Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questa guida di avvio rapido descrive come usare un modello di Azure Resource Manager per creare un cluster Apache Spark in Azure HDInsight. Creare quindi un file di Jupyter Notebook e usarlo per eseguire query Spark SQL su tabelle Apache Hive. Azure HDInsight è un servizio di analisi open source, gestito e ad ampio spettro per le aziende. Il framework Apache Spark per HDInsight consente di velocizzare cluster computing e analisi dei dati grazie all'elaborazione in memoria. Jupyter Notebook consente di interagire con i dati, combinare codice con testo di markdown ed eseguire semplici visualizzazioni.
Se si usano più cluster, sarà necessario creare una rete virtuale e, se si usa un cluster Spark, è anche consigliabile usare Hive Warehouse Connector. Per altre informazioni, vedere Pianificare una rete virtuale per Azure HDInsight e Integrare Apache Spark e Apache Hive con Hive Warehouse Connector.
Un modello di Azure Resource Manager è un file JSON (JavaScript Object Notation) che definisce l'infrastruttura e la configurazione del progetto. Il modello utilizza la sintassi dichiarativa. Si descrive la distribuzione prevista senza scrivere la sequenza di comandi di programmazione necessari per creare la distribuzione.
Se l'ambiente soddisfa i prerequisiti e si ha familiarità con l'uso dei modelli di Resource Manager, selezionare il pulsante Distribuisci in Azure. Il modello verrà aperto nel portale di Azure.

Prerequisiti
Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
Rivedere il modello
Il modello usato in questo avvio rapido proviene dai modelli di avvio rapido di Azure.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"metadata": {
"_generator": {
"name": "bicep",
"version": "0.5.6.12127",
"templateHash": "4742950082151195489"
}
},
"parameters": {
"clusterName": {
"type": "string",
"metadata": {
"description": "The name of the HDInsight cluster to create."
}
},
"clusterLoginUserName": {
"type": "string",
"maxLength": 20,
"minLength": 2,
"metadata": {
"description": "These credentials can be used to submit jobs to the cluster and to log into cluster dashboards. The username must consist of digits, upper or lowercase letters, and/or the following special characters: (!#$%&'()-^_`{}~)."
}
},
"clusterLoginPassword": {
"type": "secureString",
"minLength": 10,
"metadata": {
"description": "The password must be at least 10 characters in length and must contain at least one digit, one upper case letter, one lower case letter, and one non-alphanumeric character except (single-quote, double-quote, backslash, right-bracket, full-stop). Also, the password must not contain 3 consecutive characters from the cluster username or SSH username."
}
},
"sshUserName": {
"type": "string",
"minLength": 2,
"metadata": {
"description": "These credentials can be used to remotely access the cluster. The sshUserName can only consit of digits, upper or lowercase letters, and/or the following special characters (%&'^_`{}~). Also, it cannot be the same as the cluster login username or a reserved word"
}
},
"sshPassword": {
"type": "secureString",
"maxLength": 72,
"minLength": 6,
"metadata": {
"description": "SSH password must be 6-72 characters long and must contain at least one digit, one upper case letter, and one lower case letter. It must not contain any 3 consecutive characters from the cluster login name"
}
},
"location": {
"type": "string",
"defaultValue": "[resourceGroup().location]",
"metadata": {
"description": "Location for all resources."
}
},
"headNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the headnode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
},
"workerNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E8_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the workernode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
}
},
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"apiVersion": "2021-08-01",
"name": "[format('storage{0}', uniqueString(resourceGroup().id))]",
"location": "[parameters('location')]",
"sku": {
"name": "Standard_LRS"
},
"kind": "StorageV2"
},
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2021-06-01",
"name": "[parameters('clusterName')]",
"location": "[parameters('location')]",
"properties": {
"clusterVersion": "4.0",
"osType": "Linux",
"tier": "Standard",
"clusterDefinition": {
"kind": "spark",
"configurations": {
"gateway": {
"restAuthCredential.isEnabled": true,
"restAuthCredential.username": "[parameters('clusterLoginUserName')]",
"restAuthCredential.password": "[parameters('clusterLoginPassword')]"
}
}
},
"storageProfile": {
"storageaccounts": [
{
"name": "[replace(replace(reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))).primaryEndpoints.blob, 'https://', ''), '/', '')]",
"isDefault": true,
"container": "[parameters('clusterName')]",
"key": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))), '2021-08-01').keys[0].value]"
}
]
},
"computeProfile": {
"roles": [
{
"name": "headnode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('headNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
},
{
"name": "workernode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('workerNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
}
]
}
},
"dependsOn": [
"[resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id)))]"
]
}
],
"outputs": {
"storage": {
"type": "object",
"value": "[reference(resourceId('Microsoft.Storage/storageAccounts', format('storage{0}', uniqueString(resourceGroup().id))))]"
},
"cluster": {
"type": "object",
"value": "[reference(resourceId('Microsoft.HDInsight/clusters', parameters('clusterName')))]"
}
}
}
Nel modello sono definite due risorse di Azure:
- Microsoft.Storage/storageAccounts per creare un account di archiviazione di Azure.
- Microsoft.HDInsight/cluster: creare un cluster HDInsight.
Distribuire il modello
Selezionare il pulsante Distribuisci in Azure sotto per accedere ad Azure e aprire il modello di Resource Manager.
Immettere o selezionare i valori seguenti:
Proprietà Descrizione Subscription Nell'elenco a discesa selezionare la sottoscrizione di Azure che viene usata per il cluster. Gruppo di risorse Nell'elenco a discesa selezionare il gruppo di risorse esistente oppure selezionare Crea nuovo. Ufficio Come valore verrà inserita automaticamente la località usata per il gruppo di risorse. Nome del cluster Immettere un nome globalmente univoco. Per questo modello usare solo lettere minuscole e numeri. Nome utente dell'account di accesso del cluster Specificare il nome utente. Il valore predefinito è admin.Password di accesso al cluster Specificare una password. La password deve avere una lunghezza minima di 10 caratteri e contenere almeno una cifra, una lettera maiuscola, una lettera minuscola e un carattere non alfanumerico (ad eccezione di ' ` ").Nome utente SSH Specificare il nome utente. Il valore predefinito è sshuser.Password SSH Specificare la password. 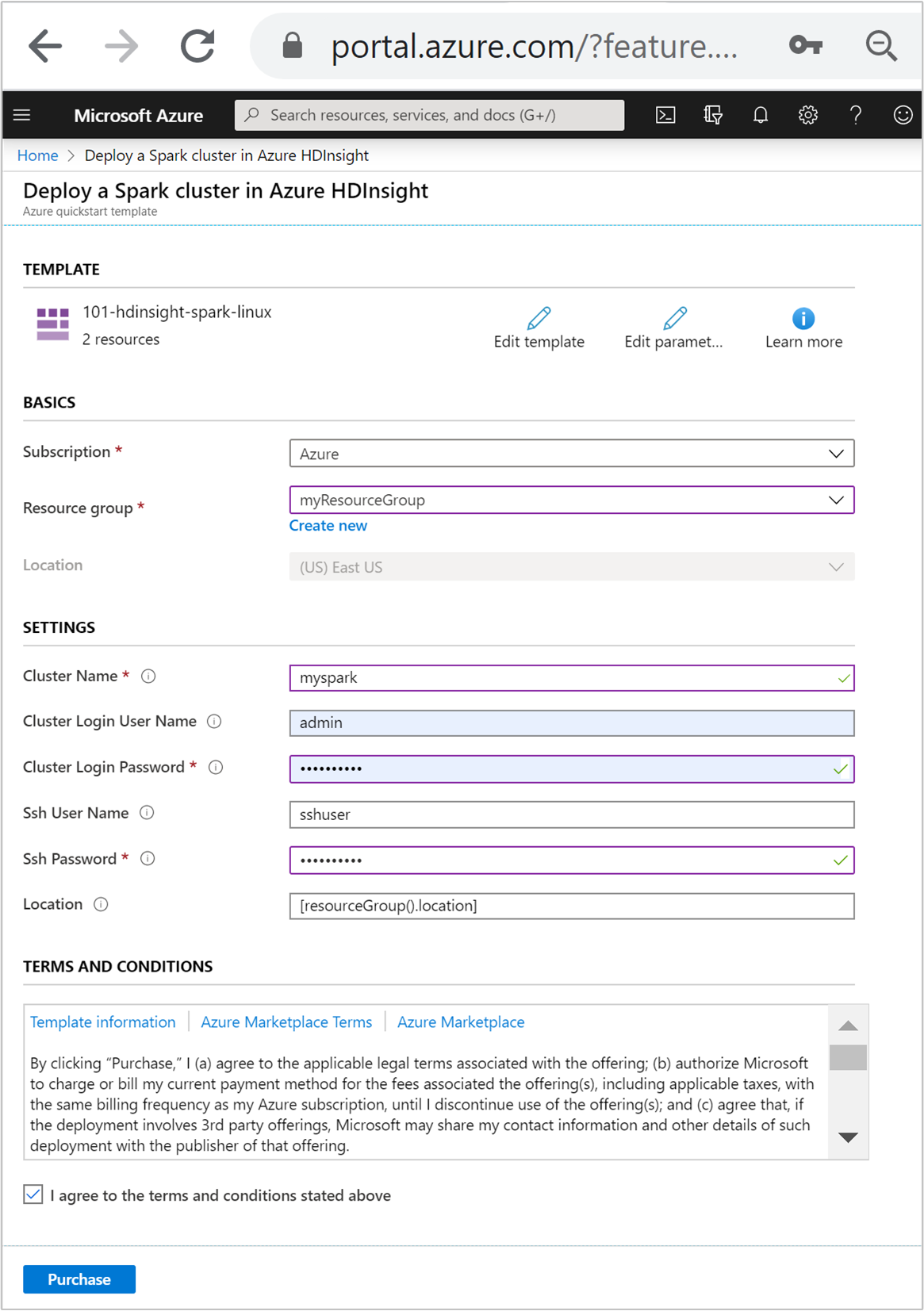
Leggere quanto riportato in CONDIZIONI. Selezionare quindi Accetto le condizioni riportate sopra e infine Acquista. Si riceverà una notifica che informa che la distribuzione è in corso. La creazione di un cluster richiede circa 20 minuti.
Se si verifica un problema durante la creazione di cluster HDInsight, è possibile che non si abbiano le autorizzazioni necessarie per eseguire questa operazione. Per altre informazioni, vedere Requisiti di controllo di accesso.
Esaminare le risorse distribuite
Al termine della creazione del cluster, si riceverà una notifica con il messaggio La distribuzione è riuscita e un collegamento Vai alla risorsa. Nella pagina del gruppo di risorse saranno presenti il nuovo cluster HDInsight e l'account di archiviazione predefinito associato. Ogni cluster ha una dipendenza dall'Archiviazione di Azure o da Azure Data Lake Storage Gen2. Viene indicato come account di archiviazione predefinito. Il cluster HDInsight e l'account di archiviazione predefinito devono avere un percorso condiviso nella stessa area di Azure. L'eliminazione dei cluster non comporta l'eliminazione dipendenza dell'account di archiviazione. Viene indicato come account di archiviazione predefinito. Il cluster HDInsight e il relativo account di archiviazione predefinito devono avere un percorso condiviso nella stessa area di Azure. L'eliminazione dei cluster non comporta l'eliminazione dell'account di archiviazione.
Creare un file di Jupyter Notebook
Jupyter Notebook è un ambiente notebook interattivo che supporta diversi linguaggi di programmazione. È possibile usare un file di Jupyter Notebook per interagire con i dati, combinare codice con testo di markdown ed eseguire semplici visualizzazioni.
Apri il portale di Azure.
Selezionare cluster HDInsight e quindi selezionare il cluster creato.
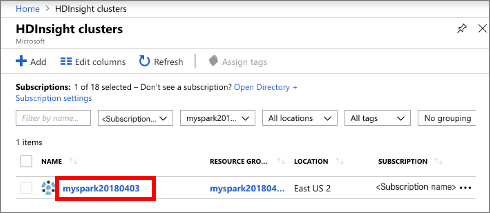
Nella sezione Dashboard cluster del portale selezionare Jupyter Notebook. Se richiesto, immettere le credenziali di accesso del cluster.
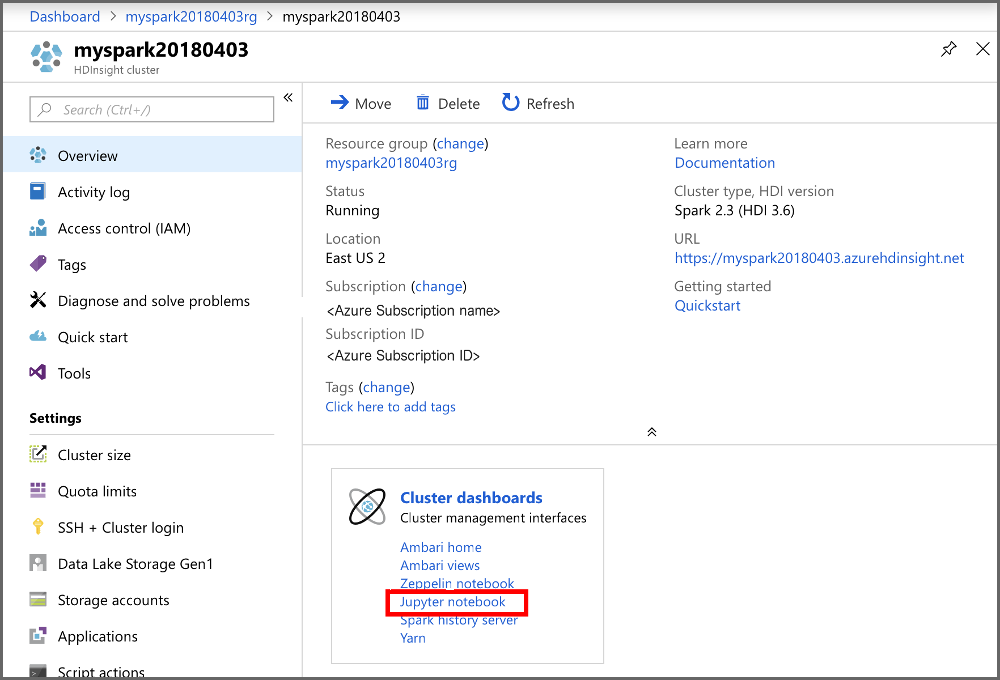
Per creare un notebook selezionare Nuovo>PySpark.
Un nuovo notebook verrà creato e aperto con il nome Untitled (Untitled.pynb).
Eseguire le istruzioni Apache Spark SQL
SQL (Structured Query Language) è il linguaggio più diffuso e più usato per l'esecuzione di query e la trasformazione dei dati. Spark SQL funziona come estensione di Apache Spark per l'elaborazione dei dati strutturati, usando la nota sintassi SQL.
Verificare che il kernel sia pronto. Il kernel è pronto quando accanto al relativo nome nel notebook viene visualizzato un cerchio vuoto. Un cerchio pieno indica che il kernel è occupato.
 alt-text="Kernel status." border="true":::
alt-text="Kernel status." border="true":::Quando si avvia il notebook per la prima volta, il kernel esegue alcune attività in background. Attendere che il kernel sia pronto.
Incollare il codice seguente in una cella vuota e quindi premere MAIUSC + INVIO per eseguire il codice. Il comando elenca le tabelle Hive sul cluster:
%%sql SHOW TABLESQuando si usa un file di Jupyter Notebook con un cluster HDInsight, si ottiene una sessione
sparkpredefinita che è possibile usare per eseguire query Hive con Spark SQL.%%sqlindica a Jupyter Notebook di usare la sessionesparkpredefinita per eseguire la query Hive. La query recupera le prime 10 righe di una tabella Hive (hivesampletable) disponibile per impostazione predefinita in tutti i cluster HDInsight. La prima volta che si invia che la query, Jupyter creerà un'applicazione Spark per il notebook. Questa operazione viene completata in 30 secondi circa. Quando l'applicazione Spark è pronta, la query viene eseguita in un secondo e genera i risultati. L'output sarà simile al seguente: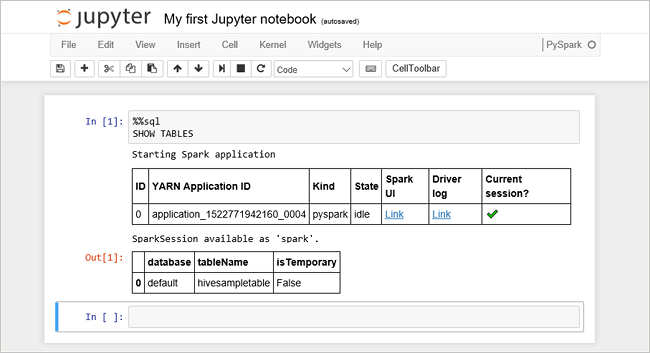 y in HDInsight" border="true":::
y in HDInsight" border="true":::Ogni volta che si esegue una query in Jupyter, il titolo della finestra del Web browser visualizza lo stato (Occupato) accanto al titolo del notebook. È anche visibile un cerchio pieno accanto al testo PySpark nell'angolo in alto a destra.
Eseguire un'altra query per visualizzare i dati in
hivesampletable.%%sql SELECT * FROM hivesampletable LIMIT 10La schermata si aggiornerà per visualizzare l'output della query.
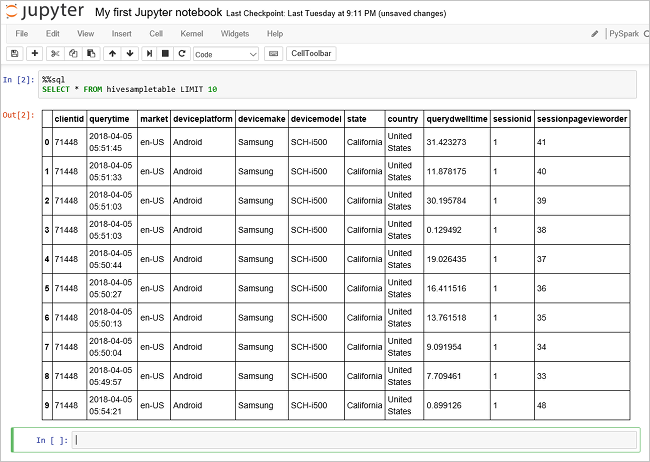 Insight" border="true":::
Insight" border="true":::Nel menu File del notebook fare clic su Close and Halt (Chiudi e interrompi). Quando il notebook viene arrestato, le risorse del cluster vengono rilasciate, inclusa l'applicazione Spark.
Pulire le risorse
Al termine dell'argomento di avvio rapido, può essere opportuno eliminare il cluster. Con HDInsight, i dati vengono archiviati in Archiviazione di Azure ed è possibile eliminare tranquillamente un cluster quando non è in uso. Vengono addebitati i costi anche per i cluster HDInsight che non sono in uso. Poiché i costi per il cluster sono decisamente superiori a quelli per l'archiviazione, eliminare i cluster quando non vengono usati è una scelta economicamente conveniente.
Nel portale di Azure passare al cluster e selezionare Elimina.
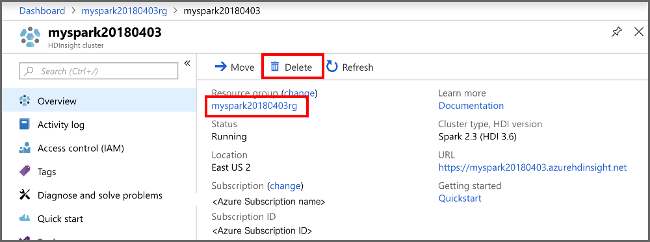 cluster sight" border="true":::
cluster sight" border="true":::
È anche possibile selezionare il nome del gruppo di risorse per aprire la pagina del gruppo di risorse e quindi selezionare Elimina gruppo di risorse. Eliminando il gruppo di risorse, si elimina sia il cluster HDInsight che l'account di archiviazione predefinito.
Passaggi successivi
In questa guida di avvio rapido si è appreso come creare un cluster Apache Spark in HDInsight ed eseguire una query Spark SQL di base. Passare all'esercitazione successiva per imparare come usare un cluster HDInsight per eseguire query interattive su dati di esempio.