Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a: SQL Server Analysis Services Azure Analysis Services Fabric/Power BI Premium
Questo articolo riepiloga le nuove funzionalità, i miglioramenti, le funzionalità deprecate e le interruzioni e il comportamento e le modifiche di rilievo nelle versioni più recenti di SQL Server Analysis Services (SSAS).
SQL Server 2025 Servizi di Analisi
Miglioramenti delle prestazioni
Modelli con gruppi di calcolo e stringhe di formato in Excel
Sono stati apportati miglioramenti significativi delle prestazioni per le query MDX sui modelli con gruppi di calcolo e stringhe di formato per ridurre l'utilizzo della memoria e migliorare la velocità di risposta. Le modifiche più recenti migliorano le prestazioni e l'affidabilità delle operazioni in Analizza in Excel nei modelli che includono uno o entrambi:
Stringhe di formato dinamico per le misure
Elementi calcolati con stringhe di formato
Per altre informazioni, vedere Stringhe di formato dinamico
Esecuzione di query parallele per DirectQuery
Il parallelismo migliorato in modalità DirectQuery consente tempi di risposta più rapidi per query complesse. L'idea fondamentale è ottimizzare le prestazioni delle query parallelizzando più query alla fonte dei dati per una singola query DAX. Questa parallelizzazione delle query riduce l'impatto dei ritardi dell'origine dati e delle latenze di rete sulle prestazioni delle query. Per altre informazioni, visitare questo blog.
Fusion orizzontale
SQL Server Analysis Services 2025 incorpora la versione più recente di Horizontal Fusion, un'ottimizzazione delle prestazioni delle query che riduce il numero di query SQL generate da DAX, migliorando l'efficienza di DirectQuery. Per maggiori dettagli, visita: Annuncio della fusione orizzontale.
Funzioni e funzionalità DAX
Calcoli visivi
Il modo di scrivere DAX cambia con l'introduzione dei calcoli visivi. I calcoli visivi sono calcoli DAX definiti ed eseguiti direttamente in un oggetto visivo. Un calcolo visivo può fare riferimento a qualsiasi dato nell'oggetto visivo, incluse colonne, misure o altri calcoli visivi. Questo approccio rimuove la complessità del modello semantico e semplifica il processo di scrittura di DAX. Potete usare calcoli visivi per completare calcoli aziendali comuni, come somme totali o medie mobili. Per altre informazioni su come abilitare e usare calcoli visivi, vedere Panoramica dei calcoli visivi.
Comportamento del filtro dei valori
Si sta introducendo una nuova opzione per controllare il comportamento del filtro dei valori. Abilitando l'impostazione "Filtri valore indipendenti", gli utenti possono impedire la combinazione automatica di più filtri nella stessa tabella in un unico filtro unito. Questa modifica offre una maggiore flessibilità, consentendo un filtro più preciso e indipendente per soddisfare esigenze di modellazione specifiche e migliorando l'accuratezza e il controllo delle query di dati. Per impostare questa proprietà per SSAS, è possibile utilizzare il modello a oggetti tabulare o TMSL in base alla proprietà ValueFilterBehavior . Per altre informazioni, vedere: Comportamento del filtro dei valori.
Espressioni di selezione per i gruppi di calcolo
Le espressioni di selezione consentono un controllo ottimizzato sul comportamento dei calcoli quando vengono soddisfatte determinate condizioni. Le espressioni di selezione introducono logica aggiuntiva per la gestione dei casi in cui vengono selezionati più elementi di calcolo o quando non viene effettuata alcuna selezione specifica in un gruppo di calcolo. Per altri dettagli, visitare: Gruppi di calcoli.
Miglioramenti delle funzioni DAX
SQL Server Analysis Services 2025 include il supporto per più nuove funzioni DAX e miglioramenti, tra cui:
LINEST e LINESTX: queste due funzioni eseguono la regressione lineare, usando il metodo Least Squares, per calcolare una linea retta più adatta ai dati specificati e restituire una tabella che descrive tale linea. Queste funzioni sono particolarmente utili per stimare valori sconosciuti (Y) quando vengono specificati valori noti (X). Per altre informazioni, visitare la funzione LINEST DAX e la funzione LINETX DAX.
Funzioni INFO: le DMV TMSCHEMA esistenti sono ora disponibili come nuova famiglia di funzioni DAX, che consente di eseguire query sui metadati sui modelli semantici direttamente all'interno di DAX, offrendo l'integrazione con altre funzioni DAX per la diagnostica e l'analisi avanzate. Per altre informazioni, vedere: Info DAX functions (Funzioni DAX).
APPROXIMATEDISTINCTCOUNT: questa funzione è attualmente disponibile per la modalità DirectQuery e restituisce un conteggio stimato di valori univoci in una colonna richiamando un'operazione di aggregazione corrispondente nell'origine dati, ottimizzata per le prestazioni delle query. Per altre informazioni, vedere La funzione DAX Approssimazionedistinctcount, che elenca le origini dati supportate.
Funzioni finestra: questa funzione recupera una sezione di risultati usando il posizionamento assoluto o relativo. La funzione WINDOW semplifica l'esecuzione di calcoli, ad esempio l'aggiunta di un totale in esecuzione, una media mobile o calcoli simili che si basano sulla selezione di un intervallo di valori. Include anche due funzioni helper denominate ORDERBY e PARTITIONBY. Per altri dettagli, vedere: Funzione Finestra DAX.
MINX/MAXX: È stato aggiunto un parametro variant facoltativo alle funzioni MINX e MAXX DAX. Tradizionalmente, queste funzioni ignorano i valori di testo e booleani quando sono presenti varianti o tipi di dati misti, ad esempio testo e numerico. Ora con il nuovo parametro variant facoltativo impostato su TRUE, le funzioni considerano i valori di testo. Per altre informazioni, visitare la funzione DAX MINX e la funzione DAX MAXX.
Suggerimento
Le funzioni INFO possono evolversi in Power BI per supportare l'individuazione delle informazioni nei nuovi artefatti del modello semantico. Vedere [MS-SSAS-T] per il set di artefatti che possono avere una funzione INFO corrispondente in SQL Server Analysis Services 2025.
Nuove edizioni per sviluppatori
Annotazioni
L'edizione completa e il supporto delle funzionalità per SQL Server Analysis Services 2025 non sono completamente documentati fino a quando il prodotto non è disponibile a livello generale. Le funzionalità e le edizioni descritte in questo articolo sono soggette a modifiche fino alla disponibilità generale.
Le seguenti edizioni gratuite sono progettate per fornire tutte le funzionalità delle corrispondenti edizioni a pagamento. Possono essere usati per sviluppare applicazioni DI SQL Server senza richiedere una licenza a pagamento.
Per le funzionalità per edizione, vedere Funzionalità supportate da SQL Server Edition
Le edizioni e le funzionalità supportate per SQL Server 2025 (17.x) Preview sono soggette a modifiche fino a quando il prodotto non è disponibile a livello generale.
Edizione Standard Developer
SQL Server 2025 Standard Developer Edition è un'edizione gratuita concessa in licenza per lo sviluppo. Include tutte le funzionalità di SQL Server Standard Edition.
- Sviluppare nuove applicazioni per l'edizione Standard.
- Configurare un ambiente di staging per certificare l'aggiornamento di un'applicazione esistente dall'edizione Standard a SQL Server 2025 Standard Edition prima di distribuirla nell'ambiente di produzione.
Enterprise Developer Edizione
SQL Server 2025 Enterprise Developer Edition include le funzionalità di SQL Server Enterprise Edition.
- Sviluppare nuove applicazioni per Enterprise Edition.
- Equivalente funzionalmente all'edizione Developer nelle versioni precedenti.
Funzionalità aggiuntive
Aggiornamenti della libreria client
I clienti sono invitati a eseguire l'aggiornamento alle librerie di Analysis Services più recenti per trarre vantaggio da miglioramenti delle prestazioni, dell'affidabilità e delle funzionalità, ad esempio il supporto XML binario, la serializzazione TMDL e altro ancora. In particolare, è stata passata la comunicazione basata su XMLA da XML normale a XML binario e è stata abilitata la compressione per le librerie client .NET. Per altri dettagli, visitare il blog relativo al miglioramento delle prestazioni di comunicazione degli strumenti basati su xmla . È anche possibile trovare sempre le versioni più recenti delle librerie client nella pagina di download delle librerie client di Analysis Services.
Miglioramenti alla gestione dei caratteri Unicode
SQL Server Analysis Services 2025 supporta ora gli standard Unicode aggiornati fornendo supporto per le coppie di surrogati Unicode per gli standard di caratteri, ad esempio lo standard del governo cinese GB18030 in DAX.
Metriche di esecuzione per la diagnostica
Le metriche di esecuzione vengono ora esposte tramite le tracce XEvents e Profiler, consentendo ai clienti di analizzare in modo più efficace le prestazioni delle query. Per altre informazioni, visitare questo blog.
Supporto per cluster di failover
Per altri dettagli, vedere questo articolo sullo schema di crittografia aggiornato.
Funzionalità deprecate e modifiche di rilievo in SQL Server Analysis Services 2025
Excel PowerPivot per SharePoint non più disponibile
È stata rimossa la modalità PowerPivot di Excel per SharePoint dal programma di installazione. Questa funzionalità è stata deprecata nelle versioni precedenti e non è più supportata in SQL Server Analysis Services 2025.
Aggiornamento dell'assembly client SQL
SQL Server Analysis Services 2025 usa ora una libreria client SQL più recente. I clienti potrebbero dover aggiornare le definizioni del modello per riflettere il nuovo nome del provider (Microsoft.Data.SqlClient).
Modifiche all'accesso HTTP
A partire da SQL Server Analysis Services 2025, le connessioni HTTP tramite msmdpump.dll verranno disabilitate per impostazione predefinita. Tutte le connessioni tramite msmdpump.dll devono essere effettuate tramite un canale sicuro come HTTPS. Per altri dettagli, vedere Configurare l'accesso HTTP.
Problemi noti
Windows Arm64 non supportato
SQL Server Analysis Services 2025 non è supportato in Windows Arm64. Attualmente sono supportate solo CPU Intel e AMD x86-64 con un massimo di 64 core per ogni nodo NUMA .
SQL Server 2022 Analysis Services
Aggiornamento cumulativo 1 (CU1)
Aggiornamento della crittografia
Questo aggiornamento include miglioramenti all'algoritmo di crittografia dell'operazione di scrittura dello schema. Questo miglioramento potrebbe richiedere l'aggiornamento di database di modelli tabulari e multidimensionali per garantire la crittografia corretta. Per altre informazioni, vedere Aggiornare la crittografia.
Disponibile a livello generale
Fusione orizzontale
Questa versione introduce Horizontal Fusion, un'ottimizzazione del piano di esecuzione delle query volta a ridurre il numero di query di origine dati necessarie per generare e restituire risultati. Più query di origine dati più piccole vengono unite in una query di origine dati più grande. Un numero minore di query sulle origini dati significa meno viaggi andata e ritorno e meno scansioni costose su grandi origini dati, con guadagni significativi nelle prestazioni DAX e riduzione della richiesta di elaborazione presso l'origine dati. Le query DAX vengono eseguite più velocemente con Horizontal Fusion, in particolare in modalità DirectQuery. Inoltre, la scalabilità aumenta.
Piani di esecuzione paralleli per DirectQuery
Questo miglioramento consente al motore di Analysis Services di analizzare le query DAX su un'origine dati DirectQuery e identificare le operazioni indipendenti del motore di archiviazione. Il motore può quindi eseguire tali operazioni sull'origine dati in parallelo. Eseguendo operazioni in parallelo, il motore di Analysis Services può migliorare le prestazioni delle query sfruttando la scalabilità di origini dati di grandi dimensioni. Per garantire che l'elaborazione delle query non sovraccarichi l'origine dati, usare l'impostazione della proprietà MaxParallelism per specificare un numero fisso di thread che possono essere usati per le operazioni parallele.
Supporto per i modelli semantici DirectQuery di Power BI
Questa versione introduce il supporto per i modelli di Power BI con connessioni DirectQuery ai modelli di SQL Server 2022 Analysis Services. Gli esperti di modellazione dei dati e gli autori di report che usano le versioni di maggio 2022 e successive di Power BI Desktop possono ora combinare i dati importati e quelli in DirectQuery da modelli di Power BI, Azure Analysis Services e ora SSAS 2022.
Per altre informazioni, vedere Uso di DirectQuery per modelli semantici e Analysis Services | Documentazione di Power BI.
Prestazioni delle query MDX
Introdotto dapprima in Power BI e ora in SSAS 2022, MDX Fusion comprende un'ottimizzazione del motore di formula (FE) che riduce il numero di query del motore di archiviazione (SE) per ogni query MDX. Le applicazioni client che usano MDX (Multidimensional Expressions) per eseguire query sui dati del modello o del set di dati, ad esempio Microsoft Excel, vedranno prestazioni delle query migliorate. I modelli di query MDX comuni richiedono ora un minor numero di query SE in cui in precedenza erano necessarie numerose query SE per supportare una granularità diversa. Meno query SE comportano un minor numero di analisi costose su modelli di grandi dimensioni, con un miglioramento significativo delle prestazioni, soprattutto quando ci si connette a modelli tabulari in modalità Direct Query.
Per altre informazioni, vedere Annuncio di prestazioni delle query MDX migliorate in Power BI | Blog di Microsoft Power BI.
Governance delle risorse
Questa versione include una maggiore accuratezza per la proprietà della memoria del server QueryMemoryLimit e la proprietà della stringa di connessione DbpropMsmdRequestMemoryLimit.
Introdotta per la prima volta in SSAS 2019, la proprietà di memoria del server QueryMemoryLimit applicata solo ai pool di memoria in cui i risultati intermedi delle query DAX vengono creati durante l'elaborazione delle query. Ora in SSAS 2022, si applica anche alle query MDX, coprendo effettivamente tutte le query. È possibile controllare meglio i processi delle query costose che comportano una materializzazione significativa. Se la query raggiunge il limite specificato, il motore annulla la query e restituisce un errore al chiamante, riducendo l'impatto su altri utenti simultanei.
Le applicazioni client possono ridurre ulteriormente la memoria consentita per ogni query specificando la proprietà della stringa di connessione DbpropMsmdRequestMemoryLimit . Specificata in Kilobyte, questa proprietà sostituisce il valore della proprietà memoria del server QueryMemoryLimit per la connessione.
Interleaving delle query - Distorsione di query breve con annullamento rapido
Questa versione introduce un nuovo valore che specifica la distorsione di query breve con annullamento rapido per l'impostazione della proprietà Threadpool\SchedulingBehavior. Questa impostazione di proprietà migliora i tempi di risposta delle query utente in scenari di concorrenza elevata. Per altre informazioni, vedere Interleaving di query - Configurare.
Livello di compatibilità del modello tabulare 1600
Questa versione introduce il livello di compatibilità 1600 per i modelli tabulari. Il livello di compatibilità 1600 coincide con le funzionalità più recenti in Power BI e Azure Analysis Services.
Funzionalità deprecate in SSAS 2022
Con questa versione non sono annunciate funzionalità deprecate .
Funzionalità non più disponibili in SSAS 2022
In questa versione non sono più disponibili le funzionalità seguenti:
| Modalità/Categoria | Caratteristica / Funzionalità |
|---|---|
| Tabellare | Livelli di compatibilità 1100 e 1103 |
| Multidimensionale | Data Mining |
| Modalità Power Pivot | PowerPivot per SharePoint |
Modifiche irreversibili in SSAS 2022
I livelli di compatibilità del modello tabulare 1100 e 1103 non sono più disponibili in questa versione. Per evitare una modifica di rilievo, aggiornare i modelli al livello di compatibilità 1200 prima di aggiornare una versione precedente di SSAS a SSAS 2022.
Modifiche del comportamento in SSAS 2022
In questa versione non sono state apportate modifiche al comportamento .
SQL Server 2019 Analysis Services
SQL Server 2019 Analysis Services CU 5
Gli aggiornamenti cumulativi di SQL Server Analysis Services sono inclusi negli aggiornamenti cumulativi di SQL Server. Per altre informazioni e scaricare l'aggiornamento cumulativo più recente, vedere l'aggiornamento cumulativo più recente di SQL Server 2019. Le pagine kb di aggiornamento cumulativo riepilogano problemi noti, miglioramenti e correzioni per tutte le funzionalità di SQL Server, tra cui SSAS. Altre informazioni sugli aggiornamenti delle funzionalità principali per SSAS sono descritte qui.
SuperDAX per i modelli multidimensionali (SuperDAXMD)
Con CU5, i client basati su DAX ora possono usare funzioni SuperDAX e modelli di query su modelli multidimensionali, offrendo prestazioni migliorate durante l'esecuzione di query sui dati del modello. SuperDAX ha introdotto le ottimizzazioni delle query DAX per i modelli tabulari con Power BI e SQL Server Analysis Services 2016. SuperDAXMD offre ora questi miglioramenti ai modelli multidimensionali.
Un annuncio separato nel blog di Power BI illustra in che modo gli utenti di Power BI possono trarre vantaggio da questo miglioramento delle prestazioni del modello multidimensionale scaricando la versione più recente di Power BI Desktop. I report interattivi esistenti nel servizio Power BI possono trarre vantaggio senza passaggi aggiuntivi, perché Power BI genera automaticamente le query SuperDAX ottimizzate. Power BI rileva automaticamente le connessioni ai modelli multidimensionali con supporto SuperDAX e usa le stesse funzioni DAX ottimizzate e gli stessi modelli di query già usati nei modelli tabulari. Anche se Power BI può passare automaticamente a SuperDAXMD, nelle proprie soluzioni di business intelligence potrebbe essere necessario ottimizzare manualmente i modelli di query DAX.
I modelli di query ottimizzati devono usare la funzione SUMMARIZECOLUMNS per sostituire la funzione SUMMARIZE standard meno efficiente. Usare variabili DAX, VAR, per calcolare le espressioni una sola volta al posto della definizione e quindi riutilizzare i risultati in qualsiasi altra espressione DAX senza dover eseguire di nuovo il calcolo. Altre funzioni SuperDAX, e forse meno comuni, sono SUBSTITUTEWITHINDEX, ADDMISSINGITEMS, così come NATURALLEFTOUTERJOIN e NATURALINNERJOIN, ISONORAFTER e GROUPBY. SELECTCOLUMNS e UNION sono anche funzioni SuperDAX.
Per altre informazioni sul funzionamento di DAX con i modelli multidimensionali e su modelli e vincoli importanti da tenere presente, vedere DAX per i modelli multidimensionali.
SQL Server 2019 Analysis Services GA (disponibile a livello generale)
Livello di compatibilità del modello tabulare
Questa versione introduce il livello di compatibilità 1500 per i modelli tabulari.
Intercalazione delle query
L'interleaving delle query è una configurazione di sistema in modalità tabulare che può migliorare i tempi di risposta delle query degli utenti negli scenari con concorrenza elevata. L'interfoliazione delle query con distorsione delle query brevi consente alle query simultanee di condividere le risorse della CPU. Per altre informazioni, vedere Interfoliazione di query.
Gruppi di calcolo in modelli tabulari
I gruppi di calcolo possono ridurre significativamente il numero di misure ridondanti raggruppando le espressioni di misura comuni come elementi di calcolo. I gruppi di calcolo vengono visualizzati nei client di report come tabella con una singola colonna. Ogni valore nella colonna rappresenta un calcolo riutilizzabile o un elemento di calcolo che può essere applicato a qualsiasi misura. Un gruppo di calcolo può avere un numero qualsiasi di elementi di calcolo. Ogni elemento di calcolo è definito da un'espressione DAX. Per altre informazioni, vedere Gruppi di calcolo.
Impostazione di governance per gli aggiornamenti della cache di Power BI
L'impostazione della proprietà ClientCacheRefreshPolicy è ora supportata in SSAS 2019 e versioni successive. Questa impostazione di proprietà è già disponibile per Azure Analysis Services. Il servizio Power BI memorizza nella cache i dati del riquadro del dashboard e i dati del report per il caricamento iniziale del report di Live Connect, causando un numero eccessivo di query della cache inviate al motore e, in casi estremi, sovraccaricare il server. La proprietà ClientCacheRefreshPolicy consente di eseguire l'override di questo comportamento a livello di server. Per altre informazioni, vedere Proprietà generali.
Allegato online
Questa funzionalità consente di collegare un modello tabulare come operazione online. L'attach online può essere usato per la sincronizzazione di repliche di sola lettura negli ambienti con scalabilità orizzontale delle query in locale. Per eseguire un'operazione di collegamento online, utilizzare l'opzione AllowOverwrite del comando Attach XMLA.

Questa operazione potrebbe richiedere il doppio della memoria del modello per mantenere online la versione precedente durante il caricamento della nuova versione.
Un modello di utilizzo tipico può essere il seguente:
DB1 (versione 1) è già collegato nel server di sola lettura B.
DB1 (versione 2) viene elaborato nel server di scrittura A.
DB1 (versione 2) viene scollegato e posizionato in una posizione accessibile al server B (tramite una posizione condivisa o tramite robocopy e così via).
Il comando Attach with AllowOverwrite=True viene eseguito nel server B con la nuova posizione di DB1 (versione 2).
Senza questa funzionalità, gli amministratori devono prima scollegare il database e quindi collegare la nuova versione del database. Ciò comporta tempi di inattività quando il database non è disponibile per gli utenti e le query su di esso avranno esito negativo.
Quando si specifica questo nuovo flag, la versione 1 del database viene eliminata in modo atomico all'interno della stessa transazione senza tempi di inattività. Tuttavia, è a costo di avere entrambi i database caricati contemporaneamente in memoria.
Relazioni molti-a-molti nei modelli tabulari
Questo miglioramento consente relazioni molti-a-molti tra tabelle in cui entrambe le colonne non sono univoche. È possibile definire una relazione tra una dimensione e una tabella dei fatti con una granularità superiore alla colonna chiave della dimensione. In questo modo si evita di dover normalizzare le tabelle delle dimensioni e di migliorare l'esperienza utente perché il modello risultante ha un numero inferiore di tabelle con colonne raggruppate logicamente.
Le relazioni molti-a-molti richiedono che i modelli siano al livello di compatibilità 1500 o superiore. È possibile creare relazioni molti-a-molti usando Visual Studio 2019 con i progetti di Analysis Services VSIX update 2.9.2 e versioni successive, l'API Tabular Object Model (TOM), il linguaggio TMSL (Tabular Model Scripting Language) e lo strumento Editor Tabulare open source.
Impostazioni di memoria per la governance delle risorse
Le impostazioni delle proprietà seguenti offrono una governance delle risorse migliorata:
- Memory\QueryMemoryLimit : questa proprietà di memoria può essere usata per limitare i pool di memoria compilati dalle query DAX inviate al modello.
- DbpropMsmdRequestMemoryLimit : questa proprietà XMLA può essere utilizzata per eseguire l'override del valore della proprietà del server Memory\QueryMemoryLimit per una connessione.
- OLAP\Query\RowsetSerializationLimit : questa proprietà del server limita il numero di righe restituite in un set di righe, proteggendo le risorse del server da un utilizzo esteso dell'esportazione dei dati. Questa proprietà si applica a entrambe le query DAX e MDX.
Queste proprietà possono essere impostate usando la versione più recente di SQL Server Management Studio (SSMS). Queste impostazioni sono già disponibili per Azure Analysis Services.
Funzionalità deprecate in SSAS 2019
Con questa versione non sono annunciate funzionalità deprecate .
Funzionalità non più disponibili in SSAS 2019
Non sono state annunciate funzionalità non più disponibili con questa versione.
Modifiche significative in SSAS 2019
In questa versione non sono state apportate modifiche di rilievo .
Modifiche del comportamento in SSAS 2019
In questa versione non sono state apportate modifiche al comportamento .
SQL Server 2017 Analysis Services
SQL Server 2017 Analysis Services visualizza alcuni dei miglioramenti più importanti a partire da SQL Server 2012. Basandosi sul successo della modalità tabulare (introdotta per la prima volta in SQL Server 2012 Analysis Services), questa versione rende i modelli tabulari più potenti che mai.
La modalità multidimensionale e la modalità Power Pivot per SharePoint sono un elemento fondamentale per molte distribuzioni di Analysis Services. Nel ciclo di vita del prodotto Analysis Services queste modalità sono mature. In questa versione non sono disponibili nuove funzionalità per queste modalità. Sono tuttavia incluse correzioni di bug e miglioramenti delle prestazioni.
Le funzionalità descritte di seguito sono incluse in SQL Server 2017 Analysis Services. Tuttavia, per sfruttarli, è necessario usare anche le versioni più recenti di Visual Studio con progetti Analysis Services e SQL Server Management Studio (SSMS). I progetti di Analysis Services e SSMS vengono aggiornati mensilmente con funzionalità nuove e migliorate che in genere coincidono con nuove funzionalità in SQL Server.
Anche se è importante conoscere tutte le nuove funzionalità, è anche importante sapere cosa è deprecato e non più disponibile in questa versione e nelle versioni future. Per altre informazioni, vedere Funzionalità deprecate in SSAS 2017.
Di seguito vengono esaminate alcune delle nuove funzionalità principali di questa versione.
Livello di compatibilità 1400 per i modelli tabulari
Per sfruttare molte delle nuove funzionalità descritte qui, è necessario impostare o aggiornare modelli tabulari nuovi o esistenti al livello di compatibilità 1400. I modelli a livello di compatibilità 1400 non possono essere distribuiti in SQL Server 2016 SP1 o versioni precedenti oppure è stato effettuato il downgrade a livelli di compatibilità inferiori. Per altre informazioni, vedere Livello di compatibilità per i modelli tabulari di Analysis Services.
In Visual Studio è possibile selezionare il nuovo livello di compatibilità 1400 durante la creazione di nuovi progetti di modello tabulare.
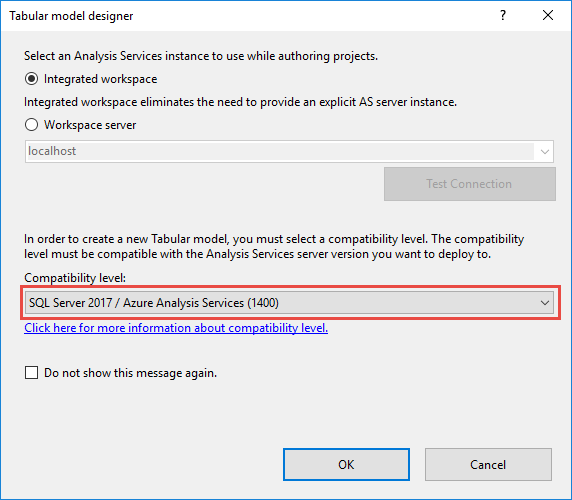
Per aggiornare un modello tabulare esistente in Visual Studio, in Esplora soluzioni fare clic con il pulsante destro del mouse su Model.bim e quindi in Proprietà impostare la proprietà Livello di compatibilità su SQL Server 2017 (1400).
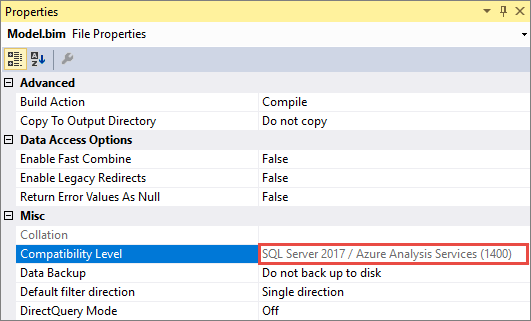
È importante tenere presente che, dopo aver aggiornato un modello esistente a 1400, non è possibile effettuare il downgrade. Assicurarsi di mantenere un backup del database modello 1200.
Esperienza moderna di acquisizione dati
Quando si tratta di importare dati da origini dati nei modelli tabulari, SSDT introduce l'esperienza moderna Recupera dati per i modelli a livello di compatibilità 1400. Questa nuova funzionalità si basa su funzionalità simili in Power BI Desktop e Microsoft Excel 2016. L'esperienza moderna Recupera dati offre enormi funzionalità di trasformazione dei dati e mashup dei dati usando il generatore di query Recupera dati e le espressioni M.
L'esperienza moderna Recupera dati offre supporto per un'ampia gamma di origini dati. In futuro, gli aggiornamenti includeranno supporto per ancora più elementi.
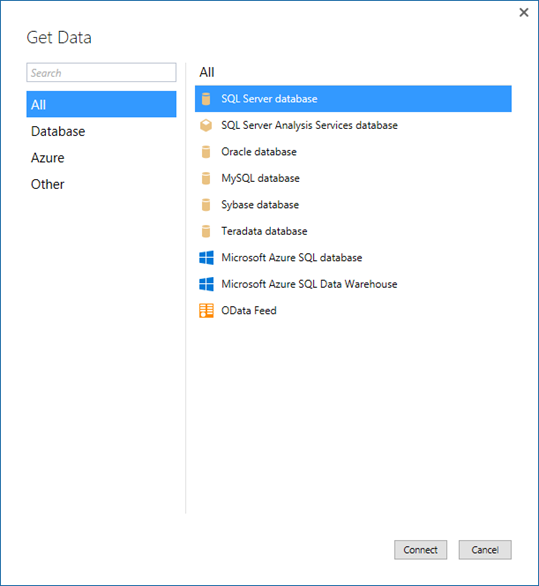
Un'interfaccia utente potente e intuitiva semplifica la selezione dei dati e delle funzionalità di trasformazione/mashup dei dati.
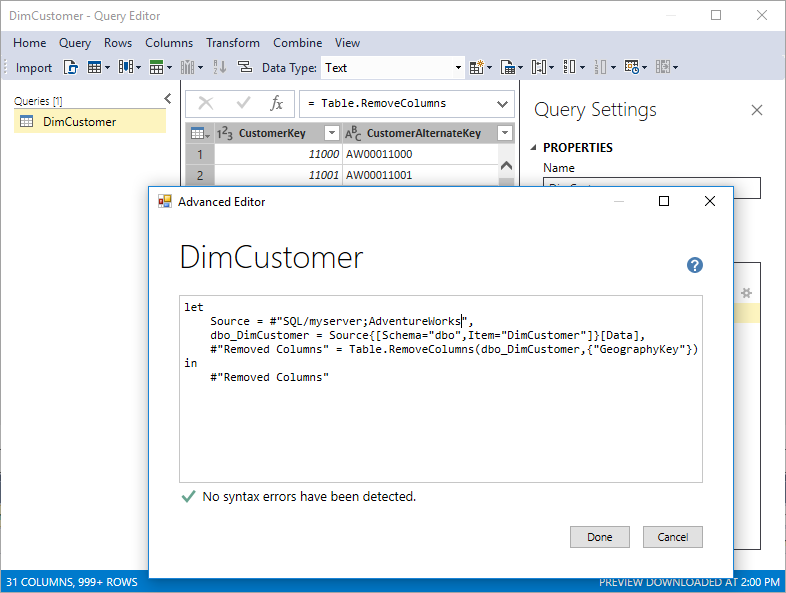
Le moderne funzionalità di Get Data e M mashup non si applicano ai modelli tabulari esistenti aggiornati a partire dal livello di compatibilità 1200 fino a 1400. La nuova esperienza si applica solo ai nuovi modelli creati a livello di compatibilità 1400.
Suggerimenti di codifica
Questa versione introduce hint di codifica, una funzionalità avanzata usata per ottimizzare l'elaborazione (aggiornamento dati) di modelli tabulari di grandi dimensioni in memoria. Per comprendere meglio la codifica, vedere Ottimizzazione delle prestazioni dei modelli tabulari nel white paper di SQL Server 2012 Analysis Services per comprendere meglio la codifica.
La codifica dei valori offre prestazioni migliori per le query per le colonne che vengono in genere usate solo per le aggregazioni.
La codifica hash è preferibile per le colonne group-by (spesso valori di tabella delle dimensioni) e per le chiavi esterne. Le colonne di tipo stringa sono sempre codificate in hash.
Le colonne numeriche possono usare uno di questi metodi di codifica. Quando Analysis Services avvia l'elaborazione di una tabella, se la tabella è vuota (con o senza partizioni) o viene eseguita un'operazione di elaborazione della tabella completa, vengono acquisiti valori di esempio per ogni colonna numerica per determinare se applicare la codifica hash o valore. Per impostazione predefinita, la codifica dei valori viene scelta quando l'esempio di valori distinti nella colonna è sufficientemente grande. In caso contrario, la codifica hash offre in genere una compressione migliore. È possibile che Analysis Services modifichi il metodo di codifica dopo che la colonna viene parzialmente elaborata in base a ulteriori informazioni sulla distribuzione dei dati e riavviare il processo di codifica; Tuttavia, questo aumenta il tempo di elaborazione ed è inefficiente. Il white paper sull'ottimizzazione delle prestazioni illustra in modo più dettagliato la ri-codifica e descrive come rilevarlo usando SQL Server Profiler.
Gli hint di codifica consentono al modellatore di specificare una preferenza per il metodo di codifica alla luce di dati preesistenti dalla profilatura dei dati e/o in risposta agli eventi di tracciamento. Poiché l'aggregazione sulle colonne con codifica hash è più lenta rispetto alle colonne con codifica valore, la codifica dei valori può essere specificata come hint per tali colonne. Non è garantito che venga applicata la preferenza. Si tratta di un suggerimento anziché di un'impostazione. Per specificare un hint di codifica, impostare la proprietà EncodingHint sulla colonna. I valori possibili sono "Default", "Value" e "Hash". Il frammento di metadati basato su JSON seguente del file Model.bim specifica la codifica dei valori per la colonna Sales Amount.
{
"name": "Sales Amount",
"dataType": "decimal",
"sourceColumn": "SalesAmount",
"formatString": "\\$#,0.00;(\\$#,0.00);\\$#,0.00",
"sourceProviderType": "Currency",
"encodingHint": "Value"
}
Gerarchie irregolari
Nei modelli tabulari è possibile modellare le gerarchie padre-figlio. Le gerarchie con un numero diverso di livelli vengono spesso definite gerarchie incomplete. Per impostazione predefinita, le gerarchie incomplete vengono visualizzate con spazi vuoti per i livelli al di sotto del figlio più basso. Ecco un esempio di gerarchia incompleta in un organigramma:
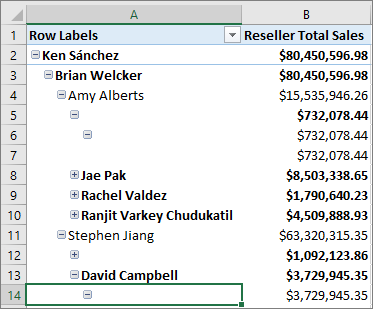
Questa versione introduce la proprietà Hide Members . È possibile impostare la proprietà Nascondi membri in una gerarchia su Nascondi membri vuoti.
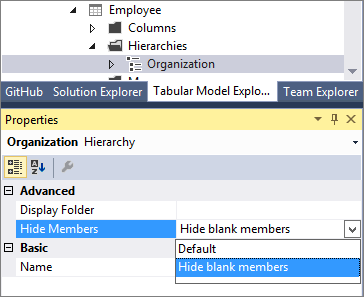
Annotazioni
I membri vuoti nel modello sono rappresentati da un valore vuoto DAX, non da una stringa vuota.
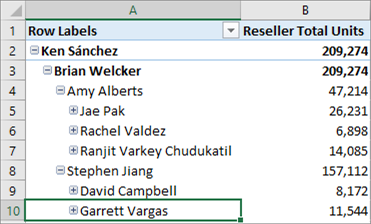
Se è impostata su Nascondi membri vuoti e il modello distribuito, viene visualizzata una versione di lettura più semplice della gerarchia nei client di report come Excel.
Righe di dettaglio
È ora possibile definire un set di righe personalizzato che contribuisce a un valore di misura. Le righe di dettaglio sono simili all'azione drill-through predefinita nei modelli multidimensionali. In questo modo gli utenti finali possono visualizzare le informazioni in modo più dettagliato rispetto al livello aggregato.
La PivotTable seguente mostra le Vendite Totali su Internet per anno, dal modello tabulare di esempio Adventure Works. È possibile fare clic con il pulsante destro del mouse su una cella con un valore aggregato dalla misura e quindi scegliere Mostra dettagli per visualizzare le righe di dettaglio.
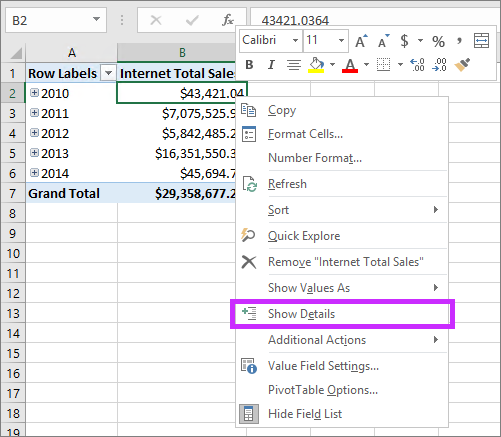
Per impostazione predefinita, vengono visualizzati i dati associati nella tabella Internet Sales. Questo comportamento limitato spesso non è significativo per l'utente perché la tabella potrebbe non avere le colonne necessarie per mostrare informazioni utili, ad esempio il nome del cliente e le informazioni sull'ordine. Con le righe di dettaglio è possibile specificare una proprietà Detail Rows Expression per le misure.
Proprietà dell'Espressione delle Righe di Dettaglio per le misure
La proprietà Detail Rows Expression per le misure consente agli autori di modelli di personalizzare le colonne e le righe restituite all'utente finale.
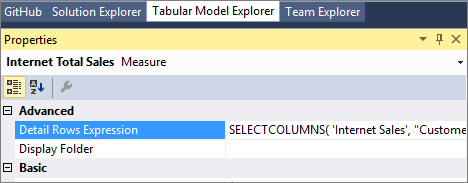
La funzione DAX SELECTCOLUMNS viene comunemente usata in un'espressione di righe di dettaglio. Nell'esempio seguente vengono definite le colonne da restituire per le righe nella tabella Internet Sales del modello tabulare Adventure Works di esempio:
SELECTCOLUMNS(
'Internet Sales',
"Customer First Name", RELATED( Customer[Last Name]),
"Customer Last Name", RELATED( Customer[First Name]),
"Order Date", 'Internet Sales'[Order Date],
"Internet Total Sales", [Internet Total Sales]
)
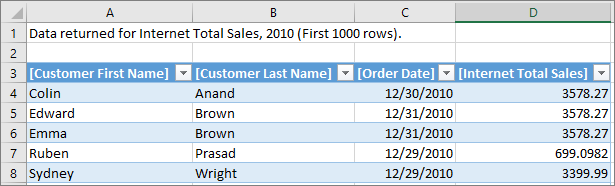
Con la proprietà definita e il modello distribuito, viene restituito un set di righe personalizzato quando l'utente seleziona Mostra dettagli. Rispetta automaticamente il contesto di filtro della cella selezionata. In questo esempio vengono visualizzate solo le righe per il valore 2010:
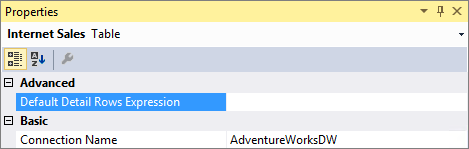
Proprietà Default Detail Rows Expression per le tabelle
Oltre alle misure, le tabelle hanno anche una proprietà per definire un'espressione di righe di dettaglio. La proprietà Default Detail Rows Expression funge da valore predefinito per tutte le misure all'interno della tabella. Le misure che non hanno una propria espressione definita ereditano l'espressione dalla tabella e mostrano il set di righe definito per la tabella. In questo modo è possibile riutilizzare le espressioni e le nuove misure aggiunte alla tabella ereditano automaticamente l'espressione.
Funzione DAX DETAILROWS
In questa versione è inclusa una nuova funzione DAX DETAILROWS che restituisce il set di righe definito dall'espressione di righe di dettaglio. Funziona in modo analogo all'istruzione DRILLTHROUGH in MDX, compatibile anche con le espressioni di righe di dettaglio definite nei modelli tabulari.
La query DAX seguente restituisce il set di righe definito dall'espressione di righe di dettaglio per la misura o la relativa tabella. Se non viene definita alcuna espressione, i dati per la tabella Internet Sales vengono restituiti perché si tratta della tabella contenente la misura.
EVALUATE DETAILROWS([Internet Total Sales])
Sicurezza a livello di oggetto
Questa versione introduce la sicurezza a livello di oggetto per tabelle e colonne. Oltre a limitare l'accesso ai dati di tabella e colonna, è possibile proteggere i nomi di tabella e colonna sensibili. Ciò consente di impedire a un utente malintenzionato di individuare tale tabella.
La sicurezza a livello di oggetto deve essere impostata usando i metadati basati su JSON, il linguaggio TMSL (Tabular Model Scripting Language) o il modello a oggetti tabulari (TOM).
Ad esempio, il codice seguente consente di proteggere la tabella Product nel modello tabulare Adventure Works di esempio impostando la proprietà MetadataPermission della classe TablePermission su Nessuno.
//Find the Users role in Adventure Works and secure the Product table
ModelRole role = db.Model.Roles.Find("Users");
Table productTable = db.Model.Tables.Find("Product");
if (role != null && productTable != null)
{
TablePermission tablePermission;
if (role.TablePermissions.Contains(productTable.Name))
{
tablePermission = role.TablePermissions[productTable.Name];
}
else
{
tablePermission = new TablePermission();
role.TablePermissions.Add(tablePermission);
tablePermission.Table = productTable;
}
tablePermission.MetadataPermission = MetadataPermission.None;
}
db.Update(UpdateOptions.ExpandFull);
DMVs (Viste di Gestione Dinamica)
Le DMV sono query in SQL Server Profiler che restituiscono informazioni sulle operazioni del server locale e sull'integrità del server. Questa versione include miglioramenti alle Viste di Gestione Dinamica (DMV) per i modelli tabulari ai livelli di compatibilità 1200 e 1400.
DISCOVER_CALC_DEPENDENCY Ora funziona con i modelli tabulari 1200 e versioni successive. I modelli tabulari 1400 e superiori mostrano dipendenze tra partizioni M, espressioni M e origini dati strutturate. Per altre informazioni, vedere il blog di Analysis Services.
MDSCHEMA_MEASUREGROUP_DIMENSIONS Sono inclusi miglioramenti per questa DMV, che viene utilizzata da diversi strumenti client per mostrare la dimensionalità delle misure. Ad esempio, la caratteristica Esplora nelle tabelle pivot di Excel consente all'utente di eseguire un'analisi incrociata alle dimensioni correlate alle misure selezionate. Questa versione corregge le colonne di cardinalità, che in precedenza mostravano valori non corretti.
Miglioramenti DAX
Una delle nuove funzionalità DAX più importanti è la nuova funzione IN Operator/CONTAINSROW per le espressioni DAX. Questo è simile all'operatore TSQL IN comunemente usato per specificare più valori in una WHERE clausola .
In precedenza, era comune specificare filtri multivalore usando l'operatore logico OR , come nell'espressione di misura seguente:
Filtered Sales:=CALCULATE (
[Internet Total Sales],
'Product'[Color] = "Red"
|| 'Product'[Color] = "Blue"
|| 'Product'[Color] = "Black"
)
Questa operazione è semplificata usando l'operatore IN :
Filtered Sales:=CALCULATE (
[Internet Total Sales], 'Product'[Color] IN { "Red", "Blue", "Black" }
)
In questo caso, l'operatore IN fa riferimento a una tabella a colonna singola con 3 righe, una per ognuno dei colori specificati. Nota che la sintassi del costruttore di tabella usa parentesi graffe.
L'operatore IN è funzionalmente equivalente alla CONTAINSROW funzione :
Filtered Sales:=CALCULATE (
[Internet Total Sales], CONTAINSROW({ "Red", "Blue", "Black" }, 'Product'[Color])
)
L'operatore IN può essere usato in modo efficace anche con i costruttori di tabella. Ad esempio, la misura seguente filtra in base alle combinazioni di colore e categoria del prodotto:
Filtered Sales:=CALCULATE (
[Internet Total Sales],
FILTER( ALL('Product'),
( 'Product'[Color] = "Red" && Product[Product Category Name] = "Accessories" )
|| ( 'Product'[Color] = "Blue" && Product[Product Category Name] = "Bikes" )
|| ( 'Product'[Color] = "Black" && Product[Product Category Name] = "Clothing" )
)
)
Usando il nuovo IN operatore, l'espressione di misura precedente è ora equivalente a quella seguente:
Filtered Sales:=CALCULATE (
[Internet Total Sales],
FILTER( ALL('Product'),
('Product'[Color], Product[Product Category Name]) IN
{ ( "Red", "Accessories" ), ( "Blue", "Bikes" ), ( "Black", "Clothing" ) }
)
)
Altri miglioramenti
Oltre a tutte le nuove funzionalità, Analysis Services, SSDT e SSMS includono anche i miglioramenti seguenti:
- Gerarchie e riutilizzo delle colonne resi visibili in posizioni più utili nell'elenco dei campi di Power BI.
- Relazioni di data per creare facilmente connessioni con dimensioni associate alle date basate sui campi temporali.
- L'opzione di installazione predefinita per Analysis Services è ora per la modalità tabulare.
- Nuove origini dati Recupera dati (Power Query).
- Editor DAX per SSDT.
- Le risorse dati DirectQuery esistenti supportano le query M.
- Miglioramenti di SSMS, ad esempio visualizzazione, modifica e supporto di scripting per origini dati strutturate.
Funzionalità deprecate in SSAS 2017
In questa versione sono deprecate le funzionalità seguenti:
| Modalità/Categoria | Caratteristica / Funzionalità |
|---|---|
| Multidimensionale | Estrazione dei dati |
| Multidimensionale | Gruppi di misure collegati remoti |
| Tabellare | Modelli a livello di compatibilità 1100 e 1103 |
| Tabellare | Proprietà del modello a oggetti tabulari - Column.TableDetailPosition, Column.IsDefaultLabel, Column.IsDefaultImage |
| Attrezzi | SQL Server Profiler per l'acquisizione delle tracce La sostituzione consiste nell'usare Extended Events Profiler incorporato in SQL Server Management Studio. Consulta Monitorare Analysis Services con eventi estesi di SQL Server. |
| Attrezzi | Profiler del server per il replay della traccia Sostituzione. Non c'è sostituzione. |
| Oggetti di gestione delle tracce e API di traccia | Oggetti Microsoft.AnalysisServices.Trace (contiene le API per gli oggetti Trace e Replay di Analysis Services). La sostituzione è in più parti: - Configurazione della traccia: Microsoft.SqlServer.Management.XEvent - Lettura traccia: Microsoft.SqlServer.XEvent.Linq - Riproduzione traccia: Nessuno |
Funzionalità non più disponibili in SSAS 2017
In questa versione non sono più disponibili le funzionalità seguenti:
| Modalità/Categoria | Caratteristica / Funzionalità |
|---|---|
| Tabellare | Il valore della proprietà di memoria VertiPaqPagingPolicy (2) abilita il paging su disco utilizzando i file mappati alla memoria. |
| Multidimensionale | Partizioni remote |
| Multidimensionale | Gruppi di misure collegati remoti |
| Multidimensionale | Aggiornamento dimensionale |
| Multidimensionale | Dimensioni collegate |
Modifiche di rilievo in SSAS 2017
In questa versione non sono state apportate modifiche di rilievo .
Modifiche del comportamento in SSAS 2017
Modifiche a MDSCHEMA_MEASUREGROUP_DIMENSIONS e DISCOVER_CALC_DEPENDENCY, descritte in dettaglio nell'annuncio Novità di SQL Server 2017 CTP 2.1 per Analysis Services .
SQL Server 2016 Analysis Services
SQL Server 2016 Analysis Services include molti nuovi miglioramenti che offrono prestazioni migliorate, creazione di soluzioni semplificate, gestione automatica dei database, relazioni avanzate con filtro incrociato bidirezionale, elaborazione parallela delle partizioni e molto altro ancora. Al centro della maggior parte dei miglioramenti per questa versione è il nuovo livello di compatibilità 1200 per i database modello tabulare.
SQL Server 2016 Service Pack 1 (SP1) Analysis Services
SQL Server 2016 Service SP1 Analysis Services offre prestazioni e scalabilità migliorate grazie alla consapevolezza NUMA (Non-Uniform Memory Access) e all'allocazione ottimizzata della memoria basata su Intel Threading Building Blocks (Intel TBB). Questa nuova funzionalità consente di ridurre il costo totale di proprietà (TCO) supportando più utenti in meno server aziendali più potenti.
In particolare, le funzionalità di SQL Server 2016 SP1 Analysis Services sono migliorate in queste aree chiave:
- Riconoscimento NUMA : per un migliore supporto NUMA, il motore in memoria (VertiPaq) all'interno di Analysis Services ora gestisce una coda di processi separata in ogni nodo NUMA. Ciò garantisce che i processi di analisi segmento vengano eseguiti nello stesso nodo in cui la memoria viene allocata per i dati del segmento. Si noti che la consapevolezza NUMA è abilitata solo per impostazione predefinita nei sistemi con almeno quattro nodi NUMA. Nei sistemi a due nodi, i costi di accesso alla memoria allocata remota in genere non giustificano il sovraccarico legato alla gestione delle specifiche NUMA.
- Allocazione di memoria : Analysis Services è stata accelerata con i blocchi predefiniti di Intel Threading, un allocatore scalabile che fornisce pool di memoria separati per ogni core. Con l'aumentare del numero di core, il sistema può essere ridimensionato quasi linearmente.
- Frammentazione dell'heap - L'allocatore scalabile basato su Intel TBB aiuta anche a attenuare i problemi di prestazioni a causa della frammentazione dell'heap che si è dimostrato verificarsi con l'heap di Windows.
I test di prestazioni e scalabilità hanno mostrato miglioramenti significativi nella velocità effettiva delle query durante l'esecuzione di SQL Server 2016 SP1 Analysis Services in server aziendali multinodo di grandi dimensioni.
Anche se la maggior parte dei miglioramenti in questa versione è specifica per i modelli tabulari, sono stati apportati numerosi miglioramenti ai modelli multidimensionali; ad esempio, ottimizzazione ROLAP di conteggio distinto per origini dati come DB2 e Oracle, supporto di drill-through a selezione multipla con Excel 2016 e le ottimizzazioni delle query di Excel.
SQL Server 2016 Disponibilità Generale (GA) Servizi di Analisi
Modellazione
Miglioramento delle prestazioni di modellazione per i modelli tabulari 1200
Per i modelli tabulari 1200, le operazioni sui metadati in SSDT sono molto più veloci rispetto ai modelli tabulari 1100 o 1103. Per confronto, nello stesso hardware, la creazione di una relazione su un modello impostato sul livello di compatibilità di SQL Server 2014 (1103) con 23 tabelle richiede 3 secondi, mentre la stessa relazione su un modello creato su un modello impostato sul livello di compatibilità 1200 richiede poco meno di un secondo.
Modelli di progetto aggiunti per i modelli tabulari 1200 in SSDT
Con questa versione non sono più necessarie due versioni di SSDT per la creazione di progetti relazionali e BI. SQL Server Data Tools per Visual Studio 2015 aggiunge modelli di progetto per soluzioni Analysis Services, inclusi i progetti tabulari di Analysis Services usati per la compilazione di modelli a livello di compatibilità 1200. Sono inclusi anche altri modelli di progetto di Analysis Services per soluzioni di data mining e multidimensionali, ma allo stesso livello funzionale (1100 o 1103) delle versioni precedenti.
Visualizzare le cartelle
Le cartelle di visualizzazione sono ora disponibili per i modelli tabulari 1200. Definito in SQL Server Data Tools e sottoposto a rendering in applicazioni client come Excel o Power BI Desktop, le cartelle di visualizzazione consentono di organizzare un numero elevato di misure in singole cartelle, aggiungendo una gerarchia visiva per semplificare la navigazione negli elenchi di campi.
Filtro incrociato bidirezionale
Novità di questa versione è un approccio predefinito per abilitare filtri incrociati bidirezionali nei modelli tabulari, eliminando la necessità di soluzioni DAX create a mano per propagare il contesto di filtro tra le relazioni tra tabelle. I filtri vengono generati automaticamente solo quando la direzione può essere stabilita con un elevato grado di certezza. Se si verifica un'ambiguità sotto forma di più percorsi di query tra le relazioni tra tabelle, non verrà creato automaticamente un filtro. Per informazioni dettagliate, vedere Filtri incrociati bidirezionali per i modelli tabulari in SQL Server 2016 Analysis Services .
Traduzioni
È ora possibile archiviare i metadati tradotti in un modello tabulare 1200. I metadati nel modello includono campi per Cultura, didascalie tradotte e descrizioni tradotte. Per aggiungere traduzioni, usare il comando Model>Translations in SQL Server Data Tools. Per informazioni dettagliate, vedere Traduzioni nei modelli tabulari (Analysis Services ).
Tabelle incollate
È ora possibile aggiornare un modello tabulare 1100 o 1103 a 1200 quando il modello contiene tabelle incollate. È consigliabile usare SQL Server Data Tools. In SSDT impostare CompatibilityLevel su 1200 e quindi eseguire la distribuzione in un'istanza di SQL Server 2017 di SQL Server Analysis Services. Per informazioni dettagliate, vedere Livello di compatibilità per i modelli tabulari in Analysis Services .
Tabelle calcolate in SSDT
Una tabella calcolata è una costruzione disponibile solo nel modello basata su un'espressione o una query DAX in SSDT. Quando viene distribuito in un database, una tabella calcolata è indistinguibile dalle tabelle normali.
Esistono diversi usi per le tabelle calcolate, inclusa la creazione di nuove tabelle per esporre una tabella esistente in un ruolo specifico. L'esempio classico è una tabella Date che opera in più contesti (data di ordine, data di spedizione e così via). Creando una tabella calcolata per un determinato ruolo, è ora possibile attivare una relazione di tabella per facilitare le query o l'interazione dei dati usando la tabella calcolata. Un altro uso per le tabelle calcolate consiste nel combinare parti di tabelle esistenti in una tabella completamente nuova che esiste solo nel modello. Per altre informazioni, vedere Creare una tabella calcolata .
Correzione della formula
Con la correzione della formula in un modello tabulare 1200, SSDT aggiornerà automaticamente tutte le misure che fanno riferimento a una colonna o a una tabella rinominata.
Supporto per Gestione configurazione di Visual Studio
Per supportare più ambienti, ad esempio ambienti di test e pre-produzione, Visual Studio consente agli sviluppatori di creare più configurazioni di progetto usando Configuration Manager. I modelli multidimensionali sfruttano già questo, ma i modelli tabulari non lo hanno fatto. Con questa versione è ora possibile usare Configuration Manager per la distribuzione in server diversi.
Gestione delle istanze
Amministrare modelli tabulari 1200 in SSMS
In questa versione un'istanza di Analysis Services in modalità server tabulare può eseguire modelli tabulari a qualsiasi livello di compatibilità (1100, 1103, 1200). La versione più recente di SQL Server Management Studio viene aggiornata per visualizzare le proprietà e fornire l'amministrazione del modello di database per i modelli tabulari a livello di compatibilità 1200.
Elaborazione parallela per più partizioni di tabella nei modelli tabulari
Questa versione include nuove funzionalità di elaborazione parallela per le tabelle con due o più partizioni, aumentando le prestazioni di elaborazione. Non sono disponibili impostazioni di configurazione per questa funzionalità. Per altre informazioni sulla configurazione di partizioni e tabelle di elaborazione, vedere Partizioni di modelli tabulari.
Aggiungere account computer come amministratori in SSMS
Gli amministratori di SQL Server Analysis Services possono ora usare SQL Server Management Studio per configurare gli account computer come membri del gruppo di amministratori di SQL Server Analysis Services. Nella finestra di dialogo Seleziona utenti o gruppi impostare i percorsi per il dominio computer e quindi aggiungere il tipo di oggetto Computers . Per altre informazioni, vedere Concedere i diritti di amministratore del server a un'istanza di Analysis Services.
DBCC per Analysis Services
Il controllo coerenza del database (DBCC) viene eseguito internamente per rilevare potenziali problemi di danneggiamento dei dati sul carico del database, ma può anche essere eseguito su richiesta se si sospettano problemi nei dati o nel modello. DBCC esegue controlli diversi a seconda che il modello sia tabulare o multidimensionale. Per informazioni dettagliate, vedere Database Consistency Checker (DBCC) per database tabulari e multidimensionali di Analysis Services .
Aggiornamenti degli eventi estesi
Questa versione aggiunge un'interfaccia utente grafica a SQL Server Management Studio per configurare e gestire gli eventi estesi di SQL Server Analysis Services. È possibile configurare flussi di dati live per monitorare l'attività del server in tempo reale, mantenere i dati della sessione caricati in memoria per un'analisi più rapida o salvare i flussi di dati in un file per l'analisi offline. Per altre informazioni, vedere Monitor Analysis Services with SQL Server Extended Events(Utilizzo di eventi estesi di SQL Server per il monitoraggio di Analysis Services).
Scrittura di script
PowerShell per modelli tabulari
Questa versione include miglioramenti di PowerShell per i modelli tabulari a livello di compatibilità 1200. È possibile usare tutti i cmdlet applicabili, oltre ai cmdlet specifici per la modalità tabulare: Invoke-ProcessASDatabase e Invoke-ProcessTable cmdlet.
Operazioni di scripting del database SSMS
Nella versione più recente di SQL Server Management Studio (SSMS) lo script è ora abilitato per i comandi del database, tra cui Create, Alter, Delete, Backup, Restore, Attach, Detach. L'output è linguaggio di scripting del modello tabulare (TMSL) in JSON. Per altre informazioni, vedere Informazioni di riferimento su TMSL (Tabular Model Scripting Language).
Attività Esegui DDL di Analysis Services
L'attività Esegui DDL di Analysis Services accetta ora anche comandi TMSL (Tabular Model Scripting Language).
Cmdlet di PowerShell per SSAS
Il cmdlet di PowerShell di SSAS Invoke-ASCmd accetta ora comandi TMSL (Tabular Model Scripting Language). Altri cmdlet di PowerShell di SSAS possono essere aggiornati in una versione futura per usare i nuovi metadati tabulari (le eccezioni verranno evidenziate nelle note sulla versione). Per informazioni dettagliate, vedere Informazioni di riferimento su PowerShell per Analysis Services.
Tabular Model Scripting Language (TMSL) supportato in SSMS
Usando la versione più recente di SSMS, è ora possibile creare script per automatizzare la maggior parte delle attività amministrative per i modelli tabulari 1200. Attualmente, è possibile creare script per le attività seguenti: Elaborare a qualsiasi livello, oltre a CREATE, ALTER, DELETE a livello di database.
A livello funzionale, TMSL equivale all'estensione XMLA ASSL che fornisce definizioni di oggetti multidimensionali, ad eccezione del fatto che TMSL usa descrittori nativi come modello, tabella e relazione per descrivere i metadati tabulari. Per informazioni dettagliate sullo schema, vedere Informazioni di riferimento su TMSL (Tabular Model Scripting Language).
Uno script basato su JSON generato per un modello tabulare potrebbe essere simile al seguente:
{
"create": {
"database": {
"name": "AdventureWorksTabular1200",
"id": "AdventureWorksTabular1200",
"compatibilityLevel": 1200,
"readWriteMode": "readWrite",
"model": {}
}
}
}
Il payload è un documento JSON che può essere minimo come l'esempio illustrato in precedenza o altamente abbellito con il set completo di definizioni di oggetti. Informazioni di riferimento su TMSL (Tabular Model Scripting Language) descrivono la sintassi.
A livello di database, i comandi CREATE, ALTER e DELETE restituiranno lo script TMSL nella finestra XMLA familiare. Altri comandi, ad esempio Process, possono anche essere inseriti in script in questa versione. Il supporto di script per molte altre azioni può essere aggiunto in una versione futura.
| Comandi scriptabili | Descrizione |
|---|---|
| creare | Aggiunge un database, una connessione o una partizione. L'equivalente ASSL è CREATE. |
| createOrReplace | Aggiorna una definizione di oggetto esistente (database, connessione o partizione) sovrascrivendo una versione precedente. L'equivalente ASSL è ALTER con AllowOverwrite impostato su true e ObjectDefinition su ExpandFull. |
| eliminare | Rimuove una definizione di oggetto. L'equivalente ASSL è DELETE. |
| aggiornare | Elabora l'oggetto. L'equivalente ASSL è PROCESS. |
DAX
Modifica migliorata delle formule DAX
Gli aggiornamenti alla barra della formula consentono di scrivere formule con maggiore facilità, differenziando funzioni, campi e misure usando la colorazione della sintassi. Fornisce suggerimenti intelligenti per funzioni e campi e indica se parti dell'espressione DAX sono errate usando le sottolineature ondulate di errore. Consente anche di utilizzare più righe (Alt + Invio) e l'indentazione (Tab). La barra della formula ora consente anche di scrivere commenti come parte delle misure, basta digitare "//" e tutto dopo questi caratteri sulla stessa riga verrà considerato un commento.
Variabili DAX
Questa versione include ora il supporto per le variabili in DAX. Le variabili possono ora archiviare il risultato di un'espressione come variabile denominata, che può quindi essere passata come argomento ad altre espressioni di misura. Dopo che i valori risultanti sono stati calcolati per un'espressione di variabile, tali valori non cambiano, anche se la variabile viene fatto riferimento in un'altra espressione. Per altre informazioni, vedere Funzione VAR.
Nuove funzioni DAX
Con questa versione, DAX introduce oltre cinquanta nuove funzioni per supportare calcoli più veloci e visualizzazioni avanzate in Power BI. Per altre informazioni, vedere Nuove funzioni DAX.
Salvare misure incomplete
È ora possibile salvare misure DAX incomplete direttamente in un progetto di modello tabulare 1200 e riprenderla quando si è pronti per continuare.
Miglioramenti aggiuntivi di DAX
- Calcolo del non vuoto: riduce il numero di analisi necessarie per il non vuoto.
- Measure Fusion: più misure della stessa tabella verranno combinate in un singolo motore di archiviazione: query.
- Set di raggruppamento: quando una query richiede misure con più granularità (totale/anno/mese), viene inviata una singola query al livello più basso e il resto delle granularità deriva dal livello più basso.
- Eliminazione di join ridondanti: una singola query al motore di memorizzazione restituisce sia i valori delle colonne di dimensione che quelli delle misure.
- Valutazione stretta di IF/SWITCH: un ramo la cui condizione è falsa non comporterà più query al motore di archiviazione. In precedenza, i rami venivano valutati con entusiasmo, ma i risultati venivano eliminati in un secondo momento.
Sviluppatore
Namespace Microsoft.AnalysisServices.Tabular per la programmabilità di Tabular 1200 in AMO
Analysis Services Management Objects (AMO) viene aggiornato per includere un nuovo spazio dei nomi tabulare per la gestione di un'istanza in modalità tabulare di SQL Server 2016 Analysis Services, oltre a fornire il linguaggio di definizione dei dati per la creazione o la modifica di modelli tabulari 1200 a livello di codice. Visitare Microsoft.AnalysisServices.Tabular per leggere l'API.
Aggiornamenti di Analysis Services Management Objects (AMO)
Analysis Services Management Objects (AMO) è stato refattorizzato per includere un secondo assembly, Microsoft.AnalysisServices.Core.dll. Il nuovo assembly separa le classi comuni, ad esempio Server, Database e Ruolo, che hanno un'applicazione generale in Analysis Services, indipendentemente dalla modalità server. In precedenza, queste classi facevano parte dell'assembly Microsoft.AnalysisServices originale. Spostandoli in un nuovo assembly apre la strada per le estensioni future a AMO, con una chiara divisione tra API generiche e specifiche del contesto. Le applicazioni esistenti non sono interessate dai nuovi assembly. Tuttavia, se si sceglie di ricompilare le applicazioni utilizzando il nuovo assembly AMO per qualsiasi motivo, assicurarsi di aggiungere un riferimento a Microsoft.AnalysisServices.Core. Analogamente, gli script di PowerShell che caricano e chiamano in AMO devono ora caricare Microsoft.AnalysisServices.Core.dll. Assicurarsi di aggiornare gli script.
Editor JSON per i file BIM
Visualizzazione codice in Visual Studio 2015 esegue ora il rendering del file BIM in formato JSON per i modelli tabulari 1200. La versione di Visual Studio determina se il rendering del file BIM viene eseguito in JSON tramite l'editor JSON predefinito o come testo semplice.
Per usare l'editor JSON, con la possibilità di espandere e comprimere sezioni del modello, sarà necessaria la versione più recente di SQL Server Data Tools più Visual Studio 2015 (qualsiasi edizione, inclusa l'edizione Community gratuita). Per tutte le altre versioni di SSDT o Visual Studio, il rendering del file BIM viene eseguito in JSON come testo semplice. Come minimo, un modello vuoto conterrà il codice JSON seguente:
{
"name": "SemanticModel",
"id": "SemanticModel",
"compatibilityLevel": 1200,
"readWriteMode": "readWrite",
"model": {}
}
Avvertimento
Evitare di modificare direttamente il codice JSON. In questo modo è possibile danneggiare il modello.
Nuovi elementi nello schema MS-CSDLBI 2.0
Gli elementi seguenti sono stati aggiunti al tipo complesso TProperty definito nello schema [MS-CSDLBI] 2.0:
| Elemento | Definizione |
|---|---|
| Valore predefinito | Proprietà che specifica il valore utilizzato durante la valutazione della query. La proprietà DefaultValue è facoltativa, ma viene selezionata automaticamente se i valori del membro non possono essere aggregati. |
| Statistiche | Set di statistiche dei dati sottostanti associati alla colonna. Queste statistiche sono definite dal tipo complesso TPropertyStatistics e vengono fornite solo se non sono dispendiose a livello di calcolo da generare, come descritto nella sezione 2.1.13.5 del documento Concettual Schema Definition File Format with Business Intelligence Annotations (Formato file di definizione dello schema concettuale con annotazioni business intelligence). |
DirectQuery
Nuova implementazione di DirectQuery
Questa versione vede miglioramenti significativi in DirectQuery per i modelli tabulari 1200. Di seguito è disponibile un riepilogo:
- DirectQuery genera ora query più semplici che offrono prestazioni migliori.
- Controllo aggiuntivo sulla definizione di set di dati di esempio usati per la progettazione e il test del modello.
- La sicurezza a livello di riga è ora supportata per i modelli tabulari 1200 in modalità DirectQuery. In precedenza, la presenza di sicurezza a livello di riga impediva la distribuzione di un modello tabulare in modalità DirectQuery.
- Le colonne calcolate sono ora supportate per i modelli tabulari 1200 in modalità DirectQuery. In precedenza, la presenza di colonne calcolate impediva la distribuzione di un modello tabulare in modalità DirectQuery.
- Le ottimizzazioni delle prestazioni includono l'eliminazione ridondante dei join per VertiPaq e DirectQuery.
Nuove origini dati per la modalità DirectQuery
Le origini dati supportate per i modelli tabulari 1200 in modalità DirectQuery includono ora Oracle, Teradata e Microsoft Analytics Platform (in precedenza noto come Parallel Data Warehouse). Per altre informazioni, vedere Modalità DirectQuery.
Funzionalità deprecate in SSAS 2016
In questa versione sono deprecate le funzionalità seguenti:
| Modalità/Categoria | Caratteristica / Funzionalità |
|---|---|
| Multidimensionale | Partizioni remote |
| Multidimensionale | Gruppi di misure collegati remoti |
| Multidimensionale | Aggiornamento dimensionale |
| Multidimensionale | Dimensioni collegate |
| Multidimensionale | Notifiche delle tabelle di SQL Server per la memorizzazione nella cache proattiva. La soluzione è utilizzare il polling per la cache proattiva. Vedere Memorizzazione nella cache attiva (dimensioni) e Memorizzazione nella cache attiva (partizioni). |
| Multidimensionale | Cubi di sessione. Non c'è sostituzione. |
| Multidimensionale | Cubi locali. Non c'è sostituzione. |
| Tabellare | I livelli di compatibilità del modello tabulare 1100 e 1103 non saranno supportati in una versione futura. La sostituzione consiste nell'impostare i modelli a livello di compatibilità 1200 o superiore, convertendo le definizioni di modello in metadati tabulari. Vedere Livello di compatibilità per i modelli tabulari in Analysis Services. |
| Attrezzi | SQL Server Profiler per l'acquisizione delle tracce La sostituzione consiste nell'usare Extended Events Profiler incorporato in SQL Server Management Studio. Consulta Monitorare Analysis Services con eventi estesi di SQL Server. |
| Attrezzi | Profiler del server per il replay della traccia Sostituzione. Non c'è sostituzione. |
| Oggetti di gestione delle tracce e API di traccia | Oggetti Microsoft.AnalysisServices.Trace (contiene le API per gli oggetti Trace e Replay di Analysis Services). La sostituzione è in più parti: - Configurazione della traccia: Microsoft.SqlServer.Management.XEvent - Lettura traccia: Microsoft.SqlServer.XEvent.Linq - Riproduzione traccia: Nessuno |
Funzionalità non più disponibili in SSAS 2016
In questa versione non sono più disponibili le funzionalità seguenti:
| Caratteristica / Funzionalità | Sostituzione o soluzione alternativa |
|---|---|
| CalculationPassValue (MDX) | Nessuno. Questa funzionalità è stata deprecata in SQL Server 2005. |
| CalculationCurrentPass (MDX) | Nessuno. Questa funzionalità è stata deprecata in SQL Server 2005. |
| Non vuoto: suggerimento per l'ottimizzatore di query | Nessuno. Questa funzionalità è stata deprecata in SQL Server 2008. |
| Assemblaggi COM | Nessuno. Questa funzionalità è stata deprecata in SQL Server 2008. |
| CELL_EVALUATION_LIST proprietà intrinseca della cella | Nessuno. Questa funzionalità è stata deprecata in SQL Server 2005. |
Modifiche di rilievo in SSAS 2016
Aggiornamento della versione di .NET 4.0
Le librerie client AMO (Analysis Services Management Objects), ADOMD.NET e Tabular Object Model (TOM) hanno ora come destinazione il runtime .NET 4.0. Può trattarsi di una modifica con effetti dirompenti per le applicazioni destinate a .NET 3.5. Le applicazioni che usano versioni più recenti di questi assembly devono ora essere destinate a .NET 4.0 o versione successiva.
Aggiornamento della versione AMO
Questa versione è un aggiornamento di versione per Analysis Services Management Objects (AMO) ed è un cambiamento importante in alcune circostanze specifiche. Il codice e gli script esistenti che chiamano in AMO continueranno a essere eseguiti come prima se si esegue l'aggiornamento da una versione precedente. Tuttavia, se è necessario ricompilare l'applicazione e si è destinati a un'istanza di SQL Server 2016 Analysis Services, è necessario aggiungere lo spazio dei nomi seguente per rendere operativo il codice o lo script:
using Microsoft.AnalysisServices;
using Microsoft.AnalysisServices.Core;
Lo spazio dei nomi Microsoft.AnalysisServices.Core è ora necessario ogni volta che si fa riferimento all'assembly Microsoft.AnalysisServices nel codice. Gli oggetti precedentemente usati solo nello spazio dei nomi Microsoft.AnalysisServices vengono spostati nello spazio dei nomi Core in questa versione se l'oggetto viene usato nello stesso modo in scenari tabulari e multidimensionali. Ad esempio, le API correlate al server vengono spostate nello spazio dei nomi Core.
Sebbene ora siano presenti più spazi dei nomi, entrambi esistono nello stesso assembly (Microsoft.AnalysisServices.dll).
Modifiche di XEvent DISCOVER
Per supportare meglio lo streaming XEvent DISCOVER in SSMS per SQL Server 2016 Analysis Services, DISCOVER_XEVENT_TRACE_DEFINITION viene sostituito con le tracce XEvent seguenti:
DISCOVER_XEVENT_PACKAGES
DISCOVER_XEVENT_OBJECT
SCOPRI_COLONNE_OGGETTO_XEVENT
DISCOVER_XEVENT_SESSION_TARGETS
Modifiche del comportamento in SSAS 2016
Analysis Services in modalità SharePoint
L'esecuzione della configurazione guidata di Power Pivot non è più necessaria come attività di post-installazione. Ciò vale per tutte le versioni supportate di SharePoint che caricano i modelli dall'istanza corrente di SQL Server 2016 Analysis Services.
Modalità DirectQuery per i modelli tabulari
DirectQuery è una modalità di accesso ai dati per i modelli tabulari, in cui l'esecuzione di query viene eseguita in un database relazionale back-end, recuperando un set di risultati in tempo reale. Viene spesso usato per set di dati di dimensioni molto grandi che non possono essere contenuti in memoria o quando i dati sono volatili e si desidera che i dati più recenti restituiti nelle query su un modello tabulare.
DirectQuery esiste come modalità di accesso ai dati per le ultime versioni. In SQL Server 2016 Analysis Services l'implementazione è stata leggermente modificata, presupponendo che il modello tabulare sia a livello di compatibilità 1200 o superiore. DirectQuery presenta meno restrizioni rispetto a prima. Ha anche proprietà di database diverse.
Se si usa DirectQuery in un modello tabulare esistente, è possibile mantenere il modello al livello di compatibilità 1100 o 1103 e continuare a usare DirectQuery come implementato per tali livelli. In alternativa, è possibile eseguire l'aggiornamento a 1200 o versione successiva per trarre vantaggio dai miglioramenti apportati a DirectQuery.
Non è disponibile alcun aggiornamento sul posto di un modello DirectQuery perché le impostazioni dei livelli di compatibilità precedenti non hanno controparti esatte nei livelli di compatibilità più recenti 1200 e superiori. Se si dispone di un modello tabulare esistente in esecuzione in modalità DirectQuery, è necessario aprire il modello in SQL Server Data Tools, disattivare DirectQuery, impostare la proprietà Livello di compatibilità su 1200 o versione successiva e quindi riconfigurare le proprietà DirectQuery. Per informazioni dettagliate, vedere Modalità DirectQuery .
Definizioni
Una funzionalità deprecata verrà sospesa dal prodotto in una versione futura, ma è ancora supportata e inclusa nella versione corrente per mantenere la compatibilità con le versioni precedenti. È consigliabile interrompere l'uso di funzionalità deprecate nei progetti nuovi ed esistenti per mantenere la compatibilità con le versioni future. La documentazione non viene aggiornata per le funzionalità deprecate.
Una funzionalità non più disponibile è stata deprecata in una versione precedente. Può continuare a essere incluso nella versione corrente, ma non è più supportato. Le funzionalità non più disponibili possono essere rimosse interamente nella versione dichiarata o futura.
Una modifica sostanziale impedisce il funzionamento di una funzionalità, di un modello di dati, di un codice applicativo o di uno script dopo l'aggiornamento alla versione corrente.
Una modifica del comportamento influisce sul funzionamento della stessa funzionalità nella versione corrente rispetto alla versione precedente. Vengono descritte solo modifiche significative del comportamento. Le modifiche apportate all'interfaccia utente non sono incluse. Le modifiche ai valori predefiniti, la configurazione manuale necessaria per completare una funzionalità di aggiornamento o ripristino o una nuova implementazione di una funzionalità esistente sono tutti esempi di una modifica del comportamento.