Gestione degli errori temporanei (compilazione di app cloud Real-World con Azure)
Scaricare correzione del progetto o scaricare E-book
L'e-book Building Real World Cloud Apps with Azure è basato su una presentazione sviluppata da Scott Guthrie. Spiega 13 modelli e procedure che consentono di sviluppare app Web per il cloud con successo. Per informazioni sul e-book, vedere il primo capitolo.
Quando si progetta un'app cloud reale, una delle cose che si deve pensare è come gestire le interruzioni temporanee del servizio. Questo problema è importante in modo univoco nelle app cloud perché è così dipendente dalle connessioni di rete e dai servizi esterni. Spesso si possono ottenere piccoli glitch che in genere sono auto-guarigione, e se non si è preparati a gestirli in modo intelligente, si otterrà un'esperienza non valida per i clienti.
Cause di errori temporanei
Nell'ambiente cloud si troverà che non è riuscito e eliminato connessioni alle banche dati si verifica periodicamente. Ciò è in parte dovuto al fatto che si passa attraverso più servizi di bilanciamento del carico rispetto all'ambiente locale in cui il server Web e il server di database hanno una connessione fisica diretta. Inoltre, a volte quando si dipende da un servizio multi-tenant, si noteranno chiamate al servizio più lente o timeout perché un altro utente che usa il servizio lo colpisce pesantemente. In altri casi si potrebbe essere l'utente che sta raggiungendo il servizio troppo frequentemente e il servizio limita intenzionalmente le connessioni – nega le connessioni – per impedire di influire negativamente su altri tenant del servizio.
Usare la logica di ripetizione/back-off intelligente per attenuare l'effetto degli errori temporanei
Anziché generare un'eccezione e visualizzare una pagina non disponibile o di errore al cliente, è possibile riconoscere gli errori che sono in genere temporanei e riprovare automaticamente l'operazione che ha generato l'errore, sperando che prima di molto si riuscirà. La maggior parte del momento in cui l'operazione avrà esito positivo al secondo tentativo e si eseguirà il ripristino dall'errore senza che il cliente abbia mai rilevato che si è verificato un problema.
Esistono diversi modi per implementare la logica di ripetizione dei tentativi intelligenti.
Il gruppo Microsoft Patterns & Practices ha un blocco di applicazioni di gestione degli errori temporanei che esegue tutto se si usa ADO.NET per l'accesso database SQL (non tramite Entity Framework). È sufficiente impostare un criterio per i tentativi, ovvero quante volte ripetere una query o un comando e il tempo di attesa tra tentativi e eseguire il wrapping del codice SQL in un blocco using .
public void HandleTransients() { var connStr = "some database"; var _policy = RetryPolicy.Create < SqlAzureTransientErrorDetectionStrategy( retryCount: 3, retryInterval: TimeSpan.FromSeconds(5)); using (var conn = new ReliableSqlConnection(connStr, _policy)) { // Do SQL stuff here. } }TFH supporta anche Cache e bus di servizio di Azure In-Role.
Quando si usa Entity Framework in genere non si lavora direttamente con le connessioni SQL, quindi non è possibile usare questo pacchetto Modelli e procedure, ma Entity Framework 6 compila questo tipo di logica di ripetizione dei tentativi nel framework. In modo analogo si specifica la strategia di ripetizione dei tentativi e quindi EF usa tale strategia ogni volta che accede al database.
Per usare questa funzionalità nell'app Correzione it, è necessario aggiungere una classe che deriva da DbConfiguration e attivare la logica di ripetizione dei tentativi.
// EF follows a Code based Configuration model and will look for a class that // derives from DbConfiguration for executing any Connection Resiliency strategies public class EFConfiguration : DbConfiguration { public EFConfiguration() { AddExecutionStrategy(() => new SqlAzureExecutionStrategy()); } }Per database SQL eccezioni identificate dal framework come errori in genere temporanei, il codice illustrato indica a EF di ripetere l'operazione fino a 3 volte, con un ritardo di back-off esponenziale tra i tentativi e un ritardo massimo di 5 secondi. Il back-off esponenziale significa che dopo ogni tentativo non riuscito attende un periodo di tempo più lungo prima di riprovare. Se tre tentativi in una riga non riescono, genererà un'eccezione. Nella sezione seguente vengono illustrati i motivi per cui si vuole eseguire il back-off esponenziale e un numero limitato di tentativi.
È possibile avere problemi simili quando si usa il servizio di archiviazione di Azure, come l'app Correzione it fa per BLOB e l'API client di archiviazione .NET implementa già lo stesso tipo di logica. È sufficiente specificare i criteri di ripetizione dei tentativi oppure non è nemmeno necessario farlo se si è soddisfatti delle impostazioni predefinite.
Interruttori
Esistono diversi motivi per cui non si vuole riprovare troppo volte in un periodo troppo lungo:
- Troppi utenti che riprovano in modo permanente le richieste non riuscite potrebbero compromettere l'esperienza degli altri utenti. Se milioni di persone fanno tutte richieste ripetute di ripetizione dei tentativi, è possibile legare le code di invio IIS e impedire all'app di eseguire richieste di manutenzione che altrimenti potrebbero gestire correttamente.
- Se tutti i tentativi vengono rieseguiti a causa di un errore del servizio, potrebbe verificarsi un numero elevato di richieste accodate che il servizio viene inondato all'avvio del ripristino.
- Se l'errore è dovuto alla limitazione della limitazione e si verifica un intervallo di tempo usato dal servizio per la limitazione, i tentativi continui potrebbero spostare tale finestra e causare la limitazione della limitazione.
- Potrebbe essere disponibile un utente in attesa del rendering di una pagina Web. Rendendo le persone in attesa troppo lungo potrebbe essere più fastidioso che relativamente rapidamente consiglia loro di riprovare più tardi.
Il back-off esponenziale risolve alcuni di questi problemi limitando la frequenza dei tentativi che un servizio può ottenere dall'applicazione. Ma è anche necessario avere i breaker del circuito: questo significa che in una determinata soglia di ripetizione dei tentativi l'app si arresta e si esegue un'altra azione, ad esempio una delle seguenti:
- Fallback personalizzato. Se non puoi ottenere un prezzo azionario da Reuters, forse puoi ottenerlo da Bloomberg; o se non è possibile ottenere dati dal database, è possibile ottenerli dalla cache.
- Errore invisibile all'utente. Se ciò che è necessario da un servizio non è tutto o niente per l'app, restituire null quando non è possibile ottenere i dati. Se si visualizza un'attività Correzione it e il servizio BLOB non risponde, è possibile visualizzare i dettagli dell'attività senza l'immagine.
- Non riuscire rapidamente. Errore nell'utente per evitare di inondare il servizio con richieste di ripetizione dei tentativi che potrebbero causare interruzioni del servizio per altri utenti o estendere una finestra di limitazione. È possibile visualizzare un messaggio descrittivo "riprovare più avanti".
Non esiste alcun criterio di ripetizione dei tentativi di una dimensione singola. È possibile riprovare più volte e attendere più tempo in un processo di lavoro in background asincrono rispetto a un'app Web sincrona in cui un utente sta aspettando una risposta. È possibile attendere più tempo tra tentativi per un servizio di database relazionale che per un servizio cache. Ecco alcuni criteri consigliati di ripetizione dei tentativi consigliati per fornire un'idea del modo in cui i numeri potrebbero variare. ("Fast First" significa nessun ritardo prima del primo tentativo.
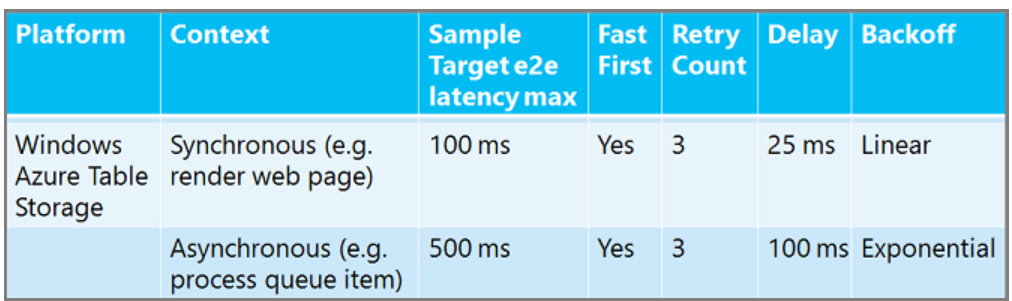
Per database SQL linee guida sui criteri di ripetizione dei tentativi, vedere Risolvere gli errori temporanei e gli errori di connessione per database SQL.
Riepilogo
Una strategia di ripetizione/back-off può aiutare a rendere invisibili gli errori temporanei al cliente al massimo del tempo e Microsoft fornisce framework che è possibile usare per ridurre al minimo il lavoro implementando una strategia se si usa ADO.NET, Entity Framework o il servizio di archiviazione di Azure.
Nel capitolo successivo si esaminerà come migliorare le prestazioni e l'affidabilità usando la memorizzazione nella cache distribuita.
Risorse
Per altre informazioni, vedere le risorse seguenti:
Documentazione
- Procedure consigliate per la progettazione di servizi di Large-Scale in Azure Servizi cloud. White paper di Mark Simms e Michael Thomassy. Analogamente alla serie Failsafe, ma si esaminano più dettagli. Vedere la sezione Telemetria e Diagnostica.
- Failsafe: linee guida per architetture cloud resilienti. White paper di Marc Mercuri, Andreas Homann e Andrew Townhill. Versione della pagina Web della serie video FailSafe.
- Modelli e procedure Microsoft - Linee guida di Azure. Vedere Modello di ripetizione dei tentativi, Modello di supervisore dell'agente di pianificazione.
- Entity Framework - Resilienza di connessione/Logica di ripetizione dei tentativi. Come usare e personalizzare la funzionalità di gestione degli errori temporanei di Entity Framework 6.
- Resilienza della connessione e intercettazione dei comandi con Entity Framework in un'applicazione MVC ASP.NET. Quarto in una serie di esercitazioni in nove parti, illustra come configurare la funzionalità di resilienza della connessione EF 6 per database SQL.
Video
- FailSafe: creazione di Servizi cloud scalabili e resilienti. Serie da nove parti di Hart Homann, Marc Mercuri e Mark Simms. Presenta concetti e principi architettonici di alto livello in modo molto accessibile e interessante, con storie disegnate da Microsoft Customer Advisory Team (CAT) con clienti effettivi. Vedere la discussione dei breaker di circuito nell'episodio 3 a partire dalle 40:55.
- Creazione di big: lezioni apprese dai clienti di Azure - Parte II. Mark Simms parla di progettazione per errori, gestione degli errori temporanei e strumentazione di tutto.
Esempio di codice
- Nozioni fondamentali sul servizio cloud in Azure. Applicazione di esempio creata dal team di consulenza clienti di Microsoft Azure che illustra come usare il blocco di gestione degli errori temporanei della libreria enterprise (TFH). Per altre informazioni, vedere l'articolo sul livello di accesso ai dati di Cloud Service Fundamentals e la gestione degli errori temporanei. TFH è consigliato per l'accesso al database usando ADO.NET direttamente (senza usare Entity Framework).
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per