Configurare AutoML per eseguire il training di modelli di visione artificiale
SI APPLICA A: Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)Python SDK azure-ai-ml v2 (corrente)
Questo articolo illustra come eseguire il training di modelli di visione artificiale sui dati delle immagini con ML automatizzato. È possibile eseguire il training di modelli usando l'estensione dell'interfaccia della riga di comando di Azure Machine Learning (v2) o Python SDK per Azure Machine Learning (v2).
ML automatizzato supporta il training dei modelli per attività di visione dei computer, ad esempio la classificazione immagini, il rilevamento oggetti e la segmentazione delle istanze. La creazione di modelli AutoML per le attività di visione dei computer è attualmente supportata tramite l'SDK Azure Machine Learning di Python. Le prove, i modelli e gli output della sperimentazione risultanti sono accessibili dall'interfaccia utente dello studio di Azure Machine Learning. Altre informazioni su ML automatizzato per le attività di visione artificiale sui dati di immagini.
Prerequisiti
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
- Un'area di lavoro di Azure Machine Learning. Per creare l'area di lavoro, vedere Creare risorse dell'area di lavoro.
- Installare e configurare l'interfaccia della riga di comando (v2) e assicurarsi di installare l'estensione
ml.
Selezionare il tipo di attività
ML automatizzato per le immagini supporta i seguenti tipi di attività:
| Tipo di attività | Sintassi del processo di AutoML |
|---|---|
| Classificazione immagini | Interfaccia della riga di comando v2: image_classification SDK v2: image_classification() |
| Classificazione immagini multietichetta | Interfaccia della riga di comando v2: image_classification_multilabel SDK v2: image_classification_multilabel() |
| Rilevamento oggetti immagine | Interfaccia della riga di comando v2: image_object_detection SDK v2: image_object_detection() |
| Segmentazione istanze immagine | Interfaccia della riga di comando v2: image_instance_segmentation SDK v2: image_instance_segmentation() |
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
Questo tipo di attività è un parametro obbligatorio e può essere impostato usando la chiave task.
Ad esempio:
task: image_object_detection
Dati di training e convalida
Per generare modelli di visione artificiale, è necessario inserire i dati etichettati di immagini come input per il training del modello sotto forma di MLTable. È possibile creare un oggetto MLTable dai dati di training in formato JSONL.
Se i dati di training sono in un formato diverso (ad esempio, Pascal VOC o COCO), è possibile applicare gli script helper inclusi nei notebook di esempio per convertirli in JSONL. Vedere altre informazioni su come preparare i dati per le attività di visione artificiale con ML automatizzato.
Nota
Per poter inviare un processo di AutoML, è necessario che i dati di training includano almeno 10 immagini.
Avviso
Per questa funzionalità, la creazione di un oggetto MLTable dai dati in formato JSONL è supportata solo con l'SDK e con l'interfaccia della riga di comando. La creazione di un oggetto MLTable tramite interfaccia utente non è supportata al momento.
Esempi di schemi JSONL
La struttura dell'oggetto TabularDataset dipende dall'attività. Per le attività di tipo visione artificiale, è costituita dai campi seguenti:
| Campo | Descrizione |
|---|---|
image_url |
Contiene il percorso file come oggetto StreamInfo |
image_details |
Informazioni sui metadati dell'immagine costituite da altezza, larghezza e formato. Questo campo è facoltativo e può esistere o no. |
label |
Rappresentazione JSON dell'etichetta dell'immagine, in base al tipo di attività. |
Il codice seguente è un file JSONL di esempio per la classificazione immagini:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
Il codice seguente è un file JSONL di esempio per il rilevamento oggetti:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Dati di utilizzo
Quando i dati sono in formato JSONL, è possibile creare un oggetto MLTable di training e convalida, come illustrato di seguito.
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
Per le attività di visione artificiale, ML automatizzato non impone vincoli sulle dimensioni dei dati di training o convalida. Le dimensioni massime del set di dati sono limitate solo dal livello di archiviazione sottostante, ad esempio un archivio di BLOB. Non è previsto un numero minimo di immagini o etichette. È tuttavia consigliabile iniziare con almeno 10-15 campioni per etichetta per garantire che il modello di output sia sottoposto a un training sufficiente. Maggiore è il numero totale di etichette/classi, maggiore è il numero di campioni necessari per etichetta.
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
I dati di training sono un parametro obbligatorio e vengono passati usando la chiave training_data. Facoltativamente, è possibile specificare un altro oggetto MLtable come dati di convalida con la chiave validation_data. Se non vengono specificati dati di convalida, il 20% dei dati di training viene usato per la convalida per impostazione predefinita, a meno che non si passi l'argomento validation_data_size con un valore diverso.
Il nome della colonna di destinazione è un parametro obbligatorio, usato come destinazione per l'attività di ML con supervisione. Viene passato usando la chiave target_column_name. ad esempio:
target_column_name: label
training_data:
path: data/training-mltable-folder
type: mltable
validation_data:
path: data/validation-mltable-folder
type: mltable
Calcolo per eseguire l'esperimento
Specificare una destinazione di calcolo per ML automatizzato per eseguire il training del modello. I modelli di ML automatizzato per le attività di visione artificiale richiedono SKU di GPU e supportano famiglie NC e ND. È consigliabile usare la serie NCsv3 (con GPU v100) per un training più rapido. Una destinazione di calcolo con uno SKU di macchina virtuale multi-GPU usa più GPU anche per velocizzare il training. Inoltre, quando si configura una destinazione di calcolo con più nodi, è possibile eseguire più velocemente il training del modello tramite parallelismo durante l'ottimizzazione degli iperparametri per il modello.
Nota
Se si usa un'istanza di ambiente di calcolo come destinazione di calcolo, assicurarsi che non vengano eseguiti contemporaneamente più processi di AutoML. Assicurarsi inoltre che il parametro max_concurrent_trials sia impostato su 1 nei limiti del processo.
La destinazione di calcolo viene passata usando il parametro compute. Ad esempio:
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
compute: azureml:gpu-cluster
Configurare gli esperimenti
Per le attività di visione artificiale, è possibile avviare singole prove, sweep manuali o sweep automatici. È consigliabile iniziare con uno sweep automatico per ottenere un primo modello di base. È quindi possibile verificare le singole prove con determinati modelli e configurazioni degli iperparametri. Infine, con gli sweep manuali è possibile esplorare più valori degli iperparametri vicino ai modelli e alle configurazioni degli iperparametri più promettenti. Questo flusso di lavoro in tre passaggi (sweep automatico, singole prove, sweep manuali) evita la necessità di cercare nell'intero spazio degli iperparametri, che aumentano in maniera esponenziale.
Gli sweep automatici possono produrre risultati competitivi per molti set di dati. Inoltre, non richiedono conoscenze avanzate delle architetture dei modelli, considerano le correlazioni tra gli iperparametri e funzionano perfettamente in diverse configurazioni hardware. Per tutti questi motivi, si tratta di un'opzione particolarmente valida per la prima fase del processo di sperimentazione.
Primary metric (Metrica principale)
Un processo di training di AutoML usa una metrica primaria per l'ottimizzazione del modello e degli iperparametri. La metrica primaria dipende dal tipo di attività, come illustrato di seguito; altri valori di metriche primarie non sono attualmente supportati.
- Accuratezza per la classificazione immagini
- Intersezione su unione per la classificazione immagini multietichetta
- Precisione media media per il rilevamento oggetti immagine
- Precisione media media per la segmentazione di istanze immagine
Limiti dei processi
È possibile controllare le risorse impiegate nel processo di training di immagini di AutoML specificando i parametri timeout_minutes, max_trials e max_concurrent_trials per il processo nelle impostazioni di limite, come descritto nell'esempio seguente.
| Parametro | Dettagli |
|---|---|
max_trials |
Parametro per il numero massimo di prove da sottoporre a sweep. Deve essere un numero intero compreso tra 1 e 1.000. Se ci si limita a esplorare gli iperparametri predefiniti per una data architettura di modelli, impostare questo parametro su 1. Il valore predefinito è 1. |
max_concurrent_trials |
Numero massimo di prove che è possibile eseguire simultaneamente. Se specificato, deve essere un numero intero compreso tra 1 e 100. Il valore predefinito è 1. NOTA: max_concurrent_trials è limitato al valore di max_trials internamente. Ad esempio, se l'utente imposta max_concurrent_trials=4, max_trials=2, i valori verranno aggiornati internamente come max_concurrent_trials=2, max_trials=2. |
timeout_minutes |
La quantità di tempo, in minuti, prima che l'esperimento termini. Se non è specificato, il valore predefinito di timeout_minutes per gli esperimenti è di sette giorni (massimo 60 giorni) |
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
limits:
timeout_minutes: 60
max_trials: 10
max_concurrent_trials: 2
Sweep automatico degli iperparametri del modello (AutoMode)
Importante
Questa funzionalità è attualmente in anteprima pubblica. Questa versione di anteprima viene fornita senza un contratto di servizio. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
È difficile prevedere l'architettura di modelli e gli iperparametri ottimali per un set di dati. Inoltre, in alcuni casi il tempo umano allocato per l'ottimizzazione degli iperparametri può essere limitato. Per le attività di visione artificiale, è possibile specificare un numero qualsiasi di prove e il sistema determina automaticamente l'area dello spazio degli iperparametri per lo sweep. Non è necessario definire uno spazio di ricerca di iperparametri, un metodo di campionamento o un criterio di interruzione anticipata.
Attivazione di AutoMode
È possibile eseguire sweep automatici impostando max_trials su un valore maggiore di 1 in limits e non specificando lo spazio di ricerca, il metodo di campionamento e i criteri di interruzione. Questa funzionalità è detta AutoMode; vedere l'esempio seguente.
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
limits:
max_trials: 10
max_concurrent_trials: 2
È probabile che un numero di prove compreso tra 10 e 20 funzioni bene in molti set di dati. Il budget temporale per il processo di AutoML può comunque essere impostato, ma è consigliabile farlo solo se ogni prova può richiedere tempi lunghi.
Avviso
L'avvio di sweep automatici tramite l'interfaccia utente non è attualmente supportato.
Singole prove
Nelle singole prove è possibile controllare direttamente l'architettura di modelli e gli iperparametri. L'architettura di modelli viene passata tramite il parametro model_name.
Architetture di modelli supportate
La tabella seguente riepiloga i modelli legacy supportati per ogni attività di visione artificiale. L'uso di questi modelli legacy attiverà le esecuzioni usando il runtime legacy (in cui ogni singola esecuzione o prova viene inviata come processo di comandi). Vedere di seguito per informazioni sul supporto di HuggingFace e MMDetection.
| Attività | Architetture di modelli | Sintassi di valori letterali stringadefault_model* indicato con * |
|---|---|---|
| Classificazione immagini (multiclasse e multietichetta) |
MobileNet: modelli leggeri per applicazioni per dispositivi mobili ResNet: reti residue ResNeSt: reti con attenzione divisa SE-ResNeXt50: reti Squeeze-and-Excitation ViT: reti di trasformatori di visione |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (piccolo) vitb16r224* (base) vitl16r224 (grande) |
| Rilevamento oggetti |
YOLOv5: modello di rilevamento oggetti in un'unica fase Faster RCNN ResNet FPN: modelli di rilevamento oggetti in due fasi RetinaNet ResNet FPN: soluzione per lo squilibrio di classi con perdita focale Nota: per informazioni sulle dimensioni dei modelli YOLOv5, consultare model_sizeiperparametro . |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Segmentazione delle istanze | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn |
Architetture di modelli supportate - HuggingFace e MMDetection
Con il nuovo back-end eseguito in pipeline di Azure Machine Learning, è anche possibile usare qualsiasi modello di classificazione immagini dell'hub HuggingFace che fa parte della libreria dei trasformatori (ad esempio microsoft/beit-base-patch16-224), nonché qualsiasi modello di rilevamento oggetti o segmentazione di istanze di MMDetection versione 3.1.0 modello Zoo (ad esempio atss_r50_fpn_1x_coco).
Oltre a supportare qualsiasi modello di trasformatori HuggingFace e MMDetection 3.1.0, è anche disponibile un elenco di modelli curati di queste librerie nel registro azureml. Questi modelli curati sono stati testati accuratamente e usano iperparametri predefiniti selezionati in base a benchmark completi per garantire un training efficace. La tabella seguente riepiloga questi modelli curati.
| Attività | Architetture di modelli | Sintassi di valori letterali stringa |
|---|---|---|
| Classificazione immagini (multiclasse e multietichetta) |
BEiT ViT DeiT SwinV2 |
microsoft/beit-base-patch16-224-pt22k-ft22kgoogle/vit-base-patch16-224facebook/deit-base-patch16-224microsoft/swinv2-base-patch4-window12-192-22k |
| Rilevamento oggetti |
Sparse R-CNN Deformable DETR VFNet YOLOF |
mmd-3x-sparse-rcnn_r50_fpn_300-proposals_crop-ms-480-800-3x_cocommd-3x-sparse-rcnn_r101_fpn_300-proposals_crop-ms-480-800-3x_coco mmd-3x-deformable-detr_refine_twostage_r50_16xb2-50e_coco mmd-3x-vfnet_r50-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-vfnet_x101-64x4d-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-yolof_r50_c5_8x8_1x_coco |
| Segmentazione delle istanze | Maschera R-CNN | mmd-3x-mask-rcnn_swin-t-p4-w7_fpn_1x_coco |
L'elenco di modelli curati viene aggiornato costantemente. È possibile ottenere l'elenco più aggiornato dei modelli curati per una determinata attività usando Python SDK:
credential = DefaultAzureCredential()
ml_client = MLClient(credential, registry_name="azureml")
models = ml_client.models.list()
classification_models = []
for model in models:
model = ml_client.models.get(model.name, label="latest")
if model.tags['task'] == 'image-classification': # choose an image task
classification_models.append(model.name)
classification_models
Output:
['google-vit-base-patch16-224',
'microsoft-swinv2-base-patch4-window12-192-22k',
'facebook-deit-base-patch16-224',
'microsoft-beit-base-patch16-224-pt22k-ft22k']
Con qualsiasi modello HuggingFace o MMDetection verranno attivate esecuzioni usando componenti di pipeline. Se si usano i modelli legacy e HuggingFace/MMdetection, tutte le esecuzioni/prove verranno attivate usando i componenti.
Oltre a controllare l'architettura di modelli, è anche possibile ottimizzare gli iperparametri usati per il training. Sebbene molti iperparametri esposti siano indipendenti dal modello, in alcuni casi sono specifici dell'attività o specifici del modello. Altre informazioni sugli iperparametri disponibili per questi casi.
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
Se si desidera usare i valori degli iperparametri predefiniti per una determinata architettura (ad esempio yolov5), è possibile specificarlo usando la chiave model_name nella sezione training_parameters. ad esempio:
training_parameters:
model_name: yolov5
Sweep automatico degli iperparametri del modello
Quando si esegue il training di modelli di visione artificiale, le prestazioni del modello dipendono in larga misura dai valori degli iperparametri selezionati. Spesso, si può scegliere di ottimizzare gli iperparametri per ottenere prestazioni ottimali. Per le attività di visione artificiale, è possibile eseguire lo sweep degli iperparametri per trovare le impostazioni ottimali per il modello. Questa funzionalità applica le funzionalità di ottimizzazione degli iperparametri di Azure Machine Learning. Informazioni su come ottimizzare gli iperparametri.
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
search_space:
- model_name:
type: choice
values: [yolov5]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.01
model_size:
type: choice
values: [small, medium]
- model_name:
type: choice
values: [fasterrcnn_resnet50_fpn]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.001
optimizer:
type: choice
values: [sgd, adam, adamw]
min_size:
type: choice
values: [600, 800]
Definire lo spazio di ricerca dei parametri
È possibile definire le architetture dei modelli e gli iperparametri da sottoporre a sweep nello spazio dei parametri. È possibile specificare una o più architetture di modelli.
- Per l'elenco delle architetture di modelli supportate per ogni tipo di attività, vedere Singole prove.
- Vedere gli iperparametri per ogni tipo di attività di visione artificiale.
- Consultare informazioni dettagliate sulle distribuzioni supportate per iperparametri discreti e continui.
Metodi di campionamento per lo sweep
Quando si esegue lo sweep degli iperparametri, è necessario specificare il metodo di campionamento da usare nello spazio dei parametri definito. Attualmente, con il parametro sampling_algorithm sono supportati i metodi di campionamento seguenti:
| Tipo di campionamento | Sintassi del processo di AutoML |
|---|---|
| Campionamento casuale | random |
| Campionamento a griglia | grid |
| Campionamento bayesiano | bayesian |
Nota
Attualmente, solo i campionamenti casuale e a griglia supportano spazi di iperparametri condizionali.
Criteri di interruzione anticipata
È possibile interrompere automaticamente le prove con prestazioni insufficienti con un criterio di interruzione anticipata. L'interruzione anticipata migliora l'efficienza di calcolo, facendo risparmiare risorse di calcolo che sarebbero state altrimenti spese per prove meno promettenti. ML automatizzato per le immagini supporta i criteri di interruzione anticipata seguenti tramite il parametro early_termination. Se non vengono specificati criteri di interruzione, tutte le prove vengono eseguite fino al completamento.
| Criteri di interruzione anticipata | Sintassi del processo di AutoML |
|---|---|
| Criteri Bandit | Interfaccia della riga di comando v2: bandit SDK v2: BanditPolicy() |
| Criteri di arresto con valore mediano | Interfaccia della riga di comando v2: median_stopping SDK v2: MedianStoppingPolicy() |
| Criteri di selezione con troncamento | Interfaccia della riga di comando v2: truncation_selection SDK v2: TruncationSelectionPolicy() |
Per altre informazioni, vedere come configurare i criteri di interruzione anticipata per lo sweep degli iperparametri.
Nota
Per un esempio completo di configurazione dello sweep, vedere questa esercitazione.
È possibile configurare tutti i parametri correlati allo sweep come illustrato nell'esempio seguente.
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
sweep:
sampling_algorithm: random
early_termination:
type: bandit
evaluation_interval: 2
slack_factor: 0.2
delay_evaluation: 6
Impostazioni fisse
È possibile passare impostazioni fisse o parametri che non cambiano durante lo sweep dello spazio dei parametri, come illustrato nell'esempio seguente.
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
training_parameters:
early_stopping: True
evaluation_frequency: 1
Aumento dei dati
In generale, le prestazioni del modello di Deep Learning possono spesso migliorare con più dati. L'aumento dei dati è una tecnica pratica per amplificare le dimensioni e la variabilità dei dati di un set di dati, il che consente di evitare l'overfitting e di migliorare la capacità di generalizzazione del modello su dati non visibili. ML automatizzato applica diverse tecniche di aumento dei dati in base all'attività di visione artificiale, prima di inviare le immagini di input al modello. Attualmente, non esiste alcun iperparametro esposto per controllare gli aumenti dei dati.
| Attività | Set di dati interessato | Tecnica o tecniche di aumento dei dati applicate |
|---|---|---|
| Classificazione immagini (multiclasse e multietichetta) | Formazione Convalida e test |
Ridimensionamento e ritaglio casuali, capovolgimento orizzontale, instabilità del colore (luminosità, contrasto, saturazione e tonalità), normalizzazione tramite deviazione media e standard di ImageNet a livello di canale Ridimensionamento, ritaglio al centro, normalizzazione |
| Rilevamento oggetti, segmentazione di istanze | Formazione Convalida e test |
Ritaglio casuale intorno ai rettangoli di selezione, espansione, capovolgimento orizzontale, normalizzazione, ridimensionamento Normalizzazione, ridimensionamento |
| Rilevamento oggetti con yolov5 | Formazione Convalida e test |
Mosaico, trasformazione affine casuale (rotazione, traslazione, scala, inclinazione), capovolgimento orizzontale Ridimensionamento in formato 16:9 |
Attualmente le operazioni di aumento definite in precedenza vengono applicate per impostazione predefinita per un processo di ML automatizzato per immagini. Per fornire controllo sugli aumenti, ML automatizzato per immagini espone i due flag seguenti per disattivare specifici aumenti. Attualmente, questi flag sono supportati solo per le attività di rilevamento oggetti e segmentazione di istanze.
- apply_mosaic_for_yolo: questo flag è specifico solo per il modello Yolo. Impostandolo su False si disattiva l'aumento dei dati a mosaico, che viene applicato al momento del training.
-
apply_automl_train_augmentations: l'impostazione di questo flag su False disattiva l'aumento applicato durante il training per i modelli di rilevamento oggetti e segmentazione di istanze. Per gli aumenti, vedere i dettagli nella tabella precedente.
- Per i modelli di rilevamento oggetti non yolo e i modelli di segmentazione di istanze, questo flag disattiva solo i primi tre aumenti. Ad esempio: ritaglio casuale intorno ai rettangoli di selezione, espansione, capovolgimento orizzontale. Gli aumenti di tipo normalizzazione e ridimensionamento vengono comunque applicati indipendentemente da questo flag.
- Per il modello Yolo, questo flag disattiva gli aumenti di tipo trasformazione affine casuale e capovolgimento orizzontale.
Questi due flag sono supportati tramite advanced_settings in training_parameters e possono essere controllati nel modo seguente.
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
training_parameters:
advanced_settings: >
{"apply_mosaic_for_yolo": false}
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false}
Si noti che questi due flag sono indipendenti l'uno dall'altro e possono anche essere usati in combinazione tramite le impostazioni seguenti.
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false, "apply_mosaic_for_yolo": false}
Nei nostri esperimenti abbiamo rilevato che questi aumenti consentono di generalizzare meglio il modello. Pertanto, quando questi aumenti sono disattivati, è consigliabile combinarli con altri incrementi offline per ottenere risultati migliori.
Training incrementale (facoltativo)
Al termine del processo di training, è possibile scegliere di eseguire un ulteriore training caricando il checkpoint del modello già sottoposto a training. Per il training incrementale, è possibile usare lo stesso set di dati o uno diverso. Se si è soddisfatti del modello, è possibile scegliere di arrestare il training e usare il modello corrente.
Passare il checkpoint tramite l'ID processo
È possibile passare l'ID processo da cui caricare il checkpoint.
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
training_parameters:
checkpoint_run_id : "target_checkpoint_run_id"
Inviare il processo di AutoML
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
Per inviare il processo di AutoML, è possibile eseguire il comando dell'interfaccia della riga di comando v2 seguente con il percorso del file con estensione yml, il nome dell'area di lavoro, il gruppo di risorse e l'ID sottoscrizione.
az ml job create --file ./hello-automl-job-basic.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Output e metriche di valutazione
I processi di training di ML automatizzato generano file di modello di output, metriche di valutazione, log e artefatti della distribuzione, come il file di assegnazione dei punteggi e il file dell'ambiente. Questi file e metriche possono essere visualizzati nella scheda di output, log e metriche dei processi figlio.
Suggerimento
Per informazioni su come passare ai risultati del processo, vedere la sezione Visualizzare i risultati del processo.
Per definizioni ed esempi dei grafici delle prestazioni e delle metriche disponibili per ogni processo, vedere Valutare i risultati degli esperimenti di Machine Learning automatizzato.
Registrare e distribuire modelli
Al termine del processo, è possibile registrare il modello creato dalla prova migliore (la configurazione che ha generato la metrica primaria migliore). È possibile registrare il modello dopo il download o specificando il percorso azureml con il jobid corrispondente. Nota: se si vogliono cambiare le impostazioni di inferenza descritte di seguito, è necessario scaricare il modello, modificare il file settings.json ed eseguire la registrazione usando la cartella del modello aggiornata.
Ottenere la prova migliore
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
CLI example not available, please use Python SDK.
Registrare il modello
Registrare il modello usando il percorso azureml o il percorso scaricato in locale.
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
az ml model create --name od-fridge-items-mlflow-model --version 1 --path azureml://jobs/$best_run/outputs/artifacts/outputs/mlflow-model/ --type mlflow_model --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Dopo aver registrato il modello da usare, è possibile distribuirlo usando l'endpoint online gestito deploy-managed-online-endpoint.
Configurare l'endpoint online
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: od-fridge-items-endpoint
auth_mode: key
Creare l'endpoint
Usando l'oggetto MLClient creato in precedenza, verrà ora creato l'endpoint nell'area di lavoro. Questo comando avvia la creazione dell'endpoint e restituisce una risposta di conferma mentre la procedura è ancora in corso.
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
az ml online-endpoint create --file .\create_endpoint.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Configurare la distribuzione online
Per distribuzione si intende un set di risorse necessarie per ospitare il modello che esegue l'inferenza effettiva. Verrà creata una distribuzione per l'endpoint usando la classe ManagedOnlineDeployment. Per il cluster di distribuzione, è possibile usare SKU di VM con GPU o CPU.
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
name: od-fridge-items-mlflow-deploy
endpoint_name: od-fridge-items-endpoint
model: azureml:od-fridge-items-mlflow-model@latest
instance_type: Standard_DS3_v2
instance_count: 1
liveness_probe:
failure_threshold: 30
success_threshold: 1
timeout: 2
period: 10
initial_delay: 2000
readiness_probe:
failure_threshold: 10
success_threshold: 1
timeout: 10
period: 10
initial_delay: 2000
Creare la distribuzione
Usando l'oggetto MLClient creato in precedenza, verrà ora creata la distribuzione nell'area di lavoro. Questo comando avvia la creazione della distribuzione e restituisce una risposta di conferma mentre la procedura è ancora in corso.
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
az ml online-deployment create --file .\create_deployment.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Aggiornare il traffico:
Per impostazione predefinita, la distribuzione corrente è impostata per ricevere lo 0% del traffico. È possibile impostare la percentuale di traffico che dovrà ricevere la distribuzione corrente. La somma delle percentuali di traffico di tutte le distribuzioni con un endpoint non deve superare il 100%.
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
az ml online-endpoint update --name 'od-fridge-items-endpoint' --traffic 'od-fridge-items-mlflow-deploy=100' --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
In alternativa, è possibile distribuire il modello dall'interfaccia utente dello studio di Azure Machine Learning. Passare al modello da distribuire nella scheda Modelli del processo di ML automatizzato e selezionare Distribuisci, quindi Esegui la distribuzione in un endpoint in tempo reale.
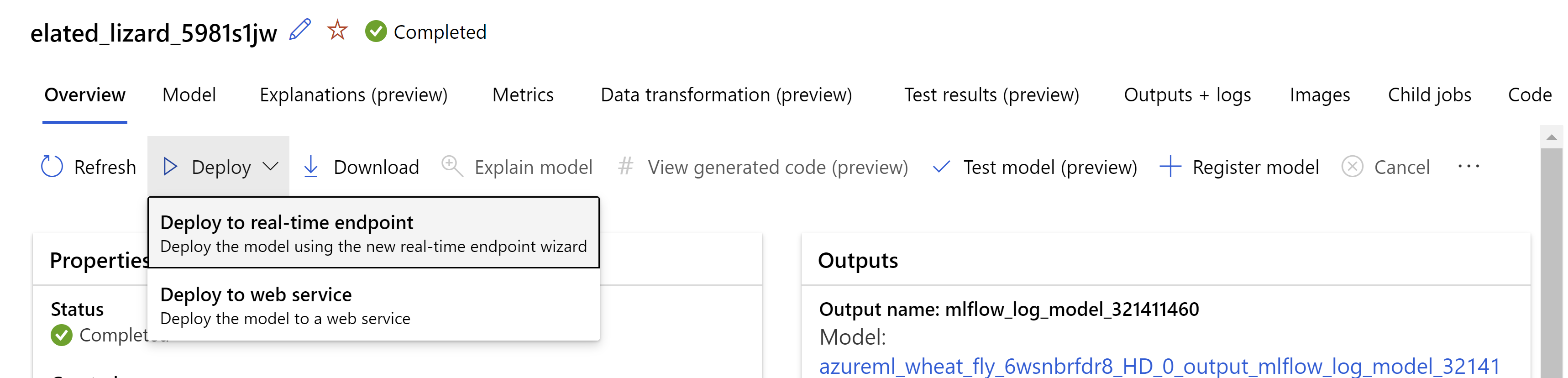 .
.
Questo è l'aspetto della pagina di revisione. È possibile selezionare il tipo e il numero di istanze e impostare la percentuale di traffico per la distribuzione corrente.
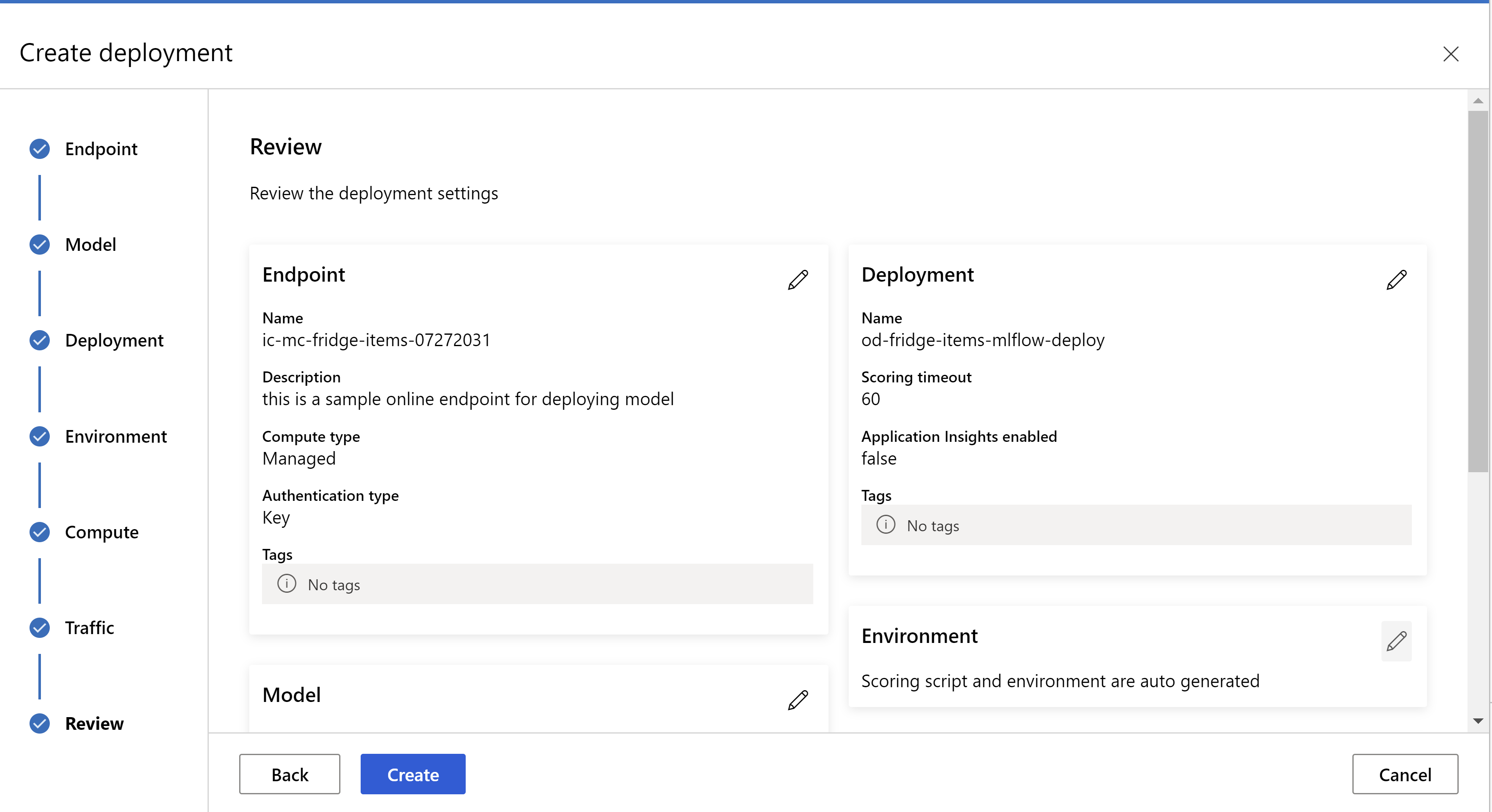 .
.
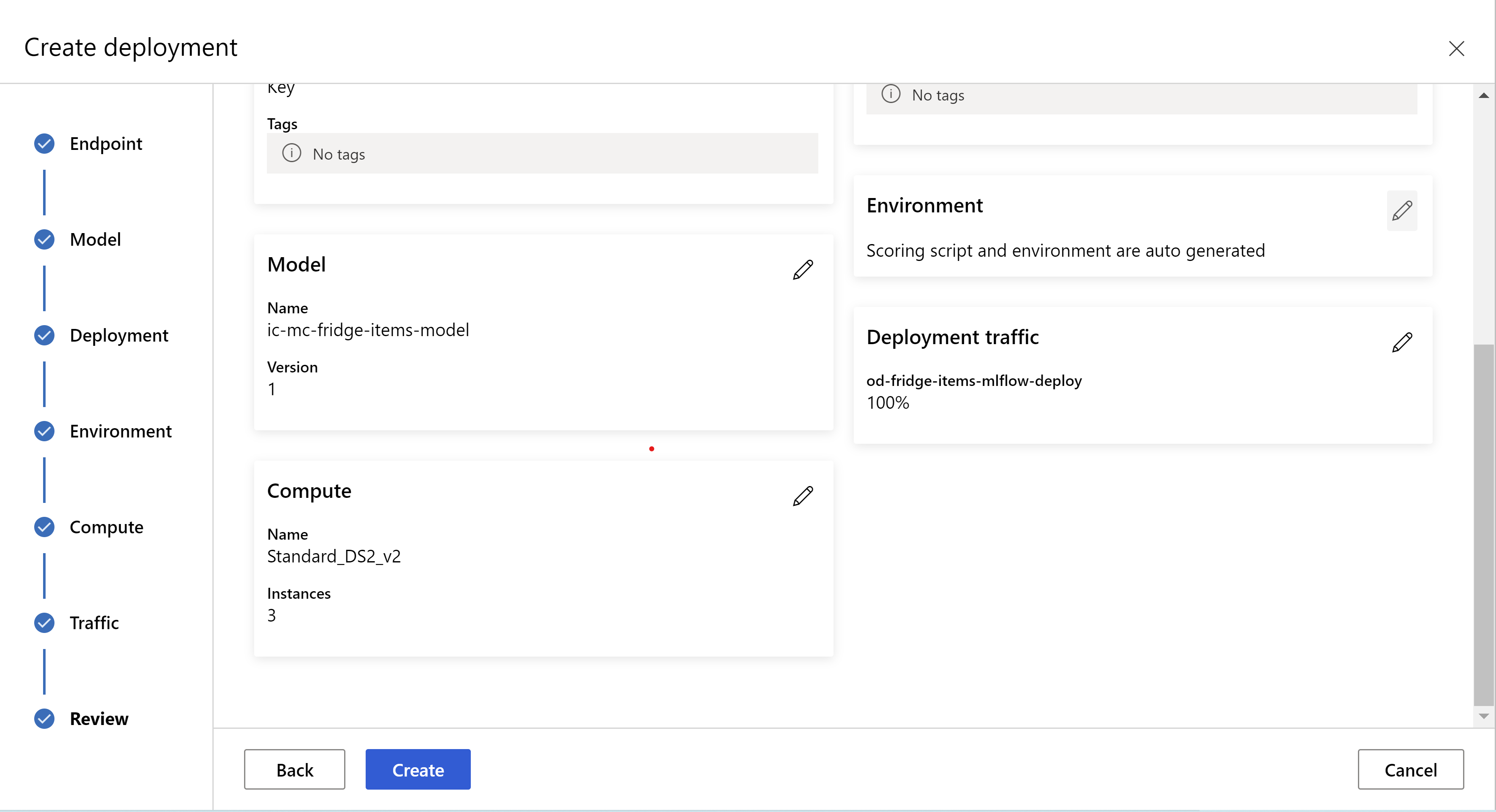 .
.
Aggiornare le impostazioni di inferenza
Nel passaggio precedente è stato scaricato un file mlflow-model/artifacts/settings.json dal modello migliore, che può essere usato per aggiornare le impostazioni di inferenza prima di registrare il modello, sebbene sia consigliabile usare gli stessi parametri del training per ottenere prestazioni ottimali.
Ognuna delle attività (e alcuni modelli) ha un set di parametri. Per impostazione predefinita, vengono usati gli stessi valori per i parametri usati durante il training e la convalida. A seconda del comportamento necessario per l’uso del modello per inferenza, è possibile cambiare questi parametri. Di seguito è riportato un elenco di parametri per ogni tipo di attività e modello.
| Attività | Nome parametro | Default |
|---|---|---|
| Classificazione immagini (multiclasse e multietichetta) | valid_resize_sizevalid_crop_size |
256 224 |
| Rilevamento oggetti | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0,3 0.5 100 |
Rilevamento oggetti con yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 medium 0,1 0.5 |
| Segmentazione delle istanze | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0,3 0.5 100 0.5 100 Falso JPG |
Per una descrizione dettagliata sugli iperparametri specifici dell'attività, vedere Iperparametri per le attività di visione artificiale in Machine Learning automatizzato.
Se si vuole usare l'affiancamento e controllare il relativo comportamento, sono disponibili i parametri seguenti: tile_grid_size, tile_overlap_ratio e tile_predictions_nms_thresh. Per altre informazioni su questi parametri, vedere Eseguire il training di un piccolo modello di rilevamento oggetti con AutoML.
Testare la distribuzione
Vedere la sezione Testare la distribuzione per testare la distribuzione e visualizzare i rilevamenti del modello.
Generare spiegazioni per le previsioni
Importante
Queste impostazioni sono attualmente disponibili in anteprima pubblica. Vengono fornite senza un contratto di servizio. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Avviso
La spiegabilità del modello è supportata solo per la classificazione multiclasse e la classificazione multietichetta.
Alcuni vantaggi dell'uso dell'intelligenza artificiale spiegabile (XAI) con AutoML per le immagini:
- Migliora la trasparenza nelle previsioni dei modelli di visione complessi
- Consente agli utenti di comprendere le caratteristiche/pixel importanti nell'immagine di input che contribuiscono alle previsioni del modello
- Consente di risolvere i problemi relativi ai modelli
- Consente di individuare la distorsione
Spiegazioni
Le spiegazioni sono attribuzioni di funzionalità o pesi dati a ogni pixel nell'immagine di input in base al relativo contributo alla previsione del modello. Ogni peso può essere negativo (correlato negativamente alla previsione) o positivo (correlato positivamente alla previsione). Queste attribuzioni vengono calcolate rispetto alla classe prevista. Per la classificazione multiclasse viene generata solo una matrice di attribuzione delle dimensioni [3, valid_crop_size, valid_crop_size] per campione, mentre per la classificazione multietichetta viene generata una matrice di attribuzione delle dimensioni [3, valid_crop_size, valid_crop_size] per ogni etichetta/classe prevista per ogni campione.
Usando l'intelligenza artificiale spiegabile in AutoML per le immagini nell'endpoint distribuito, gli utenti possono ottenere visualizzazioni di spiegazioni (attribuzioni sovrapposte a un'immagine di input) e/o attribuzioni (matrice multidimensionale di dimensioni [3, valid_crop_size, valid_crop_size]) per ogni immagine. Oltre alle visualizzazioni, gli utenti possono anche ottenere matrici di attribuzione per ottenere un maggior controllo sulle spiegazioni, ad esempio la generazione di visualizzazioni personalizzate usando attribuzioni o esaminando segmenti di attribuzioni. Tutti gli algoritmi di spiegazione usano immagini quadrate ritagliate con dimensioni valid_crop_size per generare attribuzioni.
Le spiegazioni possono essere generate da endpoint online o endpoint batch. Al termine della distribuzione, questo endpoint può essere usato per generare le spiegazioni per le previsioni. Nelle distribuzioni online assicurarsi di passare il parametro request_settings = OnlineRequestSettings(request_timeout_ms=90000) a ManagedOnlineDeployment e di impostare request_timeout_ms sul relativo valore massimo per evitare problemi di timeout durante la generazione di spiegazioni (vedere la sezione Registrare e distribuire il modello). Alcuni metodi di spiegabilità (XAI) come xrai richiedono più tempo, specialmente per la classificazione multietichetta, in quanto è necessario generare attribuzioni e/o visualizzazioni per ogni etichetta prevista. È quindi consigliabile usare qualsiasi istanza di GPU per spiegazioni più rapide. Per altre informazioni sullo schema di input e output per la generazione di spiegazioni, vedere la documentazione sugli schemi.
In AutoML per le immagini sono supportati i seguenti algoritmi di spiegabilità all'avanguardia:
- XRAI (xrai)
- Integrated Gradients (integrated_gradients)
- Guided GradCAM (guided_gradcam)
- Guided BackPropagation (guided_backprop)
La tabella seguente descrive i parametri di ottimizzazione specifici degli algoritmi di spiegabilità per XRAI e Integrated Gradients. Gli algoritmi Guided BackPropagation e Guided GradCAM non richiedono parametri di ottimizzazione.
| Algoritmo XAI | Parametri specifici dell'algoritmo | Valori predefiniti |
|---|---|---|
xrai |
1. n_steps: il numero di passaggi usati dal metodo di approssimazione. Un numero maggiore di passaggi comporta migliori approssimazioni delle attribuzioni (spiegazioni). L'intervallo di n_steps è [2, inf), ma le prestazioni delle attribuzioni iniziano a convergere dopo 50 passaggi. Optional, Int 2. xrai_fast: indica se usare o meno una versione più veloce di XRAI. Se True, il tempo di calcolo per le spiegazioni è più veloce, ma porta a spiegazioni (attribuzioni) meno accurate Optional, Bool |
n_steps = 50 xrai_fast = True |
integrated_gradients |
1. n_steps: il numero di passaggi usati dal metodo di approssimazione. Un numero maggiore di passaggi comporta migliori attribuzioni (spiegazioni). L'intervallo di n_steps è [2, inf), ma le prestazioni delle attribuzioni iniziano a convergere dopo 50 passaggi.Optional, Int 2. approximation_method: metodo per approssimare l'integrale. I metodi di approssimazione disponibili sono riemann_middle e gausslegendre.Optional, String |
n_steps = 50 approximation_method = riemann_middle |
L'algoritmo XRAI usa internamente Integrated Gradients. Pertanto, il parametro n_steps è richiesto sia dagli algoritmi Integrated Gradients che XRAI. Un numero maggiore di passaggi richiede più tempo per approssimare le spiegazioni e può causare problemi di timeout nell'endpoint online.
Per spiegazioni migliori, è consigliabile usare gli algoritmi XRAI > Guided GradCAM > Integrated Gradients > Guided BackPropagation, mentre per spiegazioni più veloci sono consigliati gli algoritmi Guided BackPropagation > Guided GradCAM > Integrated Gradients > XRAI nell'ordine specificato.
Una richiesta di campione all'endpoint online è simile alla seguente. Questa richiesta genera spiegazioni quando model_explainability è impostato su True. La richiesta seguente genera visualizzazioni e attribuzioni usando una versione più veloce dell'algoritmo XRAI con 50 passaggi.
import base64
import json
def read_image(image_path):
with open(image_path, "rb") as f:
return f.read()
sample_image = "./test_image.jpg"
# Define explainability (XAI) parameters
model_explainability = True
xai_parameters = {"xai_algorithm": "xrai",
"n_steps": 50,
"xrai_fast": True,
"visualizations": True,
"attributions": True}
# Create request json
request_json = {"input_data": {"columns": ["image"],
"data": [json.dumps({"image_base64": base64.encodebytes(read_image(sample_image)).decode("utf-8"),
"model_explainability": model_explainability,
"xai_parameters": xai_parameters})],
}
}
request_file_name = "sample_request_data.json"
with open(request_file_name, "w") as request_file:
json.dump(request_json, request_file)
resp = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name=deployment.name,
request_file=request_file_name,
)
predictions = json.loads(resp)
Per altre informazioni sulla generazione di spiegazioni, vedere il repository di notebook GitHub per esempi di Machine Learning automatizzato.
Interpretazione delle visualizzazioni
L'endpoint distribuito restituisce una stringa di immagine con codifica Base64 se sia model_explainability che visualizations sono impostati su True. Decodificare la stringa Base64 come descritto in Notebook o usare il codice seguente per decodificare e visualizzare le stringhe di immagini Base64 nella previsione.
import base64
from io import BytesIO
from PIL import Image
def base64_to_img(base64_img_str):
base64_img = base64_img_str.encode("utf-8")
decoded_img = base64.b64decode(base64_img)
return BytesIO(decoded_img).getvalue()
# For Multi-class classification:
# Decode and visualize base64 image string for explanations for first input image
# img_bytes = base64_to_img(predictions[0]["visualizations"])
# For Multi-label classification:
# Decode and visualize base64 image string for explanations for first input image against one of the classes
img_bytes = base64_to_img(predictions[0]["visualizations"][0])
image = Image.open(BytesIO(img_bytes))
L'immagine seguente descrive la visualizzazione delle spiegazioni per un'immagine di input di esempio.

La figura Base64 decodificata ha quattro sezioni di immagine all'interno di una griglia 2 x 2.
- L'immagine nell'angolo in alto a sinistra (0, 0) è l'immagine di input ritagliata
- L'immagine nell'angolo in alto a destra (0, 1) è la mappa termica delle attribuzioni su una scala di colori blu-verde-giallo-bianco in cui il contributo dei pixel bianchi nella classe prevista corrisponde il pixel massimo e quello blu al minimo.
- L'immagine nell'angolo in basso a sinistra (1, 0) è la mappa termica combinata di attribuzioni sull'immagine di input ritagliata
- L'immagine nell'angolo in basso a destra (1, 1) è l'immagine di input ritagliata con il 30% superiore dei pixel in base ai punteggi di attribuzione.
Interpretazione delle attribuzioni
L'endpoint distribuito restituisce attribuzioni se sia model_explainability che attributions sono impostati su True. Per altre informazioni, vedere Notebook di classificazione multiclasse e di classificazione multietichetta.
Queste attribuzioni offrono maggiore controllo agli utenti per generare visualizzazioni personalizzate o per esaminare i punteggi di attribuzione a livello di pixel. Il frammento di codice seguente descrive un modo per generare visualizzazioni personalizzate usando la matrice di attribuzione. Per altre informazioni sullo schema di attribuzioni per la classificazione multiclasse e la classificazione multietichetta, vedere la documentazione degli schemi.
Usare i valori valid_resize_size e valid_crop_size esatti del modello selezionato per generare le spiegazioni (i valori predefiniti sono rispettivamente 256 e 224). Il codice seguente usa funzionalità di visualizzazione Captum per generare visualizzazioni personalizzate. Gli utenti possono utilizzare qualsiasi altra libreria per generare visualizzazioni. Per altri dettagli, vedere le utilità di visualizzazione Captum.
import colorcet as cc
import numpy as np
from captum.attr import visualization as viz
from PIL import Image
from torchvision import transforms
def get_common_valid_transforms(resize_to=256, crop_size=224):
return transforms.Compose([
transforms.Resize(resize_to),
transforms.CenterCrop(crop_size)
])
# Load the image
valid_resize_size = 256
valid_crop_size = 224
sample_image = "./test_image.jpg"
image = Image.open(sample_image)
# Perform common validation transforms to get the image used to generate attributions
common_transforms = get_common_valid_transforms(resize_to=valid_resize_size,
crop_size=valid_crop_size)
input_tensor = common_transforms(image)
# Convert output attributions to numpy array
# For Multi-class classification:
# Selecting attribution matrix for first input image
# attributions = np.array(predictions[0]["attributions"])
# For Multi-label classification:
# Selecting first attribution matrix against one of the classes for first input image
attributions = np.array(predictions[0]["attributions"][0])
# visualize results
viz.visualize_image_attr_multiple(np.transpose(attributions, (1, 2, 0)),
np.array(input_tensor),
["original_image", "blended_heat_map"],
["all", "absolute_value"],
show_colorbar=True,
cmap=cc.cm.bgyw,
titles=["original_image", "heatmap"],
fig_size=(12, 12))
Set di dati di grandi dimensioni
Se si usa AutoML per eseguire il training su set di dati di grandi dimensioni, potrebbero essere utili alcune impostazioni sperimentali.
Importante
Queste impostazioni sono attualmente disponibili in anteprima pubblica. Vengono fornite senza un contratto di servizio. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Training multi-GPU e multinodo
Per impostazione predefinita, il training di ogni modello viene eseguito in una singola macchina virtuale. Se il training di un modello richiede troppo tempo, può risultare utile usare macchine virtuali che contengono più GPU. Il tempo necessario per eseguire il training di un modello su set di dati di grandi dimensioni dovrebbe diminuire in proporzione approssimativamente lineare in base al numero di GPU usate. Ad esempio, il training di un modello dovrebbe essere eseguito approssimativamente due volte più velocemente usando una VM con due GPU rispetto a una con una singola GPU. Se il tempo necessario per eseguire il training di un modello è ancora elevato in una macchina virtuale con più GPU, è possibile aumentare il numero di VM usate per il training di ogni modello. Analogamente al training con più GPU, il tempo necessario per eseguire il training di un modello su set di dati di grandi dimensioni dovrebbe anche diminuire in proporzione approssimativamente lineare in base al numero di macchine virtuali usate. Quando si esegue il training di un modello tra più macchine virtuali, assicurarsi di usare uno SKU di calcolo che supporta InfiniBand per risultati ottimali. È possibile configurare il numero di macchine virtuali usate per il training di un singolo modello impostando la proprietà node_count_per_trial del processo di AutoML.
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
properties:
node_count_per_trial: "2"
Streaming di file di immagine dall'archiviazione
Per impostazione predefinita, tutti i file di immagine vengono scaricati su disco prima del training del modello. Se le dimensioni dei file di immagine sono maggiori dello spazio disponibile su disco, il processo non riesce. Invece di scaricare tutte le immagini su disco, è possibile scegliere di trasmettere i file di immagine in streaming dall'archiviazione di Azure quando sono necessari durante il training. I file di immagine vengono trasmessi in streaming direttamente dall'archiviazione di Azure alla memoria di sistema, bypassando il disco. Allo stesso tempo, il maggior numero possibile di file trasmessi dalla risorsa di archiviazione viene memorizzato nella cache su disco per ridurre al minimo il numero di richieste di archiviazione.
Nota
Se lo streaming è abilitato, assicurarsi che l'account di archiviazione di Azure si trovi nella stessa area dell'ambiente di calcolo per ridurre al minimo i costi e la latenza.
SI APPLICA A:Estensione ML dell'interfaccia della riga di comando di Azure v2 (corrente)
training_parameters:
advanced_settings: >
{"stream_image_files": true}
Notebook di esempio
Esaminare esempi di codice e casi d'uso dettagliati nel repository di notebook GitHub per esempi di Machine Learning automatizzato. Controllare la presenza di esempi specifici per la creazione di modelli di visione dei computer nelle cartelle con il prefisso 'automl-image-'.
Esempi di codice
Esaminare esempi di codice e casi d'uso dettagliati nel repository di azureml-examples per esempi di Machine Learning automatizzato.