Router di inferenza e requisiti di connettività di Azure Machine Learning
Il router di inferenza di Azure Machine Learning è un componente critico per l'inferenza in tempo reale con il cluster Kubernetes. Questo articolo contiene informazioni relative agli argomenti seguenti:
- Definizione di router di inferenza di Azure Machine Learning
- Funzionamento della scalabilità automatica
- Come configurare e soddisfare le prestazioni delle richieste di inferenza (numero di richieste al secondo e latenza)
- Requisiti di connettività per il cluster di inferenza del servizio Azure Kubernetes
Definizione di router di inferenza di Azure Machine Learning
Il router di inferenza di Azure Machine Learning è il componente front-end (azureml-fe) distribuito nel cluster del servizio Azure Kubernetes o Arc Kubernetes in fase di distribuzione dell'estensione di Azure Machine Learning. Dispone delle funzioni seguenti:
- Instrada le richieste di inferenza in ingresso dal servizio di bilanciamento del carico del cluster o dal controller di ingresso ai pod del modello corrispondenti.
- Bilancia il carico di tutte le richieste di inferenza in ingresso con routing coordinato intelligente.
- Gestisce il ridimensionamento automatico dei pod del modello.
- Capacità di failover e a tolleranza di errore, assicura che le richieste di inferenza vengano sempre gestite per applicazioni aziendali critiche.
I passaggi seguenti illustrano come le richieste vengono elaborate dal front-end:
- Il client invia una richiesta al servizio di bilanciamento del carico.
- Il servizio di bilanciamento del carico la invia a uno dei front-end.
- Il front-end individua il router del servizio (l'istanza front-end che funge da coordinatore) per il servizio.
- Il router del servizio seleziona un back-end e lo restituisce al front-end.
- Il front-end inoltra la richiesta al back-end.
- Dopo l'elaborazione della richiesta, il back-end invia una risposta al componente front-end.
- Il front-end propaga la risposta al client.
- Il front-end informa il router del servizio che il back-end ha terminato l'elaborazione ed è disponibile per altre richieste.
Il diagramma seguente illustra questo flusso:
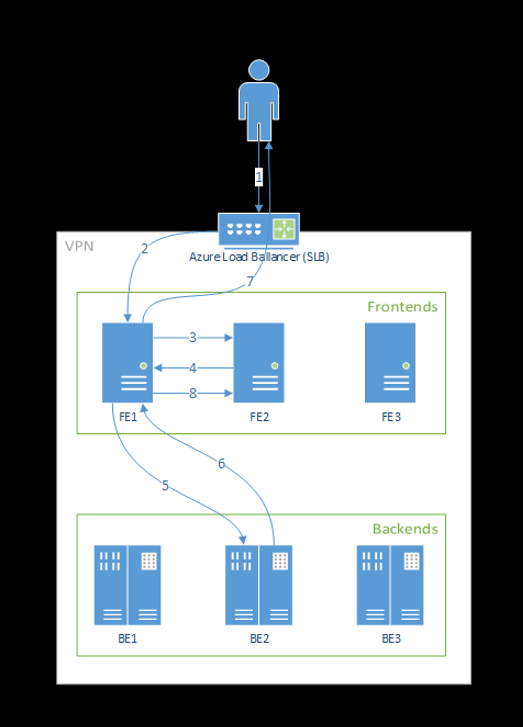
Come si può notare dal diagramma precedente, per impostazione predefinita vengono create tre istanze di azureml-fe durante la distribuzione dell'estensione di Azure Machine Learning, un'istanza funge da ruolo di coordinamento e le altre istanze servono richieste di inferenza in ingresso. L'istanza di coordinamento contiene tutte le informazioni e prende decisioni sui pod del modello per gestire la richiesta in ingresso, mentre le istanze di azureml-fe di servizio sono responsabili del routing della richiesta al pod del modello selezionato e propagano la risposta all'utente originale.
Scalabilità automatica
Il router di inferenza di Azure Machine Learning gestisce la scalabilità automatica per tutte le distribuzioni di modelli nel cluster Kubernetes. Poiché tutte le richieste di inferenza passano attraverso di esso, questo dispone dei dati necessari per scalare automaticamente i modelli distribuiti.
Importante
Non abilitare Horizontal Pod Autoscaler (HPA) Kubernetes per le distribuzioni di modelli. In questo modo, i due componenti di ridimensionamento automatico possono competere tra loro. Azureml-fe è stato progettato per ridimensionare automaticamente i modelli distribuiti da Azure Machine Learning, in cui HPA deve indovinare o approssimare l'utilizzo del modello da una metrica generica, ad esempio l'utilizzo della CPU o una configurazione della metrica personalizzata.
Azureml-fe non ridimensiona il numero di nodi in un cluster del servizio Azure Kubernetes, poiché ciò potrebbe causare un aumento imprevisto dei costi. Ridimensiona invece il numero di repliche per il modello entro i limiti del cluster fisico. Se è necessario dimensionare il numero di nodi all'interno del cluster, è possibile dimensionare manualmente il cluster o configurare il dimensionamento automatico del cluster del servizio Azure Kubernetes.
La scalabilità automatica può essere controllata dalla proprietà scale_settings nella distribuzione YAML. L'esempio seguente illustra come abilitare la scalabilità automatica:
# deployment yaml
# other properties skipped
scale_setting:
type: target_utilization
min_instances: 3
max_instances: 15
target_utilization_percentage: 70
polling_interval: 10
# other deployment properties continue
La decisione di aumentare o ridurre le prestazioni è basata su utilization of the current container replicas.
utilization_percentage = (The number of replicas that are busy processing a request + The number of requests queued in azureml-fe) / The total number of current replicas
Se questo numero supera target_utilization_percentage, vengono create più repliche. Se è inferiore, le repliche vengono ridotte. Per impostazione predefinita, l'utilizzo della destinazione è del 70%.
Le decisioni per aggiungere repliche sono veloci e immediate (circa 1 secondo). Le decisioni per rimuovere le repliche sono conservative (circa 1 minuto).
Ad esempio, se si vuole distribuire un servizio modello e si vuole sapere quante istanze (pod/repliche) devono essere configurate per le richieste di destinazione al secondo (RPS) e il tempo di risposta di destinazione. È possibile calcolare le repliche necessarie usando il codice seguente:
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
Prestazioni di azureml-fe
azureml-fe può raggiungere 5.000 richieste al secondo (QPS) con una buona latenza, con un sovraccarico che non supera i 3 ms in media e 15 ms al 99% percentile.
Nota
Se sono presenti requisiti RPS superiori a 10.000, prendere in considerazione le opzioni seguenti:
- Aumentare le richieste o i limiti delle risorse per i pod
azureml-fe; per impostazione predefinita ha 2 vCPU e un limite di risorse di memoria 1,2 G. - Aumentare il numero di istanze per
azureml-fe. Per impostazione predefinita, Azure Machine Learning crea 3 o 1 istanzeazureml-feper cluster.- Questo numero di istanze dipende dalla configurazione di
inferenceRouterHAdell'entensione di Azure Machine Learning. - Il numero di istanze aumentato non può essere conservato, poiché verrà sovrascritto con il valore configurato dopo l'aggiornamento dell'estensione.
- Questo numero di istanze dipende dalla configurazione di
- Contattare gli esperti Microsoft per assistenza.
Informazioni sui requisiti di connettività per il cluster di inferenza del servizio Azure Kubernetes
Il cluster del servizio Azure Kubernetes viene distribuito con uno dei due modelli di rete seguenti:
- Funzionalità di rete kubenet: le risorse di rete vengono in genere create e configurate quando viene distribuito il cluster del servizio Azure Kubernetes.
- Networking di Azure Container Networking Interface: il cluster del servizio Azure Kubernetes viene connesso alle configurazioni e alla risorsa di rete virtuale esistenti.
Per la rete Kubenet, la rete viene creata e configurata in modo appropriato per il servizio Azure Machine Learning. Per la rete CNI, è necessario comprendere i requisiti di connettività e garantire la risoluzione DNS e la connettività in uscita per l'inferenza del servizio Azure Kubernetes. Ad esempio, potrebbe essere necessario eseguire passaggi aggiuntivi se si usa un firewall per bloccare il traffico di rete.
Il diagramma seguente illustra i requisiti di connettività per l'inferenza del servizio Azure Kubernetes. Le frecce nere rappresentano le comunicazioni effettive e le frecce blu rappresentano i nomi di dominio. Potrebbe essere necessario aggiungere al firewall o al server DNS personalizzato delle voci per questi host.
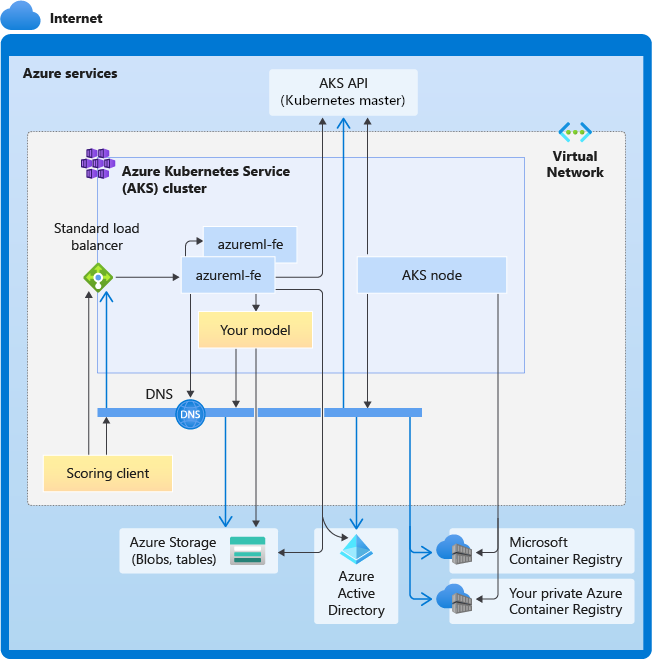
Per i requisiti generali di connettività del servizio Azure Kubernetes, vedere Controllare il traffico in uscita per i nodi del cluster nel servizio Azure Kubernetes.
Per accedere ai servizi di Azure Machine Learning dietro un firewall, vedere Configurare il traffico di rete in ingresso e in uscita.
Requisiti generali di risoluzione DNS
La risoluzione DNS all'interno di una rete virtuale esistente è sotto il proprio controllo. Ad esempio, un firewall o un server DNS personalizzato. Gli host seguenti devono essere raggiungibili:
| Nome host | Usato da |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
Server API del servizio Azure Kubernetes |
mcr.microsoft.com |
Registro Container Microsoft (MCR) |
<ACR name>.azurecr.io |
Registro Azure Container (ACR) dell'utente |
<account>.blob.core.windows.net |
Account di archiviazione di Azure (archiviazione BLOB) |
api.azureml.ms |
Autenticazione Microsoft Entra |
ingest-vienna<region>.kusto.windows.net |
Endpoint Kusto per il caricamento dei dati di telemetria |
Requisiti di connettività in ordine cronologico: dalla creazione del cluster alla distribuzione del modello
Subito dopo la distribuzione, azureml-fe tenterà di avviare e ciò richiede di:
- Risolvere il DNS per il server API del servizio Azure Kubernetes
- Eseguire query sul server API del servizio Azure Kubernetes per individuare altre istanze di se stesso (si tratta di un servizio multi-pod)
- Connettersi ad altre istanze di se stesso
Dopo l'avvio di azureml-fe, per il corretto funzionamento è necessaria la connettività seguente:
- Connettersi ad Archiviazione di Azure per scaricare la configurazione dinamica
- Risolvere il DNS per il server di autenticazione Microsoft Entra api.azureml.ms e comunicare con esso quando il servizio distribuito usa l'autenticazione Microsoft Entra.
- Eseguire query sul server API del servizio Azure Kubernetes per individuare i modelli distribuiti
- Comunicare con i POD del modello distribuiti
In fase di distribuzione del modello, per un nodo del servizio Azure Kubernetes di distribuzione del modello riuscito si dovrebbe essere in grado di:
- Risolvere il DNS per il Registro Azure Container del cliente
- Scaricare immagini dal Registro Azure Container del cliente
- Risolvere Il DNS per BLOB di Azure in cui è archiviato il modello
- Scaricare modelli da BLOB di Azure
Dopo l'avvio del modello e l'avvio del servizio, azureml-fe lo rileverà automaticamente usando l'API del servizio Azure Kubernetes e sarà pronto per instradare la richiesta. Deve essere in grado di comunicare con i POD del modello.
Nota
Se il modello distribuito richiede connettività (ad esempio, l'esecuzione di query su database esterno o altro servizio REST, il download di un BLOB e così via), è necessario abilitare sia la risoluzione DNS che la comunicazione in uscita per tali servizi.