Integrazione di Azure Esplora dati e Apache Flink®
Azure Esplora dati è una piattaforma di analisi dei Big Data completamente gestita e ad alte prestazioni che semplifica l'analisi di volumi elevati di dati quasi in tempo reale.
ADX consente agli utenti di analizzare grandi volumi di dati da applicazioni di streaming, siti Web, dispositivi IoT e così via. L'integrazione di Apache Flink con ADX consente di elaborare dati in tempo reale e analizzarli in ADX.
Prerequisiti
- Creare un cluster Apache Flink in HDInsight nel servizio Azure Kubernetes
- Creare Esplora dati di Azure
Procedura per usare Azure Esplora dati come sink in Flink
Creare un cluster Flink.
Creare ADX con database e tabella in base alle esigenze.
Aggiungere autorizzazioni di ingestor per l'identità gestita in Kusto.
.add database <DATABASE_NAME> ingestors ('aadapp=CLIENT_ID_OF_MANAGED_IDENTITY')Eseguire un programma di esempio che definisce l'URI del cluster Kusto (Uniform Resource Identifier), il database e l'identità gestita usata e la tabella in cui deve scrivere.
Clonare il progetto flink-connector-kusto: https://github.com/Azure/flink-connector-kusto.git
Creare la tabella in ADX usando il comando seguente
.create table CryptoRatesHeartbeatTimeBatch (processing_dttm: datetime, ['type']: string, last_trade_id: string, product_id: string, sequence: long, ['time']: datetime)Aggiornare il file FlinkKustoSinkSample.java con l'URI del cluster Kusto corretto, il database e l'identità gestita usata.
String database = "sdktests"; //ADX database name String msiClientId = “xxxx-xxxx-xxxx”; //Provide the client id of the Managed identity which is linked to the Flink cluster String cluster = "https://trdp-1665b5eybxs0tbett.z8.kusto.fabric.microsoft.com/"; //Data explorer Cluster URI KustoConnectionOptions kustoConnectionOptions = KustoConnectionOptions.builder() .setManagedIdentityAppId(msiClientId).setClusterUrl(cluster).build(); String defaultTable = "CryptoRatesHeartbeatTimeBatch"; //Table where the data needs to be written KustoWriteOptions kustoWriteOptionsHeartbeat = KustoWriteOptions.builder() .withDatabase(database).withTable(defaultTable).withBatchIntervalMs(30000)Successivamente compilare il progetto usando "pacchetto pulito mvn"
Individuare il file JAR denominato "samples-java-1.0-SN piattaforma di strumenti analitici HOT-shaded.jar" nella cartella "sample-java/target", quindi caricare il file JAR nell'interfaccia utente Flink e inviare il processo.
Eseguire una query sulla tabella Kusto per verificare l'output
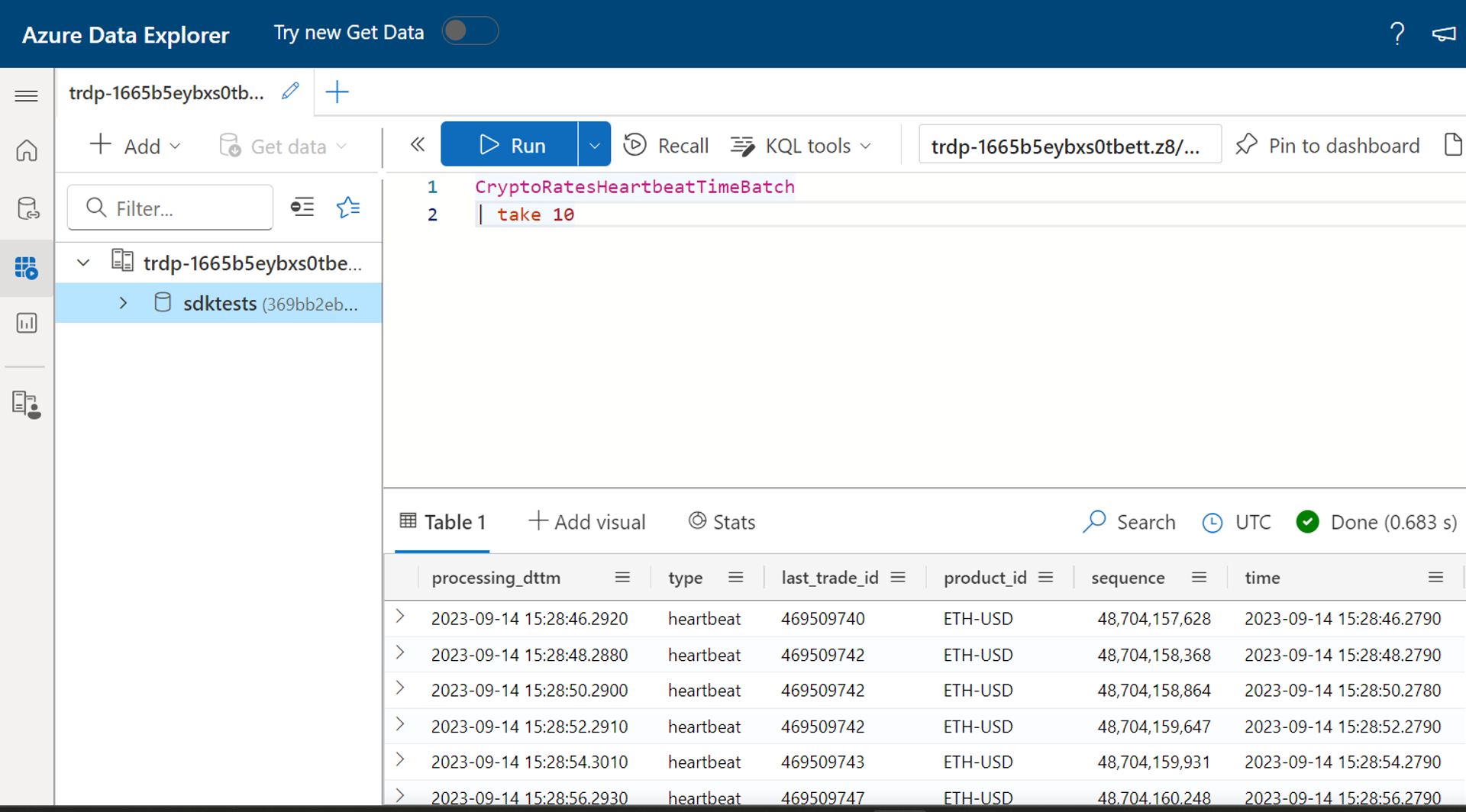
Non c'è alcun ritardo nella scrittura dei dati nella tabella Kusto da Flink.

Riferimento
- Sito Web Apache Flink
- Apache, Apache Flink, Flink e i nomi dei progetti open source associati sono marchi di Apache Software Foundation (ASF).