Endpoint per l'inferenza nell'ambiente di produzione
SI APPLICA A: Estensione ml dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Estensione ml dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Dopo aver eseguito il training di modelli o pipeline di apprendimento automatico o aver trovato modelli dal catalogo dei modelli in base alle proprie esigenze, è necessario distribuirli nell'ambiente di produzione in modo che altri utenti possano usarli per l'inferenza. L'inferenza è il processo di applicazione di nuovi dati di input a un modello o a una pipeline di Machine Learning per generare output. Anche se questi output vengono in genere definiti "previsioni", l'inferenza può essere usata per generare output per altre attività di Machine Learning, come la classificazione e il clustering. In Azure Machine Learning, si esegue l'inferenza usando endpoint .
Endpoint e distribuzioni
Un endpoint è un URL stabile e durevole che può essere usato per richiedere o richiamare un modello. Vengono forniti gli input necessari per l'endpoint e vengono restituiti gli output. Azure Machine Learning consente di implementare endpoint API serverless, endpoint onlinee endpoint batch. Un endpoint fornisce:
- un URL stabile e durevole (ad esempio endpoint-name.region.inference.ml.azure.com),
- un meccanismo di autenticazione e
- un meccanismo di autorizzazione.
Una distribuzione è un set di risorse e ambienti di calcolo necessari per ospitare il modello o un componente che esegue l'inferenza effettiva. Un endpoint contiene una distribuzione e per gli endpoint online e batch, un endpoint può contenere diverse distribuzioni. Le distribuzioni possono ospitare asset indipendenti e utilizzare risorse diverse in base alle esigenze degli asset. Inoltre, un endpoint online ha un meccanismo di routing che può indirizzare le richieste a qualsiasi distribuzione.
Da un lato, alcuni tipi di endpoint in Azure Machine Learning usano risorse dedicate nelle distribuzioni. Affinché questi endpoint vengano eseguiti, è necessario disporre della quota di calcolo nella sottoscrizione di Azure. D'altra parte, alcuni modelli supportano una distribuzione serverless, consentendo loro di non utilizzare alcuna quota dalla sottoscrizione. Per la distribuzione serverless, vengono fatturati in base all'utilizzo.
Intuizione
Si supponga di lavorare su un'applicazione che prevede il tipo e il colore di un'auto, data la foto. Per questa applicazione, un utente con determinate credenziali effettua una richiesta HTTP a un URL e fornisce un'immagine di un'automobile come parte della richiesta. In cambio, l'utente ottiene una risposta che include il tipo e il colore dell'auto come valori stringa. In questo scenario, l'URL funge da endpoint.
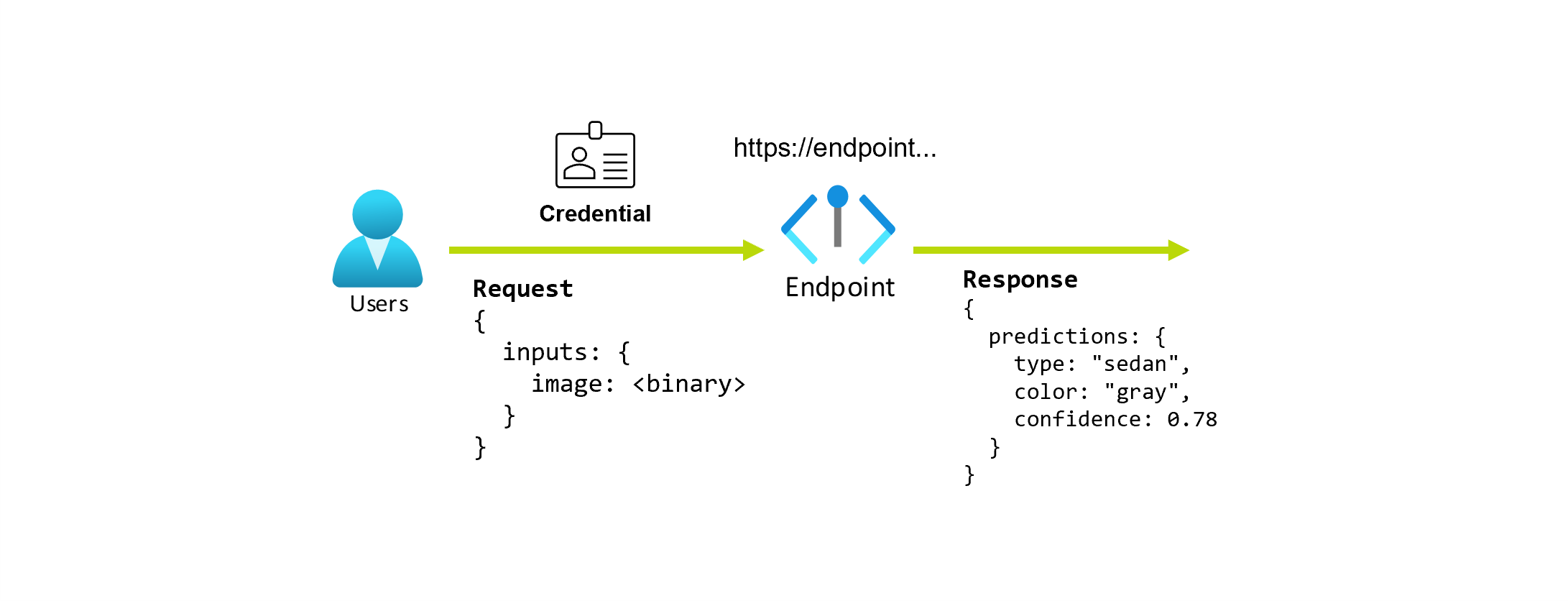
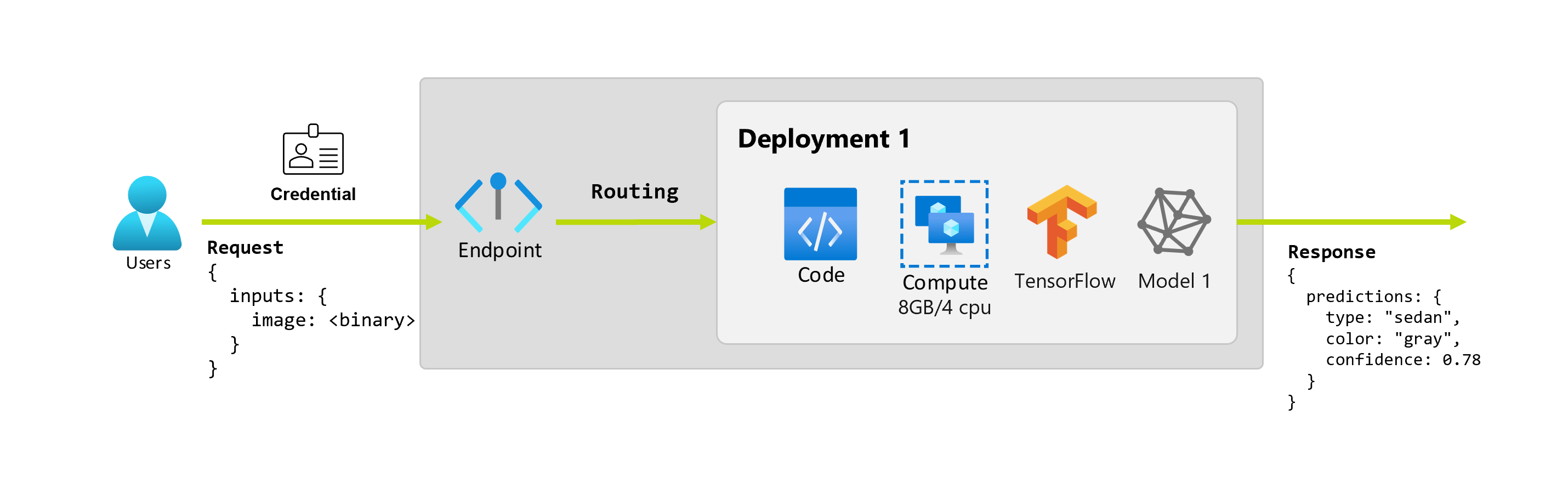
Si supponga inoltre che una scienziata dei dati, Martina, stia lavorando all'implementazione dell'applicazione. Martina conosce bene TensorFlow e decide di implementare il modello usando un classificatore sequenziale Keras con un'architettura RestNet dall'hub TensorFlow. Dopo averlo testato, Martina è soddisfatta dei risultati e decide di usare il modello per risolvere il problema di previsione dell'auto. Il modello è di grandi dimensioni e richiede 8 GB di memoria con 4 core per essere eseguito. In questo scenario, il modello e le risorse di Martina, ad esempio il codice e il calcolo, necessari per eseguire il modello costituiscono una distribuzione sotto l'endpoint.
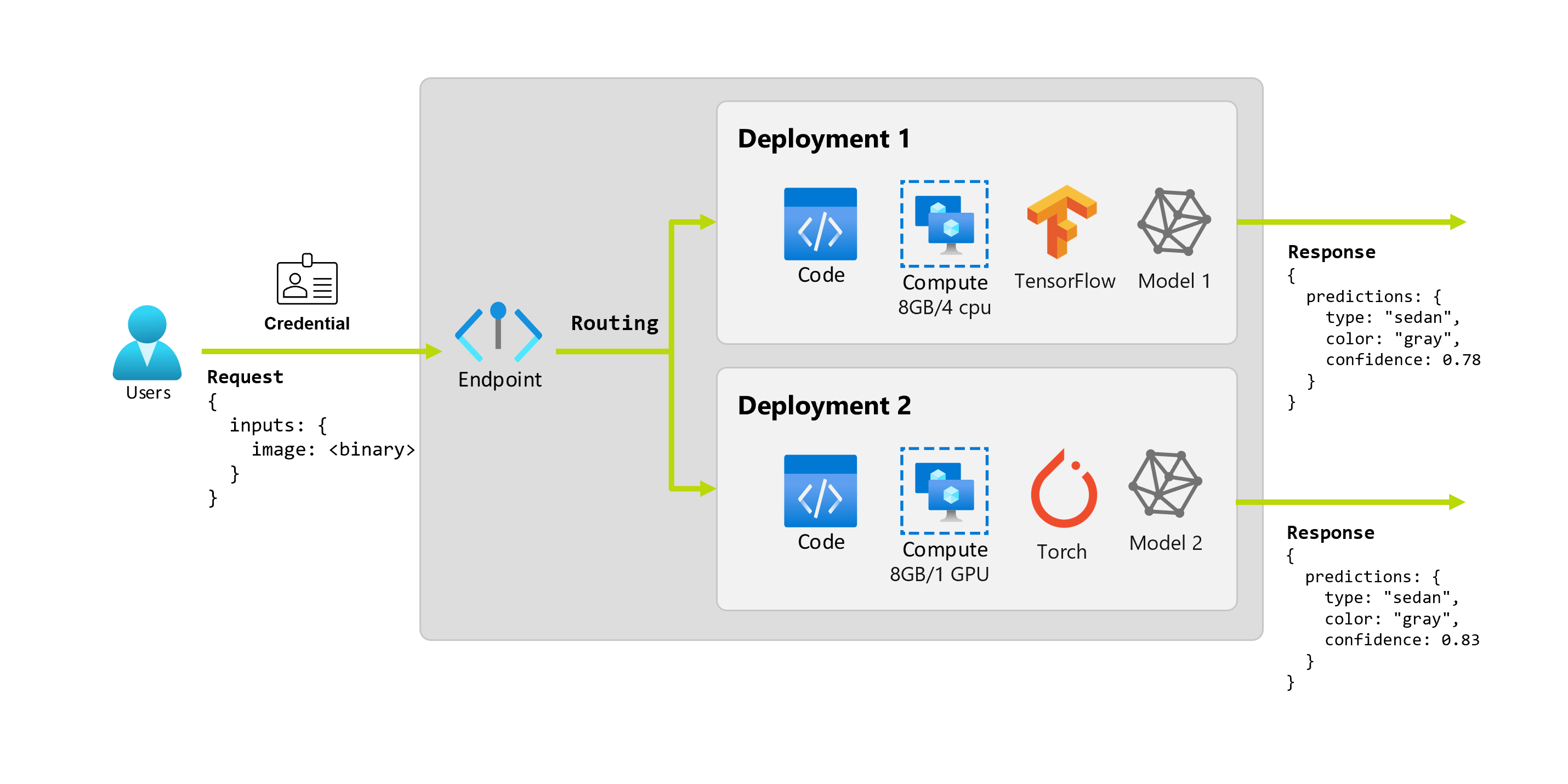
Si supponga che dopo un paio di mesi l'organizzazione scopra che l'applicazione ha prestazioni scarse sulle immagini con condizioni di illuminazione non ideali. Luca, un altro scienziato dei dati, conosce molte tecniche di aumento dei dati che consentono a un modello di creare affidabilità su tale fattore. Tuttavia, Luca preferisce usare Torch per implementare il modello ed esegue il training di un nuovo modello con Torch. Luca vuole provare gradualmente questo modello nella produzione fino a quando l'organizzazione non è pronta a ritirare il vecchio modello. Il nuovo modello mostra anche prestazioni migliori durante la distribuzione in GPU, quindi la distribuzione deve includerne una. In questo scenario, il modello e le risorse di Luca, ad esempio il codice e il calcolo, necessari per eseguire il modello costituiscono un'altra distribuzione sotto lo stesso endpoint.
Endpoint: API serverless, online e batch
Azure Machine Learning consente di implementare endpoint API serverless, endpoint onlinee endpoint batch.
Gli endpoint API serverless e gli endpoint online sono progettati per l'inferenza in tempo reale. Ogni volta che l'endpoint viene richiamato, i risultati vengono restituiti nella risposta dell'endpoint. Gli endpoint API serverless non utilizzano la quota dalla sottoscrizione; vengono invece fatturati con fatturazione con pagamento in base al consumo.
Gli endpoint Batch sono progettati per l'inferenza batch a esecuzione prolungata. Ogni volta che si richiama un endpoint batch si genera un processo batch che esegue il lavoro effettivo.
Quando usare l'API serverless, gli endpoint online e batch
endpoint API serverless:
Usare endpoint API serverless per usare modelli di base di grandi dimensioni per l'inferenza in tempo reale pronti all’uso o per ottimizzare tali modelli. Non tutti i modelli sono disponibili per la distribuzione in endpoint API serverless. È consigliabile usare questa modalità di distribuzione quando:
- Il modello è un modello di base o una versione ottimizzata di un modello di base disponibile per le distribuzioni di API serverless.
- È possibile trarre vantaggio da una distribuzione senza quota.
- Non è necessario personalizzare lo stack di inferenza usato per eseguire il modello.
Endpoint online:
Usare gli endpoint online per rendere operativi i modelli per l'inferenza in tempo reale nelle richieste sincrone a bassa latenza. È consigliabile usarli quando:
- Il modello è un modello di base o una versione ottimizzata di un modello di base, ma non è supportato negli endpoint API serverless.
- Si dispone di requisiti di bassa latenza.
- Il modello può rispondere alla richiesta in un periodo di tempo relativamente breve.
- Gli input del modello si adattano al payload HTTP della richiesta.
- È necessario aumentare le prestazioni in termini di numero di richieste.
Endpoint batch:
Usare endpoint batch per rendere operativi modelli o pipeline per l'inferenza asincrona a esecuzione prolungata. È consigliabile usarli quando:
- Si dispone di modelli o pipeline dispendiosi che richiedono tempi di esecuzione più lunghi.
- Si vogliono rendere operative le pipeline di Machine Learning e riutilizzare i componenti.
- È necessario eseguire l'inferenza su grandi quantità di dati, distribuiti in più file.
- Non si dispone di requisiti di bassa latenza.
- Gli input del modello vengono archiviati in un account di archiviazione o in un asset di dati di Azure Machine Learning.
- È possibile sfruttare la parallelizzazione.
Confronto tra API serverless, endpoint online e batch
Tutte le API serverless, online e batch si basano sull'idea degli endpoint, pertanto è possibile passare facilmente da uno all'altro. Gli endpoint online e batch sono anche in grado di gestire più distribuzioni per lo stesso endpoint.
Endpoint
La tabella seguente mostra un riepilogo delle diverse funzionalità disponibili per le API serverless. gli endpoint online e batch a livello di endpoint.
| Funzionalità | Endpoint API serverless | Endpoint online | Endpoint batch |
|---|---|---|---|
| URL di chiamata stabile | Sì | Sì | Sì |
| Supporto per più distribuzioni | No | Sì | Sì |
| Routing di distribuzione | None | Divisione del traffico | Passare all'impostazione predefinita |
| Eseguire il mirroring del traffico per un'implementazione sicura | No | Sì | No |
| Supporto di Swagger | Sì | Sì | No |
| Autenticazione | Chiave | Chiave e Microsoft Entra ID (anteprima) | Microsoft Entra ID |
| Supporto della rete privata (legacy) | No | Sì | Sì |
| Isolamento network gestito | Sì | Sì | Sì (vedere configurazione aggiuntiva richiesta) |
| Chiavi gestite dal cliente | N/D | Sì | Sì |
| Base costi | Per endpoint, al minuto1 | None | None |
1Viene addebitata una piccola frazione per gli endpoint API serverless al minuto. Vedere la sezione distribuzioni per gli addebiti relativi al consumo, fatturati per token.
Deployments
La tabella seguente mostra un riepilogo delle diverse funzionalità disponibili per le API serverless. gli endpoint online e batch a livello di distribuzione. Questi concetti si applicano a ogni distribuzione nell'endpoint (per gli endpoint online e batch) e si applicano agli endpoint API serverless (in cui il concetto di distribuzione è integrato nell'endpoint).
| Funzionalità | Endpoint API serverless | Endpoint online | Endpoint batch |
|---|---|---|---|
| Tipi distribuzione | Modelli | Modelli | Modelli e componenti della pipeline |
| Distribuzione modello MLflow | No, solo modelli specifici nel catalogo | Sì | Sì |
| Distribuzione di modelli personalizzati | No, solo modelli specifici nel catalogo | Sì, con lo script di assegnazione punteggio | Sì, con lo script di assegnazione punteggio |
| Distribuzione del pacchetto modello 2 | Predefinito | Sì (anteprima) | No |
| Server di inferenza 3 | API di inferenza del modello di Azure per intelligenza artificiale | - Server di inferenza di Azure Machine Learning - Triton - Personalizzato (tramite BYOC) |
Inferenza batch |
| Risorsa di calcolo utilizzata | Nessuno (serverless) | Istanze o risorse granulari | Istanze del cluster |
| Tipo di calcolo | Nessuno (serverless) | Calcolo gestito e Kubernetes | Calcolo gestito e Kubernetes |
| Calcolo con priorità bassa | ND | No | Sì |
| Ridimensionamento delle risorse di calcolo a zero | Predefinito | No | Sì |
| Calcolo con scalabilità automatica4 | Predefinito | Sì, in base all'uso delle risorse | Sì, in base al numero di processi |
| Gestione capacità eccessiva | Limitazione | Limitazione | Accodamento |
| Base costi5 | Per token | Per ogni distribuzione: istanze di calcolo in esecuzione | Per ogni processo: l'istanza di calcolo usata nel processo (limitata al numero massimo di istanze del cluster) |
| Test locali delle distribuzioni | No | Sì | No |
2 La distribuzione di modelli MLflow in endpoint senza connettività di Internet o reti private in uscita richiede innanzitutto di creare il pacchetto del modello.
3 Il server di inferenza fa riferimento alla tecnologia di gestione che accetta richieste, le elabora e crea risposte. Il server di inferenza determina anche il formato dell'input e degli output previsti.
4 La scalabilità automatica è la possibilità di aumentare o ridurre in modo automatico le risorse allocate alla distribuzione in base al carico. Le distribuzioni online e batch usano strategie diverse per la scalabilità automatica. Le distribuzioni online aumentano e si riducono in base all'utilizzo delle risorse (ad esempio CPU, memoria, richieste e così via), gli endpoint batch aumentano o si riducono in base al numero di processi creati.
5 Le distribuzioni sia online che batch vengono addebitate dalle risorse utilizzate. Nelle distribuzioni online, viene effettuato il provisioning delle risorse in fase di distribuzione. Nella distribuzione batch, non vengono utilizzate risorse in fase di distribuzione, bensì al momento dell'esecuzione del processo. Di conseguenza, non è previsto alcun costo associato alla distribuzione batch stessa. Allo stesso modo, anche i processi in coda non utilizzano risorse.
Interfacce per sviluppatori
Gli endpoint sono progettati per aiutare le organizzazioni a rendere operativi i carichi di lavoro a livello di produzione in Azure Machine Learning. Gli endpoint sono risorse affidabili e scalabili, e offrono le migliori funzionalità per implementare flussi di lavoro MLOps.
È possibile creare e gestire endpoint batch e online con diversi strumenti di sviluppo:
- Interfaccia della riga di comando di Azure e SDK Python
- Azure Resource Manager o API REST
- Portale Web di studio di Azure Machine Learning
- Portale di Azure (IT/Admin)
- Supporto per le pipeline CI/CD MLOps tramite l'interfaccia dell'interfaccia della riga di comando di Azure e le interfacce REST/ARM