Guida di avvio rapido: data wrangling interattivo con Apache Spark in Azure Machine Learning
Per gestire il data wrangling interattivo dei notebook di Azure Machine Learning, l'integrazione di Azure Machine Learning con Azure Synapse Analytics consente di accedere facilmente al framework Apache Spark. Questo accesso consente il data wrangling interattivo del notebook Azure Machine Learning.
Questa guida introduttiva illustra come eseguire il wrangling dei dati interattivi con il calcolo Spark serverless di Azure Machine Learning, l'account di archiviazione azure Data Lake Archiviazione (ADLS) Gen 2 e il pass-through dell'identità utente.
Prerequisiti
- Una sottoscrizione di Azure; se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare.
- Un'area di lavoro di Azure Machine Learning. Vedere Creare risorse dell'area di lavoro.
- Un account di archiviazione di Azure Data Lake Storage (ADLS) Gen 2. Vedere Creare un account di archiviazione di Azure Data Lake Archiviazione (ADLS) Gen 2.
Archiviare le credenziali dell'account di archiviazione di Azure come segreti in Azure Key Vault
Per archiviare le credenziali dell'account di archiviazione di Azure come segreti in Azure Key Vault, con l'interfaccia utente portale di Azure:
Passare all'insieme di credenziali delle chiavi di Azure nel portale di Azure
Selezionare Segreti nel pannello sinistro
Selezionare + Genera/Importa
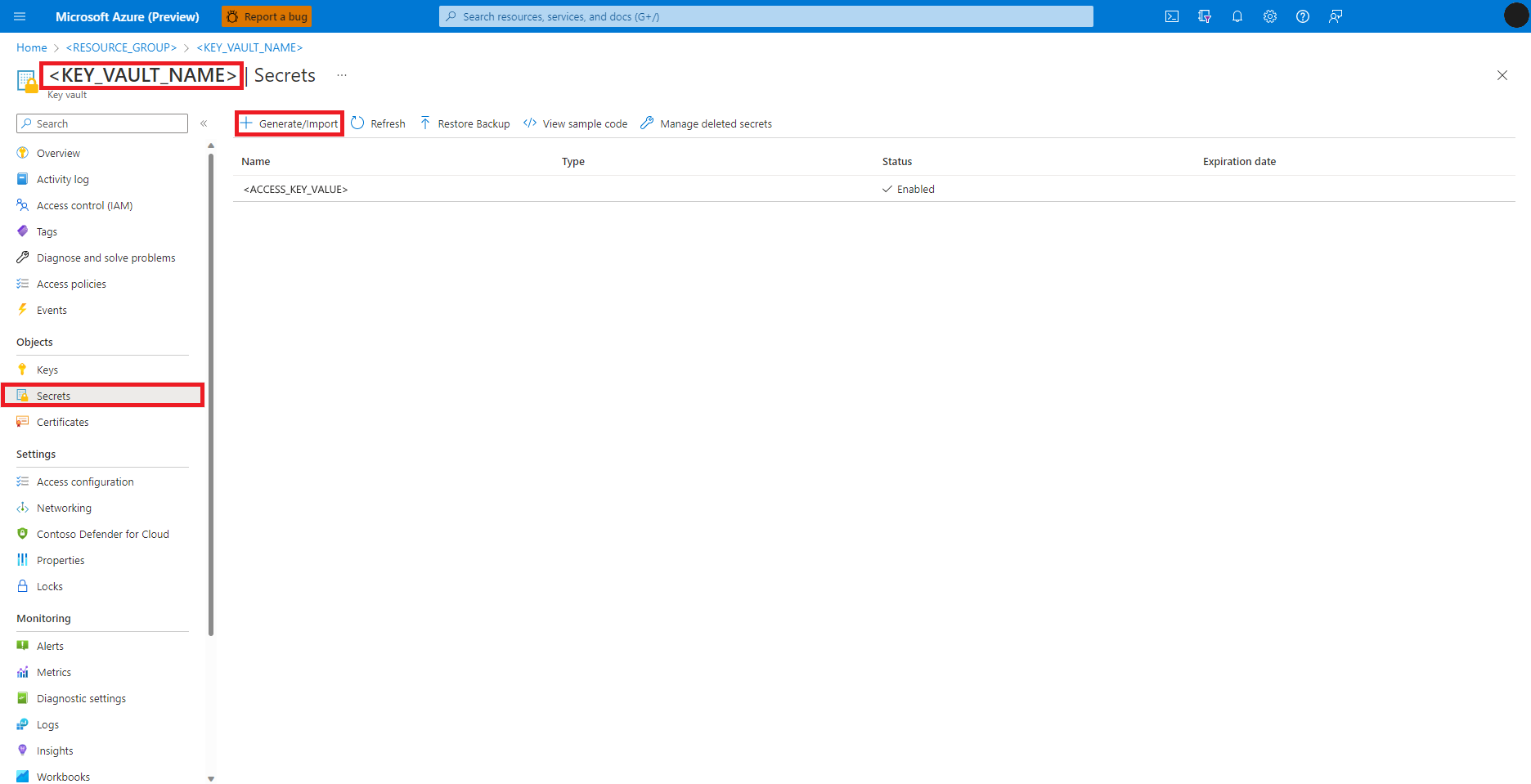
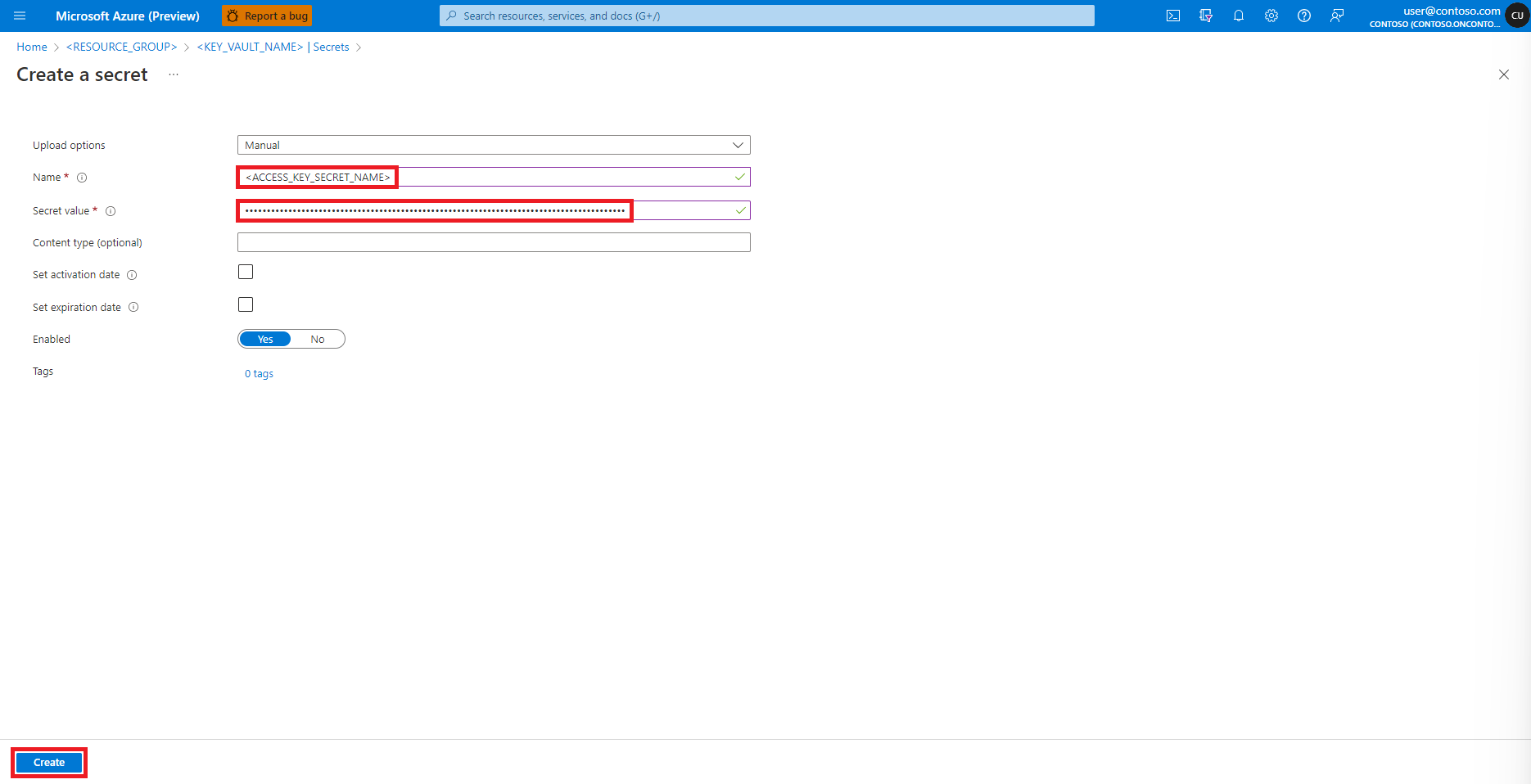
Nella schermata Crea un segreto immettere un nome per il segreto che si vuole creare
Passare a Archiviazione BLOB di Azure Account, nella portale di Azure, come illustrato in questa immagine:
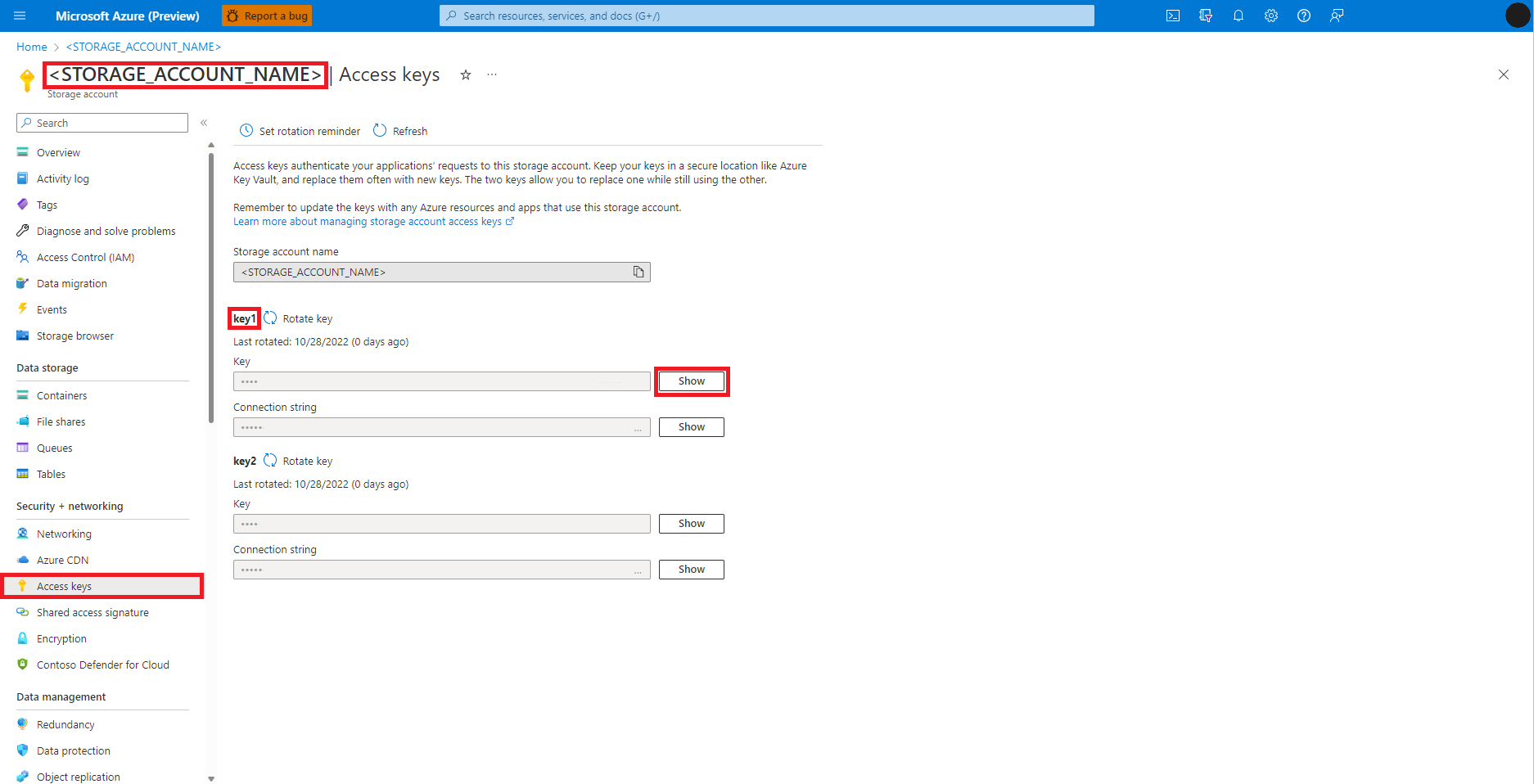
Selezionare Chiavi di accesso nel pannello sinistro della pagina account Archiviazione BLOB di Azure
Selezionare Mostra accanto alla chiave 1 e quindi Copia negli Appunti per ottenere la chiave di accesso dell'account di archiviazione
Nota
Selezionare le opzioni appropriate da copiare
- Token di firma di accesso condiviso del contenitore di archiviazione BLOB di Azure
- Credenziali dell'entità servizio dell'account di archiviazione di Azure Data Lake Storage (ADLS) Gen 2
- ID del tenant
- ID client e
- secret
nelle rispettive interfacce utente durante la creazione dei segreti di Azure Key Vault
Tornare alla schermata Crea un segreto
Nella casella di testo Valore segreto immettere le credenziali della chiave di accesso per l'account di archiviazione di Azure, copiato negli Appunti nel passaggio precedente
Selezionare Crea.
Suggerimento
L'interfaccia della riga di comando di Azure e la libreria client dei segreti di Azure Key Vault per Python possono anche creare segreti di Azure Key Vault.
Aggiungere assegnazioni di ruolo negli account di archiviazione di Azure
È necessario assicurarsi che i percorsi di dati di input e output siano accessibili prima di avviare il data wrangling interattivo. In primo luogo, per
l'identità utente della sessione Notebooks che ha eseguito l'accesso
or
Un'entità servizio
per assegnare i ruoli di Lettore e Lettore dei dati del BLOB di archiviazione all'identità utente dell'utente connesso. In alcuni scenari, tuttavia, potrebbe essere necessario scrivere nuovamente i dati scelti nell'account di archiviazione di Azure. I ruoli Lettore e Lettore dei dati del BLOB di archiviazione forniscono l'accesso in sola lettura all'identità utente o all'entità servizio. Per abilitare l'accesso in lettura e scrittura, assegnare i ruoli Collaboratore e Collaboratore ai dati dei BLOB di archiviazione all'identità utente o all'entità servizio. Per assegnare ruoli appropriati all'identità utente:
Aprire microsoft portale di Azure
Cercare e selezionare il servizio account Archiviazione

Nella pagina Account di archiviazione selezionare l'account di archiviazione di Azure Data Lake Storage (ADLS) Gen 2 nell'elenco. Verrà visualizzata una pagina che mostra la panoramica dell'account di archiviazione

Selezionare Controllo di accesso (IAM) nel pannello a sinistra
Selezionare Aggiungi assegnazione di ruolo

Trovare e selezionare il ruolo Collaboratore ai dati dei BLOB di archiviazione
Selezionare Avanti.
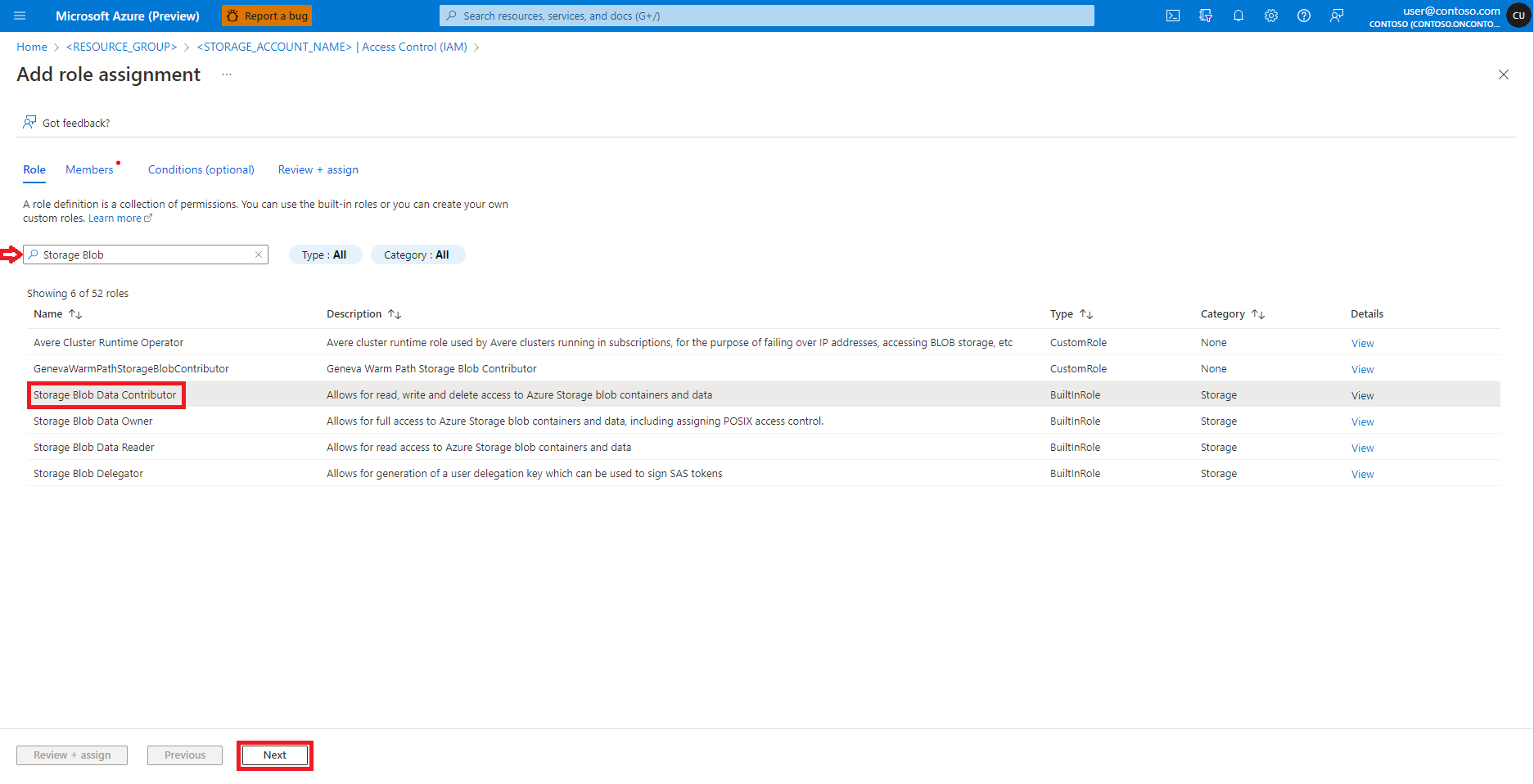
Selezionare Utente, gruppo o entità servizio
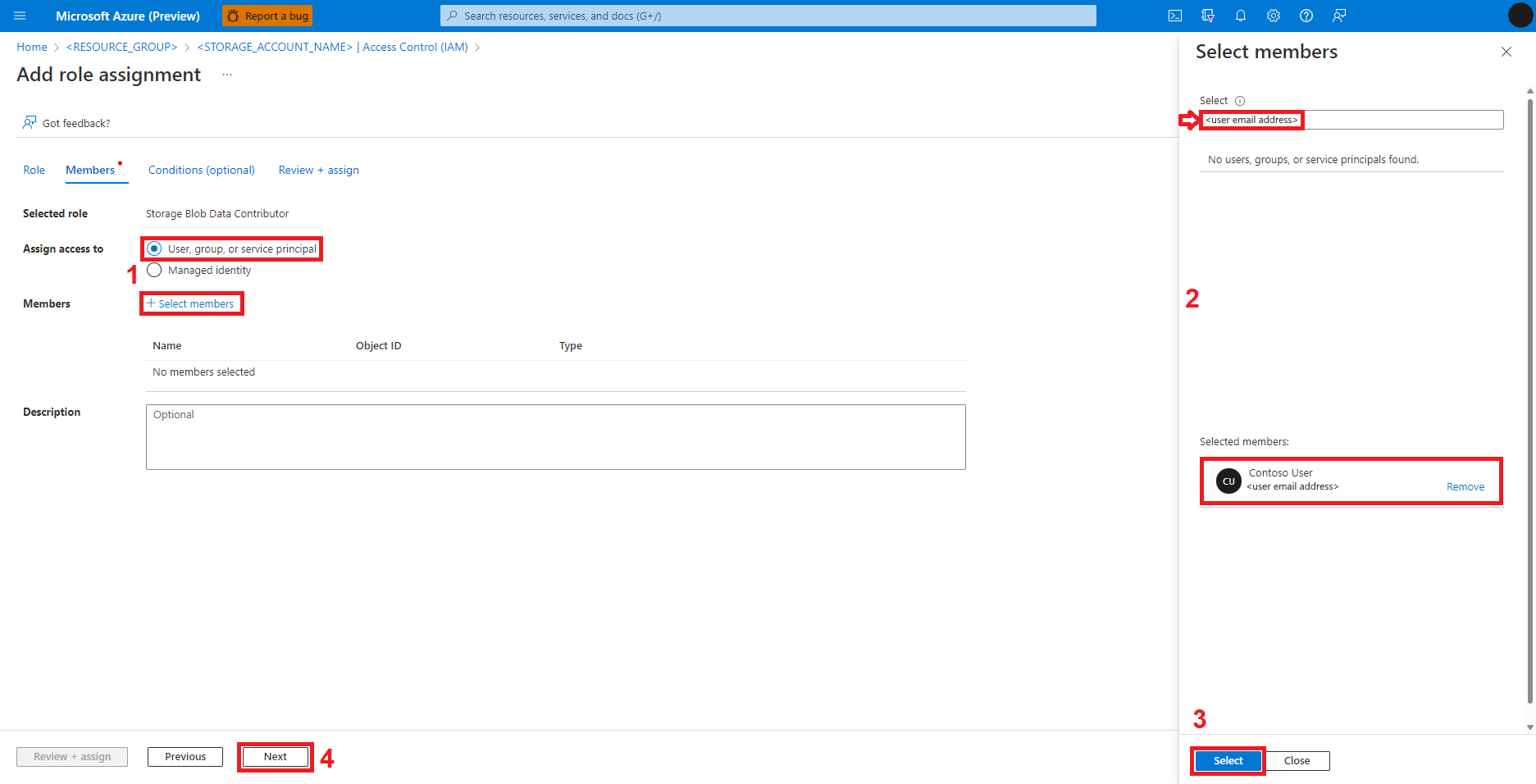
Selezionare + Seleziona membri
Cercare l'identità utente sotto Seleziona
Selezionare l'identità utente nell'elenco, in modo che venga visualizzata in Membri selezionati
Selezionare l'identità utente appropriata
Selezionare Avanti.
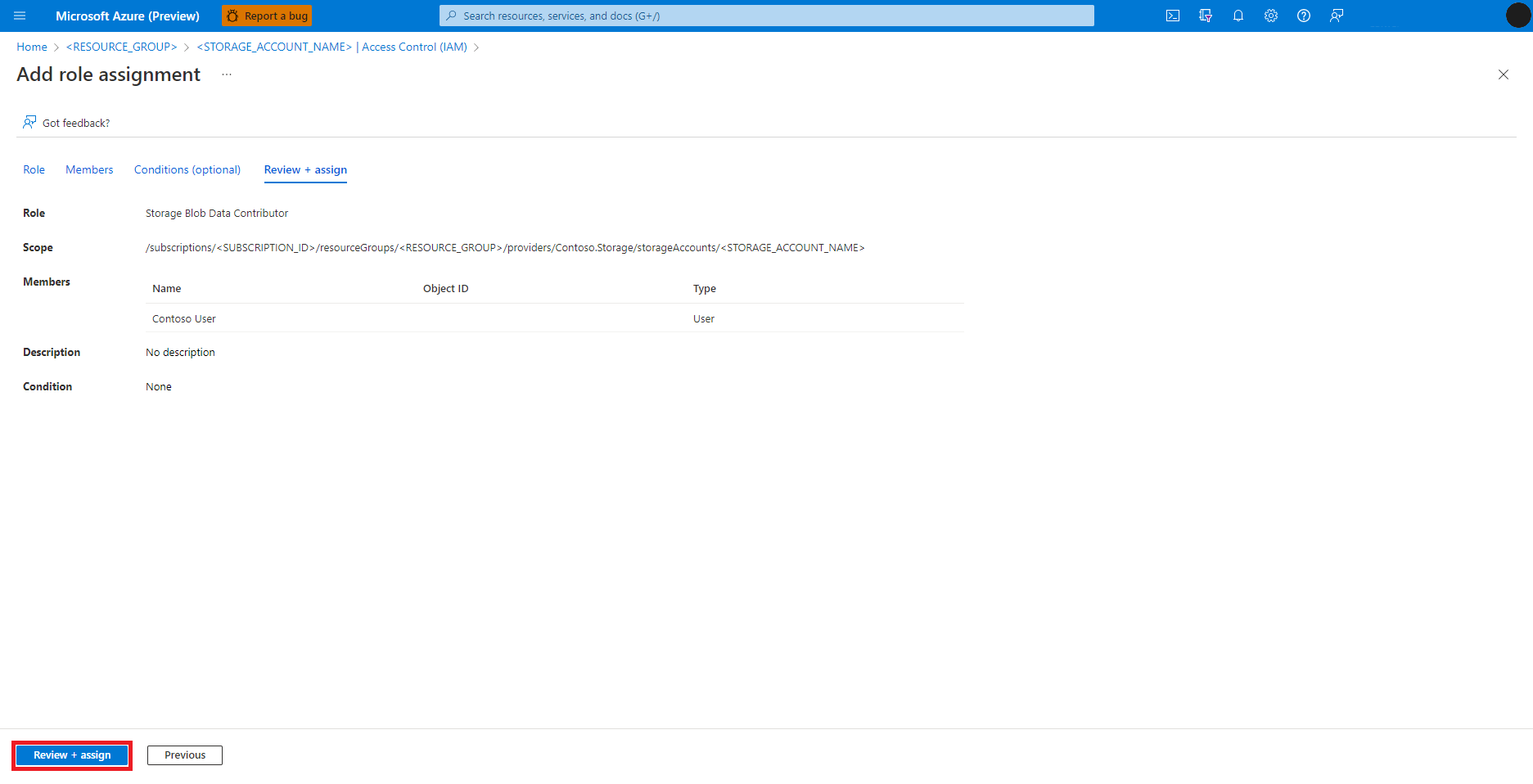
Selezionare Rivedi e assegna
Ripetere i passaggi da 2 a 13 per l'assegnazione di ruolo Collaboratore






Una che l'identità utente ha i ruoli appropriati assegnati, i dati nell'account di archiviazione di Azure devono diventare accessibili.
Nota
Se un pool di Synapse Spark collegato punta a un pool di Synapse Spark, in un'area di lavoro di Azure Synapse, a cui è associata una rete virtuale gestita, è necessario configurare un endpoint privato gestito in un account di archiviazione per garantire l'accesso ai dati.
Garantire l'accesso alle risorse per i processi Spark
Per accedere ai dati e ad altre risorse, i processi Spark possono usare un'identità gestita o un pass-through identità utente. La tabella seguente riepiloga i diversi meccanismi per l'accesso alle risorse mentre si usa il calcolo Spark serverless di Azure Machine Learning e il pool di Spark collegato synapse.
| Pool Spark | Identità supportate | Identità predefinita |
|---|---|---|
| Calcolo Spark serverless | Identità utente, identità gestita assegnata dall'utente collegata all'area di lavoro | Identità utente |
| Pool di Spark Synapse collegato | Identità utente, identità gestita assegnata dall'utente collegata al pool di Spark synapse collegato, identità gestita assegnata dal sistema del pool di Spark synapse collegato | Identità gestita assegnata dal sistema del pool di Spark synapse collegato |
Se il codice dell'interfaccia della riga di comando o del Software Development Kit (SDK) definisce un'opzione per l'uso dell'identità gestita, il calcolo Spark serverless di Azure Machine Learning si basa su un'identità gestita assegnata dall'utente collegata all'area di lavoro. È possibile collegare un'identità gestita assegnata dall'utente a un'area di lavoro di Azure Machine Learning esistente con l'interfaccia della riga di comando di Azure Machine Learning v2 o con ARMClient.
Passaggi successivi
- Apache Spark in Azure Machine Learning
- Collegare e gestire un pool di Spark Synapse in Azure Machine Learning
- Data wrangling interattivo con Apache Spark in Azure Machine Learning
- Inviare processi Spark in Azure Machine Learning
- Esempi di codice per i processi Spark con l'interfaccia della riga di comando di Azure Machine Learning
- Esempi di codice per i processi Spark con Azure Machine Learning Python SDK
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per