Funzioni di Azure. Uno sviluppatore di estensioni progetta, implementa e rilascia pacchetti Python che contengono logica personalizzata progettata specificamente per l'esecuzione nel contesto dell'esecuzione della funzione. Queste estensioni possono essere pubblicate nel registro PyPI o nei repository GitHub.
Per informazioni su come creare, inserire in pacchetti, pubblicare e usare un pacchetto di estensione del ruolo di lavoro Python, vedere Sviluppare estensioni del ruolo di lavoro Python per Funzioni di Azure.
Estensioni a livello di applicazione
Un'estensione ereditata da AppExtensionBase viene eseguita in un ambito dell'applicazione.
AppExtensionBase espone i seguenti metodi di classe astratta per le implementazioni:
| Metodo | Descrizione |
|---|---|
init |
Chiamato dopo l'importazione dell'estensione. |
configure |
Chiamato dal codice della funzione quando è necessario configurare l'estensione. |
post_function_load_app_level |
Chiamato subito dopo il caricamento della funzione. Il nome della funzione e la directory della funzione vengono passati all'estensione. Tenere presente che la directory della funzione è di sola lettura e qualsiasi tentativo di scrittura in un file locale in questa directory avrà esito negativo. |
pre_invocation_app_level |
Chiamato subito prima dell'attivazione della funzione. Il contesto della funzione e gli argomenti di chiamata di funzione vengono passati all'estensione. In genere è possibile passare altri attributi nell'oggetto contesto per il codice della funzione da utilizzare. |
post_invocation_app_level |
Chiamato subito dopo il completamento dell'esecuzione della funzione. Il contesto della funzione, gli argomenti di chiamata della funzione e l'oggetto restituito della chiamata vengono passati all'estensione. Questa implementazione è un luogo ideale per verificare se l'esecuzione degli hook del ciclo di vita è riuscita. |
Estensioni a livello di funzione
Estensione che eredita da FuncExtensionBase viene eseguita in un trigger di funzione specifico.
FuncExtensionBase espone i seguenti metodi di classe astratta per le implementazioni:
| Metodo | Descrizione |
|---|---|
__init__ |
Il costruttore dell'estensione. Viene chiamato quando un'istanza di estensione viene inizializzata in una funzione specifica. Quando si implementa questo metodo astratto, è possibile accettare un parametro filename e passarlo al metodo dell'elemento padre super().__init__(filename) per la registrazione corretta dell'estensione. |
post_function_load |
Chiamato subito dopo il caricamento della funzione. Il nome della funzione e la directory della funzione vengono passati all'estensione. Tenere presente che la directory della funzione è di sola lettura e qualsiasi tentativo di scrittura in un file locale in questa directory avrà esito negativo. |
pre_invocation |
Chiamato subito prima dell'attivazione della funzione. Il contesto della funzione e gli argomenti di chiamata di funzione vengono passati all'estensione. In genere è possibile passare altri attributi nell'oggetto contesto per il codice della funzione da utilizzare. |
post_invocation |
Chiamato subito dopo il completamento dell'esecuzione della funzione. Il contesto della funzione, gli argomenti di chiamata della funzione e l'oggetto restituito della chiamata vengono passati all'estensione. Questa implementazione è un luogo ideale per verificare se l'esecuzione degli hook del ciclo di vita è riuscita. |
Condivisione di risorse tra le origini
Funzioni di Azure supporta la condivisione di risorse tra origini (CORS, Cross-Origin Resource Sharing). La funzionalità CORS è configurata nel portale e tramite l'interfaccia della riga di comando di Azure. L'elenco delle origini consentite per CORS si applica a livello di app per le funzioni. Con la funzionalità CORS abilitata, le risposte includono l'intestazione Access-Control-Allow-Origin. Per altre informazioni, vedere Utilizzare la condivisione di risorse tra origini.
CORS è completamente supportato per le app per le funzioni Python.
Async
Per impostazione predefinita, un'istanza host per Python può elaborare una sola chiamata di funzione alla volta. Questo perché Python è un runtime a thread singolo. Per un'app per le funzioni che elabora un numero elevato di eventi di I/O o che è associata all'I/O stesso, è possibile migliorare significativamente le prestazioni eseguendo funzioni in modo asincrono. Per altre informazioni, vedere Migliorare le prestazioni della velocità effettiva delle app Python in Funzioni di Azure.
Memoria condivisa (anteprima)
Per migliorare la velocità effettiva, Funzioni di Azure consente al ruolo di lavoro del linguaggio Python fuori processo di condividere la memoria con il processo host di Funzioni. Quando l'app per le funzioni riscontra colli di bottiglia, è possibile abilitare la memoria condivisa aggiungendo un'impostazione dell'applicazione denominata FUNCTIONS_WORKER_SHARED_MEMORY_DATA_TRANSFER_ENABLED con il valore 1. Con la memoria condivisa abilitata, è quindi possibile usare l'impostazione DOCKER_SHM_SIZE per impostare la memoria condivisa su un valore simile a 268435456, che equivale a 256 MB.
Ad esempio, è possibile abilitare la memoria condivisa per ridurre i colli di bottiglia quando si usano associazioni di archiviazione BLOB per trasferire payload di dimensioni superiori a 1 MB.
Questa funzionalità è disponibile solo per le app per le funzioni in esecuzione nei piani Premium e Dedicato (Servizio app di Azure). Per altre informazioni, vedere Memoria condivisa.
Problemi noti e domande frequenti
Ecco due guide alla risoluzione dei problemi comuni:
Di seguito sono riportate due guide alla risoluzione dei problemi noti relative al modello di programmazione v2:
- Non è stato possibile caricare il file o l'assembly
- Non è possibile risolvere la connessione di Archiviazione di Azure denominata Archiviazione
Tutti i problemi noti e le richieste di funzionalità vengono registrati tramite l'elenco di problemi di GitHub. Se si verifica un problema e questo non è presente in GitHub, aprire un nuovo problema e includere una descrizione dettagliata.
Passaggi successivi
Per altre informazioni, vedere le seguenti risorse: