Analizzare le prestazioni dei processi di Analisi di flusso usando metriche e dimensioni
Per comprendere l'integrità di un processo di Analisi di flusso di Azure, è importante sapere come usare le metriche e le dimensioni del processo. È possibile usare il portale di Azure, l'estensione Analisi di flusso di Visual Studio Code o un SDK per ottenere le metriche e le dimensioni a cui si è interessati.
Questo articolo illustra come usare metriche e dimensioni dei processi di Analisi di flusso per analizzare le prestazioni di un processo tramite il portale di Azure.
Gli eventi di input con ritardo e accumulo limite sono le metriche principali per determinare le prestazioni del processo di Analisi di flusso. Se il ritardo limite del processo aumenta continuamente e gli eventi di input si accumulano, il processo non riesce a tenere il passo con la frequenza degli eventi di input e produce output in modo tempestivo.
Verranno ora esaminati diversi esempi per analizzare le prestazioni di un processo tramite i dati delle metriche di Ritardo Limite come punto di partenza.
Nessun input per una determinata partizione aumenta il ritardo limite del processo
Se il ritardo limite del processo perfettamente parallelo aumenta costantemente, passare a Metriche. Usare quindi questa procedura per verificare se la causa radice è una mancanza di dati in alcune partizioni dell'origine di input:
Controllare la partizione che ha il ritardo limite crescente. Selezionare la metrica Ritardo limite e dividerla in base alla dimensione ID partizione. Nell'esempio seguente, la partizione 465 presenta un ritardo limite massimo.

Controllare se mancano dati di input per questa partizione. Selezionare la metrica Eventi di input e filtrarla in base a questo ID di partizione specifico.



Quale ulteriore azione è possibile effettuare?
Il ritardo limite per questa partizione aumenta perché non vengono trasmessi eventi di input in questa partizione. Se la finestra di tolleranza del processo per gli arrivi in ritardo è di diverse ore e non vengono trasmessi dati di input in una partizione, si prevede che il ritardo limite per tale partizione continuerà ad aumentare fino a quando non si raggiunge la finestra di arrivo in ritardo.
Ad esempio, se la finestra di arrivo in ritardo è di 6 ore e i dati di input non vengono trasmessi nella partizione di input 1, il ritardo limite per la partizione di output 1 aumenterà fino a raggiungere 6 ore. È possibile verificare se l'origine di input produce dati come previsto.
L'asimmetria dei dati di input causa un ritardo limite massimo
Come accennato nel caso precedente, quando il processo perfettamente parallelo ha un ritardo limite massimo, la prima cosa da fare è suddividere la metrica Ritardo limite in base alla dimensione ID partizione. È quindi possibile identificare se tutte le partizioni hanno un ritardo limite massimo o solo alcune di esse.
Nell'esempio seguente, le partizioni 0 e 1 hanno un ritardo limite superiore (circa 20-30 secondi) rispetto alle altre otto partizioni. I ritardi limite delle altre partizioni sono sempre costanti a circa 8-10 secondi.

Si esaminerà ora l'aspetto dei dati di input per tutte queste partizioni con le metriche Eventi di input suddivise per ID partizione:

Quale ulteriore azione è possibile effettuare?
Come illustrato nell'esempio, le partizioni (0 e 1) con un ritardo limite massimo ricevono dati di input significativamente maggiori rispetto ad altre partizioni. Questo è chiamato asimmetria dei dati. I nodi di streaming che elaborano le partizioni con asimmetria dei dati devono usare più risorse del CPU e memoria rispetto ad altre, come illustrato nello screenshot seguente.

I nodi di streaming che elaborano le partizioni con un'asimmetria dei dati superiore mostreranno un utilizzo superiore del CPU e/o dell'unità di streaming (SU). Questo utilizzo influirà sulle prestazioni del processo e aumenterà il ritardo limite. Per far fronte a questo problema, è necessario ripartire i dati di input in modo più uniforme.
È anche possibile eseguire il debug di questo problema con il diagramma dei processi fisici, vedere Diagramma dei processi fisici: identificare gli eventi di input non uniformi distribuiti (data-skew).
Il sovraccarico del CPU o della memoria aumenta il ritardo limite
Quando un processo perfettamente parallelo ha un ritardo limite crescente, questo potrebbe verificarsi non solo in una o più partizioni, ma in tutte le partizioni. Come si ha la conferma che il processo rientra in questo caso?
Suddividere la metrica Ritardo limite in base a ID Partizione Ad esempio:

Dividere la metricaEventi di input in base a ID partizione per verificare se è presente un'asimmetria dei dati nei dati di input per ogni partizione.
Controllare l'utilizzo di CPU e SU per verificare se l'utilizzo in tutti i nodi di streaming è troppo elevato.
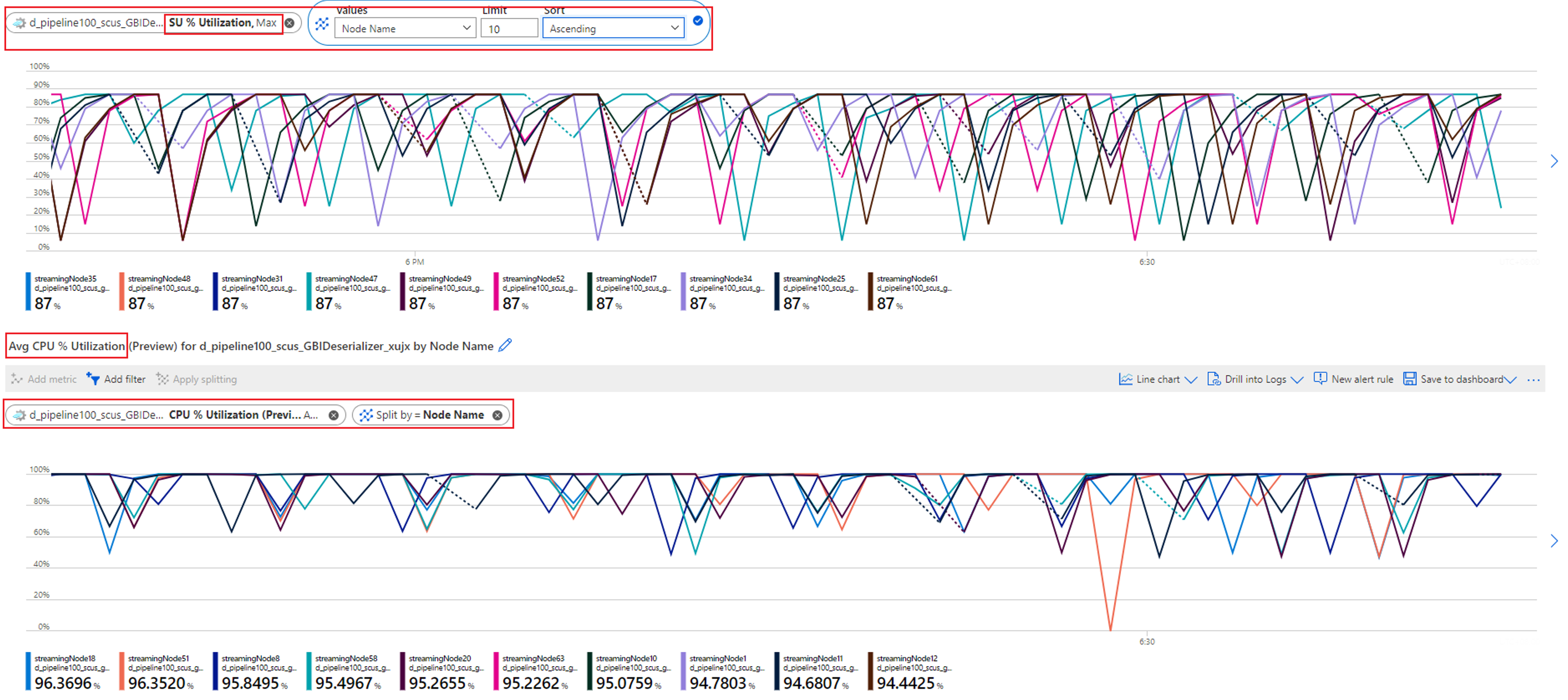
Se l'utilizzo di CPU e SU è molto elevato (oltre l'80%) in tutti i nodi di streaming, si può concludere che questo processo ha una grande quantità di dati elaborati all'interno di ogni nodo di streaming.
È possibile rivedere il numero di partizioni allocate a un nodo di streaming controllando la metrica degli Eventi di input. Filtrare per ID del nodo di streaming con la dimensione Nome nodo e dividere per ID partizione.
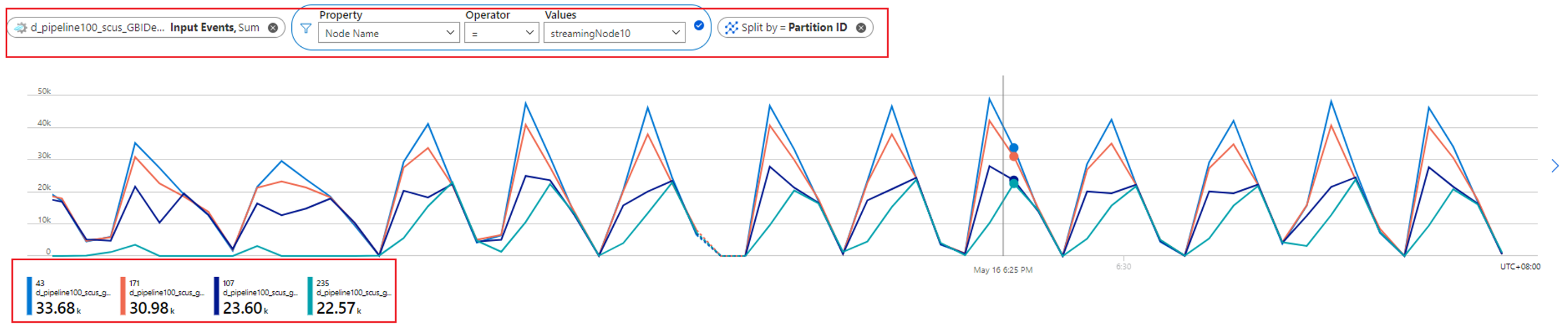
Lo screenshot precedente mostra che quattro partizioni vengono allocate a un nodo di streaming che occupa circa il 90-100% della risorsa del nodo di streaming. È possibile usare un approccio simile per controllare il resto dei nodi di streaming per verificare che vengano elaborati anche i dati da quattro partizioni.



Quale ulteriore azione è possibile effettuare?
È possibile ridurre il numero di partizioni per ogni nodo di streaming per ridurre i dati di input per ogni nodo di streaming. A tale scopo, è possibile raddoppiare le SU in modo che ogni nodo di streaming gestisca i dati da due partizioni. In alternativa, è possibile quadruplicare le SU in modo che ogni nodo di streaming gestisca i dati da una partizione. Per informazioni sulla relazione tra l'assegnazione delle SU e il numero dei nodi di streaming, vedere Informazioni e modifica delle unità di streaming.
Cosa è possibile fare se il ritardo limite aumenta ancora quando un nodo di streaming gestisce i dati da una partizione? Ripartire gli input con più partizioni per ridurre la quantità di dati in ogni singola partizione. Per maggiori dettagli, vedere Usare la ripartizione per ottimizzare i processi di Analisi di flusso di Azure.
È anche possibile eseguire il debug di questo problema con il diagramma dei processi fisici, vedere Diagramma dei processi fisici: identificare la causa del sovraccarico del CPU o della memoria.
Passaggi successivi
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per