Introduzione a Service Fabric Reliable Actors
Reliable Actors è un framework di applicazione Service Fabric basato sul criterio Actor virtuale. L'API Reliable Actors offre un modello di programmazione a thread singolo basato sulle garanzie di affidabilità e scalabilità offerte da Service Fabric.
Che cosa sono gli attori?
Un attore è un'unità isolata e indipendente di calcolo e di stato con esecuzione a thread singolo. Il criterio Actor è un modello di calcolo per sistemi simultanei o distribuiti in cui è possibile eseguire un numero elevato di attori simultaneamente e indipendente. Gli attori possono comunicare tra loro e possono creare altri attori.
Quando usare Reliable Actors
Service Fabric Reliable Actors è un'implementazione dello schema progettuale dell'attore. Come per gli altri schemi progettuali del software, la scelta di usare un criterio specifico dipende dalla capacità di un problema di progettazione software di seguire lo schema.
Sebbene lo schema progettuale dell'attore possa risultare idoneo per vari problemi e scenari di sistemi distribuiti, occorre valutare attentamente i limiti dello schema e il framework in cui viene implementato. In generale conviene prendere in considerazione il criterio dell'attore per modellare il problema o lo scenario nei casi seguenti:
- Il problema riguarda un gran numero (migliaia o più) di piccole unità indipendenti e isolate di stato e logica.
- Si desidera usare oggetti a thread singolo che non richiedono un'interazione significativa con componenti esterni, incluse query dello stato tra un insieme di attori.
- Le istanze degli attori non bloccano i chiamanti con ritardi imprevedibili eseguendo operazioni I/O.
Attori in Service Fabric
In Service Fabric gli attori sono implementati nel framework Reliable Actors: un framework di applicazioni imperniato sul criterio attore e basato su Service Fabric Reliable Services. Ogni servizio di tipo Reliable Actor che viene scritto è di fatto un servizio Reliable partizionato con stato.
Ogni attore è definito come un'istanza di un tipo di attore, come un oggetto .NET è un'istanza di un tipo .NET. Ad esempio, può essere definito un tipo di attore che implementa la funzionalità di una calcolatrice e possono esistere molti attori di quel tipo distribuiti su vari nodi di un cluster. Ciascuno di questi attori è identificato in modo univoco da un ID.
Durata attore
Gli attori Service Fabric sono virtuali, vale a dire che la loro durata non è correlata alla loro rappresentazione in memoria. Di conseguenza, non devono essere esplicitamente create o eliminate. Il runtime di Reliable Actors attiva automaticamente un attore la prima volta che riceve una richiesta per l'ID attore. Se un attore rimane inutilizzato per un determinato periodo di tempo, il runtime di Reliable Actors esegue la Garbage Collection dell'oggetto in memoria. Mantiene inoltre conoscenza dell'esistenza dell'attore, nel caso in cui debba essere riattivato in un secondo momento. Per altre informazioni, vedere Ciclo di vita degli attori e Garbage Collection.
L'astrazione della durata dell'attore virtuale produce alcune avvertenze in seguito al modello di attore virtuale, infatti in alcuni casi l'implementazione di Reliable Actors devia dal modello.
- Un attore viene automaticamente attivato, causando la costruzione di un oggetto attore, quando all'ID attore viene inviato un messaggio per la prima volta. Dopo un po' di tempo viene eseguita la Garbage Collection dell'oggetto attore. In futuro viene costruito un nuovo oggetto attore quando l'ID attore viene usato di nuovo. Quando un attore viene archiviato nella gestione stati, la durata del suo stato supera quella dell'oggetto.
- La chiamata di un qualsiasi metodo di attore per l'ID attore attiva l'attore. Per questo motivo il runtime richiama implicitamente il costruttore dei tipi di attore. Il codice client pertanto non può trasmettere i parametri al costruttore del tipo di attore, anche se i parametri possono essere trasmessi al costruttore dell'attore tramite il servizio stesso. Di conseguenza, se l'attore richiede i parametri di inizializzazione dal client, gli attori possono essere costruiti in uno stato inizializzato parzialmente al momento in cui gli altri metodi vengono chiamati su di esso. Non è presente alcun punto di ingresso singolo per l'attivazione di un attore dal client.
- Sebbene Reliable Actors crei in modo implicito oggetti attore, è possibile eliminare in modo esplicito un attore e il suo stato.
Distribuzione e failover
Per garantire scalabilità e affidabilità, Service Fabric distribuisce gli attori all'interno del cluster e ne esegue automaticamente la migrazione dai nodi non riusciti a quelli integri, se richiesto. Questa è un'astrazione su un Reliable Service partizionato con stato. La distribuzione, la scalabilità, l'affidabilità e il failover automatico sono disponibili in virtù del fatto che gli attori sono in esecuzione all'interno di un Reliable Service con stato chiamato servizio Actor.
Gli attori vengono distribuiti tra le partizioni del servizio Actor e le partizioni a loro volta vengono distribuite tra i nodi in un cluster Service Fabric. Ogni partizione del servizio contiene un set di attori. Service Fabric gestisce la distribuzione e il failover delle partizioni del servizio.
Ad esempio, quando un servizio Actor con nove partizioni viene distribuito in tre nodi usando la posizione di partizione attore predefinita:
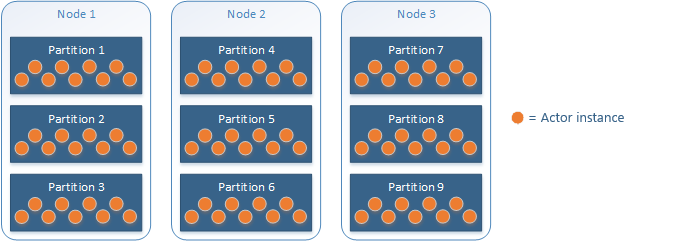
Il framework attore gestisce automaticamente le impostazioni dello schema di partizionamento e dell'intervallo di chiavi. In tal modo la scelta è più semplice, ma occorre tenere presente alcune considerazioni:
- Reliable Services consente di scegliere uno schema di partizionamento, un intervallo di chiavi nel caso in cui si usi uno schema di partizionamento con intervallo e un conteggio partizioni. Reliable Actors si limita allo schema di partizionamento dell'intervallo, lo schema uniforme Int64, e richiede l'uso di tutto l'intervallo di chiavi Int64.
- Per impostazione predefinita, gli attori vengono posizionati in modo casuale nelle partizioni, in modo che la distribuzione risulti uniforme.
- Poiché gli attori vengono posizionati in modo casuale, è prevedibile che le operazioni dell'attore richiedano sempre la comunicazione di rete, incluse la serializzazione e deserializzazione dei dati di chiamata del metodo, la latenza riscontrata e il sovraccarico.
- Negli scenari avanzati è possibile controllare il posizionamento della partizione dell'attore usando gli ID attore Int64 che eseguono il mapping su partizioni specifiche. Questo metodo può tuttavia comportare una distribuzione sbilanciata degli attori tra le partizioni.
Per altre informazioni sul partizionamento dei servizi attore vedere Concetti relativi alla partizione per gli attori.
Comunicazione tra attori
Le interazioni tra gli attori sono definite in un'interfaccia condivisa dall'attore che implementa l'interfaccia e dal client che ottiene un proxy per un attore tramite l'interfaccia stessa. Dato che questa interfaccia viene usata per richiamare i metodi dell'attore in modo asincrono, ogni metodo nell'interfaccia deve comportare la restituzione di Task.
Le chiamate ai metodi e le relative risposte risultano nelle richieste di rete eseguite nel cluster, pertanto gli argomenti e i tipi di risultati delle attività restituite devono essere serializzabili dalla piattaforma. In particolare, devono essere contratto dati serializzabili.
Proxy dell'attore
L'API client Reliable Actors consente la comunicazione tra un'istanza di attore e un client di attore. Per comunicare con un attore, un client crea un oggetto proxy di attore che implementa l'interfaccia dell'attore. Il client interagisce con l'attore richiamando metodi sull'oggetto proxy. Il proxy dell'attore può essere usato per la comunicazione tra client e attore e tra attore e attore.
// Create a randomly distributed actor ID
ActorId actorId = ActorId.CreateRandom();
// This only creates a proxy object, it does not activate an actor or invoke any methods yet.
IMyActor myActor = ActorProxy.Create<IMyActor>(actorId, new Uri("fabric:/MyApp/MyActorService"));
// This will invoke a method on the actor. If an actor with the given ID does not exist, it will be activated by this method call.
await myActor.DoWorkAsync();
// Create actor ID with some name
ActorId actorId = new ActorId("Actor1");
// This only creates a proxy object, it does not activate an actor or invoke any methods yet.
MyActor myActor = ActorProxyBase.create(actorId, new URI("fabric:/MyApp/MyActorService"), MyActor.class);
// This will invoke a method on the actor. If an actor with the given ID does not exist, it will be activated by this method call.
myActor.DoWorkAsync().get();
Osservare come le due porzioni di informazioni usate per creare l'oggetto proxy dell'attore siano l'ID dell'attore e il nome dell'applicazione. L'ID attore identifica in modo univoco l'attore, mentre il nome dell'applicazione identifica l' applicazione Service Fabric in cui è distribuito l'attore.
La classe ActorProxy(C#) / ActorProxyBase(Java) sul lato client esegue la risoluzione necessaria per individuare l'attore in base al relativo ID e aprire un canale di comunicazione con esso. In caso di errore di comunicazione e failover, la classe tenta di individuare nuovamente l'attore. Il recapito dei messaggi, di conseguenza, presenta le caratteristiche seguenti:
- Il recapito del messaggio è il massimo sforzo.
- Gli attori possono ricevere messaggi duplicati dallo stesso client.
Concorrenza
Il runtime di Reliable Actors rappresenta un modello semplice di accesso a turno per accedere ai metodi degli attori. Ciò significa che, in qualsiasi momento, all'interno del codice oggetto dell'attore non può essere attivo più di un thread. L'accesso a turno semplifica notevolmente i sistemi simultanei, poiché non occorrono meccanismi di sincronizzazione per l'accesso ai dati. I sistemi devono inoltre essere progettati tenendo in particolare considerazione la natura di accesso a thread singolo di ogni istanza dell'attore.
- Un'istanza di un solo attore non può elaborare più di una richiesta alla volta. Se si prevede di gestire richieste simultanee, un'istanza di un attore può causare un collo di bottiglia della velocità effettiva.
- Gli attori possono bloccarsi a vicenda se è presente una richiesta circolare tra due attori durante l’esecuzione di una richiesta esterna a uno degli attori. Il runtime dell'attore causa automaticamente il timeout delle chiamate dell'attore e genera un'eccezione al chiamante per interrompere le possibili situazioni di deadlock.

Accesso basato su turni
Un turno consiste nell'esecuzione completa di un metodo di un attore in risposta a una richiesta eseguita da altri attori o client oppure nell'esecuzione completa di un callback di timer/promemoria . Anche se questi metodi e callback sono asincroni, il runtime di Actors non ne esegue l'interfoliazione. Un turno deve essere interamente completato prima che sia consentito un nuovo turno. In altre parole, un metodo di un attore o un callback di timer/promemoria in esecuzione deve essere interamente completato prima che sia consentita una nuova chiamata a un metodo o a un callback. Un metodo o un callback è considerato completato se è stata restituita l'esecuzione e se l'attività restituita dal metodo o dal callback è stata completata. È opportuno sottolineare che la concorrenza basata su turni viene rispettata anche su metodi, timer e callback diversi.
Per applicare la concorrenza basata su turni, il runtime di Actors acquisisce un blocco per ogni attore all'inizio di un turno e lo rilascia alla fine del turno. Pertanto, la concorrenza basata su turni viene applicata a livello di singolo attore e non per più attori. I metodi e i callback di timer/promemoria degli attori possono essere eseguiti simultaneamente per conto di diversi attori.
L'esempio seguente illustra questi concetti. Si consideri un tipo di attore che implementa due metodi asincroni, ad esempio Method1 e Method2, un timer e un promemoria. Il diagramma seguente illustra un esempio di sequenza temporale per l'esecuzione di questi metodi e callback per conto di due attori, ActorId1 e ActorId2, appartenenti a questo tipo.

Il diagramma adotta queste convenzioni:
- Ogni linea verticale mostra il flusso logico di esecuzione di un metodo o di un callback per conto di un attore specifico.
- Gli eventi contrassegnati su ogni linea verticale sono riportati in ordine cronologico, con gli eventi più recenti elencati sotto quelli meno recenti.
- Per le sequenze temporali vengono usati colori diversi, corrispondenti a diversi attori.
- L'evidenziazione viene usata per indicare la durata in cui il blocco per attore è attivato per conto di un metodo o di un callback.
Alcuni elementi importanti da considerare:
- Mentre Method1 è in esecuzione per conto di ActorId2 in risposta alla richiesta client xyz789, arriva un'altra richiesta client abc123 per l'esecuzione di Method1 da parte di ActorId2. La seconda esecuzione di Method1 tuttavia non inizia finché non è terminata l'esecuzione precedente. Analogamente, un promemoria registrato da ActorId2 viene attivato mentre Method1 è in esecuzione in risposta alla richiesta client xyz789. Il callback di promemoria viene eseguito solo dopo che entrambe le esecuzioni di Method1 sono state completate. Tutto ciò è regolato dalla concorrenza basata su turni applicata per ActorId2.
- Questa concorrenza basata sui turni viene applicata analogamente anche per ActorId1, come dimostrato dall'esecuzione di Method1, Method2 e del callback del timer per conto di ActorId1 eseguito in modalità seriale.
- L'esecuzione di Method1 per conto di ActorId1 si sovrappone all'esecuzione per conto di ActorId2. Questo accade perché la concorrenza basata su turni viene applicata solo all'interno di un attore e non tra più attori.
- In alcune esecuzioni di metodo o callback, l'oggetto
Task(C#) /CompletableFuture(Java) restituito dal metodo o dal callback viene completato solo dopo la restituzione del metodo. In altre esecuzioni, l'operazione asincrona risulta già completata al momento della restituzione del metodo o del callback. In entrambi i casi, il blocco per attore viene rilasciato soltanto dopo la restituzione del metodo o del callback e il completamento dell'operazione asincrona.
Rientranza
Per impostazione predefinita, il runtime di Actors consente la reentrancy. In altre parole, se un metodo dell'Actor A chiama un metodo sull'Actor B, che a sua volta chiama un altro metodo sull'Actor A, il metodo può essere eseguito. perché fa parte dello stesso contesto logico della catena di chiamate. Tutte le chiamate di timer e promemoria iniziano con il nuovo contesto logico di chiamate. Per altre informazioni, vedere Rientranza di Reliable Actors.
Ambito delle garanzie di concorrenza
Il runtime di Actors fornisce queste garanzie di concorrenza nelle situazioni in cui controlla le chiamate di questi metodi, ad esempio per le chiamate di metodi eseguite in risposta a una richiesta client e per i callback di promemoria e timer. Tuttavia, se il codice dell'attore richiama direttamente questi metodi al di fuori dei meccanismi forniti dal runtime di Actors, il runtime non può offrire alcuna garanzia di concorrenza. Ad esempio, se il metodo viene richiamato nel contesto di un'attività non associata all'attività restituita dai metodi dell'attore oppure se viene richiamato da un thread che l'attore crea in modo autonomo, il runtime non può fornire garanzie di concorrenza. Per eseguire operazioni in background, pertanto, gli attori devono usare specifici timer e promemoria che rispettano la concorrenza basata su turni.
Passaggi successivi
Per iniziare, creare il primo servizio Reliable Actors: