Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
È possibile eseguire la migrazione dei dati da un archivio HDFS locale del cluster Hadoop in Archiviazione di Azure (archiviazione BLOB o Data Lake Storage) usando un dispositivo Data Box. È possibile scegliere tra Data Box Disk, Data Box con una capacità di 80, 120 o 525 TiB o 770 TiB Data Box Heavy.
Questo articolo consente di completare queste attività:
- Preparare la migrazione dei dati
- Copiare i dati su un dispositivo Data Box Disk, Data Box o Data Box Heavy
- Spedisci il dispositivo a Microsoft
- Applicare le autorizzazioni di accesso a file e directory (solo Data Lake Storage)
Prerequisiti
Questi elementi sono necessari per completare la migrazione.
Un account di archiviazione di Azure.
Un cluster Hadoop locale che contiene i dati di origine.
Un dispositivo Azure Data Box.
Cablare e connettere Data Box o Data Box Heavy a una rete locale.
Se sei pronto, iniziamo.
Copiare i dati in un dispositivo Data Box
Se i dati si adattano a un singolo dispositivo Data Box, copiare i dati nel dispositivo Data Box.
Se le dimensioni dei dati superano la capacità del dispositivo Data Box, usare la procedura facoltativa per suddividere i dati in più dispositivi Data Box e quindi eseguire questo passaggio.
Per copiare i dati dall'archivio HDFS locale in un dispositivo Data Box, è necessario impostare alcune operazioni e quindi usare lo strumento DistCp .
Seguire questa procedura per copiare i dati tramite le API REST dell'archiviazione BLOB/oggetti nel dispositivo Data Box. L'interfaccia dell'API REST fa apparire il dispositivo come un archivio HDFS nel tuo cluster.
Prima di copiare i dati tramite REST, identificare le primitive di sicurezza e connessione per connettersi all'interfaccia REST in Data Box o Data Box Heavy. Accedere all'interfaccia utente Web locale di Data Box e passare alla pagina Connetti e copia . Negli account di archiviazione di Azure per il dispositivo, in Impostazioni di accesso individuare e selezionare REST.

Nella finestra di dialogo Accedere all'account di archiviazione e caricare i dati copiare l'endpoint del servizio BLOB e la chiave dell'account di archiviazione. Dall'endpoint del servizio Blob, omettere
https://e la barra finale.In questo caso, l'endpoint è:
https://mystorageaccount.blob.mydataboxno.microsoftdatabox.com/. La parte host dell'URI usata è:mystorageaccount.blob.mydataboxno.microsoftdatabox.com. Per un esempio, vedere come connettersi a REST su http.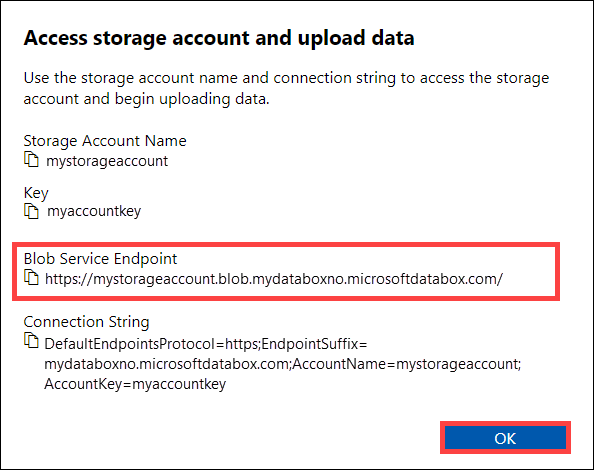
Aggiungere l'endpoint e l'indirizzo IP del nodo Data Box o Data Box Heavy a
/etc/hostsin ogni nodo.10.128.5.42 mystorageaccount.blob.mydataboxno.microsoftdatabox.comSe si usa un altro meccanismo per DNS, è necessario assicurarsi che l'endpoint Data Box possa essere risolto.
Impostare la variabile shell
azjarssul percorso dei file jarhadoop-azureeazure-storage. È possibile trovare questi file nella directory di installazione di Hadoop.Per determinare se questi file esistono, usare il comando seguente:
ls -l $<hadoop_install_dir>/share/hadoop/tools/lib/ | grep azure. Sostituire il<hadoop_install_dir>segnaposto con il percorso della directory in cui è stato installato Hadoop. Assicuratevi di utilizzare percorsi completi e qualificati.Esempi:
azjars=$hadoop_install_dir/share/hadoop/tools/lib/hadoop-azure-2.6.0-cdh5.14.0.jarazjars=$azjars,$hadoop_install_dir/share/hadoop/tools/lib/microsoft-windowsazure-storage-sdk-0.6.0.jarCreare il contenitore di archiviazione da usare per la copia dei dati. È anche necessario specificare una directory di destinazione come parte di questo comando. Potrebbe trattarsi di una directory di destinazione fittizia a questo punto.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -mkdir -p wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Sostituire il segnaposto
<blob_service_endpoint>con il nome dell'endpoint del servizio BLOB.Sostituire il
<account_key>segnaposto con la chiave di accesso dell'account.Sostituire il
<container-name>segnaposto con il nome del contenitore.Sostituire il
<destination_directory>segnaposto con il nome della directory in cui copiare i dati.
Eseguire un comando list per assicurarsi che il contenitore e la directory siano stati creati.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -ls -R wasb://<container_name>@<blob_service_endpoint>/Sostituire il segnaposto
<blob_service_endpoint>con il nome dell'endpoint del servizio BLOB.Sostituire il
<account_key>segnaposto con la chiave di accesso dell'account.Sostituire il
<container-name>segnaposto con il nome del contenitore.
Copiare dati da Hadoop HDFS all'archivio BLOB di Data Box nel contenitore creato in precedenza. Se la directory in cui si esegue la copia non viene trovata, il comando lo crea automaticamente.
hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -filters <exclusion_filelist_file> \ [-f filelist_file | /<source_directory> \ wasb://<container_name>@<blob_service_endpoint>/<destination_directory>Sostituire il segnaposto
<blob_service_endpoint>con il nome dell'endpoint del servizio BLOB.Sostituire il
<account_key>segnaposto con la chiave di accesso dell'account.Sostituire il
<container-name>segnaposto con il nome del contenitore.Sostituire il
<exclusion_filelist_file>segnaposto con il nome del file che contiene l'elenco di esclusioni di file.Sostituire il
<source_directory>segnaposto con il nome della directory contenente i dati da copiare.Sostituire il
<destination_directory>segnaposto con il nome della directory in cui copiare i dati.
L'opzione
-libjarsviene utilizzata per rendere disponibili i filehadoop-azure*.jare i file dipendentiazure-storage*.jaradistcp. Questo problema può verificarsi già per alcuni cluster.Nell'esempio seguente viene illustrato come viene usato il
distcpcomando per copiare i dati.hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.mystorageaccount.blob.mydataboxno.microsoftdatabox.com=myaccountkey \ -filter ./exclusions.lst -f /tmp/copylist1 -m 4 \ /data/testfiles \ wasb://hdfscontainer@mystorageaccount.blob.mydataboxno.microsoftdatabox.com/dataPer migliorare la velocità di copia:
Provare a modificare il numero di mapper. Il numero predefinito di mapper è 20. L'esempio precedente usa
m= 4 mapper.Provare
-D fs.azure.concurrentRequestCount.out=<thread_number>. Sostituire<thread_number>con il numero di thread per ciascun mapper. Il prodotto del numero di mapper e del numero di thread per mapper,m*<thread_number>, non deve superare 32.Provare a eseguire più
distcpin parallelo.Tenere presente che i file di grandi dimensioni offrono prestazioni migliori rispetto ai file di piccole dimensioni.
Se sono presenti file di dimensioni superiori a 200 GB, è consigliabile modificare le dimensioni del blocco in 100 MB con i parametri seguenti:
hadoop distcp \ -libjars $azjars \ -Dfs.azure.write.request.size= 104857600 \ -Dfs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -Dfs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -strategy dynamic \ -Dmapreduce.map.memory.mb=16384 \ -Dfs.azure.concurrentRequestCount.out=8 \ -Dmapreduce.map.java.opts=-Xmx8196m \ -m 4 \ -update \ /data/bigfile wasb://hadoop@mystorageaccount.blob.core.windows.net/bigfile
Spedire il Data Box a Microsoft
Seguire questa procedura per preparare e spedire il dispositivo Data Box a Microsoft.
Prima di tutto, prepararsi per la spedizione in Data Box o Data Box Heavy.
Al termine della preparazione del dispositivo, scaricare i file DBA. Questi file DBA o manifesto vengono usati in un secondo momento per verificare i dati caricati in Azure.
Arrestare il dispositivo e rimuovere i cavi.
Pianificare un ritiro con UPS.
Per i dispositivi Data Box, vedere Spedire Data Box.
Per i dispositivi Data Box Heavy, vedere Spedire Data Box Heavy.
Dopo che Microsoft riceve il dispositivo, è connesso alla rete del data center e i dati vengono caricati nell'account di archiviazione specificato al momento dell'ordine del dispositivo. Verificare in base ai file DBA che tutti i dati vengano caricati in Azure.
Applicare le autorizzazioni di accesso a file e directory (solo Data Lake Storage)
Disponi già dei dati nel tuo account di Archiviazione Azure. Ora si applicano le autorizzazioni di accesso ai file e alle directory.
Nota
Questo passaggio è necessario solo se si usa Azure Data Lake Storage come archivio dati. Se si usa solo un account di archiviazione BLOB senza spazio dei nomi gerarchico come archivio dati, è possibile ignorare questa sezione.
Creare un'entità servizio per l'account abilitato di Azure Data Lake Storage
Per creare un'entità servizio, vedere Procedura: Usare il portale per creare un'applicazione Microsoft Entra e un'entità servizio in grado di accedere alle risorse.
Quando si esegue la procedura descritta nella sezione Assegnare l'applicazione a un ruolo dell'articolo, assicurarsi di assegnare il ruolo Collaboratore ai dati del BLOB di archiviazione all'entità servizio.
Quando si eseguono i passaggi descritti nella sezione Ottenere i valori per l'accesso nell'articolo , salvare i valori di ID applicazione e segreto client in un file di testo. Ne hai bisogno presto.
Generare un elenco di file copiati con le relative autorizzazioni
Dal cluster Hadoop locale eseguire questo comando:
sudo -u hdfs ./copy-acls.sh -s /{hdfs_path} > ./filelist.json
Questo comando genera un elenco di file copiati con le relative autorizzazioni.
Nota
A seconda del numero di file in HDFS, questo comando può richiedere molto tempo per l'esecuzione.
Generare un elenco di identità ed eseguirne il mapping alle identità di Microsoft Entra
Scarica lo
copy-acls.pyscript. Consulta la sezione Scaricare gli script helper e configurare il nodo perimetrale per eseguirli in questo articolo.Eseguire questo comando per generare un elenco di identità univoche.
./copy-acls.py -s ./filelist.json -i ./id_map.json -gQuesto script genera un file denominato
id_map.jsonche contiene le identità di cui è necessario eseguire il mapping alle identità basate su ADD.Aprire il file
id_map.jsonin un editor di testo.Per ogni oggetto JSON presente nel file, aggiornare l'attributo
targetdel nome principale utente di Microsoft Entra (UPN) o dell'ObjectId (OID), con l'identità mappata appropriata. Al termine, salvare il file. Questo file sarà necessario nel passaggio successivo.
Applicare le autorizzazioni ai file copiati e applicare la mappatura delle identità
Eseguire questo comando per applicare le autorizzazioni ai dati copiati nell'account abilitato per Data Lake Storage:
./copy-acls.py -s ./filelist.json -i ./id_map.json -A <storage-account-name> -C <container-name> --dest-spn-id <application-id> --dest-spn-secret <client-secret>
Sostituire il segnaposto
<storage-account-name>con il nome del proprio account di archiviazione.Sostituire il
<container-name>segnaposto con il nome del contenitore.Sostituire i segnaposto
<application-id>e<client-secret>con l'ID dell'applicazione e il segreto client raccolti al momento della creazione dell'entità servizio.
Appendice: Suddividere i dati tra più dispositivi Data Box
Prima di spostare i dati in un dispositivo Data Box, è necessario scaricare alcuni script helper, assicurarsi che i dati siano organizzati per adattarsi a un dispositivo Data Box ed escludere eventuali file non necessari.
Scaricare gli script helper e configurare il nodo perimetrale per eseguirli
Dal nodo perimetrale o nodo principale del cluster Hadoop locale, eseguire questo comando:
git clone https://github.com/jamesbak/databox-adls-loader.git cd databox-adls-loaderQuesto comando clona il repository GitHub che contiene gli script helper.
Assicurarsi che sia il pacchetto jq installato nel computer locale.
sudo apt-get install jqInstallare il pacchetto Python Requests.
pip install requestsImpostare le autorizzazioni di esecuzione per gli script necessari.
chmod +x *.py *.sh
Assicurarsi che i dati siano organizzati per adattarsi a un dispositivo Data Box
Se le dimensioni dei dati superano le dimensioni di un singolo dispositivo Data Box, è possibile suddividere i file in gruppi che è possibile archiviare in più dispositivi Data Box.
Se i dati non superano le dimensioni di un singolo dispositivo Data Box, è possibile passare alla sezione successiva.
Con autorizzazioni elevate, eseguire lo
generate-file-listscript scaricato seguendo le indicazioni riportate nella sezione precedente.Ecco una descrizione dei parametri del comando:
sudo -u hdfs ./generate-file-list.py [-h] [-s DATABOX_SIZE] [-b FILELIST_BASENAME] [-f LOG_CONFIG] [-l LOG_FILE] [-v {DEBUG,INFO,WARNING,ERROR}] path where: positional arguments: path The base HDFS path to process. optional arguments: -h, --help show this help message and exit -s DATABOX_SIZE, --databox-size DATABOX_SIZE The size of each Data Box in bytes. -b FILELIST_BASENAME, --filelist-basename FILELIST_BASENAME The base name for the output filelists. Lists will be named basename1, basename2, ... . -f LOG_CONFIG, --log-config LOG_CONFIG The name of a configuration file for logging. -l LOG_FILE, --log-file LOG_FILE Name of file to have log output written to (default is stdout/stderr) -v {DEBUG,INFO,WARNING,ERROR}, --log-level {DEBUG,INFO,WARNING,ERROR} Level of log information to output. Default is 'INFO'.Copiare gli elenchi di file generati in HDFS in modo che siano accessibili al processo DistCp .
hadoop fs -copyFromLocal {filelist_pattern} /[hdfs directory]
Escludere i file non necessari
È necessario escludere alcune directory dal processo DisCp. Ad esempio, escludere directory che contengono informazioni sullo stato che mantengono il cluster in esecuzione.
Nel cluster Hadoop locale in cui si prevede di avviare il processo DistCp creare un file che specifica l'elenco di directory da escludere.
Ecco un esempio:
.*ranger/audit.*
.*/hbase/data/WALs.*
Passaggi successivi
Informazioni sul funzionamento di Data Lake Storage con i cluster HDInsight. Per ulteriori informazioni, vedere Usare Azure Data Lake Storage con i cluster di Azure HDInsight.