Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Il backup del servizio Azure Kubernetes è un processo semplice nativo del cloud che è possibile usare per eseguire il backup e il ripristino di applicazioni e dati in contenitori eseguiti nel cluster del servizio Azure Kubernetes. È possibile configurare i backup pianificati per lo stato del cluster e i dati dell'applicazione archiviati nei Volumi Persistenti di Kubernetes nell'Archiviazione Dischi di Azure basata su driver CSI (Container Storage Interface).
La soluzione offre un controllo granulare. È possibile eseguire il backup o il ripristino di uno spazio dei nomi specifico o di un intero cluster archiviando i backup in locale in un contenitore BLOB e come snapshot del disco. È possibile usare il backup del servizio Azure Kubernetes per scenari end-to-end, tra cui ripristino operativo, clonazione di ambienti di sviluppo o test e scenari di aggiornamento del cluster.
Il backup di AKS si integra con il Centro Backup di Azure per fornire una visione unificata che consente di governare, monitorare, operare e analizzare i backup su larga scala. I backup sono disponibili anche nel portale di Azure in Impostazioni nel menu del servizio per un'istanza AKS.
Come funziona il backup di AKS?
È possibile usare il backup del servizio Azure Kubernetes per eseguire il backup dei carichi di lavoro del servizio Azure Kubernetes e dei volumi permanenti distribuiti nei cluster del servizio Azure Kubernetes. La soluzione richiede che l'estensione Backup sia installata all'interno del cluster AKS. La cassetta di sicurezza di backup comunica all'estensione per completare le operazioni di backup e ripristino. L'uso dell'estensione backup è obbligatorio. L'estensione deve essere installata all'interno del cluster AKS per abilitare il backup e il ripristino per il cluster. Quando si configura il backup del servizio Azure Kubernetes, si aggiungono valori per un account di archiviazione e un contenitore BLOB in cui vengono archiviati i backup.
Insieme all'estensione Backup, viene creata un'identità utente (denominata identità dell'estensione) nel gruppo di risorse gestite del cluster del servizio Azure Kubernetes. All'identità dell'estensione è assegnato al ruolo di Collaboratore dell'account di archiviazione su cui sono memorizzati i backup in un contenitore BLOB.
Per supportare cluster pubblici, privati e autorizzati basati su IP, il backup di AKS richiede l'abilitazione della funzionalità Accesso attendibile tra il cluster AKS e l'insieme di credenziali Backup. Accesso attendibile consente al caveau di Backup di accedere al cluster AKS perché gli sono assegnate autorizzazioni specifiche per le operazioni di backup. Per altre informazioni sull'Accesso attendibile del servizio Azure Kubernetes, vedere Abilitare le risorse di Azure per accedere ai cluster del servizio Azure Kubernetes tramite Accesso attendibile.
Il backup di AKS consente di archiviare i backup sia nel livello operativo che nel livello Vault. Il livello operativo è un archivio dati locale (i backup vengono archiviati nel tenant come snapshot). È ora possibile spostare un punto di ripristino al giorno e archiviarlo nel livello Vault come blob (al di fuori del tenant) utilizzando il backup di Azure Kubernetes. I backup archiviati nel livello Vault possono essere usati anche per ripristinare i dati in un'area secondaria (Azure-paired region associata).
Dopo aver installato l'estensione backup e abilitato l'accesso attendibile, è possibile configurare i backup pianificati per i cluster in base ai criteri di backup. È anche possibile ripristinare i backup nel cluster originale o in un cluster diverso nella stessa sottoscrizione e nella stessa area. Durante la configurazione dell'operazione specifica, è possibile scegliere uno spazio dei nomi specifico o un intero cluster come configurazione di backup e ripristino.
Il backup AKS abilita le operazioni di backup per le origini dati AKS distribuite nel cluster. Abilita anche le operazioni di backup per i dati archiviati nel volume persistente per il cluster. Archivia quindi i backup in un contenitore BLOB. I Volumi Persistenti basati su disco sono sottoposti a backup come snapshot del disco in un gruppo di risorse snapshot. Gli snapshot e lo stato del cluster in un BLOB si combinano per formare un punto di ripristino denominato livello operativo archiviato nel tenant. È anche possibile convertire i backup (il primo backup riuscito in un giorno, una settimana, un mese o un anno) nel Livello Operativo in BLOB, e poi spostarli in un archivio (all'esterno del tenant) una volta al giorno.
Nota
Attualmente, Backup di Azure supporta solo i volumi persistenti nell'Archiviazione su disco Azure basata su driver CSI. Durante i backup, la soluzione ignora altri tipi di volumi persistenti, come le condivisioni di Azure Files e i blob. Inoltre, se si impostano regole di conservazione definite per il livello Vault, i backup sono idonei per essere spostati nel Vault solo se i volumi permanenti sono minori o uguali a 1 TB.
Configurare il backup
Per configurare i backup per i cluster AKS, creare prima di tutto un Archivio di Backup. La cassaforte offre una visualizzazione consolidata dei backup configurati tra le diverse fonti di dati. Il backup di AKS supporta i backup sia per il livello operativo che per il livello Vault.
L'impostazione di ridondanza dell'archiviazione dell'archivio di backup (archiviazione con ridondanza locale o archiviazione con ridondanza geografica) si applica solo ai backup archiviati nel Livello di archivio. Se si vogliono usare i backup per il ripristino di emergenza, impostare la ridondanza dell'archiviazione su ridondanza geografica e abilitare il ripristino tra aree.
Nota
La vault di backup e il cluster AKS di cui si vuole eseguire il backup o il ripristino devono trovarsi nella stessa area e nella stessa sottoscrizione.
Il sistema di backup AKS attiva automaticamente un processo di backup pianificato. Il processo copia le risorse del cluster in un contenitore BLOB e crea uno snapshot incrementale dei volumi persistenti basati su disco in base alla frequenza di backup. I backup vengono conservati nel livello operativo e nel livello di archiviazione secondo la durata di conservazione definita nella politica di backup. I backup vengono eliminati quando la durata è finita.
È possibile usare il backup del servizio Azure Kubernetes per creare più istanze di backup per un singolo cluster del servizio Azure Kubernetes usando configurazioni di backup diverse per ogni istanza di backup. È tuttavia consigliabile creare ogni istanza di backup di un cluster del servizio Azure Kubernetes in uno dei due modi seguenti:
- In un insieme di credenziali di backup diverso
- Usando un criterio di backup separato nello stesso archivio di backup
Gestire il backup
Al termine della configurazione di backup per un cluster del servizio Azure Kubernetes, viene creata un'istanza di backup nell'insieme di credenziali di backup. È possibile visualizzare l'istanza di backup per il cluster nella sezione Backup per un'istanza AKS nel portale di Azure. È possibile eseguire qualsiasi operazione correlata al backup per l'istanza, ad esempio l'avvio di ripristini, il monitoraggio, l'arresto della protezione e così via, tramite l'istanza di backup corrispondente.
Il backup del servizio Azure Kubernetes si integra direttamente con il Centro backup per gestire centralmente la protezione per tutti i cluster del servizio Azure Kubernetes e altri carichi di lavoro supportati dal backup. Il Centro backup offre una singola visualizzazione per tutti i requisiti di backup, ad esempio il monitoraggio dei processi e lo stato dei backup e dei ripristini. Il Centro backup consente di garantire la conformità e la governance, analizzare l'utilizzo dei backup ed eseguire operazioni critiche per eseguire il backup e il ripristino dei dati.
Il backup di AKS usa un'identità gestita per accedere ad altre risorse di Azure. Per configurare il backup di un cluster AKS e ripristinare da un backup precedente, l'identità gestita dell'insieme di backup richiede un set di autorizzazioni sul cluster AKS. Richiede anche un set di autorizzazioni per il gruppo di risorse snapshot in cui vengono creati e gestiti gli snapshot. Attualmente, il cluster AKS richiede un set di autorizzazioni per il gruppo di risorse snapshot.
Inoltre, l'estensione Backup crea un'identità utente e assegna un set di autorizzazioni per accedere all'account di archiviazione in cui vengono archiviati i backup in un BLOB. È possibile concedere autorizzazioni all'identità gestita usando il controllo degli accessi in base al ruolo di Azure. Un'identità gestita è un tipo speciale di principio del servizio che può essere usata solo con le risorse di Azure. Vedere altre informazioni sulle identità gestite.
Eseguire il ripristino da un backup
È possibile ripristinare dati da qualsiasi momento per cui esiste un punto di ripristino. Un punto di ripristino viene creato quando un'istanza di backup è in uno stato protetto. Può essere usato per ripristinare i dati fino a quando la politica di backup conserva i dati.
Backup di Azure offre la possibilità di ripristinare tutti gli elementi di cui è stato eseguito il backup o di usare controlli granulari per selezionare elementi specifici dai backup usando spazi dei nomi e altre opzioni di filtro. È anche possibile eseguire il ripristino nel cluster del servizio Azure Kubernetes originale (cluster di cui è stato eseguito il backup) o in un cluster del servizio Azure Kubernetes alternativo. È possibile ripristinare i backup archiviati nel livello operativo e nel livello archivio in un cluster nella stessa sottoscrizione o in una sottoscrizione diversa. Solo i backup archiviati nel livello di Vault possono essere usati per effettuare un ripristino su un cluster in una regione diversa (regione abbinata di Azure).
Per ripristinare un backup archiviato nel livello Vault, è necessario specificare un percorso di staging in cui i dati di backup vengono reidratati. Questo percorso di gestione temporanea include un gruppo di risorse e un account di archiviazione all'interno della stessa area e sottoscrizione del cluster di destinazione per il ripristino. Durante il ripristino, le risorse specifiche (contenitore BLOB, disco e snapshot del disco) vengono create come parte dell'idratazione. Vengono cancellati al termine dell'operazione di ripristino.
Backup di Azure per AKS supporta attualmente le seguenti due opzioni per uno scenario in cui si verifica un conflitto di risorse. Un conflitto di risorse si verifica quando una risorsa sottoposta a backup ha lo stesso nome della risorsa nel cluster del servizio Azure Kubernetes di destinazione. È possibile scegliere una di queste opzioni quando si definisce la configurazione di ripristino.
Ignora: questa opzione è selezionata per impostazione predefinita. Ad esempio, se si esegue il backup di un'attestazione di volume persistente (PVC) denominata
pvc-azurediske la si ripristina in un cluster di destinazione con lo stesso nome, l'estensione di backup ignora il ripristino del PVC di cui è stato eseguito il backup. In questi scenari è consigliabile eliminare la risorsa dal cluster. Eseguire quindi l'operazione di ripristino in modo che gli elementi di cui è stato eseguito il backup siano disponibili solo nel cluster e non vengano ignorati.Patch: Questa opzione consente di applicare patch alla variabile modificabile nella risorsa di backup sulla risorsa nel cluster di destinazione. Se si vuole aggiornare il numero di repliche nel cluster di destinazione, si può scegliere di applicare una patch.
Nota
Il backup di AKS non elimina e ricrea le risorse nel cluster di destinazione, se già esistenti. Se si tenta di ripristinare volumi persistenti nel percorso originale, eliminare i volumi persistenti esistenti e quindi eseguire l'operazione di ripristino.
Usare hook personalizzati per il backup e il ripristino
È possibile usare hook personalizzati per creare snapshot coerenti con l'applicazione di volumi usati per i database distribuiti come carichi di lavoro in contenitori.
Che cosa sono gli hook personalizzati?
È possibile utilizzare il backup di AKS per eseguire hook personalizzati come parte di un'operazione di backup e ripristino. Gli hook sono configurati per eseguire uno o più comandi all'interno del contenitore di un pod durante un'operazione di backup o dopo il ripristino.
Questi hook vengono definiti come risorsa personalizzata e distribuiti nel cluster del servizio Azure Kubernetes di cui si vuole eseguire il backup o il ripristino. quando la risorsa personalizzata viene distribuita nel cluster AKS nello spazio dei nomi richiesto, si forniscono i dettagli come input al flusso che configura il backup e il ripristino. L'estensione Backup esegue gli hook come definito in un file YAML.
Nota
Gli hook non vengono eseguiti in una shell nei contenitori.
Il backup nel servizio Azure Kubernetes include due tipi di hook:
- Hook di backup
- Hook di ripristino
Hook di backup
Quando si usa un hook di backup, è possibile configurare i comandi per eseguire l'hook prima di qualsiasi elaborazione dell'azione personalizzata (PreHooks). È anche possibile eseguire l'hook al termine di tutte le azioni personalizzate ed eventuali elementi aggiuntivi specificati dalle azioni personalizzate vengono sottoposti a backup (PostHooks).
Ad esempio, di seguito è riportato il modello YAML per la distribuzione di una risorsa personalizzata usando hook di backup:
apiVersion: clusterbackup.dataprotection.microsoft.com/v1alpha1
kind: BackupHook
metadata:
# BackupHook CR Name and Namespace
name: bkphookname0
namespace: default
spec:
# BackupHook is a list of hooks to execute before and after backing up a resource.
backupHook:
# BackupHook Name. This is the name of the hook that will be executed during backup.
# compulsory
- name: hook1
# Namespaces where this hook will be executed.
includedNamespaces:
- hrweb
excludedNamespaces:
labelSelector:
# PreHooks is a list of BackupResourceHooks to execute prior to backing up an item.
preHooks:
- exec:
# Container is the container in the pod where the command should be executed.
container: webcontainer
# Command is the command and arguments to execute.
command:
- /bin/uname
- -a
# OnError specifies how Velero should behave if it encounters an error executing this hook
onError: Continue
# Timeout is the amount of time to wait for the hook to complete before considering it failed.
timeout: 10s
- exec:
command:
- /bin/bash
- -c
- echo hello > hello.txt && echo goodbye > goodbye.txt
container: webcontainer
onError: Continue
# PostHooks is a list of BackupResourceHooks to execute after backing up an item.
postHooks:
- exec:
container: webcontainer
command:
- /bin/uname
- -a
onError: Continue
timeout: 10s
Hook di ripristino
Nello script hook di ripristino, i comandi o gli script personalizzati vengono scritti per essere eseguiti nei contenitori di un pod del servizio Azure Kubernetes ripristinato.
Ecco il modello YAML per una risorsa personalizzata distribuita tramite hook di ripristino:
apiVersion: clusterbackup.dataprotection.microsoft.com/v1alpha1
kind: RestoreHook
metadata:
name: restorehookname0
namespace: default
spec:
# RestoreHook is a list of hooks to execute after restoring a resource.
restoreHook:
# Name is the name of this hook.
- name: myhook-1
# Restored Namespaces where this hook will be executed.
includedNamespaces:
excludedNamespaces:
labelSelector:
# PostHooks is a list of RestoreResourceHooks to execute during and after restoring a resource.
postHooks:
- exec:
# Container is the container in the pod where the command should be executed.
container: webcontainer
# Command is the command and arguments to execute from within a container after a pod has been restored.
command:
- /bin/bash
- -c
- echo hello > hello.txt && echo goodbye > goodbye.txt
# OnError specifies how Velero should behave if it encounters an error executing this hook
# default value is Continue
onError: Continue
# Timeout is the amount of time to wait for the hook to complete before considering it failed.
execTimeout: 30s
# WaitTimeout defines the maximum amount of time Velero should wait for the container to be ready before attempting to run the command.
waitTimeout: 5m
Scopri come utilizzare i ganci durante il backup del servizio Azure Kubernetes (AKS).
Durante il ripristino, l'estensione di backup attende che il contenitore venga attivato e quindi esegue i comandi exec su di essi, definiti negli hook di ripristino.
Se si esegue il ripristino nello stesso spazio dei nomi di cui è stato eseguito il backup, l'hook di ripristino non viene eseguito. Cerca solo un contenitore appena generato. Questo risultato si verifica indipendentemente dal fatto che si usino i criteri skip o patch.
Modificare la risorsa mentre si ripristinano i backup nel cluster AKS
È possibile utilizzare la funzionalità di modifica delle risorse per modificare le risorse Kubernetes di cui è stato eseguito il backup durante il ripristino del backup, specificando patch JSON implementate configmap nel cluster AKS.
Creare e applicare una mappa di configurazione del modificatore di risorse durante il ripristino
Per creare e applicare la modifica delle risorse, seguire questa procedura:
Creare un modificatore
configmapdi risorse.È necessario creare un
configmapnel tuo spazio dei nomi preferito da un file YAML che definisce i modificatori di risorse.Esempio per la creazione di un comando:
version: v1 resourceModifierRules: - conditions: groupResource: persistentvolumeclaims resourceNameRegex: "^mysql.*$" namespaces: - bar - foo labelSelector: matchLabels: foo: bar patches: - operation: replace path: "/spec/storageClassName" value: "premium" - operation: remove path: "/metadata/labels/test"- La precedente
configmapapplica la patch JSON a tutte le copie del volume persistente nellanamespacesbarra efoocon un nome che inizia conmysqlematch label foo: bar. La patch JSON sostituiscestorageClassNameconpremiume rimuove l'etichettatestdalle copie del volume persistente. - In questo caso,
namespaceè lo spazio dei nomi originale della risorsa sottoposta a backup e non il nuovo spazio dei nomi in cui verrà ripristinata la risorsa. - È possibile specificare più patch JSON per una determinata risorsa. Le patch vengono applicate in base all'ordine specificato in
configmap. La patch successiva viene applicata nell'ordine corretto. Se vengono specificate più patch per lo stesso percorso, l'ultima patch sostituisce quelle precedenti. - È possibile specificare più
resourceModifierRulesinconfigmap. Le regole vengono applicate in base all'ordine specificato inconfigmap.
- La precedente
Creare un riferimento al modificatore di risorse nella configurazione di ripristino
Quando si esegue un'operazione di ripristino, fornire
ConfigMap nameenamespacela posizione in cui viene implementata come parte della configurazione di ripristino. Questi dettagli devono essere forniti in Regole del modificatore di risorse.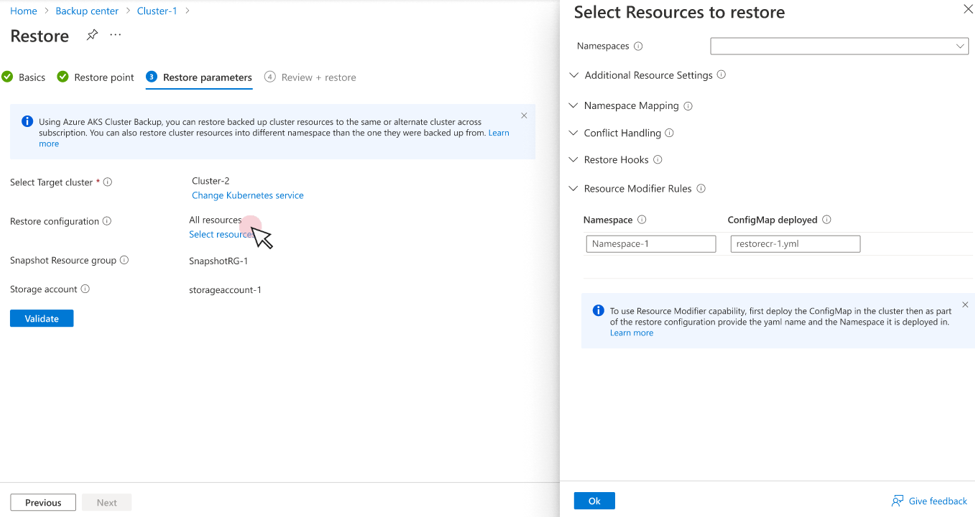

Operazioni supportate dal modificatore di risorse
Aggiunta
È possibile usare l'operazione Aggiungi per aggiungere un nuovo blocco al codice JSON della risorsa. Nell'esempio seguente, l'operazione aggiunge nuovi dettagli del contenitore alla specifica durante una distribuzione.
version: v1 resourceModifierRules: - conditions: groupResource: deployments.apps resourceNameRegex: "^test-.*$" namespaces: - bar - foo patches: # Dealing with complex values by escaping the yaml - operation: add path: "/spec/template/spec/containers/0" value: "{\"name\": \"nginx\", \"image\": \"nginx:1.14.2\", \"ports\": [{\"containerPort\": 80}]}"Rimuovi
È possibile usare l'operazione Rimuovi per rimuovere una chiave dal codice JSON della risorsa. Nell'esempio seguente l'operazione rimuove l'etichetta con
testcome chiave.version: v1 resourceModifierRules: - conditions: groupResource: persistentvolumeclaims resourceNameRegex: "^mysql.*$" namespaces: - bar - foo labelSelector: matchLabels: foo: bar patches: - operation: remove path: "/metadata/labels/test"Sostituzione
È possibile usare l'operazione Replace per sostituire un valore per il percorso indicato impostando un percorso alternativo. Nell'esempio seguente, l'operazione sostituisce il
storageClassNamenel PVC con ilpremium.version: v1 resourceModifierRules: - conditions: groupResource: persistentvolumeclaims resourceNameRegex: "^mysql.*$" namespaces: - bar - foo labelSelector: matchLabels: foo: bar patches: - operation: replace path: "/spec/storageClassName" value: "premium"Copia
È possibile usare l'operazione Copy per copiare un valore da un percorso dalle risorse definite a un altro percorso.
version: v1 resourceModifierRules: - conditions: groupResource: deployments.apps resourceNameRegex: "^test-.*$" namespaces: - bar - foo patches: - operation: copy from: "/spec/template/spec/containers/0" path: "/spec/template/spec/containers/1"Test
È possibile usare l'operazione Test per verificare se nella risorsa è presente un valore specifico. Se il valore è presente, viene applicata la patch. Se il valore non è presente, non viene applicata la patch. Nell'esempio seguente, l'operazione verifica se i PVC hanno
premiumcomeStorageClassNamee lo sostituiscono constandard, se è vero.version: v1 resourceModifierRules: - conditions: groupResource: persistentvolumeclaims resourceNameRegex: ".*" namespaces: - bar - foo patches: - operation: test path: "/spec/storageClassName" value: "premium" - operation: replace path: "/spec/storageClassName" value: "standard"Patch JSON
Ciò
configmapapplica la patch JSON a tutte le distribuzioni nei namespace per impostazione predefinita enginxil cui nome inizia connginxdep. La patch JSON aggiorna il numero di repliche in12per tutte queste distribuzioni.version: v1 resourceModifierRules: - conditions: groupResource: deployments.apps resourceNameRegex: "^nginxdep.*$" namespaces: - default - nginx patches: - operation: replace path: "/spec/replicas" value: "12"Patch di fusione JSON
Questo
configmapapplica la patch di merge JSON a tutte le distribuzioni nei namespace "default" enginxcon un nome che inizia connginxdep. La patch di merge JSON aggiunge o aggiorna l'etichettaappcon il valorenginx1.version: v1 resourceModifierRules: - conditions: groupResource: deployments.apps resourceNameRegex: "^nginxdep.*$" namespaces: - default - nginx mergePatches: - patchData: | { "metadata" : { "labels" : { "app" : "nginx1" } } }Patch di fusione strategica
Ciò
configmapapplica la patch di unione strategica a tutti i pod nello spazio dei nomi predefinito il cui nome inizia connginx. La patch di unione strategica aggiorna l'immagine del contenitorenginxamcr.microsoft.com/cbl-mariner/base/nginx:1.22.version: v1 resourceModifierRules: - conditions: groupResource: pods resourceNameRegex: "^nginx.*$" namespaces: - default strategicPatches: - patchData: | { "spec": { "containers": [ { "name": "nginx", "image": "mcr.microsoft.com/cbl-mariner/base/nginx:1.22" } ] } }
Quale livello di archiviazione di backup supporta il backup del servizio Azure Kubernetes?
Azure Backup per AKS supporta due livelli di archiviazione come datastores di backup.
Livello operativo: l'estensione di backup installata nel cluster del servizio Azure Kubernetes esegue prima il backup eseguendo snapshot del volume tramite il driver CSI. Archivia quindi lo stato del cluster in un contenitore BLOB nel proprio tenant. Questo livello supporta un obiettivo del punto di ripristino (RPO) inferiore con la durata minima di quattro ore tra due backup. Inoltre, per i volumi basati su disco di Azure, il livello operativo supporta ripristini più rapidi.
Livello Vault: per archiviare i dati di backup per una durata più lunga a un costo inferiore rispetto agli snapshot, il backup di AKS supporta i datastore standard del vault. In base alle regole di conservazione impostate nei criteri di backup, il primo backup riuscito (di un giorno, di una settimana, di un mese o di un anno) viene spostato in un contenitore BLOB all'esterno del tenant. Questo archivio dati non solo consente una conservazione più lunga, ma fornisce anche protezione ransomware. È anche possibile spostare i backup archiviati nell'insieme di credenziali in un'altra area (area associata ad Azure) per il ripristino abilitando la ridondanza geografica e il ripristino tra aree nell'insieme di credenziali di Backup.
Nota
È possibile archiviare i dati di backup in un archivio dati standard dell'insieme di credenziali tramite criteri di backup definendo le regole di conservazione. Viene spostato solo un punto di ripristino programmato al giorno nel livello di archiviazione. Tuttavia, è possibile spostare qualsiasi quantità di backup su richiesta nell'archivio in base alla regola selezionata.
Informazioni sui prezzi
Vengono effettuati addebiti per:
Tariffa dell'istanza protetta: Backup di Azure per il servizio Azure Kubernetes addebita una tariffa di istanza protetta per spazio dei nomi al mese. Quando si configura il backup per un cluster del servizio Azure Kubernetes, viene creata un'istanza protetta. Ogni istanza ha un numero specifico di spazi dei nomi di cui viene eseguito il backup come definito nella configurazione di backup. Per ulteriori informazioni sui prezzi per il backup di AKS, vedere Prezzi per il backup di Azure e selezionare Servizio Azure Kubernetes come carico di lavoro.
Tariffa snapshot: Azure Backup per AKS protegge un volume persistente basato su disco acquisendo snapshot archiviati nel gruppo di risorse della sottoscrizione di Azure. Questi snapshot comportano dei costi per l'archiviazione dei dati. Poiché gli snapshot non vengono copiati nella cassetta di sicurezza di backup, i costi di archiviazione del backup non vengono applicati. Per altre informazioni sui prezzi degli snapshot, vedere Prezzi di Managed Disks.
Tariffa per l'archiviazione dei backup: Azure Backup per Azure Kubernetes Service supporta anche l'archiviazione dei backup nel livello di vault. È possibile archiviare i backup nel livello Vault definendo le regole di conservazione per lo standard del Vault nella policy di backup, con un punto di ripristino al giorno idoneo per essere spostato nel Vault. I punti di ripristino archiviati nel livello Vault vengono addebitati una tariffa separata (denominata tariffa di archiviazione del backup) in base ai dati totali archiviati (in gigabyte) e al tipo di ridondanza abilitato nell'archivio di backup.