Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo descrive le procedure consigliate per ottimizzare SQL Server e migliorare le prestazioni nelle macchine virtuali dell'hub di Azure Stack. Quando si esegue SQL Server nelle macchine virtuali dell'hub di Azure Stack, è possibile usare le stesse opzioni di ottimizzazione delle prestazioni del database applicabili a SQL Server in un ambiente server locale. Le prestazioni di un database relazionale in un cloud dell'hub di Azure Stack dipendono da molti fattori, tra cui le dimensioni della famiglia di una macchina virtuale e la configurazione dei dischi dati.
Quando si creano immagini di SQL Server, valuta la possibilità di effettuare il provisioning delle macchine virtuali nel portale Azure Stack Hub. Scaricare l'estensione SQL IaaS dalla gestione del Marketplace nel portale di amministrazione dell'hub di Azure Stack e scaricare le immagini di macchine virtuali di SQL Server desiderate. Queste immagini includono SQL Server 2016 SP1, SQL Server 2016 SP2 e SQL Server 2017.
Nota
Anche se l'articolo descrive come effettuare il provisioning di una macchina virtuale di SQL Server usando il portale di Azure globale, le indicazioni si applicano anche all'hub di Azure Stack con le differenze seguenti: SSD non è disponibile per il disco del sistema operativo e esistono differenze minime nella configurazione dell'archiviazione.
Nelle immagini di macchine virtuali, per SQL Server è possibile usare soltanto la formula bring-your-own-license (BYOL). Per Windows Server, il modello di licenza predefinito è con pagamento in base al consumo (PAYG). Per informazioni dettagliate sul modello di licenza di Windows Server nella macchina virtuale, vedere le domande frequenti Windows Server in Azure Stack Hub Marketplace.
Ottenere prestazioni ottimali per SQL Server nelle macchine virtuali dell'hub di Azure Stack è l'obiettivo di questo articolo. Se il carico di lavoro è contenuto, potrebbero non essere necessarie tutte le ottimizzazioni elencate di seguito. Prendere in considerazione le esigenze di prestazioni e i modelli di carico di lavoro durante la valutazione di queste indicazioni.
Nota
Per indicazioni sulle prestazioni per SQL Server nelle macchine virtuali di Azure, vedere queste linee guida.
Elenco di controllo per le procedure consigliate per SQL Server
L'elenco di controllo seguente consente di ottenere prestazioni ottimali di SQL Server nelle macchine virtuali dell'hub di Azure Stack:
| Area | Ottimizzazioni |
|---|---|
| Dimensioni della VM |
DS3 o versione successiva per SQL Server Enterprise Edition. DS2 o versione successiva per SQL Server Standard Edition e Web Edition. |
| Archiviazione | Usare una famiglia di macchine virtuali che supporta lo Storage Premium. |
| Dischi | Usare almeno due dischi dati (uno per i file di log e uno per il file di dati e TempDB) e scegliere le dimensioni del disco in base alle esigenze di capacità. Impostare i percorsi predefiniti dei file di dati su questi dischi durante l'installazione di SQL Server. Evitare l'uso del sistema operativo o di dischi temporanei per la registrazione o l'archiviazione di database. Eseguire lo striping di più dischi dati di Azure per ottenere un maggiore throughput di I/O usando Spazi di Archiviazione. Formattare utilizzando dimensioni di allocazione documentate. |
| I/O | Abilitare l'inizializzazione immediata dei file di dati. Limitare l'aumento automatico dei database con incrementi fissi ragionevolmente ridotti (64-256 MB). Disabilitare la compattazione automatica nel database. Configurare i percorsi predefiniti dei file di backup e di database nei dischi dati, non nel disco del sistema operativo. Abilitare le pagine bloccate. Applicare i Service Pack di SQL Server e gli aggiornamenti cumulativi. |
| Specifico per funzionalità | Eseguire il backup direttamente nell'archivio BLOB (se supportato dalla versione di SQL Server in uso). |
Per altre informazioni su come e perché apportare queste ottimizzazioni, vedere i dettagli e le indicazioni fornite nelle sezioni seguenti.
Linee guida per le dimensioni delle VM
Per le applicazioni sensibili alle prestazioni, sono consigliate le dimensioni delle macchine virtuali seguenti:
- SQL Server Enterprise Edition: DS3 o versione successiva.
- SQL Server edizione Standard e edizione Web: DS2 o superiore.
Con l'hub di Azure Stack, non esiste alcuna differenza di prestazioni tra la serie DS e la famiglia di macchine virtuali DS_v2.
Linee guida per l'archiviazione
Le macchine virtuali serie DS (insieme alle macchine virtuali serie DSv2) nell'hub di Azure Stack offrono la velocità effettiva massima del disco del sistema operativo e del disco dati (IOPS). Una macchina virtuale della serie DS o DSv2 offre fino a 1.000 operazioni di I/O al secondo per il disco del sistema operativo e fino a 2.300 operazioni di I/O al secondo per ogni disco dati, indipendentemente dal tipo o dalle dimensioni del disco scelto.
La velocità effettiva del disco dati viene determinata in modo univoco in base alla serie della famiglia di macchine virtuali. Vedere dimensioni delle macchine virtuali supportate nell'hub di Azure Stack per identificare la velocità effettiva del disco dati per ogni serie di famiglie di macchine virtuali.
Nota
Per i carichi di lavoro di produzione, selezionare una macchina virtuale serie DS o serie DSv2 per fornire il massimo numero possibile di operazioni di I/O al secondo nel disco del sistema operativo e nei dischi dati.
Quando si crea un account di archiviazione nell'hub di Azure Stack, l'opzione di replica geografica non ha alcun effetto, perché questa funzionalità non è disponibile nell'hub di Azure Stack.
Linee guida per i dischi
Esistono tre tipi di disco principali in una macchina virtuale dell'hub di Azure Stack:
- disco del sistema operativo: quando si crea una macchina virtuale di Azure Stack Hub, la piattaforma collega almeno un disco (etichettato come unità C) alla macchina virtuale per il disco del sistema operativo. Questo disco è un VHD memorizzato come BLOB di pagine nello storage.
- disco temporaneo: le macchine virtuali dell'hub di Azure Stack contengono un altro disco denominato disco temporaneo (etichettato come unità D). Si tratta di un disco nel nodo che è possibile usare per lo spazio scratch.
- dischi dati: è possibile collegare dischi aggiuntivi alla macchina virtuale come dischi dati e questi dischi vengono archiviati come BLOB di pagine.
Nelle sezioni seguenti sono riportati alcuni consigli per l'uso di questi diversi dischi.
Disco del sistema operativo
Per disco del sistema operativo si intende un disco rigido virtuale che è possibile avviare e montare come versione in esecuzione di un sistema operativo ed è etichettato come unità C .
Disco temporaneo
L'unità di archiviazione temporanea, etichettata come unità D , non è persistente. Non archiviare dati che non vorresti perdere nell'unità D. Sono inclusi i file di database utente e i file di log delle transazioni utente.
È consigliabile archiviare TempDB in un disco dati perché ogni disco dati offre un massimo di 2.300 operazioni di I/O al secondo per ogni disco dati.
Dischi dati
- Usare dischi dati per i file di dati e di log. Se non si usa lo striping del disco, usare due dischi dati di una macchina virtuale che supporta l'archiviazione Premium, in cui un disco contiene i file di log e l'altro contiene i dati e i file TempDB. Ogni disco dati offre un numero di operazioni di I/O al secondo a seconda della famiglia di macchine virtuali, come descritto in Dimensioni delle macchine virtuali supportate nell'hub di Azure Stack. Se si usa una tecnica di striping dei dischi, ad esempio Spazi di Archiviazione, inserire tutti i file di dati e di log nella stessa unità (incluso il TempDB). Questa configurazione offre il numero massimo di operazioni di I/O al secondo disponibili per l'utilizzo di SQL Server, indipendentemente dal file necessario in un determinato momento.
Nota
Quando si esegue il provisioning di una VM SQL Server nel portale, è possibile modificare la configurazione di archiviazione. A seconda della configurazione, l'hub di Azure Stack configura uno o più dischi. Più dischi vengono combinati in un singolo pool di archiviazione. Entrambi i file di dati e di log risiedono insieme in questa configurazione.
striping del disco: per una maggiore velocità effettiva, è possibile aggiungere altri dischi dati e usare lo striping del disco. Per determinare il numero di dischi dati necessari, analizzare il numero di operazioni di I/O al secondo necessarie per i file di log e per i file di dati e TempDB. Si noti che i limiti delle operazioni di I/O al secondo sono per disco dati in base alla famiglia di serie di macchine virtuali e non in base alle dimensioni della macchina virtuale. I limiti della larghezza di banda di rete, tuttavia, sono basati sulle dimensioni della macchina virtuale. Per altri dettagli, vedere le tabelle sulle dimensioni delle macchine virtuali nell'hub di Azure Stack. Attenersi alle linee guida seguenti:
Per Windows Server 2012 o versione successiva, usare Spazi di archiviazione con le linee guida seguenti:
Impostare l'interleave (dimensione di striping) su 64 KB (65.536 byte) per carichi di lavoro OLTP (Online Transaction Processing) e 256 KB (262.144 byte) per i carichi di lavoro di data warehousing per evitare un impatto sulle prestazioni a causa di un errore di partizione. Questo valore deve essere impostato con PowerShell.
Impostare il numero di colonne sul numero di dischi fisici. Usare PowerShell quando si configurano più di otto dischi (non l'interfaccia utente di Server Manager). Ad esempio, il comando di PowerShell seguente crea un nuovo pool di archiviazione con dimensioni interleave impostate su 64 KB e il numero di colonne su 2:
$PoolCount = Get-PhysicalDisk -CanPool $True $PhysicalDisks = Get-PhysicalDisk | Where-Object {$_.FriendlyName -like "*2" -or $_.FriendlyName -like "*3"} New-StoragePool -FriendlyName "DataFiles" -StorageSubsystemFriendlyName "Storage Spaces*" -PhysicalDisks $PhysicalDisks | New-VirtualDisk -FriendlyName "DataFiles" -Interleave 65536 -NumberOfColumns 2 -ResiliencySettingName simple -UseMaximumSize |Initialize-Disk -PartitionStyle GPT -PassThru |New-Partition -AssignDriveLetter -UseMaximumSize |Format-Volume -FileSystem NTFS -NewFileSystemLabel "DataDisks" -AllocationUnitSize 65536 -Confirm:$false
Determinare il numero di dischi associati al pool di archiviazione dell'utente in base alle aspettative di carico. Tenere presente che le diverse dimensioni di macchine virtuali consentono diversi numeri di dischi dati associati. Per altre informazioni, vedere Dimensioni delle macchine virtuali supportate nell'hub di Azure Stack.
Per ottenere il numero massimo possibile di operazioni di I/O al secondo per i dischi dati, è consigliato aggiungere il massimo numero di dischi dati supportato dalle dimensioni del VM e utilizzare lo striping del disco.
dimensione dell'unità di allocazione NTFS: quando si formatta il disco dati, è consigliabile usare una dimensione di unità di allocazione di 64 KB per i file di dati e di log, nonché TempDB.
Procedure di gestione del disco: quando si rimuove un disco dati, arrestare il servizio SQL Server durante la modifica. Inoltre, non modificare le impostazioni della cache nei dischi perché non offre miglioramenti delle prestazioni.
Avviso
La mancata interruzione del servizio SQL durante queste operazioni può causare il danneggiamento del database.
Linee guida per l'I/O
È possibile abilitare l'inizializzazione immediata dei file per ridurre il tempo necessario per l'allocazione iniziale dei file. Per sfruttare i vantaggi dell'inizializzazione immediata dei file, concedere al servizio SQL Server (MSSQLSERVER) il privilegio SE_MANAGE_VOLUME_NAME e aggiungerlo ai criteri di sicurezza per le attività di manutenzione del volume. Se si usa un'immagine della piattaforma SQL Server per Azure, l'account del servizio predefinito (NT Service\MSSQLSERVER) non viene aggiunto alla politica di sicurezza Eseguire attività di manutenzione del volume. In altre parole, l'inizializzazione immediata dei file non è abilitata in un'immagine della piattaforma SQL Server Azure. Dopo aver aggiunto l'account del servizio SQL Server ai criteri di sicurezza Esecuzione attività di manutenzione volume, riavviare il servizio del SQL Server. Quando si usa questa funzionalità, potrebbero essere presenti considerazioni sulla sicurezza. Per ulteriori informazioni, vedere inizializzazione dei file di database.
Autocrescita è un'opzione per una crescita imprevista. Non gestire i dati e la crescita dei log su base giornaliera con aumento automatico. Se si usa l'aumento automatico, aumentare in modo preliminare il file usando l'opzione dimensioni.
Assicurarsi che compattazione automatica sia disabilitata per evitare un sovraccarico non necessario che influisca negativamente sulle prestazioni.
Configurare i percorsi predefiniti dei file di backup e di database. Usare le raccomandazioni contenute in questo articolo e apportare le modifiche nella finestra Proprietà server. Per istruzioni, vedere Visualizzare o modificare i percorsi predefiniti per i file di dati e di log. Lo screenshot seguente mostra dove apportare queste modifiche:
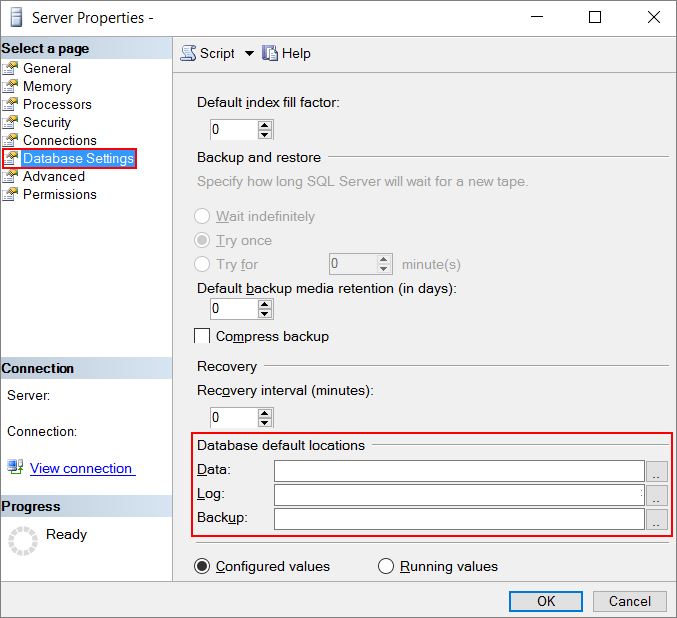
Attivare le pagine bloccate per ridurre le operazioni di I/O e le attività di paging. Per ulteriori informazioni, vedere l'opzione Abilita il blocco delle pagine in memoria.
È consigliabile comprimere tutti i file di dati quando si trasferisce l'hub di Azure Stack, inclusi i backup.
Guida specifica delle funzionalità
Alcune distribuzioni possono ottenere vantaggi in termini di prestazioni usando tecniche di configurazione più avanzate. L'elenco seguente evidenzia alcune funzionalità di SQL Server che consentono di ottenere prestazioni migliori:
Eseguire il backup nell'archiviazionedi Azure. Quando si eseguono backup per SQL Server in esecuzione nelle macchine virtuali dell'Azure Stack Hub, è possibile usare SQL Server Backup su URL. Questa funzionalità è disponibile a partire da SQL Server 2012 SP1 CU2 ed è consigliata per il backup su dischi dati associati.
Quando si esegue il backup o il ripristino utilizzando l'archiviazione di Azure, seguire le raccomandazioni fornite nelle procedure consigliate e risoluzione dei problemi per il backup di SQL Server su URL di e nel ripristino da backup archiviati in Microsoft Azure. È anche possibile automatizzare questi backup usando backup automatico per SQL Server nelle macchine virtuali di Azure.
Eseguire il backup su Hub di Archiviazione Azure Stack. È possibile eseguire il backup nell'archiviazione di Azure Stack Hub in moda analoga al backup su archiviazione di Azure. Quando si crea un backup in SQL Server Management Studio (SSMS), è necessario immettere manualmente le informazioni di configurazione. Non è possibile usare SSMS per creare il contenitore di archiviazione o la firma di accesso condiviso. SSMS si connette solo alle sottoscrizioni di Azure, non alle sottoscrizioni dell'hub di Azure Stack. Creare invece l'account di archiviazione, il contenitore e la firma di accesso condiviso nel portale dell'hub di Azure Stack o con PowerShell.
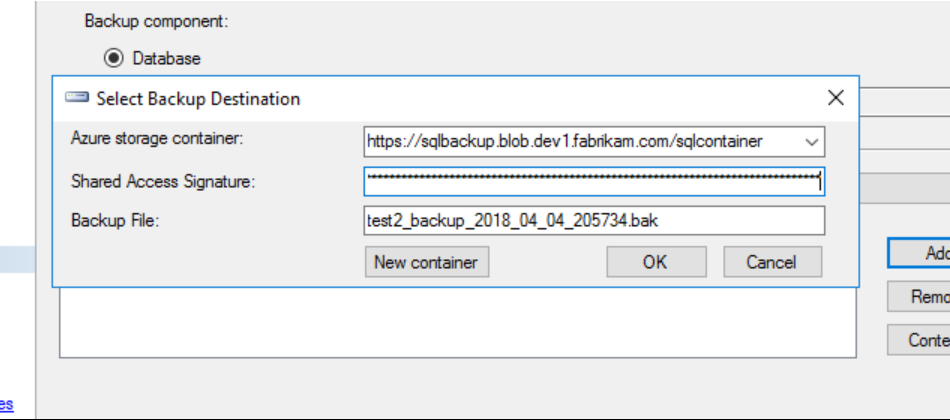
Nota
Il token SAS è il token di accesso condiviso dal portale Azure Stack Hub, senza il carattere "?" iniziale nella stringa. Se si usa la funzione di copia dal portale, eliminare il valore "?" iniziale per il funzionamento del token all'interno di SQL Server.
Dopo aver configurato e configurato la destinazione di backup in SQL Server, è possibile eseguire il backup nell'archivio BLOB dell'hub di Azure Stack.