Cluster in modalità applicazione Apache Flink in HDInsight su AKS
Nota
Azure HDInsight su AKS verrà ritirato il 31 gennaio 2025. Prima del 31 gennaio 2025, sarà necessario eseguire la migrazione dei carichi di lavoro a Microsoft Fabric o a un prodotto Azure equivalente per evitare interruzioni improvvise dei carichi di lavoro. I cluster rimanenti nella sottoscrizione verranno arrestati e rimossi dall’host.
Solo il supporto di base sarà disponibile fino alla data di ritiro.
Importante
Questa funzionalità è attualmente disponibile solo in anteprima. Le Condizioni per l'utilizzo supplementari per le anteprime di Microsoft Azure includono termini legali aggiuntivi che si applicano a funzionalità di Azure in versione beta, in anteprima o in altro modo non ancora disponibili a livello generale. Per informazioni su questa anteprima specifica, vedere Informazioni sull'anteprima di Azure HDInsight nel servizio Azure Kubernetes. Per domande o suggerimenti sulle funzionalità, inviare una richiesta in AskHDInsight con i dettagli e seguire Microsoft per altri aggiornamenti nella Community di Azure HDInsight.
HDInsight su AKS offre ora un cluster in modalità applicazione Flink. Questo cluster consente di gestire il ciclo di vita della modalità applicazione Flink del cluster usando il portale di Azure con un'interfaccia facile da usare e le API REST di Gestione risorse di Azure. I cluster in modalità applicazione sono progettati per supportare processi di grandi dimensioni e a esecuzione prolungata con risorse dedicate e gestire attività di elaborazione dati estese o a elevato utilizzo di risorse.
Questa modalità di distribuzione consente di assegnare risorse dedicate per applicazioni Flink specifiche, assicurandosi che dispongano di potenza di calcolo e memoria sufficienti per gestire in modo efficiente carichi di lavoro di grandi dimensioni.

Vantaggi
Distribuzione semplificata del cluster con file JAR del processo.
API REST intuitiva: HDInsight su AKS offre API REST ARM intuitive per gestire le operazioni di processo in modalità app, ad esempio Aggiornamento, Punto di salvataggio, Annullamento ed Eliminazione.
Facilità di gestione degli aggiornamenti dei processi e della gestione dello stato: l'integrazione del portale di Azure nativo offre un'esperienza semplice per l'aggiornamento dei processi e il ripristino all'ultimo stato salvato (punto di salvataggio). Questa funzionalità garantisce la continuità e l'integrità dei dati nel ciclo di vita del processo.
Automatizzare i processi Flink usando Azure Pipelines o altri strumenti CI/CD: usando HDInsight su AKS, gli utenti Flink hanno accesso all'API REST ARM intuitiva, è possibile integrare facilmente le operazioni del processo Flink nella pipeline di Azure o in altri strumenti CI/CD.
Funzionalità principali
Arrestare e avviare processi con punti di salvataggio: gli utenti possono arrestare e avviare normalmente i processi AppMode Flink dallo stato precedente (punto di salvataggio). I punti di salvataggio assicurano che lo stato di avanzamento del processo venga mantenuto, abilitando le riprese senza problemi.
Aggiornamenti del processo: l'utente può aggiornare il processo AppMode in esecuzione dopo l'aggiornamento del file JAR nell'account di archiviazione. Questo aggiornamento accetta automaticamente il punto di salvataggio e avvia il processo AppMode con un nuovo file JAR.
Aggiornamenti senza stato: l'esecuzione di un nuovo riavvio per un processo AppMode viene semplificata tramite aggiornamenti senza stato. Questa funzionalità consente agli utenti di avviare un riavvio pulito usando il file JAR del processo aggiornato.
Gestione dei punti di salvataggio: in qualsiasi momento, gli utenti possono creare punti di salvataggio per i processi in esecuzione. Questi punti di salvataggio possono essere elencati e usati per riavviare il processo da un punto di controllo specifico in base alle esigenze.
Annulla: annulla il processo in modo permanente.
Elimina: elimina il cluster AppMode.
Come creare un cluster di applicazioni Flink
Prerequisiti
Completare i prerequisiti nelle sezioni seguenti:
Aggiungere il file JAR del processo nell'account di archiviazione.
Prima di configurare un cluster in modalità app Flink, sono necessari diversi passaggi preliminari. Uno di questi passaggi comporta l'inserimento del file JAR del processo in modalità app nell'account di archiviazione del cluster.
Creare una directory per il file JAR del processo in modalità app:
All'interno dei contenitori dedicati creare una directory in cui caricare il file JAR del processo in modalità app. Questa directory funge da percorso per l'archiviazione di file JAR da includere nel classpath del cluster o del processo Flink.
Directory dei punti di salvataggio (facoltativo):
Se gli utenti intendono usare punti di salvataggio durante l'esecuzione del processo, creare una directory separata all'interno dell'account di archiviazione per archiviare questi punti di salvataggio. Questa directory è usata per archiviare i dati e i metadati del punto di controllo per i punti di salvataggio.
Struttura di esempio della directory:
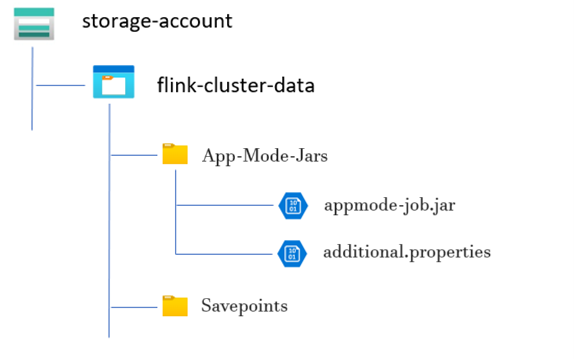

Creare un cluster in modalità app Flink
Dopo aver completato la distribuzione del pool di cluster, è possibile creare cluster AppMode Flink. Ora si vedrà come procedere nel caso in cui si stiano muovendo i primi passi con un pool di cluster esistente.
Nel portale di Azure digitare Pool di cluster HDInsight/HDInsight/HDInsight su AKS e selezionare Pool di cluster Azure HDInsight su AKS per aprire la pagina Pool di cluster. Nella pagina Pool di cluster HDInsight su AKS selezionare il pool di cluster in cui si vuole creare un nuovo cluster Flink.

Nella pagina del pool di cluster specifico fare clic su + Nuovo cluster e specificare le informazioni seguenti:
Proprietà Descrizione Subscription Questo campo viene popolato automaticamente con la sottoscrizione di Azure registrata per il pool di cluster. Gruppo di risorse Questo campo viene popolato automaticamente e mostra il gruppo di risorse nel pool di cluster. Paese Questo campo viene popolato automaticamente e mostra l'area selezionata nel pool di cluster. Pool di cluster Questo campo viene popolato automaticamente e mostra il nome del pool di cluster in cui viene creato il cluster. Per creare un cluster in un pool diverso, individuare il pool di cluster nel portale e fare clic su + Nuovo cluster. HDInsight nella versione pool del servizio Azure Kubernetes Questo campo viene popolato automaticamente e mostra la versione del pool di cluster in cui viene creato il cluster. HDInsight nella versione del servizio Azure Kubernetes Selezionare la versione secondaria o patch di HDInsight nel servizio Azure Kubernetes del nuovo cluster. Tipo di cluster Nell'elenco a discesa selezionare Flink. Nome cluster Immettere il nome del nuovo cluster. Identità gestita assegnata dall'utente Nell'elenco a discesa, selezionare l'identità gestita da usare con il cluster. Se si è il proprietario dell'identità del servizio gestito e quest'ultima non ha il ruolo Operatore identità gestita nel cluster, fare clic sul collegamento seguente per assegnare l'autorizzazione necessaria dall'identità del servizio gestito del pool di agenti del servizio Azure Kubernetes. Se l'identità del servizio gestito dispone già delle autorizzazioni corrette, non viene visualizzato alcun collegamento. Per altre assegnazioni di ruolo necessarie per l'identità del servizio gestito, vedere i Prerequisiti. Account di archiviazione Nell'elenco a discesa selezionare l'account di archiviazione da associare al cluster Flink e specificare il nome del contenitore. All'identità gestita viene ulteriormente concesso l'accesso all'account di archiviazione specificato usando il ruolo "Proprietario dati BLOB di archiviazione", durante la creazione del cluster. Rete virtuale Rete virtuale per il cluster. Subnet Subnet virtuale per il cluster. Abilitazione del catalogo Hive per Flink SQL:
Proprietà Descrizione Usare catalogo Hive Abilitare questa opzione per usare un metastore Hive esterno. Database SQL per Hive Nell'elenco a discesa, selezionare il database SQL in cui aggiungere tabelle hive-metastore. Nome utente amministratore SQL Immettere il nome utente dell'amministratore di SQL Server. Questo account viene usato dal metastore per comunicare con il database SQL. Key Vault Nell'elenco a discesa, selezionare l'insieme di credenziali delle chiavi, che contiene un segreto con password per il nome utente amministratore di SQL Server. È necessario configurare un criterio di accesso con tutte le autorizzazioni necessarie, ad esempio autorizzazioni chiave, autorizzazioni segrete e autorizzazioni del certificato per l'identità del servizio gestito, che viene usata per la creazione del cluster. MSI richiede un ruolo di amministratore dell'insieme di credenziali delle chiavi. Aggiungere le autorizzazioni necessarie usando IAM. Nome del segreto password SQL Immettere il nome del segreto dall'insieme di credenziali delle chiavi in cui è archiviata la password del database SQL. 
Nota
Per impostazione predefinita si usa l'account di archiviazione per il catalogo Hive come l'account di archiviazione e il contenitore usati durante la creazione del cluster.
Selezionare Avanti: Configurazione per continuare.
Nella pagina Configurazione, specificare le informazioni seguenti:
Proprietà Descrizione Dimensioni nodo Selezionare le dimensioni del nodo da usare per i nodi Flink sia per i nodi head che per i nodi di lavoro. Numero di nodi Selezionare il numero di nodi per il cluster Flink; per impostazione predefinita, i nodi head sono due. Il ridimensionamento dei nodi dei ruoli di lavoro consente di determinare le configurazioni di Gestione attività per Flink. I server di gestione processi e cronologia si trovano nei nodi di intestazione. Nella sezione Distribuzione scegliere Modalità applicazione come tipo di distribuzione e specificare le informazioni seguenti:
Proprietà Descrizione Percorso file JAR Assegnare il percorso ABFS (Archiviazione) per il file JAR del processo. Ad esempio, abfs://flink@teststorage.dfs.core.windows.net/appmode/job.jarClasse di immissione (facoltativo) Classe principale per il cluster in modalità applicazione. Ad esempio: com.microsoft.testjob Argomenti (facoltativo) Argomento per la classe principale del processo. Nome del punto di salvataggio Nome del punto di salvataggio precedente, che si vuole usare per l'avvio del processo Modalità di aggiornamento Selezionare l'opzione di aggiornamento predefinita. Questa opzione viene usata quando si verifica l'aggiornamento della versione principale del cluster. Sono disponibili tre opzioni. UPDATE: usato quando un utente vuole eseguire il ripristino dall'ultimo punto di salvataggio dopo l'aggiornamento. STATELESS_UPDATE: usato quando un utente vuole riavviare nuovamente il processo dopo l'aggiornamento. LAST_STATE_UPDATE: usato quando un utente vuole ripristinare il processo dall'ultimo punto di controllo dopo l'aggiornamento Configurazione del processo Flink Aggiungere altre configurazioni necessarie per il processo Flink. Selezionare "Aggregazione log processo". Selezionare la casella di controllo se si vuole caricare il log del processo nell'archiviazione remota. Consente di eseguire il debug dei problemi del processo. Il percorso predefinito per il log dei processi è "StorageAccount/Container/DeploymentId/logs". È possibile modificare la directory di log predefinita configurando "pipeline.remote.log.dir". L'intervallo predefinito per la raccolta dei log è di 600 secondi. L'utente può cambiarlo configurando "pipeline.log.aggregation.interval".
Nella sezione Configurazione del servizio specificare le informazioni seguenti:
Proprietà Descrizione CPU di Gestione attività Integer. Immettere le dimensioni delle CPU di Gestione attività (in core). Memoria in MB di Gestione attività Immettere le dimensioni della memoria di Gestione attività in MB. Minimo di 1.800 MB. CPU di Gestione processi Integer. Immettere il numero di CPU per Gestione processi (in core). Memoria di Gestione processi in MB Immettere le dimensioni della memoria in MB. Minimo 1.800 MB. CPU del server di cronologia Integer. Immettere il numero di CPU per Gestione processi (in core). Memoria del server di cronologia in MB Immettere le dimensioni della memoria in MB. Minimo 1.800 MB. 
Fare clic sul pulsante Avanti: Integrazione per passare alla pagina successiva.
Nella pagina Integrazione, specificare le informazioni seguenti:
Proprietà Descrizione Log Analytics Questa funzionalità è disponibile solo se è possibile selezionare il pool di cluster associato all'area di lavoro Log Analytics dopo aver abilitato i log da raccogliere. Azure Prometheus Questa funzionalità è utile per visualizzare le informazioni dettagliate e i log direttamente nel cluster inviando metriche e log a un'area di lavoro Monitoraggio di Azure. 
Fare clic sul pulsante Avanti: Tag per passare alla pagina successiva.
Nella pagina Tag specificare le informazioni seguenti:
Proprietà Descrizione Name Facoltativo. Immettere un nome, ad esempio HDInsight nel servizio Azure Kubernetes, per identificare facilmente tutte le risorse associate alle risorse del cluster. Valore È possibile lasciare vuoto questo campo. Conto risorse Selezionare Tutte le risorse selezionate. Selezionare Avanti: Rivedi e crea per continuare.
Nella pagina Rivedi e crea cercare il messaggio Convalida completata nella parte superiore della pagina e quindi fare clic su Crea.




Viene visualizzata la pagina Distribuzione in corso relativa alla creazione del cluster. La creazione del cluster richiede 5-10 minuti. Dopo aver creato il cluster, viene visualizzato il messaggio "La distribuzione è stata completata". Se si esce dalla pagina, è possibile controllare lo stato corrente delle notifiche.
Gestire il processo dell'applicazione nel portale
HDInsight AKS offre modi per gestire i processi Flink. È possibile riavviare un processo non riuscito. Riavviare il processo dal portale.
Per eseguire il processo Flink dal portale, passare a:
Portale > HDInsight su AKS > Cluster Flink > Impostazioni > Processi Flink.

Arresta: l'arresto del processo non richiede parametri. L'utente può arrestare il processo selezionando l'azione. Dopo l'arresto del processo, lo stato del processo nel portale è ARRESTATO.
Avvia: avvia il processo dal punto di salvataggio. Per avviare il processo, selezionare il processo arrestato e avviarlo.
Aggiorna: l'aggiornamento consente di riavviare i processi con il codice del processo aggiornato. Gli utenti devono aggiornare il file JAR del processo più recente nella posizione di archiviazione e aggiornare il processo dal portale. Questa azione arresta il processo con il punto di salvataggio e lo avvia di nuovo con il file JAR più recente.
Aggiornamento senza stato: l'aggiornamento senza stato è simile a un aggiornamento, ma comporta un nuovo riavvio del processo con il codice più recente. Dopo aver aggiornato il processo, lo stato del processo nel portale viene visualizzato come In esecuzione.
Punto di salvataggio: adotta il punto di salvataggio per il processo Flink.
Annulla: termina il processo.
Elimina: elimina il cluster AppMode.
Visualizza dettagli processo: per visualizzare i dettagli del processo l'utente può fare clic sul nome del processo, che fornisce i dettagli sul processo e sull'ultimo risultato dell'azione.


Per qualsiasi azione non riuscita, questa visualizzazione JSON fornisce eccezioni dettagliate e motivi dell'errore.