Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Importante
Gli elementi contrassegnati (anteprima) in questo articolo sono attualmente disponibili in anteprima pubblica. Questa anteprima viene fornita senza un contratto di servizio e non è consigliabile per i carichi di lavoro di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
I modelli linguistici di grandi dimensioni (LLM) multimodali, che possono elaborare e interpretare diverse forme di input di dati, rappresentano uno strumento potente che può elevare significativamente le funzionalità dei sistemi incentrati esclusivamente sulla lingua. Tra i vari tipi di dati, le immagini sono importanti per molte applicazioni reali. L'incorporazione dei dati di immagine nei sistemi di intelligenza artificiale offre un livello essenziale di comprensione visiva.
In questo articolo, imparerai a:
- Come usare i dati delle immagini nel prompt flow
- Come usare lo strumento GPT-4V predefinito per analizzare gli input di immagine.
- Come creare un chatbot in grado di elaborare input di immagine e testo.
- Come creare un'esecuzione batch usando dati di immagine.
- Come usare l'endpoint online con i dati di immagine.
Tipo di immagine nel prompt flow
L'input e l'output del prompt flow supportano Image come nuovo tipo di dati.
Per usare i dati di immagine nella pagina di creazione del prompt flow:
Aggiungere un input del flusso, selezionare il tipo di dati come Immagine. È possibile caricare, trascinare e rilasciare un file di immagine, incollare un'immagine dagli Appunti o specificare un URL di immagine o il percorso relativo dell'immagine nella cartella del flusso.

Visualizzare in anteprima l'immagine. Se l'immagine non viene visualizzata correttamente, eliminare l'immagine e aggiungerla di nuovo.

È consigliabile pre-elaborare l'immagine usando lo strumento Python prima di aggiungerla al modello LLM. Ad esempio, è possibile ridimensionare o ritagliare l'immagine per ottenere dimensioni inferiori.
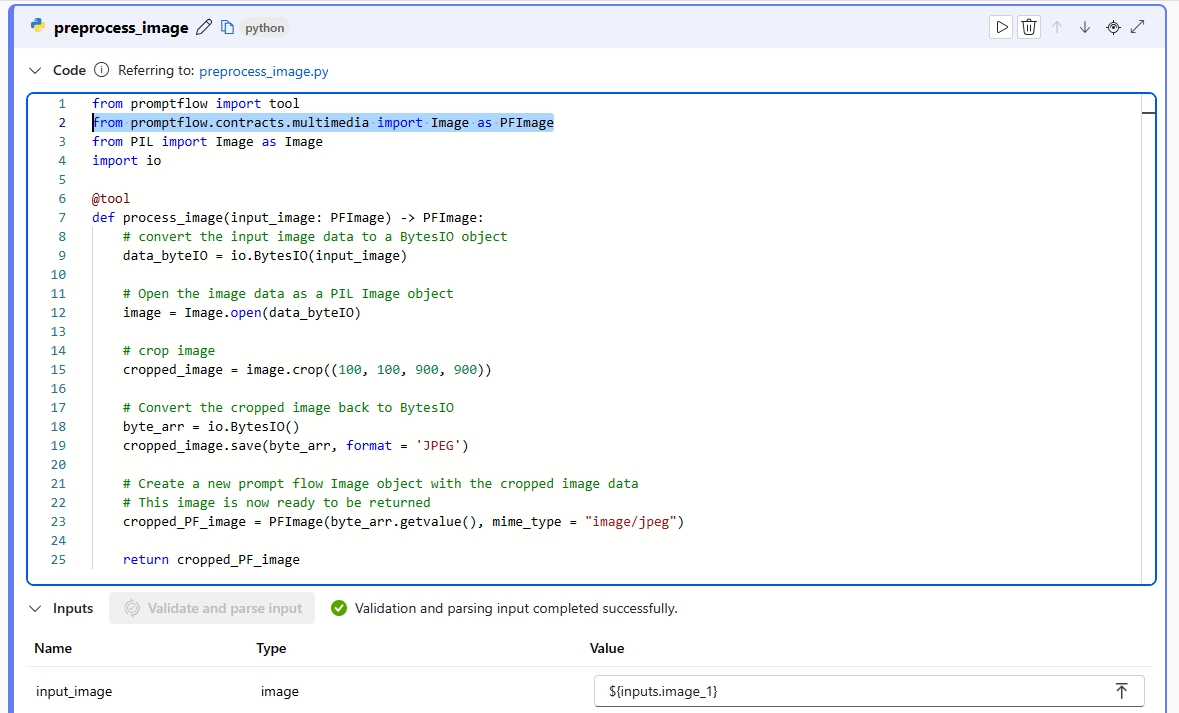
from promptflow import tool from promptflow.contracts.multimedia import Image as PFImage from PIL import Image as Image import io @tool def process_image(input_image: PFImage) -> PFImage: # convert the input image data to a BytesIO object data_byteIO = io.BytesIO(input_image) # Open the image data as a PIL Image object image = Image.open(data_byteIO) # crop image cropped_image = image.crop((100, 100, 900, 900)) # Convert the cropped image back to BytesIO byte_arr = io.BytesIO() cropped_image.save(byte_arr, format = 'JPEG') # Create a new prompt flow Image object with the cropped image data # This image is now ready to be returned cropped_PF_image = PFImage(byte_arr.getvalue(), mime_type = "image/jpeg") return cropped_PF_image ``` > [!IMPORTANT] > To process images using a Python function, you need to use the `Image` class that you import from the `promptflow.contracts.multimedia` package. The `Image` class is used to represent an `Image` type within prompt flow. It is designed to work with image data in byte format, which is convenient when you need to handle or manipulate the image data directly. > > To return the processed image data, you need to use the `Image` class to wrap the image data. Create an `Image` object by providing the image data in bytes and the [MIME type](https://developer.mozilla.org/docs/Web/HTTP/Basics_of_HTTP/MIME_types/Common_types) `mime_type`. The MIME type lets the system understand the format of the image data, or it can be `*` for unknown type.Eseguire il nodo Python e controllare l'output. In questo esempio la funzione di Python restituisce l'oggetto Image elaborato. Selezionare l'output dell'immagine per visualizzare l'anteprima dell'immagine.

Se l'oggetto Image del nodo Python è impostato come output del flusso, è possibile visualizzare in anteprima anche l'immagine nella pagina di output del flusso.




Usare lo strumento GPT-4V
Lo strumento GPT-4 Turbo di OpenAI di Azure con Visione e GPT-4V di OpenAI sono strumenti predefiniti nel prompt flow che possono usare il modello GPT-4V di OpenAI per rispondere a domande in base a immagini di input. Per trovare lo strumento, selezionare + Altri strumenti nella pagina di creazione del flusso.
Aggiungere lo strumento GPT-4 Turbo di OpenAI di Azure con Vision al flusso. Assicurarsi di avere una connessione OpenAI di Azure, con la disponibilità dei modelli di anteprima di visione GPT-4.

Il modello Jinja per la composizione di richieste nello strumento GPT-4V segue una struttura simile all'API di chat nello strumento LLM. Per rappresentare un input di immagine all'interno della richiesta, è possibile usare la sintassi . L'input di immagine può essere passato nei messaggi user, system e assistant.
Dopo aver composto il prompt, selezionare il pulsante Convalida e analizza input per analizzare i segnaposto di input. L'input di immagine rappresentato da  verrà analizzato come tipo di immagine con il nome di input come INPUT NAME.
È possibile assegnare un valore all'input di immagine nei modi seguenti:
- Riferimento dall'input del flusso di tipo Image.
- Riferimento dall'output di un altro nodo di tipo Image.
- Caricare, trascinare, incollare un'immagine o specificare un URL di immagine o il percorso relativo dell'immagine.
Creare un chatbot per elaborare le immagini
In questa sezione viene spiegato come creare un chatbot in grado di elaborare input di immagine e testo.
Si supponga di voler creare un chatbot in grado di rispondere a qualsiasi domanda sulla combinazione di immagine e testo. A tale scopo, seguire i passaggi descritti in questa sezione.
Creare un flusso di chat.
In Input selezionare il tipo di dati come "list". Nella casella della chat l'utente può immettere una sequenza mista di testi e immagini e il servizio prompt flow la trasformerà in un elenco.
Aggiungere lo strumento GPT-4V al flusso. È possibile copiare il prompt dalla chat predefinita dello strumento LLM e incollarlo nello strumento GPT 4V. Eliminare quindi la chat predefinita dello strumento LLM dal flusso.
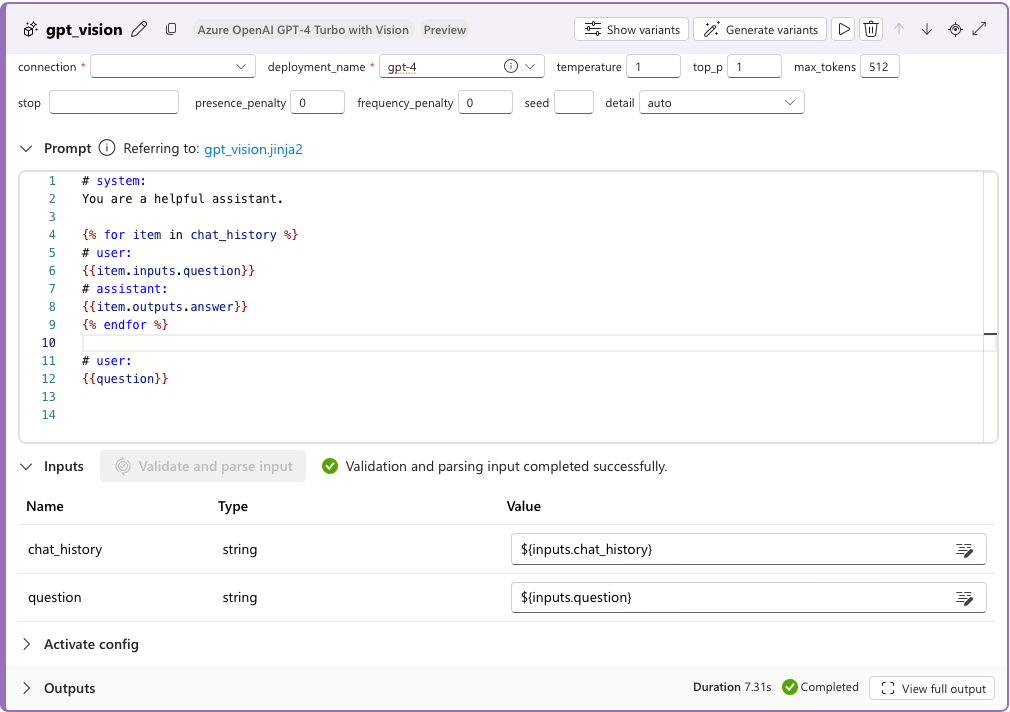
In questo esempio
{{question}}fa riferimento all'input della chat, che è un elenco di testi e immagini.In Output modificare il valore di "answer" impostando il nome dell'output dello strumento di visione,
${gpt_vision.output}ad esempio .
(Facoltativo) È possibile aggiungere qualsiasi logica personalizzata al flusso per elaborare l'output di GPT-4V. Ad esempio, è possibile aggiungere lo strumento Guardrails &controls per rilevare se la risposta contiene contenuto inappropriato e restituire una risposta finale all'utente.
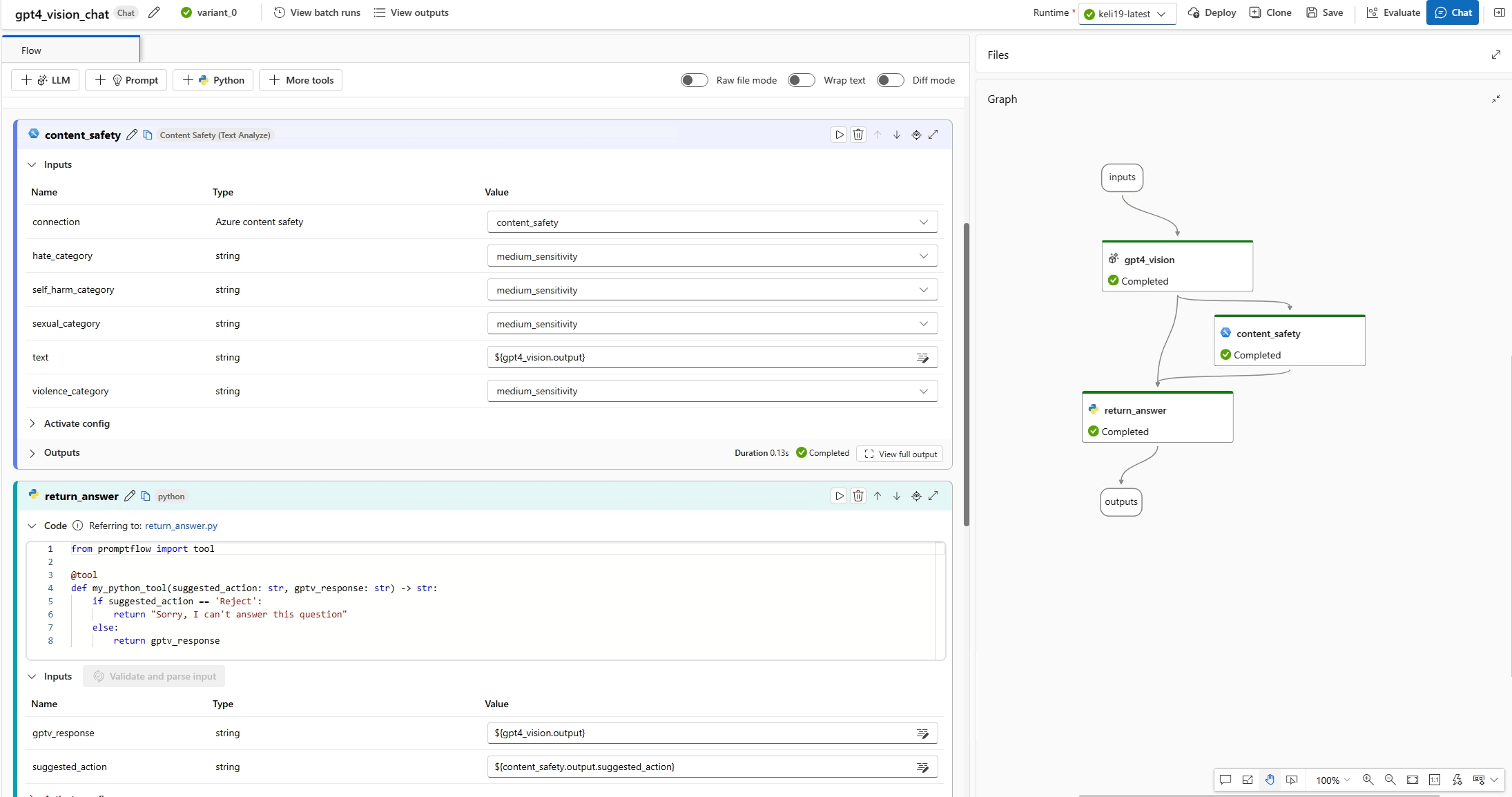
È ora possibile testare il chatbot. Aprire la finestra della chat e immettere eventuali domande relative alle immagini. Il chatbot risponderà alle domande in base agli input di immagine e di testo. Il valore di input della chat viene inserito automaticamente dall'input nella finestra della chat. È possibile trovare i testi con immagini nella casella della chat che viene convertita in un elenco di testi e immagini.
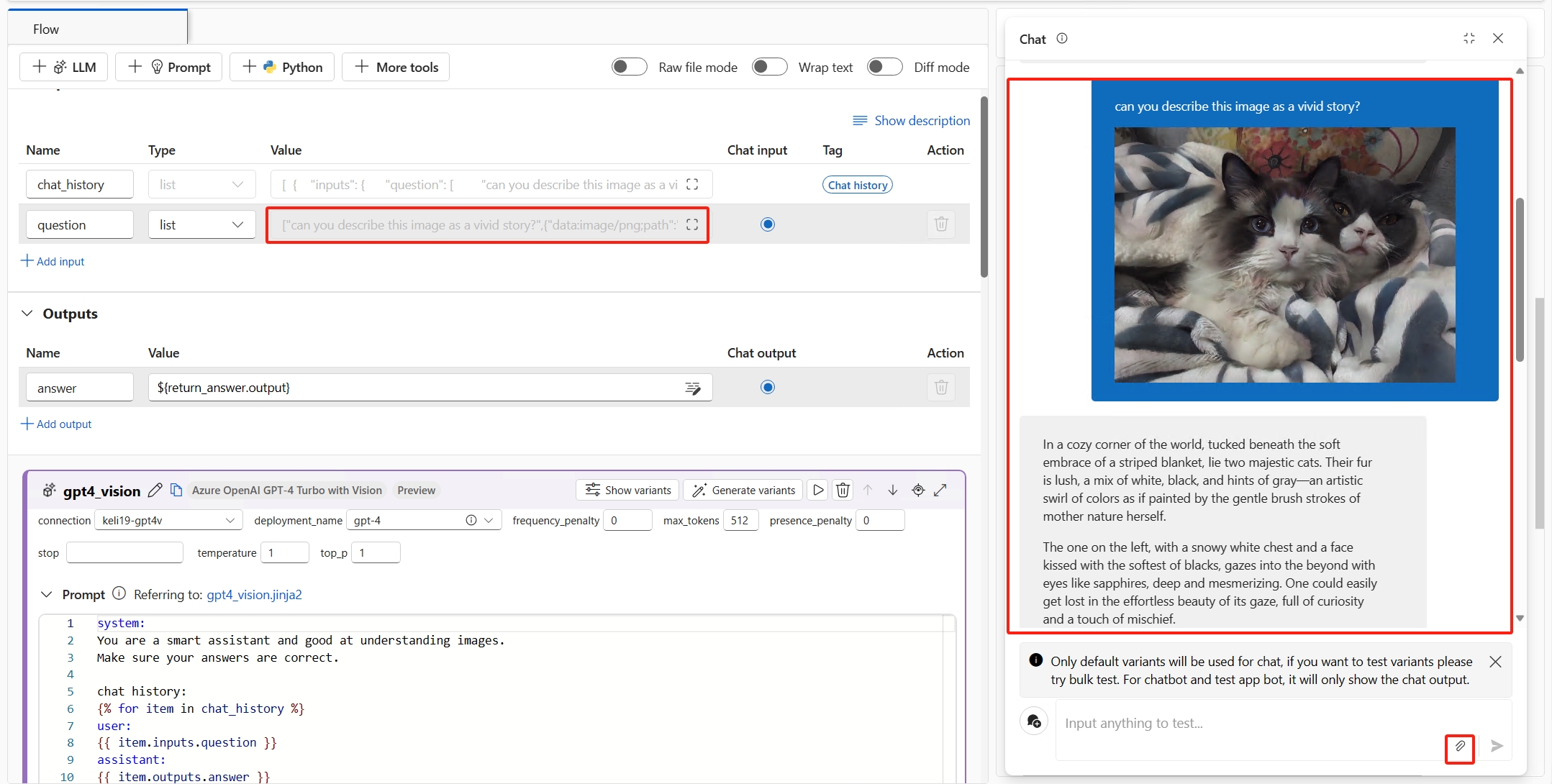





Annotazioni
Per consentire al chatbot di rispondere con testo e immagini avanzati, impostare l'output della chat sul tipo list. L'elenco deve essere costituito da stringhe (per il testo) e gli oggetti Image del prompt flow (per le immagini) in ordine personalizzato.

Creare un'esecuzione batch usando dati di immagine
Un'esecuzione batch consente di testare il flusso con un set di dati completo. Esistono tre metodi per rappresentare i dati di immagine: tramite un file di immagine, un URL di immagine pubblico o una stringa Base64.
-
File di immagine: per testare i file di immagine nell'esecuzione batch, è necessario preparare una cartella dati. Questa cartella deve contenere un file di voce di esecuzione batch in formato
jsonlche si trova nella directory radice, insieme a tutti i file di immagine archiviati nella stessa cartella o in sottocartelle.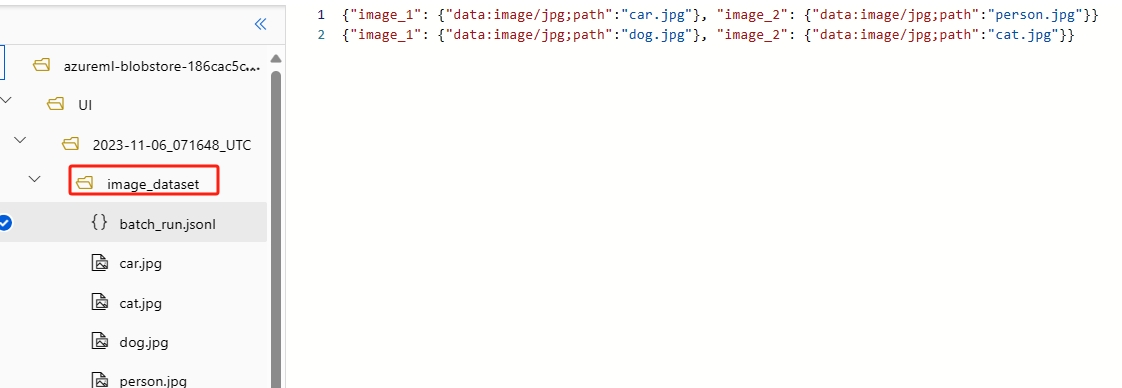 Nel file di voce è necessario usare il formato
Nel file di voce è necessario usare il formato {"data:<mime type>;path": "<image relative path>"}per fare riferimento a ogni file di immagine. Ad esempio:{"data:image/png;path": "./images/1.png"}. -
URL di immagine pubblico: è anche possibile fare riferimento all'URL dell'immagine nel file di voce usando questo formato:
{"data:<mime type>;url": "<image URL>"}. Ad esempio:{"data:image/png;url": "https://www.example.com/images/1.png"}. -
Stringa Base64: è possibile fare riferimento a una stringa Base64 nel file di voce usando questo formato:
{"data:<mime type>;base64": "<base64 string>"}. Ad esempio:{"data:image/png;base64": "iVBORw0KGgoAAAANSUhEUgAAAGQAAABLAQMAAAC81rD0AAAABGdBTUEAALGPC/xhBQAAACBjSFJNAAB6JgAAgIQAAPoAAACA6AAAdTAAAOpgAAA6mAAAF3CculE8AAAABlBMVEUAAP7////DYP5JAAAAAWJLR0QB/wIt3gAAAAlwSFlzAAALEgAACxIB0t1+/AAAAAd0SU1FB+QIGBcKN7/nP/UAAAASSURBVDjLY2AYBaNgFIwCdAAABBoAAaNglfsAAAAZdEVYdGNvbW1lbnQAQ3JlYXRlZCB3aXRoIEdJTVDnr0DLAAAAJXRFWHRkYXRlOmNyZWF0ZQAyMDIwLTA4LTI0VDIzOjEwOjU1KzAzOjAwkHdeuQAAACV0RVh0ZGF0ZTptb2RpZnkAMjAyMC0wOC0yNFQyMzoxMDo1NSswMzowMOEq5gUAAAAASUVORK5CYII="}.

In sintesi, il prompt flow usa un formato di dizionario univoco per rappresentare un'immagine, ovvero {"data:<mime type>;<representation>": "<value>"}. In questo caso, <mime type> si riferisce ai tipi di immagine MIME standard HTML e <representation> fa riferimento alle rappresentazioni di immagini supportate: path,url e base64.
Creare un'esecuzione batch
Nella pagina di creazione del flusso selezionare il pulsante Valuta>Valutazione personalizzata per avviare un'esecuzione batch. In Impostazioni esecuzione batch selezionare un set di dati, che può essere una cartella (contenente il file di voce e i file di immagine) o un file (contenente solo il file di voce). È possibile visualizzare in anteprima il file di voce ed eseguire il mapping di input per allineare le colonne nel file di voce con gli input del flusso.

Visualizzare i risultati dell'esecuzione batch
È possibile controllare gli output di esecuzione batch nella pagina dei dettagli dell'esecuzione. Selezionare l'oggetto immagine nella tabella di output per visualizzare facilmente l'anteprima dell'immagine.

Se gli output dell'esecuzione batch contengono immagini, è possibile controllare il set di dati flow_outputs con il file JSONL di output e le immagini di output.

Usare l'endpoint online con i dati di immagine
È possibile distribuire un flusso in un endpoint online per l'inferenza in tempo reale.
La scheda Test nella pagina dei dettagli della distribuzione non supporta attualmente le immagini come input o output.
Per il momento è possibile testare l'endpoint inviando una richiesta, inclusi gli input dell'immagine.
Per utilizzare l'endpoint online con l'input di immagine, è necessario rappresentare l'immagine usando il formato {"data:<mime type>;<representation>": "<value>"}. In questo caso <representation> può essere url o base64.
Se il flusso genera l'output dell'immagine, viene restituito con base64 formato, {"data:<mime type>;base64": "<base64 string>"}ad esempio .