Il presente articolo è stato tradotto automaticamente.
Esecuzione dei test
Analisi progetto esposizione E dei rischi tramite rischio e PERICOLO
Download codice disponibile dalla Raccolta di codice di MSDN
Selezionare il codice in linea
Contenuto
I rischi di metadati
Identificazione dei rischi
Analisi dei rischi
Disposizione dei
Tutti i progetti software affrontare rischi. Un rischio è un evento, che può o non possono verificarsi e che genera sorta di perdita. La relazione tra rischio e test del software è semplice. Perché, tranne in casi rari, è impossibile con attenzione verificare un sistema software, analisi dei rischi rivela problemi che possono causare la perdita la maggior parte dei. È possibile utilizzare queste informazioni consentono di definire la priorità del lavoro test. Nell'articolo di questo mese presenterò pratiche tecniche che è possibile utilizzare per identificare e analizzare i rischi in un progetto software. Si inizia.
Si supponga una situazione ipotetica nella quale si sviluppa un'applicazione basata sul Web di ASP.NET di qualche tipo. Nella figura 1 viene illustrato alcuni dei problemi associati all'analisi dei rischi software e idee principali. Il processo generale di analisi dei rischi prevede Identificazione dei rischi, la probabilità stima ogni rischio è, determinando la perdita associata a ogni rischio e combinazione probabilità e la perdita di informazioni in un valore denominato esposizione al rischio.
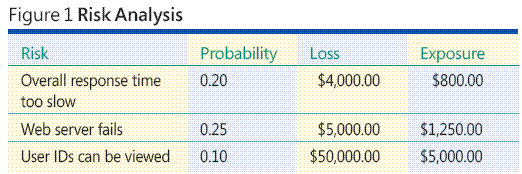
In base ai dati di esempio nella Figura 1 , il rischio che "ID utente possono essere visualizzati" prevede l'esposizione massimo altri fattori che uguale, che probabilmente si desidera rendere una priorità superiore per verificare questa opzione per impedire il rischio di divenire una realtà. Ma come è identificare i rischi? Come è possibile stimare la probabilità di rischio e perdite È comunque possibile eseguire analisi dei rischi se si non prevede probabilità di rischio e la perdita?
Anche se sono stati diversi sforzi di formalizzare e standardizzare terminologia di analisi dei rischi, in pratica diversi termini tendono a essere utilizzato in domini diversi problemi. Utilizzerà il termine "analisi dei rischi" per media elaborazione esposizione al rischio moltiplicando la probabilità di rischio o probabilità per la perdita di rischio o significa che il processo generale di identificazione, analisi e gestione dei rischi del progetto software.
Di malgrado il fatto che analisi dei rischi sono una parte importante critico di sviluppo software, in base alla mia esperienza, molte tecniche di analisi del rischio sono ampiamente note nel software test comunità. Se le ricerche nel Web, si noterà decine di migliaia di riferimenti all'analisi dei rischi di software. Tuttavia, la maggior parte dei seguenti fa riferimento a un indirizzo analisi molto ad alto livello di rischio non presenti tecniche pratiche o presente solo una tecnica di analisi dei rischi specifici e non spiegare come la tecnica si inserisce in un'infrastruttura di analisi dei rischi generali. Verrà visualizzato una panoramica di analisi dei rischi e tecniche utili che è possibile utilizzare immediatamente nell'ambiente di sviluppo software.
Nelle sezioni di questo articolo descritto due metadati rischi che sono comuni a tutti i progetti software. Quindi è possibile presentare tre metodi che è possibile identificare specifici rischi associati al progetto software e tre modi per l'analisi dei rischi. In particolare, verrà presentare un'interessante nuovo rischio analisi tecnica denominata esposizione di progetto utilizzando impatto ordinato e rischio e probabilità (PERICOLO) che è particolarmente utile in un ambiente di sviluppo software. È possibile concludere con una breve descrizione della gestione dei rischi. Ritiene che le tecniche qui presentate diventerà un'aggiunta molto utile per il software di test, sviluppo e gestione strumento kit.
I rischi di metadati
Due tipi speciali di analisi dei rischi di progetto software sono cosa è possibile chiamare tempo e costi analisi dei rischi di metadati. Gestione dei progetti tradizionale definisce un concetto con nomi diversi, tra cui "il progetto gestione triplo vincolo" e "triangolo del progetto management." L'idea è, in breve, che praticamente tutti i progetti ha tre fattori limitazione: costo, pianificazione e ambito. Costo è la quantità denaro che è necessario dedicare al progetto pianificazione è il tempo è necessario completare il progetto e ambito è l'insieme di funzionalità progetto necessari e le qualità.
I vincoli di tre progetto dispone di un'ampia gamma di alias. Ad esempio costo è detto anche preventivo o denaro. Pianificazione viene spesso chiamata tempo o durata. E ambito è a volte definito funzionalità, o qualità o anche funzionalità e qualità. Si noti che questo vincolo di funzionalità e qualità l'ultimo può essere ovvero e spesso è infatti considerati due vincoli distinti.
Un concetto chiave è che una modifica in uno dei vincoli probabilmente causerà una modifica in una o entrambe due vincoli. Ad esempio, se si sviluppa un'applicazione software e improvvisamente necessario per completare il progetto in un periodo di tempo più breve quanto inizialmente pianificato, sarà probabilmente necessario dedicare più denaro (ad esempio, per acquistare risorse aggiuntive o esterno parte del progetto) o tagliare alcune funzionalità o la qualità. Se viene rimosso il budget per il progetto, quindi sarà probabilmente necessario estendere il tempo di fine del progetto, rimuovere alcune funzionalità o ridurre la qualità del progetto. Utilizza il paradigma di triangolo gestione progetto poiché test software è progettata per migliorare la qualità di un sistema, ne consegue che i due massimi livelli di rischio in un progetto software siano il progetto non viene completata puntualmente e che il progetto viene eseguito superiore al preventivo.
È possibile relativamente semplice ma efficace per valutare i rischi di pianificazione e il costo generali a un progetto software. Diamo un'occhiata solo i metadati pianificazione tempo rischio analisi rischio e Costo preventivato funziona esattamente allo stesso modo. Il primo passaggio un'analisi meta-risk ad alto livello consiste di suddividere il progetto globale in blocchi più piccoli e più gestibili di attività.
Si supponga ad esempio, sta lavorando in un piccolo progetto dell'applicazione Web e il progetto deve essere completato in 30 giorni di lavoro. È possibile iniziare l'analisi dei rischi di metadati per elencare tutte le attività partecipate al progetto. Di seguito l'approccio più comune consiste nel creare ciò che viene chiamato una struttura di suddivisione di lavoro (WBS), visualizzabile nella Figura 2 . Creare un'attività principale che è costituito dall'intero progetto. Quindi di suddividere tale attività in un numero di sottoattività più piccoli, in genere su tre attività sette. Si ripetere il processo, decomposing ogni sub-task in sottoattività inferiore fino a raggiungere il livello di granularità appropriato per il proprio ambiente.
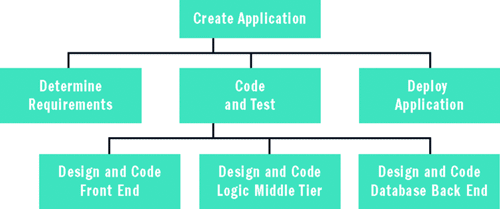
Nella figura 2 struttura funzionale della produzione
Il livello inferiore, le attività di nodo foglia a volte vengono chiamate i pacchetti di lavoro. Esattamente come scompongono le attività e la granularità apportate il WBS dipende da una serie di fattori. Ad esempio, in un ambiente di sviluppo agile, è anche possibile che della struttura funzionale completa di semplice a due livelli soddisfi le proprie esigenze. Oppure, se si lavora su un progetto software molto estesi e complessi utilizzando una metodologia di ciclo di vita di sviluppo software tradizionali, si dispone decine di migliaia di pacchetti di lavoro.
È possibile creare un piccolo WBS manualmente, utilizzare strumenti di produttività generico, ad esempio Microsoft Office Excel, oppure strumenti sofisticati, ad esempio Microsoft Office Project. Un WBS non contiene informazioni sequencing, tempi e costi. In altre parole, una WBS indica cosa deve essere effettuata, ma non in quali ordine e non indica come lungo ogni attività richiederà o quanto ogni avrà un costo. Dopo aver creato la struttura funzionale del progetto, in genere il passaggio successivo consiste nell'utilizzare i pacchetti di lavoro per creare ciò che viene chiamato un diagramma di precedenza.
.gif)
Nella figura 3 precedenza diagramma
Il diagramma di precedenza aggiunge informazioni di sequenza. Il diagramma illustrato nella Figura 3 indica che l'attività dei requisiti deve essere completato prima l'attività database back end, che a sua volta necessario completare prima che sia l'attività di livello intermedio e le attività Front-End possa iniziare. Queste ultime due attività può essere eseguita in parallelo in base al diagramma di precedenza. Infine, sia l'attività di livello intermedio e le attività Front-End deve essere completate prima che possa iniziare l'attività di distribuzione di applicazioni.
Dopo avere creato un diagramma di precedenza con le informazioni di sequenza, il passaggio successivo nell'analisi di meta-risk volta è necessario valutare il tempo richiesto per ogni pacchetto di lavoro. Anche se è possibile stimare ogni ora come una singola coordinata, un approccio migliore consiste fornire le stime tre, ovvero una stima ottimistica, una stima di stima migliore e una stima pessimistica.
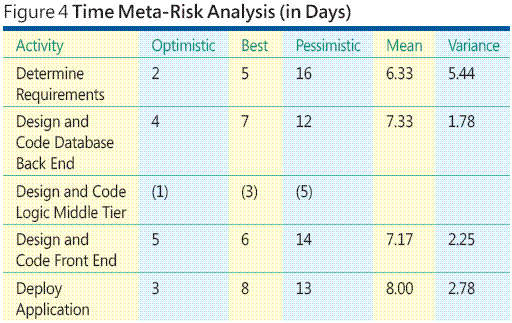
OK, ma solo tali stime provenienza? Determinazione di stime di costi e tempo fa parte di gran lunga più difficile di analisi dei rischi di metadati progetto software. Esistono molti modi per stimare il tempo di attività e il costo. È possibile utilizzare prestazioni cronologiche, educated tentativi, modelli matematiche avanzate e così via. Le tecniche utilizzabili verranno dipendono dalle proprie esigenze. Indipendentemente dal metodo utilizzare, stima il tempo e costo di un insieme di attività più piccolo è molto più stima il tempo e il costo di un'attività monolitica semplice. La tabella nella Figura 4 illustra meta rischio un tempo esempio-analisi.
Quando sono analisi ottimistica, volta ipotesi migliore e pessimistica che i dati, in genere utilizzare una semplice distribuzione matematica chiamata la distribuzione beta. La media o la media, di una distribuzione beta viene calcolata come questo:
(optimistic + (4 * best-guess) + pessimistic) / 6
In modo per la distribuzione di applicazioni attività al tempo stimato medio per completamento è:
mean = (3 + 4*8 + 13) / 6
= 48 / 6
= 8.0 days.
Si noti che una media della versione beta è semplicemente una media ponderata con i pesi 1, 4 e 1. Di conseguenza, la varianza di una distribuzione beta è determinata dalla seguente formula:
((pessimistic - optimistic)/6)²
Pertanto, per l'attività di distribuzione di applicazioni la variazione è:
variance = ((13 - 3) / 6)²
= (10/6)²
= (1.6667)²
= 2.78 days²
La deviazione standard generale per il progetto è la radice quadrata della somma delle varianze delle attività. Pertanto, in questo esempio, l'equazione aspetto seguente:
std. deviation = sqrt(5.44 + 1.78 + 2.25 + 2.78)
= sqrt(12.25)
= 3.50 days
Si noti che i calcoli non utilizzano i dati per l'attività normale e codice logica intermedio, livello. Poiché l'attività di livello di regola secondo può essere eseguita in parallelo con l'attività di database back-end e Front-End attività può iniziare finché non sono state entrambe le attività parallele, l'attività parallela più breve (secondo logica livello) non esplicitamente contribuisce al tempo complessivo per completare il progetto.
Questo tipo di analisi viene chiamato il metodo di percorso critico (CPM) ed è una tecnica di gestione di progetto standard. Con la pianificazione Media e varianza dati calcolati, è ora possibile calcolare la probabilità che avranno più di 30 giorni per completare l'intero progetto:
z = (30.00 - 28.83) / 3.50 = 0.33
p(0.33) = 0.6293
p(late) = 1.0000 - 0.6293 = 0.3707
In primo luogo, si calcola l'cosiddette z valore, che equivale alla quantità di tempo che sono programmata per completare il progetto (in questo caso, 30 giorni) meno il tempo previsto di completamento (giorni 28.83) diviso la deviazione standard di totale dell'attività (3.50 giorni). Quindi è rendere il valore z (0.33) e cercare la corrispondente p-valore in una tabella di distribuzione normale standard oppure utilizzare la funzione di Excel DISTRIB.NORM.ST (0.6293). Infine, si sottrae un valore p-da 1.0000 per ottenere la probabilità che il progetto verrà inseriti in pianificazione.
Si sta eseguendo un'analisi di una coda perché desiderati solo se è più lungo di quello pianificato e non attenzione se si scattano meno tempo. Con dati in questo esempio, è la probabilità che l'applicazione Web più di 30 giorni per completare 0.3707 o quasi 40 %, ovvero una situazione piuttosto rischioso. Se si ritiene informazioni per un momento, il risultato deve senso. La programmazione pianificata di 26 giorni di sviluppo è troppo vicino al limite di progetto di 30 giorni e, non si dispone disponibile spazio sufficiente wiggle per conto per le variazioni di programmazione.
Ovviamente, i risultati di rischio metadati sono solo come come le dati di input, il tempo in questo caso stima. Se le stime di input sono errate, Nessun importo di analisi statistica può produrre risultati significativi. Per calcolare la probabilità di rischio di metadati che il progetto verrà inseriti fuori preventivo utilizzando la stessa tecnica come stato appena illustrato per pianificazione. Dopo aver configurato la probabilità che il progetto verrà inseriti su pianificazione, è possibile calcolare l'esposizione al rischio di rischio metadati se è possibile stimare la perdita di valuta a causa di in ritardo.
In alcuni casi, potrebbe essere in un contratto per creare un sistema software e il contratto può essere ben definiti e significativi riduzioni in ritardo. Si supponga ad esempio, i contratto stati penalità $10,000.00 per il recapito in ritardo. L'esposizione al rischio di metadati è $ 10,000.00 * 0.3707 = $3,707. In altri casi, il costo di un progetto software ritardo è troppo difficile stimare oltre "molto, molto costoso."
Ma si noti che, anche senza un esposizione al rischio di calcolo, l'analisi del rischio metadati ora produce informazioni utili. Se si esaminano i dati nella figura 4 , si noterà che attività di determinare i requisiti ha SV maggiore. Di conseguenza, applicando semplicemente le risorse aggiuntive in anticipo del progetto può ridurre la varianza di attività, che a sua volta consente di ridurre la probabilità di passare su pianificazione.
Identificazione dei rischi
A differenza di tempi e costi metadati rischi, in cui gli eventi di rischio possono essere determinati in un po'dettagliate (anche se assolutamente semplice) modo da iteratively decomposing attività in sottoattività più piccole, identificazione dei rischi in genere è molto meno meccaniche. In un ambiente di prova e sviluppo del software, esistono tre metodi principali per l'identificazione dei rischi: base tassonomia, lo scenario, in base e base specifica.
Una tassonomia è solo un elenco di classificazione. Considerare l'analogia seguente. Si intende eseguire un viaggio in aereo, pertanto è utilizzare un elenco promemoria standard che è possibile utilizzare prima di ogni di andata e ritorno. L'elenco contiene istruzioni o domande ad esempio, " È necessario mio ID?" e "disporre È controllato per verificare se il volo è puntualmente"?
Nel corso degli anni, molte persone e organizzazioni sono creata software rischio tassonomie. Ha creato un elenco di tali sono Boehm, un pioneer iniziali e un researcher noti nell'area di rischio del progetto software. In 1989 Boehm identificato una tassonomia di rischio software 10 superiore e ha aggiornato l'elenco nel 1995. Versione di tassonomia alto rischio progetto software 10 1995 è elencata di seguito:
- Shortfalls personale
- Pianificazioni, budget, processo
- Software commerciali disponibili, componenti esterni
- Mancata corrispondenza dei requisiti
- Mancata corrispondenza di interfaccia utente
- Architettura, le prestazioni, di qualità
- Le modifiche dei requisiti
- Software legacy
- Le attività eseguite esternamente
- Straining informatica
Deve essere visibile all'utente che primi 10 rischio elenco di Boehm non identifica immediatamente i rischi. Invece della tassonomia semplicemente fornisce un punto da cui iniziare pensando i rischi che riguardano il progetto software. Ad esempio comprende il rischio di primo, "shortfalls personale", sono molti diversi rischi possibili correlati a personale. Il progetto semplicemente potrebbe non disporre sufficiente tecnici per creare l'applicazione o sistema. Oppure un ingegnere chiave potrebbe lasciare a metà tra la pianificazione del progetto al progetto. O il personale di progettazione non dispone le competenze tecniche necessarie per il progetto. E così via.
La maggior parte delle categorie di rischio 10 superiore deve essere familiare, tranne per forse la dieci volte in cui rischio categoria "straining informatica". Questa è alquanto di una categoria tutti catch e vengono illustrate attività correlate a elementi quali analisi tecnica, analisi vantaggio di costi e alla creazione di prototipi.
Un altro elenco di tassonomia di frequente software rischio è stato creato da SEI (Software Engineering Institute). Il SEI è uno dei 36 federally funded ricerca e sviluppo centri negli Stati Uniti Queste aree di ricerca sono organizzazioni ibrido molto strano che funded da money pubblica ma vendono prodotti e servizi. La tassonomia di rischio SEI software è stata creata nel 1993 e costituito da circa 200 domande. Ad esempio, è la domanda 1, "sono i requisiti di stabilità? Se non, qual è l'effetto sul sistema (qualità, funzionalità di pianificazione, integrazione, progettazione, test)? " Domanda #16 è, "come determinare fattibilità di algoritmi e strutture (creazione di prototipi, di modellizzazione, analisi di simulazione,)?" È possibile trovare il Tassonomia dei rischi SEI in un'appendice al documento.
In base scenario software Identificazione dei rischi, immaginare manualmente nei ruoli diversi, creare scenari per i ruoli e identificare cosa Impossibile passare errato in ogni scenario. Utilizzando l'analogia di andata e ritorno aeroplano descritto in precedenza, si potrebbero analisi mentally i passaggi che si consegnare sul viaggio. Ad esempio "nome unità aeroporto. Quindi park mia auto. Successivamente, archivia nel contatore di volo." Questo processo scenario potrebbe visualizzare molti rischi, inclusi i ritardi del traffico a causa di costruzione di viaggio o di un caso gli parcheggio non disponibilità, l'ID di ogni e così via.
In un ambiente di progetto software, alcuni ruoli comuni utilizzati per l'identificazione dei rischi lo scenario, in base sono gli utenti, gli sviluppatori, tester, agenti di vendita, gli architetti software e i project manager. Uno scenario utente potrebbe essere lungo le linee di "innanzitutto, è possibile installare l'applicazione. Successivamente, è possibile avviare l'applicazione." In molti casi uno scenario di identificazione dei rischi esegue il mapping direttamente a un test case.
I ruoli di identificazione dei rischi lo scenario, in base non sono necessariamente gli utenti. Ruoli possono essere troppo moduli software o sottosistemi. Si supponga, ad esempio, di che avere un oggetto C# che esegue le operazioni di crittografia e decrittografia. Si può immaginare che l'oggetto è il ruolo e creare scenari ad esempio, "prima è possibile accettare l'input di alcune e creare un'istanza di uso personale. Successivamente è possibile accettare l'alcuni input ed passarla al metodo di crittografia. " È stata meno ricerca sull'identificazione rischio software lo scenario, in base sull'identificazione di base di tassonomia. La carta di ricerca trova Numero di modelli di rischio per i progetti software viene fornita una panoramica del campo buona e propone un approccio interessante teorico, in base allo schema di identificazione dei rischi.
Oltre a strategie di identificazione dei rischi in base a tassonomia e lo scenario, in base, un terzo approccio è una strategia di base specifica. In questo approccio è strettamente esaminare ciascuna funzionalità ed elaborare il prodotto o documenti specifiche di sistema e tentativo di identificare quali possono accedere errato. Utilizzando l'analogia di andata e ritorno aeroplani, si può esaminare attentamente un itinerario di viaggio dettagliate che è stato creato da un agente di viaggio. Si supponga che uno dei documenti specifica per un Web di applicazione per segnalare che si desidera utilizzare un consulente esterno per produrre i vari file della Guida per l'applicazione. Una relazione progetto esterno possibile assegnare adito a un lungo elenco di rischi. Cosa accade se il consulente non riesce a consegnare ora? Cosa accade se lavoro qualità il consulente non soddisfa il standard soggettivo?
Non è Nessuna strategia di identificazione dei rischi singolo, ottimale, ognuno ha e relativi vantaggi e svantaggi. Rischio tassonomie rivelano un eccellente per iniziare il processo di identificazione i rischi del progetto software. Consentono un piuttosto meccanico iniziare nel senso che si semplicemente Avvia analisi ogni commento della tassonomia o domanda. Tassonomie inoltre consentono distribuire il processo di identificazione dei rischi tra più utenti assegnando tassonomia diverse domande persone diverse. Sul lato negativo, utilizzando le tassonomie per Identificazione dei rischi può richiedere molto tempo. Inoltre, sono tassonomie, per loro natura, generico e in modo non possono identificare i rischi che sono specifici del sistema di software a meno che non si inserisce nello sforzo per rilevare questi rischi specifici.
Un vantaggio di un approccio basato scenario rispetto a Identificazione dei rischi in base tassonomia, è che tende a essere meno generico e si impone dall'inizio da più definita. Invece, identificazione dei rischi in base lo scenario è leggermente più immagini a scienza e si può perdere facilmente uno scenario di chiave. Identificazione dei rischi di base specifica in genere rappresenta l'approccio meno generico, più specifico. Tuttavia, un approccio basato specifica verrà risultare solo valida come il documento di specifica. Se utilizzato insieme, tre approcci consentono una buona possibilità di identificare con precisione i rischi del software.
Analisi dei rischi
Analisi dei rischi sono il processo di combinazione la probabilità o probabilità di un evento di rischio con perdite di valuta (o effetti negativi) che si verifica se l'evento si verifica, per produrre un valore che può essere utilizzato per confrontare e assegnare la priorità del rischio e altri i rischi. In questa sezione, è possibile rendere disponibili due approcci precedente all'analisi dei rischi (la tecnica di valore previsto e la tecnica di categorie) e un nuovo approccio denominato rischio e PERICOLO. Esaminiamo la tecnica di valore previsto prima.
Osservare l'esempio riportato nella Figura 5 . Si supponga di che aver identificato quattro eventi di rischio. Si chiamarli dei rischi A, B dei rischi, dei rischi C e d dei rischi È necessario assegnare probabilità a ogni evento di rischio. Probabilità è un numero compreso tra 0 (ovvero Impossibile) e 1,00 (certezza significato) che indica come probabile che l'evento è. Successivamente, si assegna un valore monetario perdite a ogni evento di rischio, che rappresenta il costo per l'utente se si verifica l'evento di rischio. A questo punto per ogni evento di rischio è semplicemente moltiplicare probabilità del rischio e la perdita del rischio per ottenere l'esposizione al rischio.
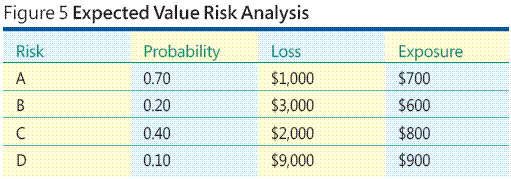
Utilizzare questo metodo, esposizione al rischio è solo una di valore previsto. Naturalmente, ci sono diversi problemi principali con l'approccio valore previsto. Come è possibile stimare le probabilità di rischio Come è possibile prevedere una perdita di rischio In alcune situazioni potrebbe Disponi buona dati cronologici o esperienza di base le stime al momento, ma è in genere una situazione rara durante la creazione di software. Base mia esperienza, l'approccio di valore previsto per l'analisi dei rischi spesso non è fattibile in un ambiente di sviluppo software.
Poiché è difficile o impossibile anche in molti ambienti di sviluppo software per stimare la probabilità di un evento di rischio o la perdita associato, un'alternativa più comune consiste nell'utilizzare categorie Scale per probabilità di rischio e il rischio perdite. Si tratta della tecnica categorie. Un esempio verrà creata l'idea deselezionare. Si supponga di che aver identificato quattro dei rischi, A, B, C e d. Ora invece di indovinare la probabilità e una perdita di ogni rischio, è necessario generare una tabella di esposizione di categorie di rischio come quello illustrato nella parte superiore della figura 6 .
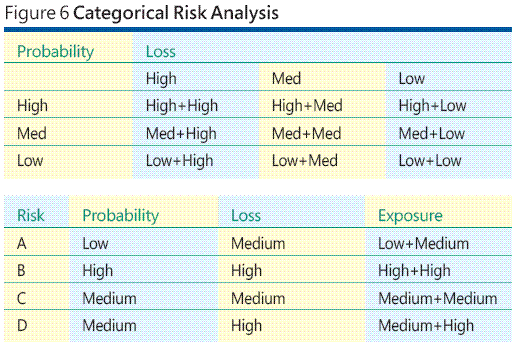
Come può notare, si dispone di un totale di nove categorie di esposizione al rischio. Sono disponibili tre categorie della probabilità di rischio, basso, medio e alto. Sono disponibili tre categorie di perdita, anche basso, medio e alto. Il prodotto tra di categoria di probabilità e perdita categoria produce nove categorie di esposizione dei rischi, da a bassa basso (bassa probabilità di una perdita bassa) tramite elevato, Elevato (alta probabilità perdita elevato di. Ora È possibile esaminare ciascuno di eventi i rischio quattro, assegnare un basso, medio, o alta probabilità e quindi un basso, medio o elevata perdita, per ottenere un esposizione al rischio di nove punti. Il concetto è che è spesso più ragionevole assegnare un valore di probabilità di "Bassa" invece di un valore numerico esatto come 0,05 ad esempio.
I dati nella tabella nella parte inferiore della figura 6 ipotetici suggerisce che B dei rischi è l'esposizione più alto e potrebbe giustifica più attenzione o le risorse (compresi test) rispetto A, che ha l'esposizione più basso rischio. Sebbene un approccio di analisi di categorie di rischio semplifica alquanto il problema di assegnazione di difficile o impossibile determinare le probabilità e perdita di informazioni, la tecnica introduce nuovi problemi.
Si noti che utilizzano arbitrariamente tre categorie per probabilità e perdita. Questo è un approccio molto a punta spessa. Ma si supponga che decide di migliorare l'analisi dei rischi utilizzando cinque categorie per il fattore di probabilità e il fattore di perdita: Molto Bassa, Bassa, Medio, Alto e molto alta. A questo punto È necessario terminare fino con un totale di rischi 25 esposizione categorie —(Very Low + Very Low) tramite (molto alta + molto alta). Come si è possibile classificare o confrontare questi valori di esposizione 25? Solo come un (molto bassa + alta) rischio esposizione esposizione di confronto a una (alta + Media)? Se più utenti sono valutare i dati di esposizione di categorie di rischio, si sono interpretare gli esposizione dati nello stesso modo?
Per risolvere i problemi con un approccio di rischio esclusivamente l'analisi, diversi anni fa che HO sviluppato una tecnica viene chiamato esposizione di progetto utilizzando impatto ordinato e probabilità (rischio e PERICOLO). L'essenza dell'idea consiste nell'utilizzare le categorie (come nell'approccio al categorie) ma Converti in una scala quantitativo in modo che possono essere facilmente combinati (come nell'approccio al valore previsto) per produrre metriche esposizione numerico.
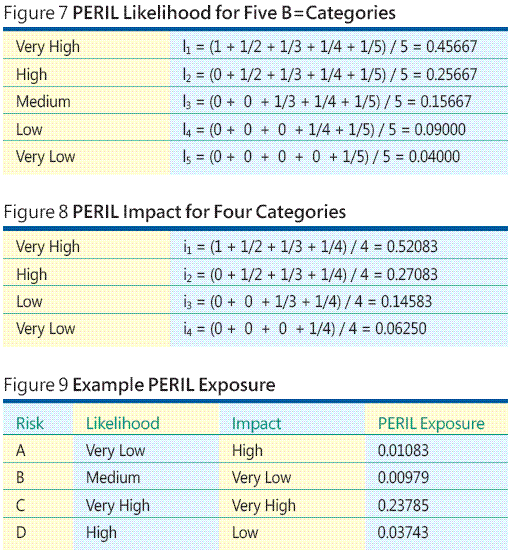
Consente di illustrare un esempio. Si supponga di aver identificato i rischi quattro: A, B, C e d. Si supponga che si decide che tentando di assegnare valori numerici significativo probabilità e perdita ogni rischio è ora ma non fattibile. Inoltre, si decide che in un ambiente particolare è opportuno per categorizzare la probabilità di rischio in cinque categorie: Molto Bassa, Bassa, Medio, Alto e molto alta. Successivamente, si determina che verrà classificare perdita/impatto su una scala a quattro punte: molto bassa, bassa, alta e molto alta. La tecnica di rischio e PERICOLO associa l'dati in una scala quantitativo utilizzando un costrutto di matematico semplice denominato centroids ordine di rango. La tecnica di mapping è meglio illustrata dall'esempio. Per la scala cinque categorie probabilità il mapping di centro dell'ordine di rango cinque sono illustrati nella Figura 7 .
Analogamente, il mapping di impatto quattro categorie vengono calcolati, come illustrato nella Figura 8 . Ora È possibile combinare probabilità di ogni rischio e valore di centro dell'impatto per calcolare esposizione il rischio tramite la moltiplicazione. Ad esempio, osservare nella figura 9 . Qui, dei rischi D dispone di alta probabilità, che associa a 0.25667, e di impatto minimo, che associa a 0.14583, pertanto l'esposizione è 0.25667 * 0.14583 = 0.03743. Da questi dati è possibile concludere il C rischio ha chiaramente l'esposizione più alto e apparirebbe in modi per evitare il rischio che si verifichino e creare un piano di emergenza se si verifica l'evento di rischio.
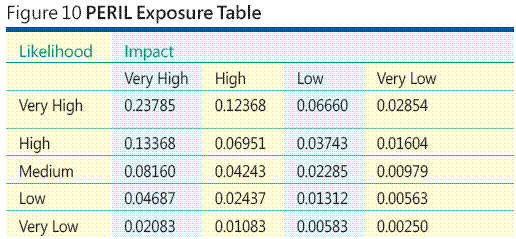
Invece di calcolo esposizione ogni rischio singolarmente, È possibile creare una tabella di ricerca esposizione rischio e PERICOLO completa per cinque livelli di probabilità e quattro livelli di impatto e quindi leggere semplicemente i valori di esposizione di rischio e PERICOLO dalla tabella, come illustrato nella Figura 10 . La tecnica di rischio e PERICOLO generalizes qualsiasi numero di categorie probabilità e impatto.
Classificazione ordine centroids mapping classi (ad esempio il primo, secondo, terzo) ai valori numerici (quali 0.61111 0.27778, 0.11111. Si noti che i valori del centro dell'ordine di rango vengono normalizzati in senso sommare e 1,0 (soggette a errori di arrotondamento). Espresso in notazione sigma, se N è il numero di categorie è il valore numerico corrispondente al k-esimo categoria:
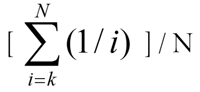
Esistono molti altri mapping matematico tra le categorie e i valori numerici, ma vi è qualche ricerca che suggerisce che utilizzo centroids ordine rango rappresenta un metodo molto migliore per mappare valutazioni delle quali quelli utilizzati nell'analisi dei rischi. Una descrizione completa di ordine di rango centroids rientra nell'ambito di questo articolo, ma si consiglia di questo argomento informale. Si supponga che si utilizzano solo due categorie di probabilità di evento di rischio: alta e bassa. Probabilmente la probabilità di evento High-risk è la probabilità del corso è maggiore di 0,5 e pertanto la probabilità di rischio basso evento ha una probabilità di inferiori a 0,5. Senza ulteriori informazioni, si può presumere che la probabilità di evento elevato è a metà tra 0,5 1.0 e così uguale a 0,75. Nello stesso modo, la probabilità di evento minimo è tra 0.0 e 0,5 che è 0,25. Questi due valori, con spessore di 0,75 e 0,25, sono centroids ordine di rango per N = 2 categorie (come illustrato nella Figura 11 ).
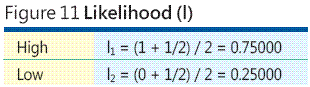
Si noti che quando si utilizza il rischio e PERICOLO, è possibile utilizzare la probabilità che i termini e impatto anziché probabilità e perdita. Probabilità di rischio e PERICOLO e impatto sono relativi, normalizzare i valori. Anche se i valori di probabilità di rischio e PERICOLO sommare e 1 come un insieme di probabilità, consente di sottolineare che i valori di probabilità di rischio e PERICOLO non sono le probabilità. Analogamente, i valori di impatto del rischio e PERICOLO hanno un significato solo quando confrontati tra loro e non sono valori monetari perdita.
Le tre tecniche per determinare l'esposizione al rischio, ovvero la tecnica di valore previsto, la tecnica di categorie e la tecnica di rischio e PERICOLO, punti di forza e punti deboli. Se i dati cronologici a tinta unita che consente di stimare le probabilità di rischio eventi e la perdita di valuta associato a ogni evento, quindi la tecnica di valore previsto è in genere l'approccio migliore. Tuttavia in un sviluppo di software e l'ambiente di prova raramente necessario dati sufficienti per creare stime probabilità e perdita significative.
In invece se praticamente senza dati cronologici rischio, quindi la tecnica di categorie, con due o tre categorie di probabilità di rischio e la perdita dei rischi associati, è un approccio ragionevole. In situazioni in cui si è in grado di suddividere probabilità di evento di rischio e impatto dei rischi associati (che può essere monetario o non monetario perdita ad esempio morale effetto) in circa cinque categorie, quindi la tecnica di rischio e PERICOLO è spesso una scelta ottima.
Indipendentemente delle tecniche di analisi dei rischi si decide di utilizzare nell'ambiente, è necessario richiedere attenzione per interpretare i risultati prudentemente. Tenere presente che quasi sempre il rischio di analisi ha grandi quantità di variabilità nelle stime di input. In altre parole, analisi dei rischi fornisce linee guida, non regole, per assegnare le priorità le iniziative di test del software.
Risorse di rischio
Per ulteriori informazioni sul rischio, vedere le MSDN Magazine (informazioni in lingua inglese) colonne:
| " Esecuzione dei test: analisi competitiva Utilizzo MAGIQ" |
| " Esecuzione dei test: il processo gerarchia di analisi" |
Disposizione dei
Una parte del processo di analisi dei rischi generale che non discusso in questa colonna è la gestione dei rischi. Gestione dei rischi comporta attività quali la creazione di un sistema di immissione e l'archiviazione dei dati dei rischi più informazioni di rischio nel tempo durante l'avanzamento del progetto software di monitoraggio. Sistemi di gestione dei rischi possono variare da un sistema informale di base di posta elettronica, tramite un approccio leggero basato su fogli di calcolo di Excel, fino a un approccio sofisticato basata sull'utilizzo dei rischi elementi in un sistema di Microsoft Team Foundation Server.
È importante comprendere che l'analisi dei rischi devono essere un processo iterativo, in corso, indipendentemente dal modo in cui si desidera gestire il lavoro rischio. Poiché lo sviluppo del progetto software è un'attività dinamica, è necessario modificare i dati di rischio e si evolve i risultati come il progetto.
Buon senso suggerisce che analisi dei rischi software devono far parte di tutti i progetti software. I progetti da piccoli, uno sviluppatore, una settimana sforzi fino a progetti di grandi dimensioni, anni con centinaia o addirittura migliaia di sviluppatori devono avere qualche forma di analisi dei rischi. Tuttavia, è piuttosto un po'di ricerche di sondaggio che mostra che le analisi dei rischi spesso non vengono eseguite, soprattutto nei progetti software medie e piccole dimensioni.
Esistono più probabile spiegazioni. Ritiene che un motivo rischio analisi vengono eseguite raramente richiedono tecniche e aptitudes che sono quasi opposto le competenze e aptitudes necessarie per la codifica. Consente di descrivere. Sviluppo software la maggior parte delle attività sono relativamente ben definite in base a un sistema a chiuso, sono orientati a scopo di Microsoft e in genere fornire un feedback immediato. Ad esempio, quando si scrive codice come sviluppatore, è possibile ottenere commenti immediati quando si compila e quindi esegue il codice. Se il codice viene eseguito come previsto, si ottiene in genere una certa quantità di soddisfazione. Esecuzione dell'analisi dei rischi software è un molto tipo diverso di attività. Non si ottiene uno dei tipi di commenti e suggerimenti o soddisfazione che abituali per il recupero.
Il punto è che analisi dei rischi software sono molto diverso dal codice. Questa colonna è probabilmente possibile è l'importanza di esecuzione dell'analisi dei rischi e illustrate alcune tecniche brillante per creare software migliori e più affidabili.
Inviare domande e commenti per John a testrun@Microsoft.com.
Dr. James McCaffrey funziona per Volt Information Sciences, Inc., in cui che gestisce la formazione tecnica per ingegneri software di utilizzo di Microsoft in Redmond, Washington. Egli ha lavorato su diversi prodotti Microsoft, tra cui Internet Explorer e MSN Search ed è l'autrice di .NET Test Automation: A Problem-Solution Approach (Apress, 2006). John è possibile contattarlo all' jmccaffrey@volt.com o v-jammc@microsoft.com.