Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a: App per la logica di Azure (A consumo e Standard)
Se il flusso di lavoro dell'app per la logica subisce una limitazione, che si verifica quando il numero di richieste supera la velocità che la destinazione può gestire in un determinato periodo di tempo, viene visualizzato l'errore "HTTP 429 Troppe richieste". La limitazione può creare problemi come ritardi nell'elaborazione dei dati, la riduzione della velocità delle prestazioni ed errori come il superamento dei criteri di ripetizione dei tentativi specificati.
Ad esempio, l'azione di SQL Server seguente in un flusso di lavoro A consumo mostra un errore 429 che segnala un problema di limitazione delle richieste:
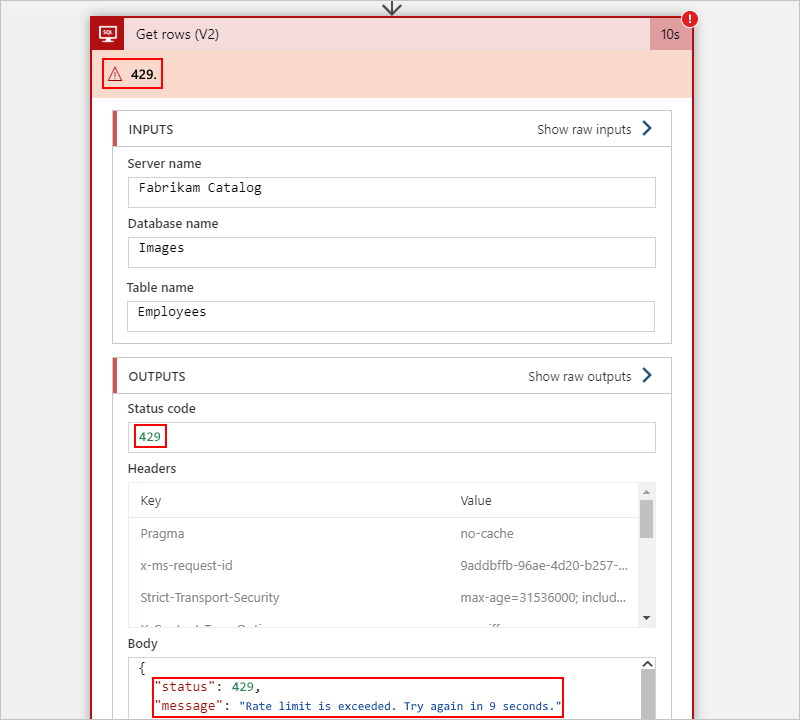
Le sezioni seguenti descrivono i livelli comuni in cui il flusso di lavoro potrebbe riscontrare limitazioni delle richieste:
Limitazione delle risorse dell'app per la logica
App per la logica di Azure ha limiti di velocità effettiva specifici. Se la risorsa dell'app per la logica supera questi limiti, la risorsa dell'app per la logica viene sottoposta a limitazione delle richieste, non solo un'istanza o un'esecuzione specifiche del flusso di lavoro.
Per trovare gli eventi di limitazione delle richieste a questo livello, seguire questa procedura:
Nel portale di Azure aprire la risorsa dell'app per la logica A consumo.
Nel menu della barra laterale della risorsa, in Monitoraggio, selezionare Metriche.
In Titolo grafico selezionare Aggiungi metrica, che aggiunge un'altra barra delle metriche al grafico.
Nella prima barra delle metriche, nell'elenco Metrica, selezionare Eventi con limitazione delle azioni. Nell'elenco Aggregazione selezionare Conteggio.
Nella seconda barra delle metriche, nell'elenco Metrica selezionare Attiva eventi limitati. Nell'elenco Aggregazione selezionare Conteggio.
Il grafico mostra ora gli eventi con limitazione delle richieste per azioni e trigger nel flusso di lavoro dell'app per la logica. Per altre informazioni, vedere Visualizzare le metriche per l'integrità e le prestazioni del flusso di lavoro nelle App per la logica di Azure.
Per gestire la limitazione delle richieste a questo livello, sono disponibili le opzioni seguenti:
Limitare il numero di istanze del flusso di lavoro che possono essere eseguite contemporaneamente.
Per impostazione predefinita, se la condizione del trigger del flusso di lavoro viene soddisfatta più volte contemporaneamente, più istanze del trigger vengono attivate ed eseguite simultaneamente o in parallelo. Ogni istanza del trigger viene attivata prima di completare l'esecuzione dell'istanza del flusso di lavoro precedente.
Anche se il numero predefinito di istanze di trigger che possono essere eseguite contemporaneamente è illimitato, è possibile limitare questo numero attivando l'impostazione di concorrenza del trigger e, se necessario, selezionare un limite diverso dal valore predefinito.
Abilitare la modalità velocità effettiva elevata .
Un flusso di lavoro A consumo ha un limite predefinito per il numero di azioni che possono essere eseguite in un intervallo di 5 minuti. Per aumentare questo limite al numero massimo di azioni, attivare la modalità velocità effettiva elevata nella risorsa dell'app per la logica.
Un flusso di lavoro Standard non prevede limiti al numero di azioni che possono essere eseguite durante un intervallo.
Disabilitare la scomposizione batch della matrice o l'impostazione Dividi nei trigger.
Se un trigger restituisce una matrice per le azioni rimanenti del flusso di lavoro da elaborare, l'impostazione Dividi del trigger divide gli elementi della matrice e avvia un'istanza del flusso di lavoro per ogni elemento della matrice. Questo comportamento attiva in modo efficace più esecuzioni simultanee fino al limite dividi.
Per controllare la limitazione delle richieste, disattivare l'impostazione Dividi del trigger e fare in modo che l'intero flusso di lavoro elabori l'intera matrice con una singola chiamata, anziché gestire un singolo elemento per ogni chiamata.
Eseguire il refactoring delle azioni in diversi flussi di lavoro più piccoli.
Come accennato in precedenza, un flusso di lavoro dell'app per la logica A consumo è limitato a un numero predefinito di azioni che possono essere eseguite in un periodo di 5 minuti. Sebbene sia possibile aumentare questo limite abilitando la modalità velocità effettiva elevata, è anche possibile valutare se si desidera suddividere le azioni del flusso di lavoro in flussi di lavoro più piccoli in modo che il numero di azioni eseguite in ogni flusso di lavoro rimanga inferiore al limite. In questo modo, si riduce il carico su un singolo flusso di lavoro e si distribuisce il carico tra più flussi di lavoro. Questa soluzione funziona meglio per le azioni che gestiscono set di dati di grandi dimensioni o attivano così tante azioni in esecuzione contemporaneamente, iterazioni di cicli o azioni all'interno di ogni iterazione di ciclo che superano il limite di esecuzione dell'azione.
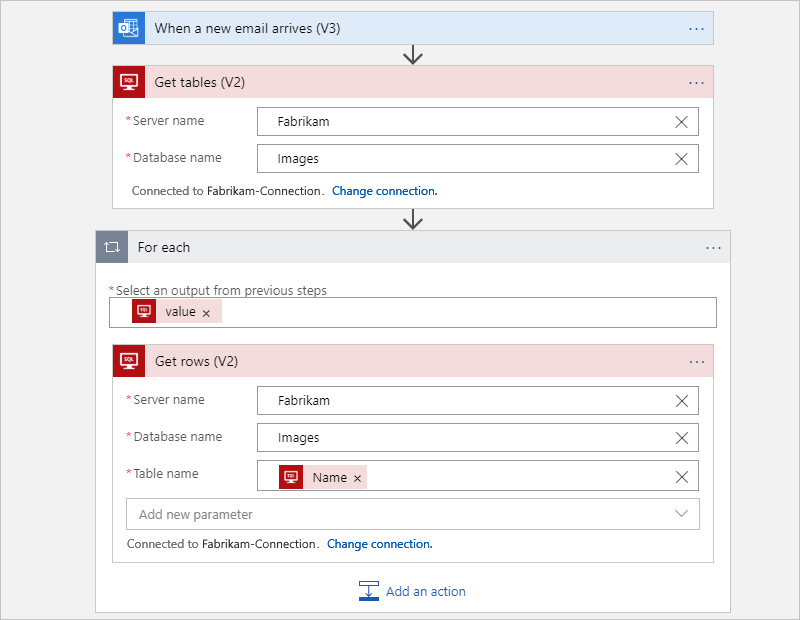
Ad esempio, il flusso di lavoro A consumo seguente esegue tutto il lavoro per ottenere tabelle da un database di SQL Server e ottiene le righe da ogni tabella. Il ciclo Per ciascuna esegue contemporaneamente l'iterazione di ogni tabella in modo che l'azione Ottieni righe restituisca le righe per ogni tabella. In base alle quantità di dati in tali tabelle, queste azioni potrebbero superare il limite per le esecuzioni di azioni.
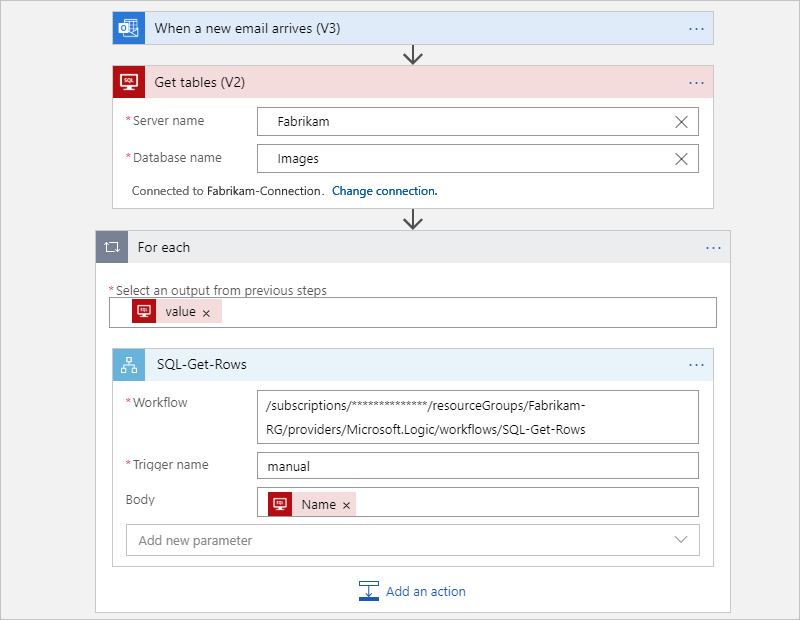
Dopo il refactoring, il flusso di lavoro originale viene suddiviso in un flusso di lavoro padre e un flusso di lavoro figlio.
Il flusso di lavoro padre seguente ottiene le tabelle da SQL Server e quindi chiama il flusso di lavoro figlio per ogni tabella, per ottenere le righe:
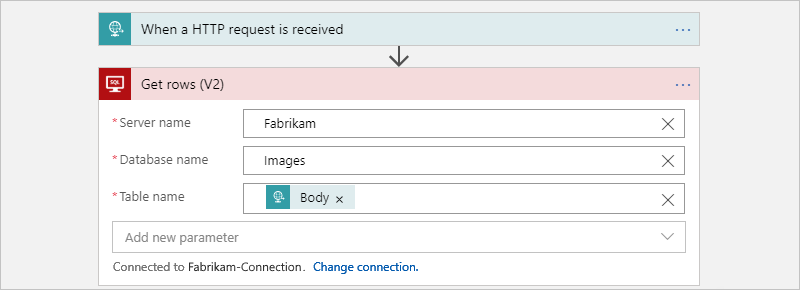
Il flusso di lavoro figlio seguente viene chiamato dal flusso di lavoro padre per ottenere le righe per ogni tabella:
Limitazione delle richieste connettori
Ogni connettore ha limiti di limitazione specifici, disponibili nella pagina di riferimento tecnica di ogni connettore. Ad esempio, il connettore del bus di servizio di Azure ha un limite di limitazione che consente fino a 6.000 chiamate al minuto, mentre il connettore SQL Server ha limiti di limitazione che variano in base al tipo di operazione.
Alcuni trigger e azioni, ad esempio HTTP, hanno un criterio di ripetizione dei tentativi che è possibile personalizzare in base ai limiti dei criteri di ripetizione dei tentativi per implementare la gestione delle eccezioni. Questo criterio specifica se e con quale frequenza un trigger o un'azione ritenta una richiesta quando la richiesta originale ha esito negativo o raggiunge il timeout e restituisce una risposta 408, 429 o 5xx. Pertanto, quando inizia la limitazione delle richieste e restituisce un errore 429, App per la logica segue i criteri di ripetizione dei tentativi, se supportati.
Per sapere se un trigger o un'azione supporta i criteri di retry, controllare le impostazioni del trigger o dell'azione. Per visualizzare i tentativi di un trigger o di un'azione, passare alla cronologia di esecuzione del flusso di lavoro dell'app per la logica, selezionare l'esecuzione da rivedere ed espandere tale trigger o azione per visualizzare i dettagli sugli input, sugli output e sui tentativi.
L'esempio di flusso di lavoro A consumo seguente mostra dove è possibile trovare queste informazioni per un'azione HTTP:
Screenshot che mostra il flusso di lavoro del Consumo con la cronologia di esecuzione, i tentativi, gli input e gli output di un'azione HTTP.
Anche se la cronologia dei retry fornisce informazioni sugli errori, è possibile che si verifichino problemi di differenziazione tra la limitazione dei connettori e la limitazione della destinazione. In questo caso, potrebbe essere necessario esaminare i dettagli della risposta o eseguire alcuni calcoli dell'intervallo di limitazione delle richieste per identificare l'origine.
Per i flussi di lavoro delle app per la logica A consumo in App per la logica di Azure multi-tenant, la limitazione avviene a livello di connessione.
Per gestire la limitazione delle richieste a questo livello, sono disponibili le opzioni seguenti:
Configurare più connessioni per una singola azione in modo che il flusso di lavoro possa eseguire la partizione dei dati per l'elaborazione.
Valutare se è possibile distribuire il carico di lavoro dividendo le richieste di un'azione tra più connessioni alla stessa destinazione usando le stesse credenziali.
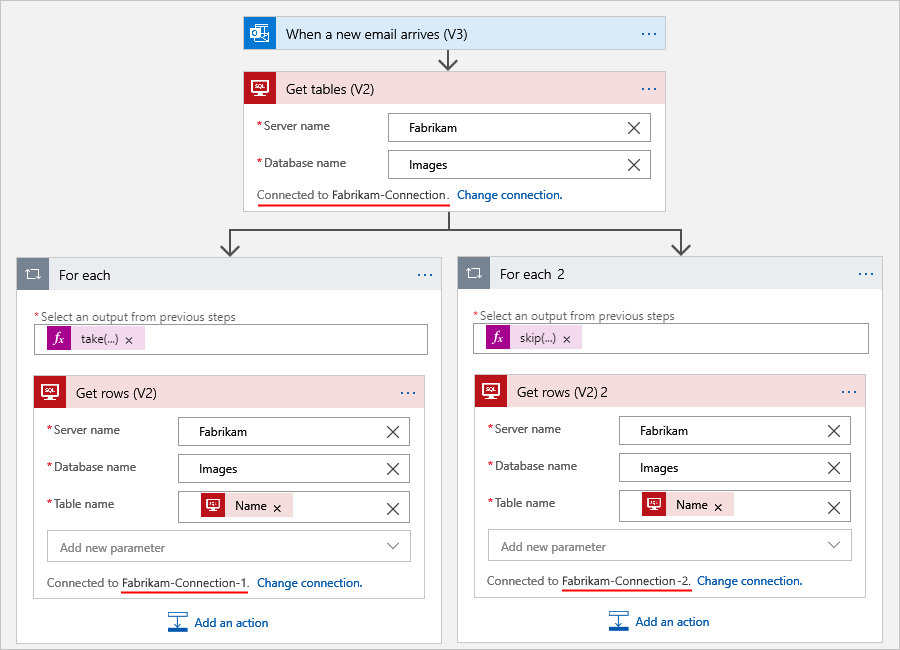
Si supponga, ad esempio, che il flusso di lavoro ottenga tabelle da un database di SQL Server e quindi ottenga le righe da ogni tabella. In base al numero di righe da elaborare, è possibile usare più connessioni e più cicli Per ciascuna per dividere il numero totale di righe in set più piccoli per l'elaborazione. Questo scenario usa due cicli Per ciascuna per suddividere il numero totale di righe in metà. Il primo ciclo Per ciascuna usa un'espressione che ottiene la prima metà. L'altro ciclo Per ciascuna usa un'espressione diversa che ottiene la seconda metà, ad esempio:
Espressione 1: la funzione
take()ottiene la parte anteriore di una raccolta. Per altre informazioni, vedere latake()funzione.@take(collection-or-array-name, div(length(collection-or-array-name), 2))Espressione 2: la funzione
skip()rimuove la parte anteriore di una raccolta e restituisce tutti gli altri elementi. Per altre informazioni, vedere laskip()funzione.@skip(collection-or-array-name, div(length(collection-or-array-name), 2))L'esempio di flusso di lavoro A consumo seguente illustra come usare queste espressioni:
Configurare una connessione diversa per ogni azione.
Valutare se è possibile distribuire il carico di lavoro distribuendo le richieste di ogni azione tramite la specifica connessione, anche quando le azioni si connettono allo stesso servizio o sistema e usano le stesse credenziali.
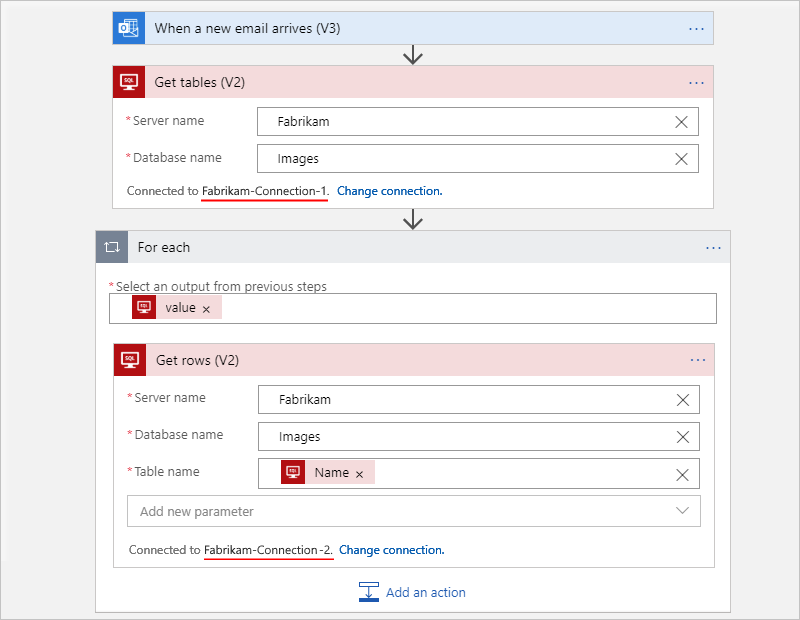
Si supponga, ad esempio, che il flusso di lavoro ottenga le tabelle da un database di SQL Server e ottenga ogni riga in ogni tabella. È possibile usare connessioni separate in modo che l'azione Recupera tabelle usi una connessione, mentre l'azione Recupera righe usa un'altra connessione.
L'esempio seguente mostra un flusso di lavoro A consumo che crea e usa una connessione diversa per ogni azione:
Modificare la concorrenza o il parallelismo del ciclo For each.
Per impostazione predefinita, le iterazioni del ciclo For each vengono eseguite contemporaneamente fino al limite di concorrenza. Se si dispone di una connessione che viene limitata all'interno di un ciclo Per ciascuna, è possibile ridurre il numero di iterazioni del ciclo eseguite in parallelo. Per altre informazioni, vedere la documentazione seguente:
Cicli Per ciascuna: modificare la concorrenza o eseguire in sequenza
Schema del linguaggio di definizione del flusso di lavoro - Per ogni ciclo
Schema del linguaggio di definizione del flusso di lavoro - Modifica per ogni concorrenza del ciclo
Schema del linguaggio di definizione del flusso di lavoro - Eseguire Per ciascuna in sequenza
Limitazione delle richieste del servizio o del sistema di destinazione
Anche se un connettore ha limiti di limitazione delle richieste specifici, il servizio o il sistema di destinazione o chiamato dal connettore potrebbe anche avere limiti di limitazione delle richieste. Ad esempio, alcune API in Microsoft Exchange Server hanno limiti di limitazione delle richieste più restrittivi rispetto al connettore di Microsoft Office 365 Outlook.
Per impostazione predefinita, le istanze del flusso di lavoro di un'app per la logica e tutti i cicli o i rami all'interno di tali istanze vengono eseguiti in parallelo. Questo comportamento indica che più istanze possono chiamare lo stesso endpoint contemporaneamente. Ogni istanza non conosce l'esistenza dell'altra, quindi i tentativi di ripetizione di azioni non riuscite possono creare race condition in cui più chiamate tentano di eseguire contemporaneamente, ma per avere esito positivo, tali chiamate devono arrivare al servizio di destinazione o al sistema prima che la limitazione delle richieste inizi a verificarsi.
Si supponga, ad esempio, di avere una matrice con 100 elementi. Si usa un ciclo For each per scorrere la matrice e attivare il controllo di concorrenza del ciclo in modo da limitare il numero di iterazioni parallele a 20 o al limite predefinito corrente. All'interno di tale ciclo, un'azione inserisce un elemento dalla matrice in un database di SQL Server, che consente solo 15 chiamate al secondo. Questo scenario comporta un problema di limitazione delle richieste perché viene compilato un backlog di tentativi e non viene mai eseguito.
La tabella seguente descrive la sequenza temporale per ciò che accade nel ciclo quando l'intervallo tra tentativi dell'azione è di 1 secondo:
| Temporizzazione | Numero di azioni in esecuzione | Numero di azioni che hanno esito negativo | Numero di tentativi in attesa |
|---|---|---|---|
| T + 0 secondi | 20 inserimenti | 5 con esito negativo a causa del limite SQL | 5 tentativi |
| T + 0,5 secondi | 15 inserimenti dovuti ai 5 tentativi precedenti in attesa | Tutti i 15 hanno esito negativo a causa del limite SQL precedente ancora in vigore per altri 0,5 secondi | 20 tentativi (precedente 5 + 15 nuovi) |
| T + 1 secondo | 20 inserimenti | 5 errori più 20 tentativi di ripetizione precedenti, a causa del limite SQL | 25 tentativi (precedenti 20 + 5 nuovi) |
Per gestire la limitazione delle richieste a questo livello, sono disponibili le opzioni seguenti:
Creare singoli flussi di lavoro in modo che ognuno gestisca una singola operazione.
Continuando con lo scenario di SQL Server di esempio in questa sezione, è possibile creare un flusso di lavoro che inserisce gli elementi della matrice in una coda, ad esempio una Coda del bus di servizio di Azure. Si crea quindi un altro flusso di lavoro che esegue solo l'operazione di inserimento per ogni elemento in tale coda. In questo modo, viene eseguita una sola istanza del flusso di lavoro in un qualsiasi momento specifico, che completa l'operazione di inserimento e passa all'elemento successivo nella coda, oppure l'istanza ottiene errori 429, ma non tenta tentativi non produttivi.
Creare un flusso di lavoro padre che chiama un flusso di lavoro figlio o annidato per ogni azione. Se l'elemento padre deve chiamare flussi di lavoro figlio diversi in base al risultato dell'elemento padre, è possibile usare un'azione condizione o un'azione switch che determina il flusso di lavoro figlio da chiamare. Questo modello consente di ridurre il numero di chiamate o operazioni.
Si supponga, ad esempio, di avere due flussi di lavoro, ognuno con un trigger di polling che controlla l'account di posta elettronica ogni minuto per un oggetto specifico, ad esempio "Operazione riuscita" o "Errore". Questa configurazione restituisce 120 chiamate all'ora. Se invece si crea un singolo flusso di lavoro padre che esegue il polling ogni minuto, ma chiama un flusso di lavoro figlio che viene eseguito in base al fatto che l'oggetto sia "Operazione riuscita" o "Errore", si taglia il numero di controlli di polling a metà, o in questo caso a 60.
Impostare l'elaborazione batch (solo per i flussi di lavoro di consumo).
Se il servizio di destinazione supporta le operazioni batch, è possibile risolvere la limitazione delle richieste elaborando gli elementi in gruppi o batch anziché singolarmente. Per implementare la soluzione di elaborazione batch, si crea un flusso di lavoro dell'app per la logica del ricevitore batch e un flusso di lavoro dell'app per la logica del mittente batch . Il mittente del batch raccoglie messaggi o elementi fino a quando non vengono soddisfatti i criteri specificati e quindi li invia in un singolo gruppo. Il ricevitore batch accetta tale gruppo ed elabora tali messaggi o elementi. Per altre informazioni, vedere Inviare, ricevere ed elaborare messaggi batch in App per la logica di Azure.
Usare le versioni del webhook per trigger e azioni, anziché le versioni di polling.
Perché? Un trigger di polling continua a controllare il servizio o il sistema di destinazione a intervalli specifici. Un intervallo molto frequente, ad esempio ogni secondo, può creare problemi di limitazione delle richieste. Tuttavia, un trigger o un'azione webhook, ad esempio webhook HTTP, crea solo una singola chiamata al servizio o al sistema di destinazione, che avviene in fase di sottoscrizione e richiede che la destinazione notifica il trigger o l'azione solo quando si verifica un evento. In questo modo, il trigger o l'azione non deve controllare continuamente la destinazione.
Pertanto, se il servizio o il sistema di destinazione supporta webhook o fornisce un connettore con una versione webhook, questa opzione è preferibile rispetto all'uso della versione di polling. Per identificare i trigger e le azioni del webhook, verificare che abbiano il tipo
ApiConnectionWebhooko che non richiedano di specificare una ricorrenza. Per altre informazioni, vedere Trigger ApiConnectionWebhook e Azione ApiConnectionWebhook.