Inviare un processo di training in Studio
Sono disponibili diverse opzioni per creare un processo di training con Azure Machine Learning. È possibile usare l'interfaccia della riga di comando (vedere Eseguire il training di modelli (creare processi), l'API REST (vedere Eseguire il training dei modelli con REST (anteprima) oppure usare l'interfaccia utente per creare direttamente un processo di training. Questo articolo illustra come usare dati e codice personalizzati per eseguire il training di un modello di Machine Learning con un'esperienza guidata per l'invio di processi di training in studio di Azure Machine Learning.
Importante
Questa funzionalità è attualmente in anteprima pubblica. Questa versione di anteprima viene fornita senza un contratto di servizio e non è consigliabile per i carichi di lavoro di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate.
Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Prerequisiti
Una sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare. Provare la versione gratuita o a pagamento di Azure Machine Learning.
Un'area di lavoro di Azure Machine Learning. Vedere Creare risorse dell'area di lavoro.
Informazioni sul processo in Azure Machine Learning. Vedere come eseguire il training dei modelli.
Operazioni preliminari
Accedere ad Azure Machine Learning Studio.
Selezionare la sottoscrizione e l’area di lavoro.
- È possibile immettere l'interfaccia utente di creazione del processo dalla home page. Selezionare Crea nuovo e selezionare Processo.
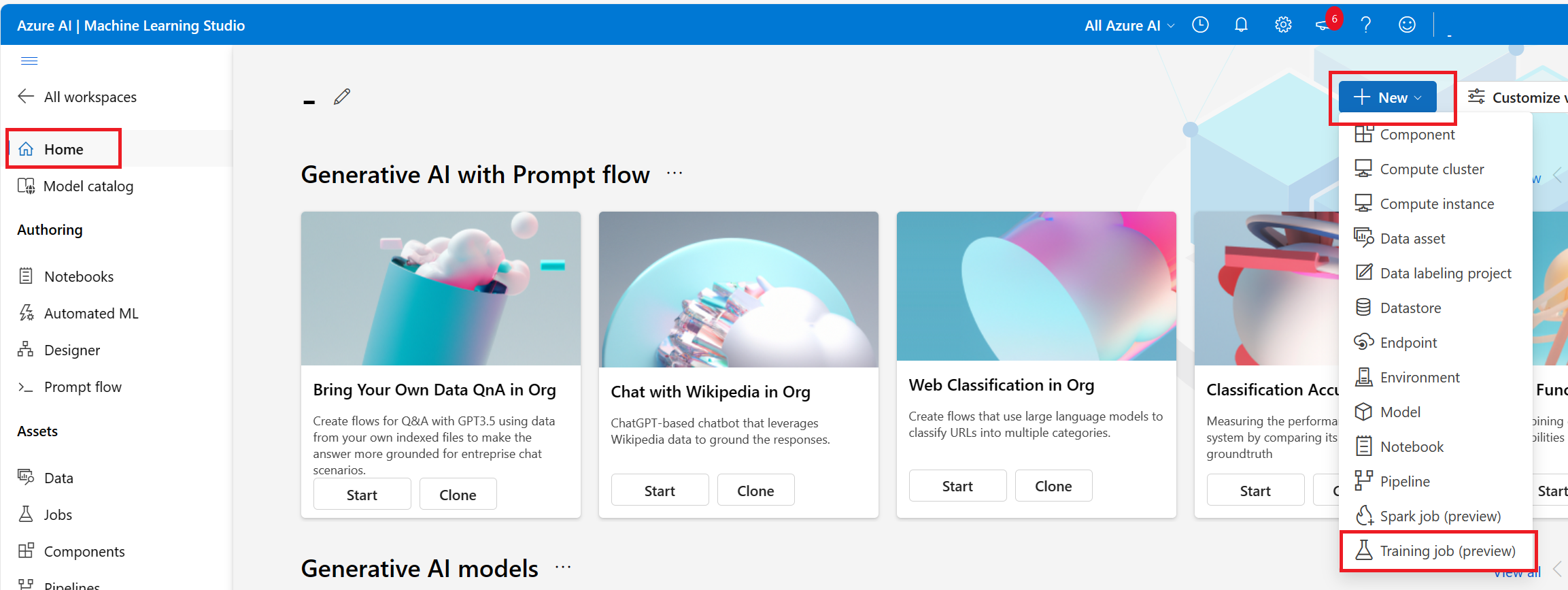
In questo passaggio è possibile selezionare il metodo di training, completare il resto del modulo di invio in base alla selezione e inviare il processo di training. Di seguito viene illustrato il modulo con i passaggi per l'esecuzione di uno script personalizzato (processo di comando).
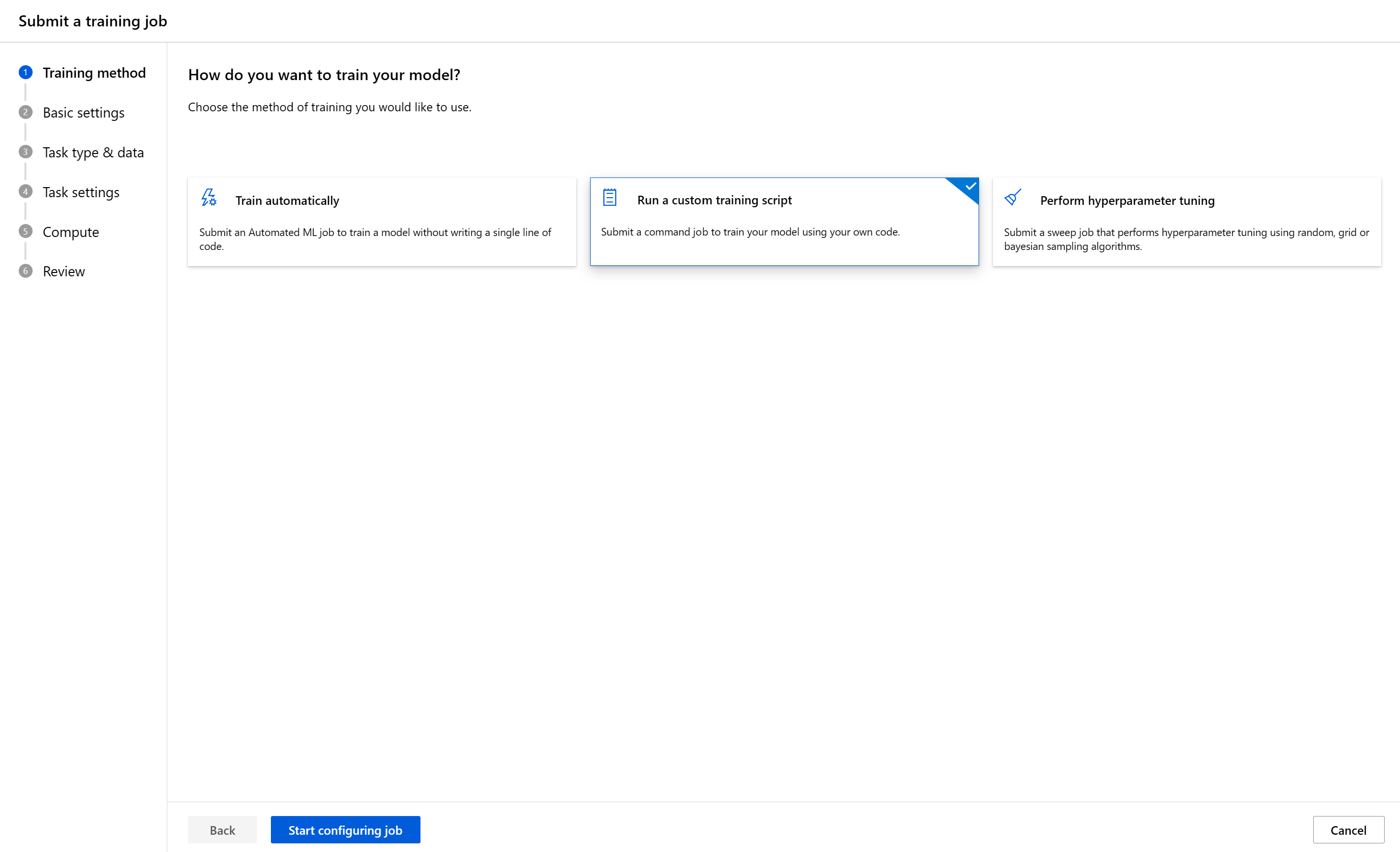
Configurare le impostazioni di base
Il primo passaggio consiste nel configurare informazioni di base sul processo di training. Puoi procedere successivamente se sei soddisfatto delle impostazioni predefinite che abbiamo scelto per te o apportare modifiche alle preferenze desiderate.
Questi sono i campi disponibili:
| Campo | Descrizione |
|---|---|
| Nome processo | Il campo del nome del processo viene usato per identificare in modo univoco il processo. Viene usato anche come nome visualizzato per il processo. |
| Nome dell'esperimento | Ciò consente di organizzare il processo in studio di Azure Machine Learning. Il record di esecuzione di ogni processo è organizzato nell'esperimento corrispondente nella scheda "Experiment" dello studio. Per impostazione predefinita, Azure inserisce il processo nell'esperimento predefinito . |
| Descrizione | Aggiungere del testo che descrive il processo, se necessario. |
| Timeout | Specificare il numero di ore consentite per l'esecuzione dell'intero processo di training. Una volta raggiunto questo limite, il sistema annulla il processo, inclusi tutti i processi figlio. |
| Tag | Aggiungere tag al processo per facilitare l'organizzazione. |
Script di training
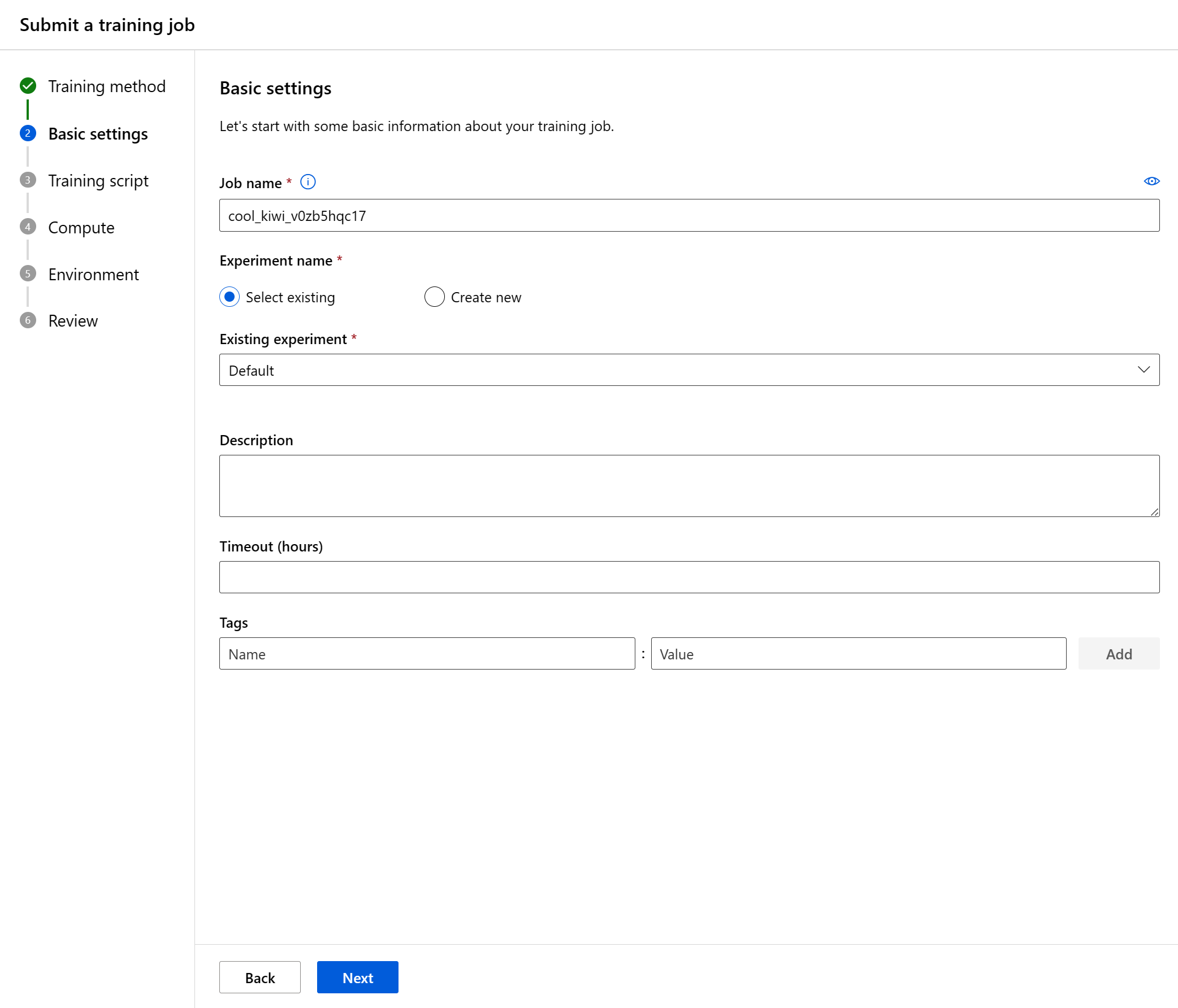
Il passaggio successivo consiste nel caricare il codice sorgente, configurare gli input o gli output necessari per eseguire il processo di training e specificare il comando per eseguire lo script di training.
Può trattarsi di un file di codice o di una cartella dall'archivio BLOB predefinito del computer locale o dell'area di lavoro. Azure mostrerà i file da caricare dopo aver effettuato la selezione.
| Campo | Descrizione |
|---|---|
| Codice | Può trattarsi di un file o di una cartella dal computer locale o dall'archiviazione BLOB predefinita dell'area di lavoro come script di training. Studio mostrerà i file da caricare dopo aver effettuato la selezione. |
| Input | Specificare il numero di input necessario per i tipi seguenti di dati, integer, number, boolean, string). |
| Comando | Comando da eseguire. Gli argomenti della riga di comando possono essere scritti in modo esplicito nel comando o dedotti da altre sezioni, in particolare gli input usando la notazione parentesi graffe, come illustrato nella sezione successiva. |
Codice
Il comando viene eseguito dalla directory radice della cartella del codice caricato. Dopo aver selezionato il file di codice o la cartella, è possibile visualizzare i file da caricare. Copiare il percorso relativo nel codice contenente il punto di ingresso e incollarlo nella casella immettere il comando per avviare il processo.
Se il codice si trova nella directory radice, è possibile farvi riferimento direttamente nel comando . Ad esempio, python main.py.
Se il codice non si trova nella directory radice, è necessario usare il percorso relativo. Ad esempio, la struttura del modello linguistico delle parole è:
.
├── job.yml
├── data
└── src
└── main.py
In questo caso, il codice sorgente si trova nella src sottodirectory . Il comando sarà python ./src/main.py (più altri argomenti della riga di comando).
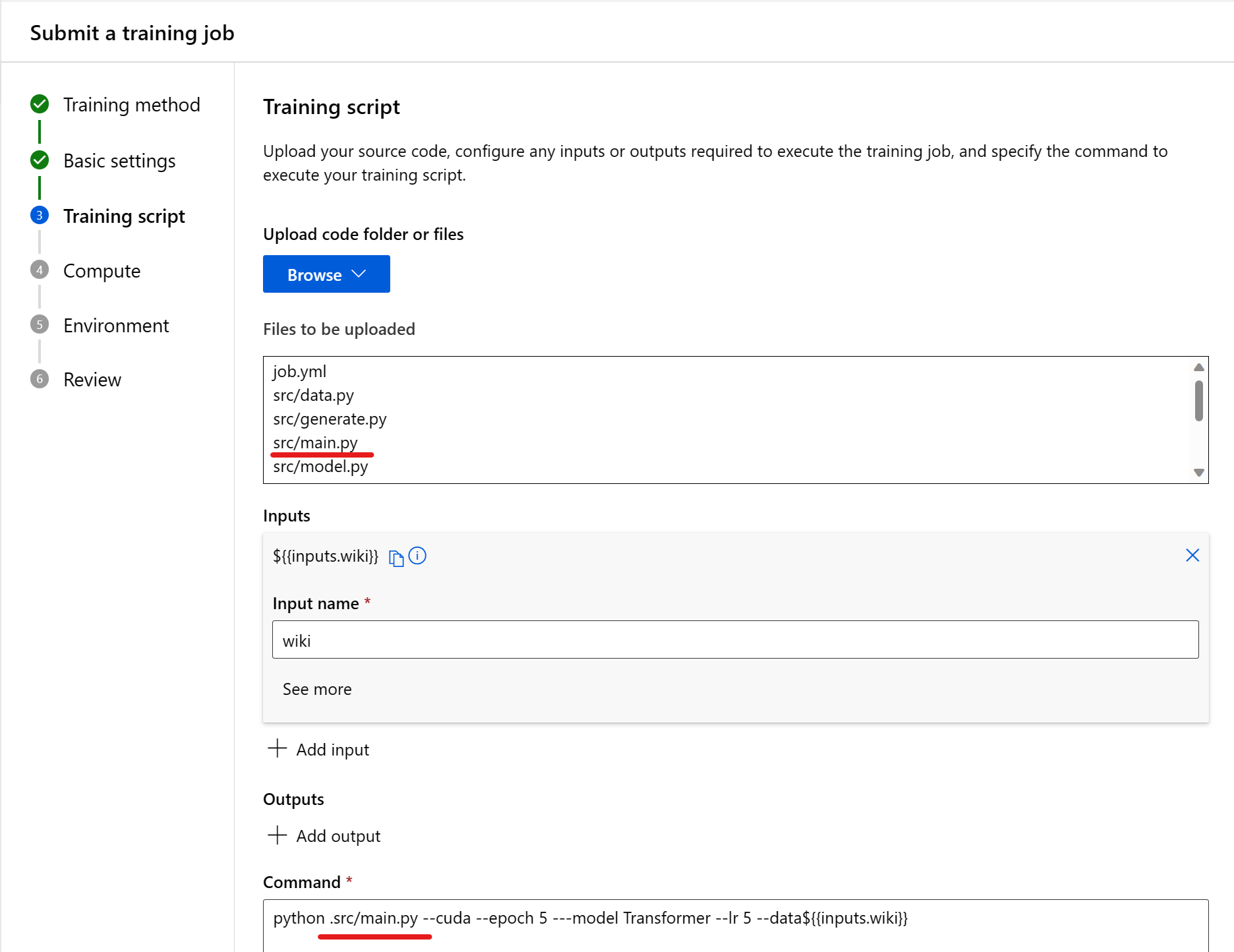
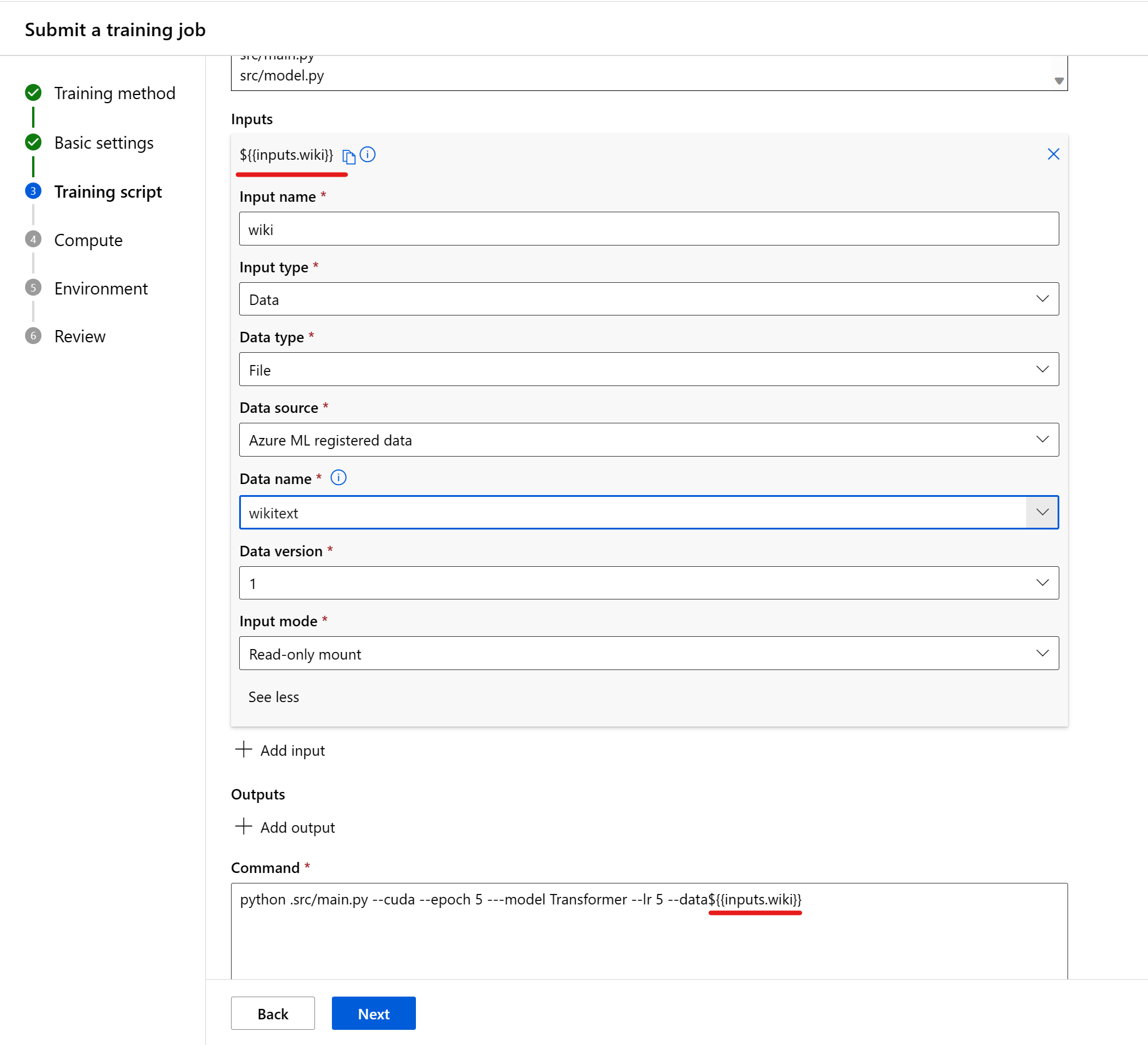
Input
Quando si usa un input nel comando, è necessario specificare il nome di input. Per indicare una variabile di input, usare il modulo ${{inputs.input_name}}. Ad esempio, ${{inputs.wiki}}. È quindi possibile farvi riferimento nel comando , --data ${{inputs.wiki}}ad esempio .
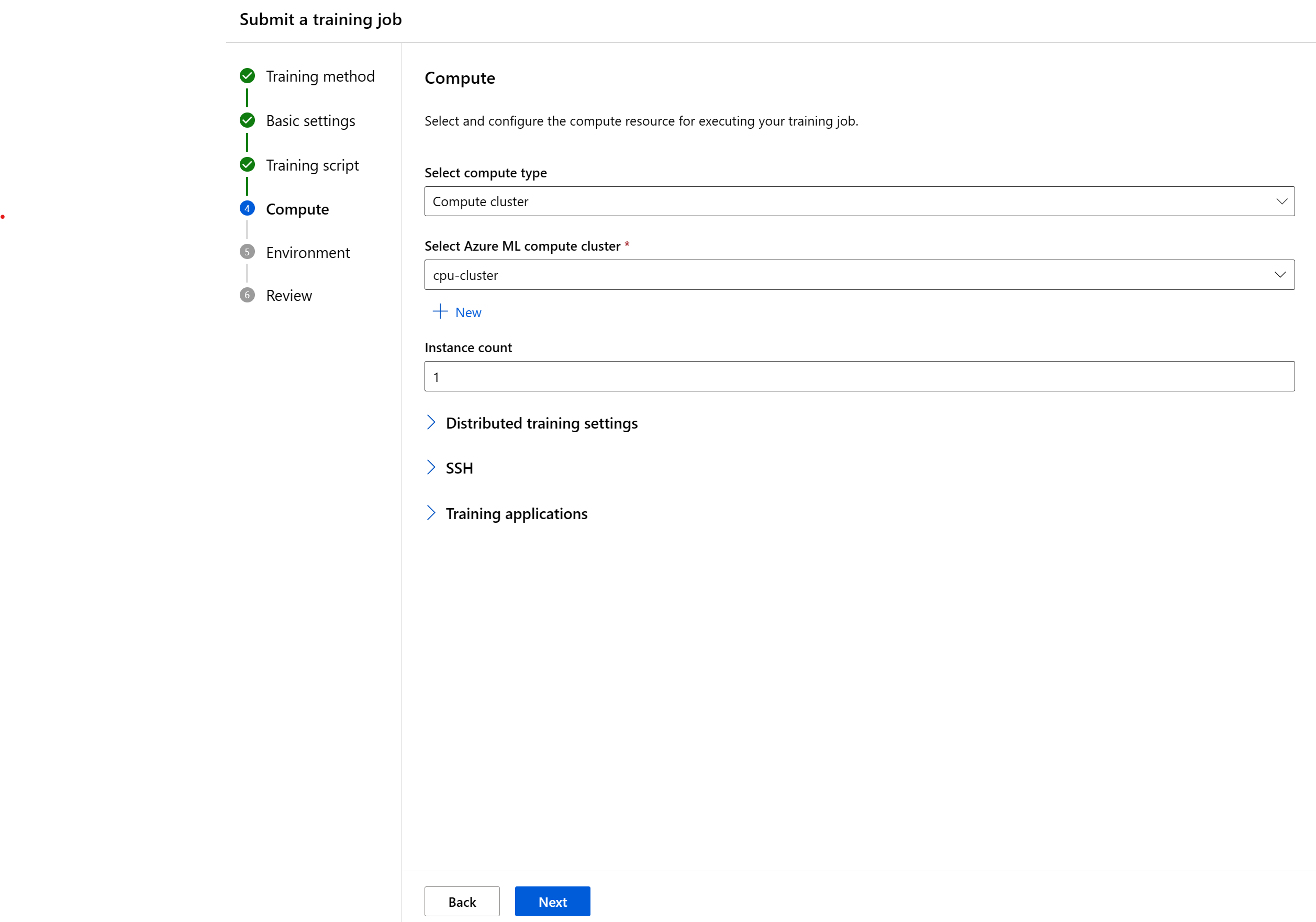
Selezionare le risorse di calcolo
Il passaggio successivo consiste nel selezionare la destinazione di calcolo in cui si vuole eseguire il processo. L'interfaccia utente per la creazione di processi supporta diversi tipi di calcolo:
| Tipo di ambiente di calcolo | Introduzione |
|---|---|
| Istanza di calcolo | Che cos'è un'istanza di calcolo di Azure Machine Learning? |
| Cluster di elaborazione | Che cos'è un cluster di calcolo? |
| Calcolo collegato (cluster Kubernetes) | Configurare e collegare un cluster Kubernetes ovunque (anteprima). |
- Selezionare un tipo di calcolo
- Selezionare una risorsa di calcolo esistente. L'elenco a discesa mostra le informazioni sul nodo e il tipo di SKU per facilitare la scelta.
- Per un cluster di calcolo o un cluster Kubernetes, è anche possibile specificare il numero di nodi desiderati per il processo in Numero di istanze. Il numero predefinito di istanze è 1.
- Quando sei soddisfatto delle tue scelte, scegli Avanti.
Se si usa Azure Machine Learning per la prima volta, viene visualizzato un elenco vuoto e un collegamento per creare un nuovo ambiente di calcolo. Per altre informazioni sulla creazione dei vari tipi, vedere:
| Tipo di ambiente di calcolo | Procedura |
|---|---|
| Istanza di calcolo | Creare un'istanza di calcolo di Azure Machine Learning |
| Cluster di elaborazione | Creare un cluster di calcolo di Azure Machine Learning |
| Cluster Kubernetes collegato | Collegare un cluster Kubernetes abilitato per Azure Arc |
Specificare l'ambiente necessario
Dopo aver selezionato una destinazione di calcolo, è necessario specificare l'ambiente di runtime per il processo. L'interfaccia utente di creazione del processo supporta tre tipi di ambiente:
- Ambienti dedicati
- Ambienti personalizzati
- Immagine del registro contenitori
Ambienti dedicati
Gli ambienti curati sono raccolte di pacchetti Python definiti da Azure usati nei carichi di lavoro di Machine Learning comuni. Gli ambienti curati sono disponibili nell'area di lavoro per impostazione predefinita. Questi ambienti sono supportati da immagini Docker memorizzate nella cache, riducendo il sovraccarico di preparazione del processo. Le schede visualizzate nella pagina "Ambienti curati" mostrano i dettagli di ogni ambiente. Per altre informazioni, vedere Ambienti curati in Azure Machine Learning.
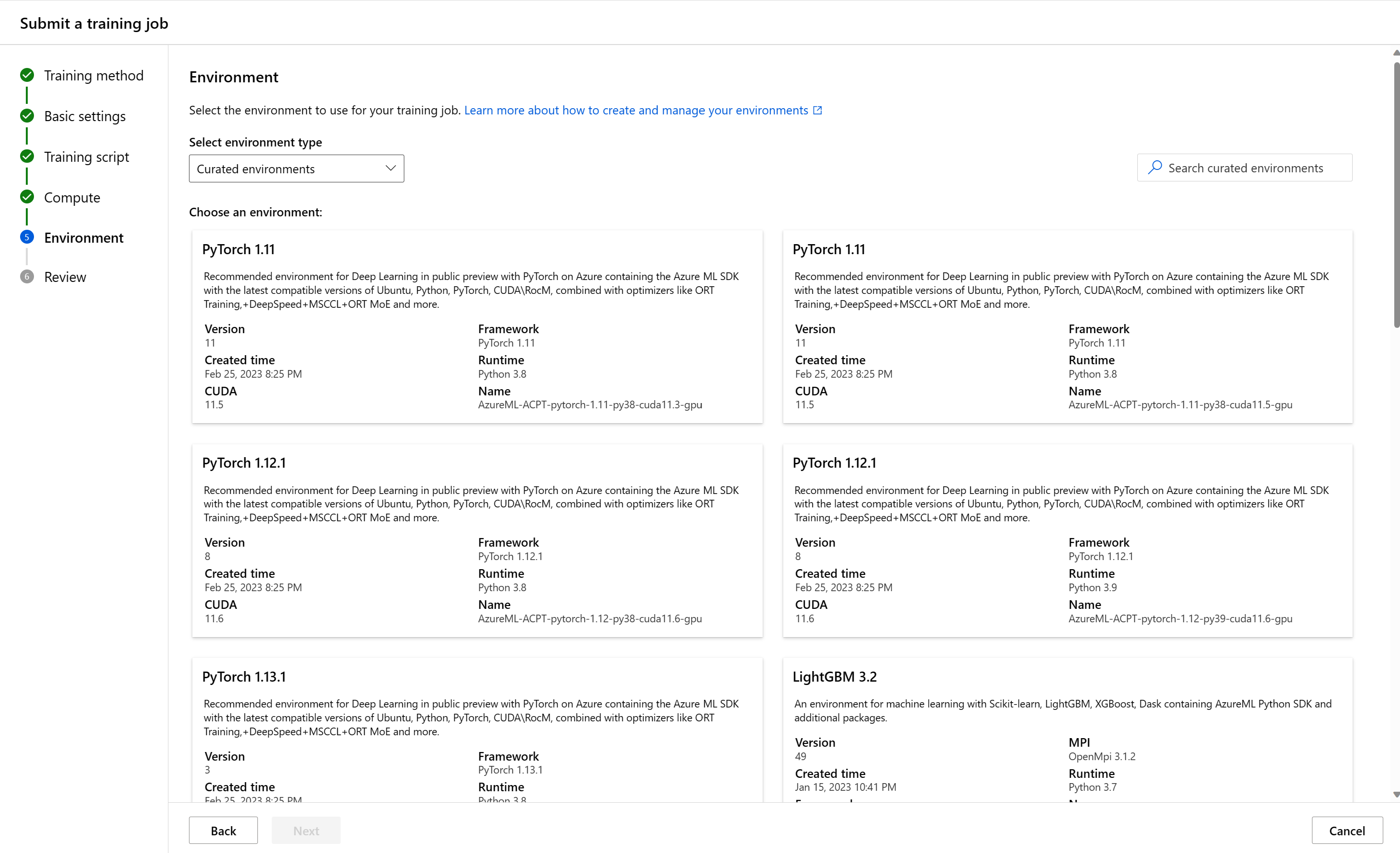
Ambienti personalizzati
Gli ambienti personalizzati sono ambienti specificati dall'utente. È possibile specificare un ambiente o riutilizzare un ambiente già creato. Per altre informazioni, vedere Gestire gli ambienti software in studio di Azure Machine Learning (anteprima).
Immagine del registro contenitori
Se non si vuole usare gli ambienti curati di Azure Machine Learning o specificare il proprio ambiente personalizzato, è possibile usare un'immagine Docker da un registro contenitori pubblico, ad esempio Docker Hub.
Rivedi e crea
Dopo aver configurato il processo, scegliere Avanti per passare alla pagina Revisione . Per modificare un'impostazione, scegliere l'icona a forma di matita e apportare la modifica.

Per avviare il processo, scegliere Invia processo di training. Dopo aver creato il processo, Azure mostra la pagina dei dettagli del processo, in cui è possibile monitorare e gestire il processo di training.
Come configurare i messaggi di posta elettronica in Studio
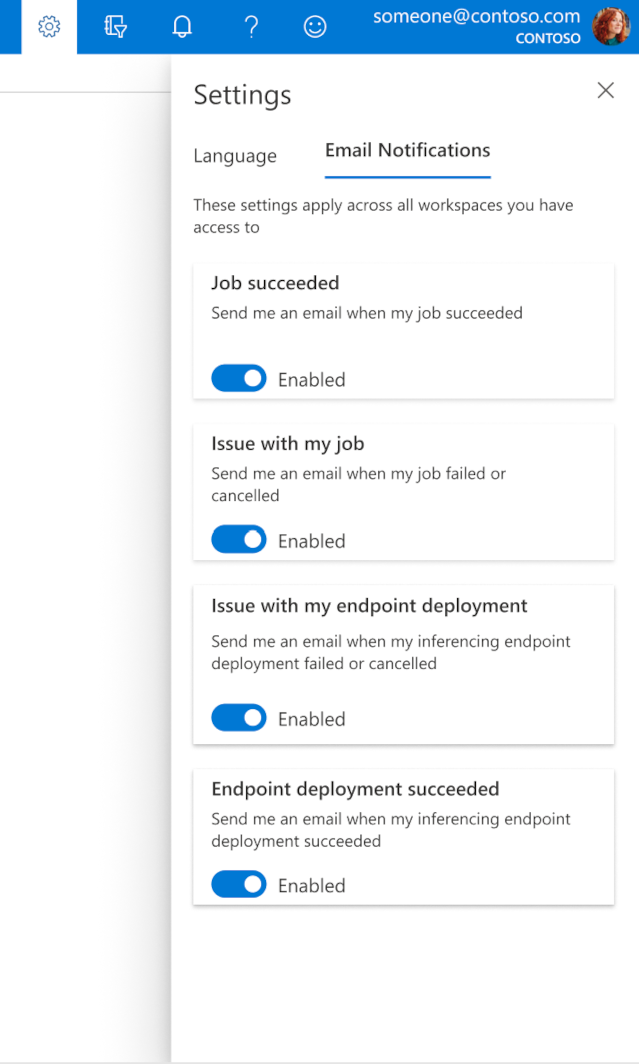
Per iniziare a ricevere messaggi di posta elettronica quando il processo, l'endpoint online o l'endpoint batch è stato completato o se si verifica un problema (non riuscito, annullato), seguire questa procedura:
- In Azure ML Studio passare alle impostazioni selezionando l'icona a forma di ingranaggio.
- Selezionare la scheda Notifiche tramite posta elettronica .
- Attivare o disabilitare le notifiche tramite posta elettronica per un evento specifico.
Passaggi successivi
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per