Registri di Machine Learning per MLOps
Questo articolo descrive come i registri di Azure Machine Learning separano gli asset di Machine Learning dalle aree di lavoro, consentendo di usare MLOps in ambienti di sviluppo, test e produzione. Gli ambienti possono variare in base alla complessità dei sistemi IT. I fattori seguenti influenzano il numero e il tipo di ambienti necessari:
- Criteri di sicurezza e conformità. Gli ambienti di produzione potrebbero dover essere isolati dagli ambienti di sviluppo in termini di controlli di accesso, architettura di rete ed esposizione dei dati.
- Sottoscrizioni. Gli ambienti di sviluppo e gli ambienti di produzione usano spesso sottoscrizioni separate per scopi di fatturazione, budget e gestione dei costi.
- Aree. Potrebbe essere necessario eseguire la distribuzione in aree di Azure diverse per supportare i requisiti di latenza e ridondanza.
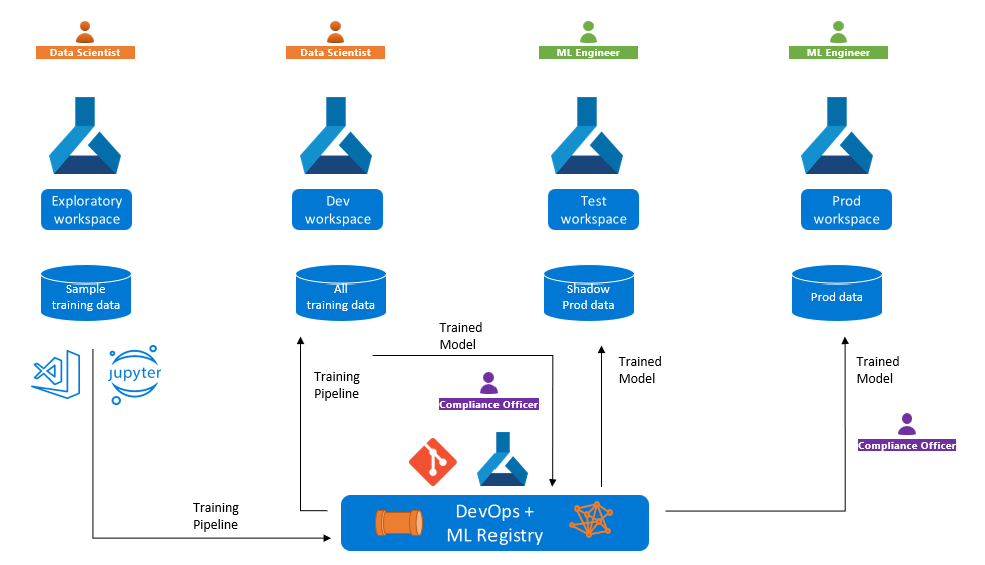
Negli scenari precedenti è possibile usare aree di lavoro di Azure Machine Learning diverse per sviluppo, test e produzione. Questa configurazione presenta le potenziali sfide seguenti per il training e la distribuzione del modello:
Potrebbe essere necessario eseguire il training di un modello in un'area di lavoro di sviluppo, ma distribuirlo in un endpoint in un'area di lavoro di produzione, possibilmente in una sottoscrizione o un'area di Azure diversa. In questo caso, è necessario essere in grado di tenere traccia del processo di training. Ad esempio, se si verificano problemi di accuratezza o prestazioni con la distribuzione di produzione, è necessario analizzare le metriche, i log, il codice, l'ambiente e i dati usati per eseguire il training del modello.
Potrebbe essere necessario sviluppare una pipeline di training con dati di test o dati anonimi nell'area di lavoro di sviluppo, ma ripetere il training del modello con i dati di produzione nell'area di lavoro di produzione. In questo caso, potrebbe essere necessario confrontare le metriche di training sui dati di esempio e di produzione per garantire che le ottimizzazioni del training funzionino correttamente con i dati effettivi.
MLOps tra aree di lavoro con registri
Un registro, molto simile a un repository Git, separa gli asset di Machine Learning dalle aree di lavoro e ospita gli asset in una posizione centrale, rendendoli disponibili per tutte le aree di lavoro dell'organizzazione.
Per promuovere modelli in ambienti di sviluppo, test e produzione, è possibile iniziare sviluppando in modo iterativo un modello nell'ambiente di sviluppo. Quando si dispone di un modello candidato valido, è possibile pubblicarlo in un registro. È quindi possibile distribuire il modello dal registro di sistema agli endpoint in aree di lavoro diverse.
Suggerimento
Se i modelli sono già stati registrati in un'area di lavoro, è possibile alzare di livello i modelli a un registro. È anche possibile registrare un modello direttamente in un registro dall'output di un processo di training.
Per sviluppare una pipeline in un'area di lavoro e quindi eseguirla in altre aree di lavoro, iniziare registrando i componenti e gli ambienti che costituiscono i blocchi predefiniti della pipeline. Quando si invia il processo della pipeline, il calcolo e i dati di training, univoci per ogni area di lavoro, determinano l'area di lavoro in cui eseguire.
Il diagramma seguente illustra l'innalzamento di livello della pipeline di training tra aree di lavoro esplorative e di sviluppo, quindi viene eseguito il training della promozione del modello per il test e la produzione.
Passaggi successivi
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per