Tenere traccia degli esperimenti e dei modelli di Machine Learning con MLflow
Questo articolo illustra come usare MLflow per tenere traccia degli esperimenti e delle esecuzioni nelle aree di lavoro di Azure Machine Learning.
Il rilevamento è il processo di salvataggio delle informazioni pertinenti sugli esperimenti eseguiti. Le informazioni salvate (metadati) variano in base al progetto e possono includere:
- Codice
- Dettagli dell'ambiente (ad esempio versione del sistema operativo, pacchetti Python)
- Dati di input
- Configurazioni dei parametri
- Modelli
- Metriche di valutazione
- Visualizzazioni di valutazione (ad esempio matrici di confusione, grafici di importanza)
- Risultati della valutazione (incluse alcune stime di valutazione)
Quando si lavora con i processi in Azure Machine Learning, Azure Machine Learning tiene automaticamente traccia di alcune informazioni sugli esperimenti, ad esempio codice, ambiente e dati di input e output. Per altre informazioni, ad esempio modelli, parametri e metriche, tuttavia, il generatore di modelli deve configurare il relativo rilevamento, in quanto sono specifiche di un determinato scenario.
Nota
Per tenere traccia degli esperimenti in esecuzione in Azure Databricks, vedere Tenere traccia degli esperimenti di Machine Learning in Azure Databricks con MLflow e Azure Machine Learning. Per informazioni sul rilevamento degli esperimenti in esecuzione in Azure Synapse Analytics, vedere Tenere traccia degli esperimenti di Machine Learning in Azure Synapse Analytics con MLflow e Azure Machine Learning.
Vantaggi del rilevamento di esperimenti
È consigliabile che i professionisti in ambito di apprendimento automatico tengano traccia degli esperimenti, indipendentemente dal fatto che si stia eseguendo il training con processi in Azure Machine Learning o che si esegua il training in modo interattivo nei notebook. Il rilevamento di esperimenti consente di:
- Organizzare tutti gli esperimenti di Machine Learning in un'unica posizione. È quindi possibile cercare e filtrare gli esperimenti ed eseguire il drill-down per visualizzare i dettagli sugli esperimenti eseguiti in precedenza.
- Confrontare esperimenti, analizzare i risultati ed eseguire il debug del training del modello con poco lavoro aggiuntivo.
- Riprodurre o rieseguire esperimenti per convalidare i risultati.
- Migliorare la collaborazione, poiché è possibile vedere cosa stanno facendo gli altri colleghi, condividere i risultati dell'esperimento e accedere ai dati dell'esperimento a livello di codice.
Perché usare MLflow per tenere traccia degli esperimenti?
Le aree di lavoro di Azure Machine Learning sono compatibili con MLflow, il che significa che è possibile usare MLflow per tenere traccia di esecuzioni, metriche, parametri e artefatti all'interno delle aree di lavoro di Azure Machine Learning. Uno dei vantaggi principali dell'uso di MLflow per il rilevamento è che non è necessario modificare le routine di training per usare Azure Machine Learning o inserire una sintassi specifica del cloud.
Per altre informazioni su tutte le funzionalità di MLflow e Azure Machine Learning supportate, vedere MLflow e Azure Machine Learning.
Limiti
Alcuni metodi disponibili nell'API MLflow potrebbero non essere disponibili quando si è connessi ad Azure Machine Learning. Per informazioni dettagliate sulle operazioni supportate e non supportate, vedere Matrice di supporto per query su esecuzioni ed esperimenti.
Prerequisiti
- Una sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare. Provare la versione gratuita o a pagamento di Azure Machine Learning.
Installare il pacchetto MLflow SDK
mlflowe il plug-in di Azure Machine Learningazureml-mlflowper MLflow:pip install mlflow azureml-mlflowSuggerimento
È possibile usare il pacchetto
mlflow-skinny, che è un pacchetto di MLflow leggero senza risorse di archiviazione SQL, server, interfaccia utente o dipendenze di data science.mlflow-skinnyè consigliabile per gli utenti che necessitano principalmente delle funzionalità di rilevamento e registrazione di MLflow senza importare la suite completa di funzionalità, incluse le distribuzioni.Un'area di lavoro di Azure Machine Learning. Per creare un'area di lavoro, vedere l'esercitazione Creare risorse di apprendimento automatico. Rivedere le autorizzazioni di accesso necessarie per eseguire operazioni MLflow nell'area di lavoro.
Se si esegue il rilevamento remoto, cioè si monitorano esperimenti in esecuzione all'esterno di Azure Machine Learning, configurare MLflow in modo che punti all'URI di rilevamento dell'area di lavoro di Azure Machine Learning. Per altre informazioni su come connettere MLflow all'area di lavoro, vedere Configurare MLflow per Azure Machine Learning.
Configurare l'esperimento
MLflow organizza le informazioni in esperimenti ed esecuzioni. Le esecuzioni vengono chiamate processi in Azure Machine Learning. Per impostazione predefinita, le esecuzioni vengono registrate in un esperimento denominato Default creato automaticamente. È possibile configurare l'esperimento in cui viene eseguito il rilevamento.
Per il training interattivo, ad esempio in un notebook Jupyter, usare il comando mlflow.set_experiment() di MLflow. Ad esempio, il frammento di codice seguente configura un esperimento:
experiment_name = 'hello-world-example'
mlflow.set_experiment(experiment_name)
Configurare l'esecuzione
Azure Machine Learning tiene traccia di qualsiasi processo di training in quello che MLflow chiama un'esecuzione. Usare le esecuzioni per acquisire tutte le elaborazioni eseguite dal processo.
Quando si lavora in modo interattivo, MLflow inizia a tenere traccia della routine di training non appena si prova a registrare le informazioni che richiedono un'esecuzione attiva. Ad esempio, il rilevamento di MLflow inizia quando si registra una metrica, un parametro o si avvia un ciclo di training e la funzionalità di registrazione automatica di MLflow è abilitata. Tuttavia, risulta in genere utile avviare l'esecuzione in modo esplicito, specialmente se si vuole acquisire il tempo totale per l'esperimento nel campo Duration. Per avviare l'esecuzione in modo esplicito, usare mlflow.start_run().
Indipendentemente dal fatto che l'esecuzione venga avviata manualmente o meno, alla fine è necessario arrestare l'esecuzione, in modo che MLflow sappia che l'esecuzione dell'esperimento è stata completata e possa contrassegnare lo stato dell'esecuzione come Completed. Per arrestare un'esecuzione, usare mlflow.end_run().
È consigliabile avviare manualmente le esecuzioni, in modo da non dimenticare di terminarle quando si lavora nei notebook.
Per avviare un'esecuzione manualmente e terminarla al termine del lavoro nel notebook:
mlflow.start_run() # Your code mlflow.end_run()In genere è utile usare il paradigma del gestore del contesto per ricordarsi di terminare l'esecuzione:
with mlflow.start_run() as run: # Your codeQuando si avvia una nuova esecuzione con
mlflow.start_run(), può essere utile specificare il parametrorun_name, che in seguito viene convertito nel nome dell'esecuzione nell'interfaccia utente di Azure Machine Learning e consente di identificare più rapidamente l'esecuzione:with mlflow.start_run(run_name="hello-world-example") as run: # Your code
Abilitare la registrazione automatica di MLflow
È possibile registrare metriche, parametri e file con MLflow manualmente. Tuttavia, è anche possibile affidarsi alla funzionalità di registrazione automatica di MLflow. Ogni framework di Machine Learning supportato da MLflow decide di quali elementi tenere traccia automaticamente.
Per abilitare la registrazione automatica, inserire il codice seguente prima del codice di training:
mlflow.autolog()
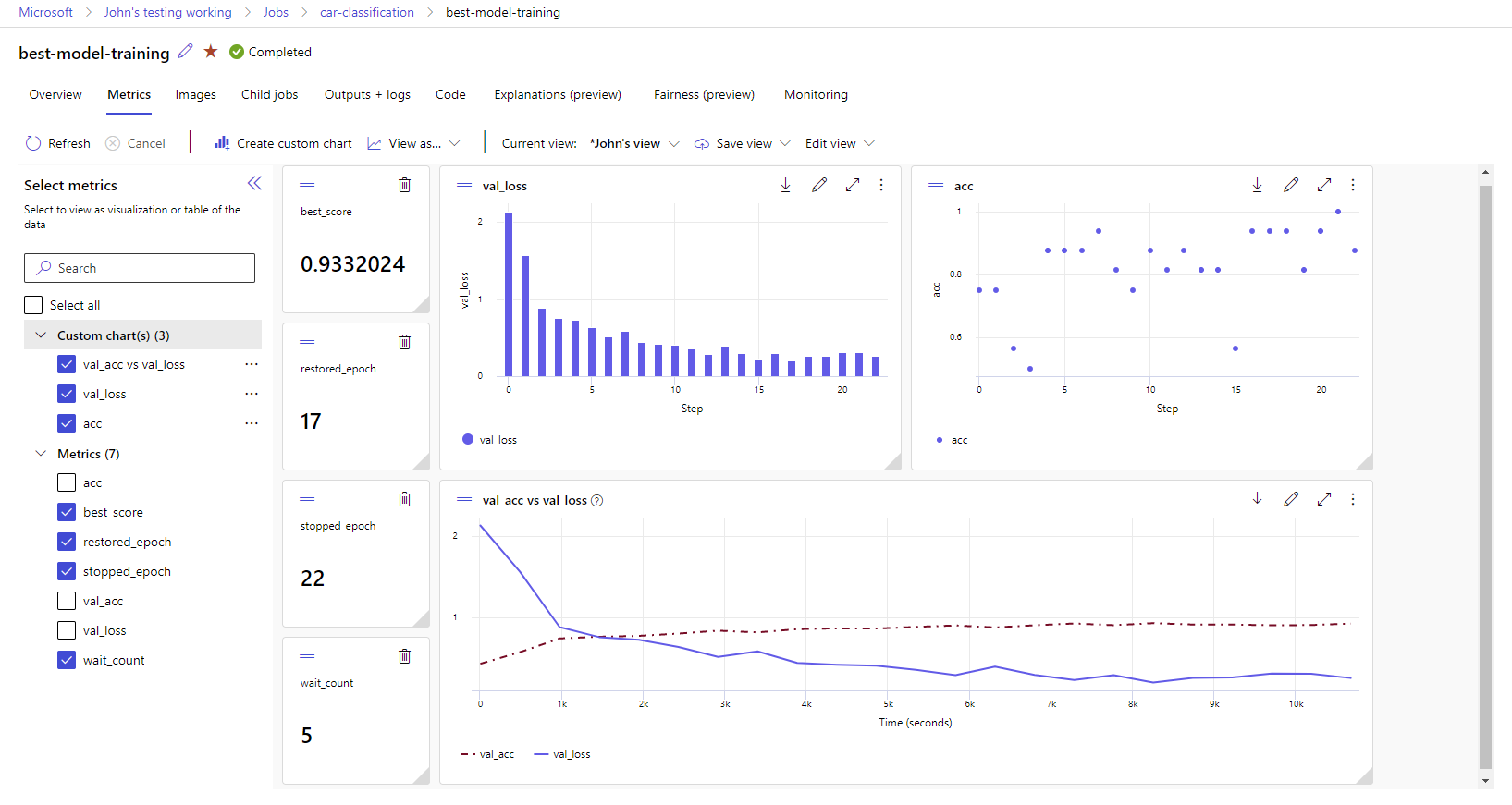
Visualizzare le metriche e gli artefatti nell'area di lavoro
Le metriche e gli artefatti dalla registrazione di MLflow vengono rilevati nell'area di lavoro. È possibile visualizzarli e accedervi nello studio in qualsiasi momento o accedervi a livello di programmazione tramite MLflow SDK.
Per visualizzare metriche e artefatti nello studio:
Passare a Studio di Azure Machine Learning.
Passare all'area di lavoro.
Trovare l'esperimento in base al nome nell'area di lavoro.
Selezionare le metriche registrate per eseguire il rendering dei grafici sul lato destro. È possibile personalizzare i grafici applicando lo smoothing, modificando il colore o tracciando più metriche in un singolo grafico. È anche possibile ridimensionare e riorganizzare il layout come desiderato.
Dopo aver creato la visualizzazione desiderata, salvarla per usarla in futuro e condividerla con i membri del team, usando un collegamento diretto.

Per accedere o eseguire query su metriche, parametri e artefatti a livello di codice tramite MLflow SDK, usare mlflow.get_run().
import mlflow
run = mlflow.get_run("<RUN_ID>")
metrics = run.data.metrics
params = run.data.params
tags = run.data.tags
print(metrics, params, tags)
Suggerimento
Per le metriche, il codice di esempio precedente restituirà solo l'ultimo valore di una determinata metrica. Se si vuole recuperare tutti i valori di una determinata metrica, usare il metodo mlflow.get_metric_history. Per altre informazioni sul recupero dei valori di una metrica, vedere Recupero di parametri e metriche da un'esecuzione.
Per scaricare artefatti registrati, ad esempio file e modelli, usare mlflow.artifacts.download_artifacts().
mlflow.artifacts.download_artifacts(run_id="<RUN_ID>", artifact_path="helloworld.txt")
Per altre informazioni su come recuperare o confrontare informazioni da esperimenti ed esecuzioni in Azure Machine Learning, usando MLflow, vedere Eseguire query e confrontare esperimenti ed esecuzioni con MLflow.