Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Informazioni su come ottimizzare i modelli in Microsoft Foundry per i set di dati e i casi d'uso. L'ottimizzazione consente di:
- Risultati di qualità più elevati rispetto a ciò che è possibile ottenere solo dalla progettazione del prompt
- La possibilità di eseguire il training su più esempi di quanto possa rientrare nel limite massimo di contesto di richiesta di un modello.
- Risparmio di token dovuto a richieste più brevi
- Richieste a bassa latenza, in particolare quando si usano modelli più piccoli.
A differenza dell'apprendimento few-shot, l'ottimizzazione migliora il modello eseguendo il training su più esempi rispetto a quanto possibile in un prompt. Poiché i pesi si adattano al compito specifico, si includono meno esempi o istruzioni, riducendo il numero di token per chiamata con una riduzione potenziale dei costi e della latenza.
Usiamo LoRA, o adattamento con classificazione bassa, per ottimizzare i modelli in modo da ridurre la complessità senza influire significativamente sulle prestazioni. Questo metodo funziona approssimando la matrice originale di rango elevato con un rango inferiore, ottimizzando quindi solo un sottoinsieme più piccolo di parametri importanti durante la fase di training supervisionata, rendendo il modello più gestibile ed efficiente. Per gli utenti, questo processo rende il training più veloce e più conveniente rispetto ad altre tecniche.
In questo articolo verrà spiegato come:
- Scegliere set di dati e formati appropriati per l'ottimizzazione
- Attivare un processo di ottimizzazione, monitorare lo stato e recuperare i risultati.
- Distribuire e valutare un modello ottimizzato.
- Iterare sulla base del feedback di valutazione.
Prerequisiti
- Leggere la guida su quando utilizzare Foundry per la messa a punto.
- Una sottoscrizione di Azure. Creane uno gratis.
- Risorsa di progetto Foundry. Accedi al Portale Foundry per crearne uno.
- Per perfezionare l'accesso è necessario il ruolo Azure AI User.
- Se non si ha già accesso per visualizzare la quota e distribuire modelli nel portale di Microsoft Foundry, sono necessarie altre autorizzazioni.
Modelli supportati
Consultare la pagina dei modelli per verificare quali aree supportano attualmente l'ottimizzazione.
In alternativa, è possibile ottimizzare un modello ottimizzato in precedenza, formattato come base-model.ft-{jobid}.
Preparare i dati
I dati di training e i set di dati di convalida sono costituiti da esempi di input e output per il modo in cui si vuole eseguire il modello.
I dati di training e convalida che utilizzi devono essere formattati come documento JSON Lines (JSONL) e nel formato conversazionale utilizzato dall'API Chat completions.
È consigliabile utilizzare le istruzioni e i prompt che si sono rivelati migliori in ogni esempio di formazione. Ciò consente di ottenere i risultati migliori, soprattutto se si hanno meno di cento esempi.
Se non si dispone di un set di dati esistente preparato, è possibile usare le funzionalità di generazione dei dati per crearne una nuova.
Formato del file di esempio
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Formato di file chat multiturn
Sono inoltre supportati diversi turn di una conversazione in una singola riga del file di training jsonl. Per ignorare l'ottimizzazione su messaggi di assistente specifici, aggiungere la coppia di valori di chiave weight facoltativa. Attualmente è possibile impostare weight su 0 o 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the biggest city in France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Completamento della chat con Visione
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Oltre al formato JSONL, i file di dati di training e convalida devono essere codificati in UTF-8 e includere un byte order mark (BOM). Il file deve avere dimensioni inferiori a 512 MB.
Considerazioni sulle dimensioni dei set di dati
Più esempi di training sono disponibili, meglio è. L'ottimizzazione dei processi non procederà senza almeno 10 esempi di training; tuttavia, un numero così ridotto non è sufficiente per influenzare notevolmente le risposte del modello. È consigliabile fornire centinaia, se non migliaia, di esempi di training per avere successo. È consigliabile iniziare con 50 dati di training ben creati.
In generale, il raddoppio delle dimensioni del set di dati può comportare un aumento lineare della qualità del modello. Tenere tuttavia presente che gli esempi di bassa qualità possono influire negativamente sulle prestazioni. Se si esegue il training del modello su una grande quantità di dati interni, senza prima eseguire l'eliminazione del set di dati solo per gli esempi di qualità più elevata, è possibile che si verifichi un modello che comporta prestazioni peggiori del previsto.
Creare il modello ottimizzato
Per ottimizzare un modello in un progetto Foundry esistente, seguire questa procedura:
Accedere a Foundry e selezionare il progetto. Se non si ha già un progetto, crearne prima di tutto uno.
Passare alla pagina Ottimizzazione> compilazione e selezionare il pulsante Ottimizza in alto a destra.
Viene in genere visualizzata l'esperienza di ottimizzazione di un modello per la creazione di un nuovo processo di ottimizzazione. Usare le sezioni seguenti per facilitare la configurazione del processo e selezionare Invia per avviare il training del nuovo modello ottimizzato.
Selezione del modello di base
I modelli disponibili potrebbero essere limitati dall'area del progetto. La scelta del modello influisce sia sulle prestazioni che sul costo del modello.
Quando si seleziona il modello, è anche possibile selezionare un modello ottimizzato in precedenza.
Metodo di personalizzazione
È possibile supportare metodi di personalizzazione diversi in base al modello selezionato:
Supervisionato (SFT): esegue il training del modello su coppie di input-output etichettate. Ideale per la maggior parte degli scenari, inclusa la specializzazione delle attività.
Ottimizzazione delle preferenze dirette (DPO): allinea il modello con le risposte preferite dall'utente. Ideale per migliorare la qualità della risposta.
Rinforzo (RFT): usa i segnali di ricompensa dei classificatori del modello per ottimizzare comportamenti complessi.
Annotazioni
Il resto di questo documento illustra i passaggi per il metodo di ottimizzazione con supervisione. Per istruzioni specifiche per altri metodi di personalizzazione, vedere gli articoli per DPO o RFT.
Tipo di training
Selezionare il livello di training in base al caso d'uso e al budget.
Standard: il training viene eseguito nell'area della risorsa Fonderia attuale, fornendo garanzie di residenza dei dati. Ideale per i carichi di lavoro in cui i dati devono rimanere in un'area specifica.
Globale: offre prezzi più convenienti rispetto a Standard usando capacità oltre l'area corrente. I dati e i pesi vengono copiati nella regione in cui avviene l'addestramento. Ideale se la residenza dei dati non è una restrizione e si vogliono tempi di coda più rapidi.
Sviluppatore (anteprima): offre significativi risparmi sui costi usando la capacità inattiva per la formazione. Non ci sono garanzie di latenza o di accordo sul livello del servizio, quindi i processi in questo livello possono essere sospesi automaticamente e ripresi in un secondo momento. Non esistono garanzie di residenza dei dati. Ideale per la sperimentazione e i carichi di lavoro sensibili ai prezzi.
Dati di training e convalida
Se nel progetto Foundry sono presenti set di dati esistenti, scegliere Set di dati esistente per l'origine dati e quindi selezionare il set di dati.
Per caricare i set di dati appena preparati, scegliere Carica nuovo set di dati per l'origine dati e quindi caricare il file JSONL.
Dopo aver selezionato o caricato i file di dati, i controlli di convalida vengono eseguiti automaticamente per verificare che siano nel formato corretto.
Annotazioni
I file di dati di training devono essere formattati come file JSONL, codificati in UTF-8 con un byte order mark (BOM). Il file deve avere dimensioni inferiori a 512 MB. Sebbene 10 sia il numero minimo di campioni necessari nel set di dati, è consigliabile disporre di almeno centinaia di campioni di addestramento per allenare il modello per una nuova abilità.
Parametri facoltativi
Suffisso
È consigliabile compilare il campo Suffisso per semplificare la distinzione tra iterazioni diverse del modello ottimizzato. Un suffisso accetta una stringa di un massimo di 18 caratteri e viene usata quando si assegna un nome al modello ottimizzato risultante.
Seed
Controlla la riproducibilità del processo. Il passaggio degli stessi parametri per l'inizializzazione e il processo dovrebbe produrre gli stessi risultati, ma in rari casi può differire. Se non viene specificato un valore di inizializzazione, ne viene generato uno automaticamente.
Iperparametri
Gli iperparametri per il processo di ottimizzazione fine possono essere configurati manualmente o lasciati come valori predefiniti.
Sono disponibili gli iperparametri seguenti:
| Nome | Tipo | Descrizione |
|---|---|---|
batch_size |
integer | Dimensioni del batch da usare per il training. Le dimensioni del batch sono il numero di esempi di training usati per eseguire il training di un singolo passaggio avanti e indietro. In generale, si scopre che le dimensioni dei batch più grandi tendono a funzionare meglio per i set di dati più grandi. Il valore predefinito e quello massimo per questa proprietà sono specifici di un modello di base. Una dimensione batch maggiore indica che i parametri del modello vengono aggiornati meno frequentemente, ma con varianza inferiore. Se impostato su -1, batch_size viene calcolato come 0,2% degli esempi nel set di training e il valore massimo è 256. |
learning_rate_multiplier |
d'acquisto | Moltiplicatore della frequenza di apprendimento da usare per il training. La velocità di apprendimento di ottimizzazione è la velocità di apprendimento originale usata per il training preliminare moltiplicata per questo valore. I tassi di apprendimento più elevati tendono a ottenere prestazioni migliori con dimensioni batch maggiori. È consigliabile provare con i valori compresi nell'intervallo da 0,02 a 0,2 per vedere quali risultati producono i risultati migliori. Un tasso di apprendimento inferiore potrebbe essere utile per evitare il sovradattamento. |
n_epochs |
integer | Numero di periodi per cui eseguire il training del modello. Un periodo fa riferimento a un ciclo completo attraverso il set di dati di training. Se impostato su -1, il numero di periodi è determinato in modo dinamico in base ai dati di input. |
Abilitare la distribuzione automatica
Per risparmiare tempo, è possibile abilitare la distribuzione automatica per il modello risultante. Se il training termina correttamente, il modello viene distribuito usando il tipo di distribuzione selezionato. Il nome della distribuzione si basa sul nome univoco generato per il modello personalizzato e sul suffisso facoltativo fornito in precedenza.
Annotazioni
La distribuzione automatica è supportata solo per i modelli OpenAI.
Monitorare e analizzare i risultati
Dopo aver inviato il processo di ottimizzazione, verrà visualizzata una visualizzazione tabella che elenca tutti gli invii di processi di ottimizzazione. Fare clic nella pagina dei dettagli del processo per visualizzare altre informazioni sui singoli risultati.
Il processo potrebbe essere in coda dietro altri processi nel sistema. Il training del modello può richiedere alcuni minuti a seconda delle dimensioni del modello e del set di dati.
Metriche
È possibile monitorare le metriche seguenti passando al pivot Monitoraggio :
- train_loss: perdita del batch di training. Ogni passo di addestramento sull'asse x rappresenta un singolo passaggio, in avanti e indietro, su un batch di dati di addestramento.
- full_valid_loss: la perdita di convalida calcolata alla fine di ogni epoca. Quando il training va bene, la perdita dovrebbe diminuire.
-
train_mean_token_accuracy: percentuale di token nel batch di training stimata correttamente dal modello.
Ad esempio, se le dimensioni del batch sono impostate su 3 e i dati contengono completamenti[[1, 2], [0, 5], [4, 2]], questo valore viene impostato su 0,83 (5 di 6) se il modello ha previsto[[1, 1], [0, 5], [4, 2]]. - full_valid_mean_token_accuracy: accuratezza valida del token calcolata alla fine di ogni periodo. Quando il training va bene, l'accuratezza del token dovrebbe aumentare.
Cercare la perdita da ridurre nel tempo e l'accuratezza da aumentare. Se viene visualizzata una divergenza tra i dati di training e di convalida, ciò potrebbe indicare un overfitting. Provare a eseguire il training con meno periodi o a un moltiplicatore di frequenza di trading più piccolo.
Punti di controllo
Al completamento di ogni periodo di training, viene generato un checkpoint. I checkpoint possono essere visualizzati passando alla scheda Checkpoint.
Un checkpoint è una versione completamente funzionale di un modello, che può essere distribuita e usata come modello di destinazione per i successivi processi di ottimizzazione. I checkpoint possono essere utili, in quanto possono fornire snapshot prima dell'overfitting. Al termine di un processo di ottimizzazione, saranno disponibili le tre versioni più recenti del modello da distribuire. È possibile copiare punti di controllo tra risorse e sottoscrizioni attraverso l'API REST.
Annotazioni
Durante il training è possibile visualizzare le metriche e sospendere il processo in base alle esigenze. La sospensione può essere utile se le metriche non sono convergenti o se si ritiene che il modello non stia imparando al ritmo corretto. Una volta sospeso il processo di training, al termine delle valutazioni di sicurezza verrà creato un checkpoint distribuibile. Questo checkpoint è disponibile per la distribuzione e l'utilizzo per l'inferenza o per riprendere il processo fino al completamento. L'operazione di sospensione è applicabile solo per i processi sottoposti a training per almeno un passaggio e che siano in stato In esecuzione. La sospensione è supportata solo per i modelli OpenAI.
Distribuire il modello ottimizzato
Dopo aver soddisfatto le metriche del processo di ottimizzazione, è possibile distribuire il modello facendo clic sul pulsante Distribuisci nella parte superiore destra della pagina dei dettagli e configurando le impostazioni di distribuzione.
Per altri dettagli, vedere la guida all'ottimizzazione della distribuzione.
Usare un modello ottimizzato per la distribuzione
Dopo la distribuzione del modello ottimizzato, è possibile usarlo come qualsiasi altro modello distribuito. È possibile usare Playground in Foundry per sperimentare la nuova distribuzione. È anche possibile usare l'API REST per chiamare il modello ottimizzato dall'applicazione. È anche possibile iniziare a usare questo nuovo modello ottimizzato nel prompt flow per compilare l'applicazione di intelligenza artificiale generativa.
Annotazioni
Per i modelli di chat, il messaggio di sistema usato per guidare il modello ottimizzato (sia distribuito sia disponibile per i test nel playground) deve essere lo stesso del messaggio di sistema usato per l'addestramento. Se si usa un messaggio di sistema differente, il modello potrebbe non funzionare come previsto.
Ottimizzazione continua
Dopo aver creato un modello ottimizzato, è possibile continuare a perfezionare il modello nel tempo tramite un'ulteriore ottimizzazione. L'ottimizzazione continua è il processo iterativo per selezionare un modello già ottimizzato come modello di base e ottimizzarlo ulteriormente sui nuovi set di esempi di training.
Per eseguire l'ottimizzazione su un modello ottimizzato in precedenza, è necessario usare lo stesso processo descritto nella creazione di un modello ottimizzato, ma invece di specificare il nome di un modello di base generico, è necessario specificare il modello già ottimizzato. Un modello personalizzato ottimizzato apparirebbe come gpt-4o-2024-08-06.ft-d93dda6110004b4da3472d96f4dd4777-ft.
Annotazioni
L'ottimizzazione continua è supportata solo per i modelli OpenAI.
Pulisci le tue risorse
Al termine del modello ottimizzato, è possibile eliminare la distribuzione e il modello. È anche possibile eliminare i file di training e convalida caricati nel servizio, se necessario.
Eliminare la distribuzione del modello ottimizzato
Importante
Dopo la distribuzione di un modello personalizzato, se in qualsiasi momento la distribuzione rimane inattiva per più di quindici (15) giorni, la distribuzione verrà eliminata. La distribuzione di un modello personalizzato è inattiva se il modello è stato distribuito più di quindici (15) giorni prima e non sono stati effettuati completamenti o chiamate di completamento della chat per un periodo continuativo di 15 giorni.
L'eliminazione di una distribuzione inattiva non elimina o influisce sul modello personalizzato sottostante e il modello personalizzato può essere ridistribuito in qualsiasi momento. Come descritto nei prezzi di Azure OpenAI in Modelli di Fonderia Microsoft, ogni modello personalizzato, ottimizzato e distribuito comporta un costo di hosting orario indipendentemente dal fatto che vengano effettuate chiamate di completamento o di completamento della chat al modello. Per altre informazioni sulla pianificazione e la gestione dei costi con Azure OpenAI, vedere le linee guida in Pianificare la gestione dei costi per Azure OpenAI.
È possibile eliminare la distribuzione per il modello ottimizzato nella pagina Compila> Modelli nel portale Fonderia.
Eliminare il modello ottimizzato
È possibile eliminare un modello ottimizzato nella pagina Fine-tuning sul portale Foundry. Selezionare il modello ottimizzato da eliminare, quindi selezionare Elimina per eliminarlo.
Annotazioni
Non è possibile eliminare un modello ottimizzato se ha una distribuzione esistente. Prima di poter eliminare la distribuzione modello, è necessario eliminare il modello ottimizzato.
Prerequisiti
- Leggere la Guida Quando usare l'ottimizzazione di Azure OpenAI.
- Una sottoscrizione di Azure. Creane uno gratis.
- Risorsa Azure OpenAI. Per altre informazioni, vedere Creare una risorsa e distribuire un modello con Azure OpenAI.
- Le librerie Python seguenti:
os,json,requests,openai. - Libreria Python OpenAI.
- Per ottimizzare l'accesso è necessario il ruolo Utente AI di Azure.
- Se non si ha già accesso alla quota di visualizzazione e si distribuiscono modelli nel portale di Microsoft Foundry, saranno necessarie autorizzazioni aggiuntive.
Modelli supportati
Consultare la pagina dei modelli per verificare quali aree supportano attualmente l'ottimizzazione.
In alternativa, è possibile ottimizzare un modello ottimizzato in precedenza, formattato come base-model.ft-{jobid}.
Esaminare il flusso di lavoro per Python SDK
Esaminare il flusso di lavoro di ottimizzazione per l'uso di Python SDK con Azure OpenAI:
- Preparare i dati di training e convalida.
- Selezionare un modello di base.
- Caricare i dati di training.
- Eseguire il training del nuovo modello personalizzato.
- Controllare lo stato del modello personalizzato.
- Distribuire il modello personalizzato per l'uso.
- Usare il modello personalizzato.
- Facoltativamente, analizzare prestazioni e adattamento del modello personalizzato.
Preparare i dati di training e convalida
I dati di training e i set di dati di convalida sono costituiti da esempi di input e output per il modo in cui si vuole eseguire il modello.
I dati di training e convalida che utilizzi devono essere formattati come documento JSON Lines (JSONL) e nel formato conversazionale utilizzato dall'API Chat completions.
Per una procedura dettagliata sull'ottimizzazione, gpt-4o-mini-2024-07-18 vedere l'esercitazione sull'ottimizzazione di Azure OpenAI
Formato del file di esempio
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Formato di file chat multiturn
Sono inoltre supportati diversi turn di una conversazione in una singola riga del file di training jsonl. Per ignorare l'ottimizzazione su messaggi di assistente specifici, aggiungere la coppia di valori di chiave weight facoltativa. Attualmente è possibile impostare weight su 0 o 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Completamento della chat con Visione
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Oltre al formato JSONL, i file di dati di training e convalida devono essere codificati in UTF-8 e includere un byte order mark (BOM). Il file deve avere dimensioni inferiori a 512 MB.
Creare i set di dati di training e convalida
Più esempi di training sono disponibili, meglio è. L'ottimizzazione dei processi non procederà senza almeno 10 esempi di training; tuttavia, un numero così ridotto non è sufficiente per influenzare notevolmente le risposte del modello. È consigliabile fornire centinaia, se non migliaia, di esempi di training per avere successo.
In generale, il raddoppio delle dimensioni del set di dati può comportare un aumento lineare della qualità del modello. Tenere tuttavia presente che gli esempi di bassa qualità possono influire negativamente sulle prestazioni. Se si esegue il training del modello su una grande quantità di dati interni, senza prima eliminare il set di dati solo degli esempi di qualità più elevati, è possibile ottenere un modello che comporta prestazioni molto peggiori del previsto.
Caricare i dati di training
Il passaggio successivo consiste nella scelta dei dati di training preparati esistenti o nel caricamento di nuovi dati di training preparati da usare durante la personalizzazione del modello. Dopo aver preparato i dati di training, è possibile caricare i file nel servizio. Sono disponibili due modi per caricare i dati di training:
Per i file di dati di grandi dimensioni, è consigliabile eseguire l'importazione da un archivio BLOB di Azure. I file di grandi dimensioni possono diventare instabili quando vengono caricati tramite moduli in più parti, perché le richieste sono atomiche e non possono essere ritentate o riprese. Per altre informazioni su Archiviazione BLOB di Azure, vedere Che cos’è l’archiviazione BLOB di Azure?
Annotazioni
I file di dati di training devono essere formattati come file JSONL, codificati in UTF-8 con un byte order mark (BOM). Il file deve avere dimensioni inferiori a 512 MB.
L'esempio Python seguente carica i file di training e convalida locali usando Python SDK e recupera gli ID file restituiti.
import os
from openai import OpenAI
# Load the OpenAI client
client = OpenAI(
api_key = os.getenv("AZURE_OPENAI_API_KEY"),
base_url="https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/"
)
# Upload the training and validation dataset files to Microsoft Foundry with the SDK.
training_file_name = 'training_set.jsonl'
validation_file_name = 'validation_set.jsonl'
training_response = client.files.create(file=open(training_file_name, "rb"), purpose="fine-tune")
validation_response = client.files.create(file=open(validation_file_name, "rb"), purpose="fine-tune")
training_file_id = training_response.id
validation_file_id = validation_response.id
print("Training file ID:", training_file_id)
print("Validation file ID:", validation_file_id)
Creare un modello personalizzato
Dopo aver caricato i file di training e convalida, si è pronti per avviare il processo di ottimizzazione.
Il codice Python seguente illustra un esempio di come creare un nuovo processo di ottimizzazione con Python SDK:
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-4.1-2025-04-14", # Enter base model name.
suffix="my-model", # Custom suffix for naming the resulting model. Note that in Microsoft Foundry the model cannot contain dot/period characters.
seed=105, # Seed parameter controls reproducibility of the fine-tuning job. If no seed is specified one will be generated automatically.
extra_body={ "trainingType": "GlobalStandard" } # Change this to your preferred training type. Other options are `Standard` and `Developer`.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print(response.model_dump_json(indent=2))
Annotazioni
È consigliabile usare il livello Standard globale per il tipo di training, perché offre risparmi sui costi e sfrutta la capacità globale per tempi di accodamento più rapidi. Tuttavia, copia i dati e i pesi fuori dall'area di risorse corrente. Se la residenza dei dati è un requisito, usare un modello che supporta l'addestramento al livello Standard.
È anche possibile passare parametri facoltativi aggiuntivi, ad esempio gli iperparametri, per assumere un maggiore controllo del processo di ottimizzazione. Per il training iniziale, è consigliabile usare le impostazioni predefinite automatiche presenti senza specificare questi parametri.
Gli iperparametri attualmente supportati per i Fine-Tuning con supervisione sono:
| Nome | Tipo | Descrizione |
|---|---|---|
batch_size |
integer | Dimensioni del batch da usare per il training. Le dimensioni del batch sono il numero di esempi di training usati per eseguire il training di un singolo passaggio avanti e indietro. In generale, è stato rilevato che le dimensioni dei batch più grandi tendono a funzionare meglio per set di dati di dimensioni maggiori. Il valore predefinito e il valore massimo per questa proprietà sono specifici di un modello di base. Una dimensione batch maggiore indica che i parametri del modello vengono aggiornati meno frequentemente, ma con varianza inferiore. |
learning_rate_multiplier |
d'acquisto | Moltiplicatore della frequenza di apprendimento da usare per il training. La velocità di apprendimento di ottimizzazione è la velocità di apprendimento originale usata per il training preliminare moltiplicata per questo valore. I tassi di apprendimento più elevati tendono a ottenere prestazioni migliori con dimensioni batch maggiori. È consigliabile provare con i valori compresi nell'intervallo da 0,02 a 0,2 per vedere quali risultati producono i risultati migliori. Un tasso di apprendimento inferiore può essere utile per evitare l'overfitting. |
n_epochs |
integer | Numero di periodi per cui eseguire il training del modello. Un periodo fa riferimento a un ciclo completo attraverso il set di dati di training. |
seed |
integer | Il seme controlla la riproducibilità del lavoro. Il passaggio degli stessi parametri di inizializzazione e processo dovrebbe produrre gli stessi risultati, ma in rari casi può differire. Se non viene specificato un valore di inizializzazione, ne verrà generato uno automaticamente. |
Per impostare iperparametri personalizzati con la versione 1.x dell'API Python OpenAI, specificarli come parte di method:
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-4.1-2025-04-14",
suffix="my-model",
seed=105,
method={
"type": "supervised", # In this case, the job will be using Supervised Fine Tuning.
"supervised": {
"hyperparameters": {
"n_epochs": 2
}
}
},
extra_body={ "trainingType": "GlobalStandard" }
)
Annotazioni
Per altre informazioni sugli iperparametri supportati, vedere le guide per l'ottimizzazione delle preferenze dirette e l'ottimizzazione del rinforzo .
Tipo di training
Selezionare il livello di training in base al caso d'uso e al budget.
Standard: il training viene eseguito nell'area della risorsa Fonderia attuale, fornendo garanzie di residenza dei dati. Ideale per i carichi di lavoro in cui i dati devono rimanere in un'area specifica.
Globale: offre prezzi più convenienti rispetto a Standard sfruttando la capacità oltre l'area corrente. I dati e i pesi vengono copiati nella regione in cui avviene l'addestramento. Ideale se la residenza dei dati non è una restrizione e si vogliono tempi di coda più rapidi.
Sviluppatore (anteprima): fornisce significativi risparmi sfruttando la capacità inattiva per il training. Non ci sono garanzie di latenza o di accordo sul livello del servizio, quindi i processi in questo livello possono essere sospesi automaticamente e ripresi in un secondo momento. Non esistono garanzie di residenza dei dati. Ideale per la sperimentazione e i carichi di lavoro sensibili ai prezzi.
import openai
from openai import AzureOpenAI
base_uri = "https://<ACCOUNT-NAME>.services.ai.azure.com"
api_key = "<API-KEY>"
api_version = "2025-04-01-preview"
client = AzureOpenAI(
azure_endpoint=base_uri,
api_key=api_key,
api_version=api_version
)
try:
client.fine_tuning.jobs.create(
model="gpt-4.1-mini",
training_file="<FILE-ID>",
extra_body={"trainingType": "developerTier"}
)
except openai.APIConnectionError as e:
print("The server could not be reached")
print(e.__cause__) # an underlying Exception, likely raised within httpx.
except openai.RateLimitError as e:
print("A 429 status code was received; we should back off a bit.")
except openai.APIStatusError as e:
print("Another non-200-range status code was received")
print(e.status_code)
print(e.response)
print(e.body)
Controllare lo stato del processo di ottimizzazione
response = client.fine_tuning.jobs.retrieve(job_id)
print("Job ID:", response.id)
print("Status:", response.status)
print(response.model_dump_json(indent=2))
Elencare gli eventi di ottimizzazione
Per esaminare i singoli eventi di ottimizzazione generati durante il training, potrebbe essere necessario aggiornare la libreria client OpenAI alla versione più recente con per pip install openai --upgrade eseguire questo comando.
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
Punti di controllo
Al completamento di ogni periodo di training, viene generato un checkpoint. Un checkpoint è una versione completamente funzionale di un modello che può essere distribuita e usata come modello di destinazione per i processi di ottimizzazione successivi. I checkpoint possono essere particolarmente utili, in quanto possono fornire snapshot prima dell'overfitting. Al termine di un processo di ottimizzazione, le tre versioni più recenti del modello saranno disponibili per la distribuzione. L'epoca finale sarà rappresentata dal modello ottimizzato, le due epoche precedenti saranno disponibili come checkpoint.
È possibile eseguire il comando list checkpoints per recuperare l'elenco di checkpoint associati a un singolo processo di ottimizzazione. Per eseguire questo comando potrebbe essere necessario aggiornare la libreria client OpenAI all'ultima versione con pip install openai --upgrade.
response = client.fine_tuning.jobs.checkpoints.list(job_id)
print(response.model_dump_json(indent=2))
Analizzare il modello personalizzato
Azure OpenAI collega un file di risultato, denominato results.csv a ogni processo di ottimizzazione dopo il completamento. È possibile usare il file dei risultati per analizzare le prestazioni del training e convalidare del modello personalizzato. L'ID file per il file dei risultati è elencato per ogni modello personalizzato ed è possibile usare Python SDK per recuperare l'ID file e scaricare il file di risultato per l'analisi.
L'esempio python seguente recupera l'ID file del primo file di risultato allegato al processo di ottimizzazione per il modello personalizzato e quindi usa Python SDK per scaricare il file nella directory di lavoro corrente per l'analisi.
# Retrieve the file ID of the first result file from the fine-tuning job
# for the customized model.
response = client.fine_tuning.jobs.retrieve(job_id)
if response.status == 'succeeded':
result_file_id = response.result_files[0]
retrieve = client.files.retrieve(result_file_id)
# Download the result file.
print(f'Downloading result file: {result_file_id}')
with open(retrieve.filename, "wb") as file:
result = client.files.content(result_file_id).read()
file.write(result)
Il file dei risultati è un file CSV contenente una riga di intestazione e una riga per ogni passaggio di training eseguito dal processo di ottimizzazione. Il file dei risultati contiene le colonne seguenti:
| Nome della colonna | Descrizione |
|---|---|
step |
Numero del passaggio di training. Un passaggio di training rappresenta un singolo passaggio, avanti e indietro, in un batch di dati di training. |
train_loss |
Perdita per il batch di training. |
train_mean_token_accuracy |
Percentuale di token nel batch di training stimati correttamente dal modello. Ad esempio, se le dimensioni del batch sono impostate su 3 e i dati contengono completamenti [[1, 2], [0, 5], [4, 2]], questo valore viene impostato su 0,83 (5 di 6) se il modello ha previsto [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
Perdita per il batch di convalida. |
validation_mean_token_accuracy |
Percentuale di token nel batch di convalida stimati correttamente dal modello. Ad esempio, se le dimensioni del batch sono impostate su 3 e i dati contengono completamenti [[1, 2], [0, 5], [4, 2]], questo valore viene impostato su 0,83 (5 di 6) se il modello ha previsto [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
Perdita di convalida calcolata alla fine di ogni epoca. Quando il training va bene, la perdita dovrebbe diminuire. |
full_valid_mean_token_accuracy |
Accuratezza del token media valida calcolata alla fine di ogni epoca. Quando il training va bene, l'accuratezza del token dovrebbe aumentare. |
È anche possibile visualizzare i dati nel file results.csv come tracciati nel portale di Microsoft Foundry. Selezionare il collegamento per il modello sottoposto a training; verranno visualizzati tre grafici: perdita, accuratezza del token media e accuratezza del token. Se sono stati forniti dati di convalida, entrambi i set di dati verranno visualizzati nello stesso tracciato.
Cercare la perdita da ridurre nel tempo e l'accuratezza da aumentare. Una divergenza tra i dati di training e i dati di convalida potrebbe indicare un overfitting. Provare a eseguire il training con meno periodi o a un moltiplicatore di frequenza di trading più piccolo.
Distribuire un modello ottimizzato
Dopo aver soddisfatto le metriche del processo di ottimizzazione, oppure si vuole semplicemente passare all'inferenza, è necessario distribuire il modello.
Se si esegue la distribuzione per un'ulteriore convalida, valutare la possibilità di eseguire la distribuzione per i test usando una distribuzione per sviluppatori.
A differenza dei comandi SDK precedenti, la distribuzione deve essere eseguita usando l'API del piano di controllo che richiede un'autorizzazione separata, un percorso API diverso e una versione differente dell'API.
| Variabile | Definizione |
|---|---|
| token | Esistono diversi modi per generare un token di autorizzazione. Il metodo più semplice per i test iniziali consiste nell'avviare Cloud Shell dal portale di Azure. Quindi eseguire az account get-access-token. È possibile usare questo token come token di autorizzazione temporaneo per il test dell'API. È consigliabile archiviare questo valore in una nuova variabile di ambiente. |
| abbonamento | ID sottoscrizione per la risorsa Azure OpenAI associata. |
| gruppo di risorse | Nome del gruppo di risorse per la risorsa Azure OpenAI. |
| nome_risorsa | Nome della risorsa di Azure OpenAI. |
| model_deployment_name | Nome personalizzato per la nuova distribuzione del modello ottimizzata. Questo è il nome a cui verrà fatto riferimento nel codice quando si effettuano chiamate di completamento della chat. |
| fine_tuned_model | Recuperare questo valore dai risultati del processo di ottimizzazione nel passaggio precedente. Sarà simile a gpt-4.1-2025-04-14.ft-b044a9d3cf9c4228b5d393567f693b83. Sarà necessario aggiungere tale valore al deploy_data json. In alternativa, è anche possibile distribuire un checkpoint passando l'ID del checkpoint, che verrà visualizzato nel formato ftchkpt-e559c011ecc04fc68eaa339d8227d02d |
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<YOUR_SUBSCRIPTION_ID>"
resource_group = "<YOUR_RESOURCE_GROUP_NAME>"
resource_name = "<YOUR_AZURE_OPENAI_RESOURCE_NAME>"
model_deployment_name ="gpt-41-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2024-10-01"} # control plane API version rather than dataplane API for this call
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"fine_tuned_model">, #retrieve this value from the previous call, it will look like gpt-4.1-2025-04-14.ft-b044a9d3cf9c4228b5d393567f693b83
"version": "1"
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
Altre informazioni sulla distribuzione tra aree e sull'uso del modello distribuito sono disponibili qui.
Se si è pronti per la distribuzione per la produzione o si hanno specifiche esigenze di residenza dei dati, seguire la guida alla distribuzione.
Ottimizzazione continua
Dopo aver creato un modello ottimizzato, si può desiderare di continuare a perfezionare il modello nel tempo tramite un'ulteriore ottimizzazione. L'ottimizzazione continua è il processo iterativo per selezionare un modello già ottimizzato come modello di base e ottimizzarlo ulteriormente sui nuovi set di esempi di training.
Annotazioni
L'ottimizzazione continua è supportata solo per i modelli OpenAI.
Per eseguire l'ottimizzazione su un modello ottimizzato in precedenza, è necessario usare lo stesso processo descritto in Creare un modello personalizzato, ma invece di specificare il nome di un modello di base generico, è necessario specificare l'ID del modello già ottimizzato. L'ID modello ottimizzato è simile al seguente gpt-4.1-2025-04-14.ft-5fd1918ee65d4cd38a5dcf6835066ed7
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-4.1-2025-04-14.ft-5fd1918ee65d4cd38a5dcf6835066ed7"
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
È anche consigliabile includere il parametro suffix per semplificare la distinzione tra iterazioni differenti del modello ottimizzato.
suffix accetta una stringa ed è impostato per identificare il modello ottimizzato. Con l'API Python OpenAI è supportata una stringa di un massimo di 18 caratteri che verrà aggiunta al nome del modello ottimizzato.
Se non si è certi dell'ID del modello ottimizzato esistente, queste informazioni sono disponibili nella pagina Modelli di Microsoft Foundry oppure è possibile generare un elenco di modelli per una determinata risorsa OpenAI di Azure usando l'API REST.
Pulire le distribuzioni, i modelli personalizzati e i file di training
Al termine del modello personalizzato, è possibile eliminare la distribuzione e il modello. È anche possibile eliminare i file di training e convalida caricati nel servizio, se necessario.
Eliminare la distribuzione del modello
Importante
Dopo la distribuzione di un modello personalizzato, se in qualsiasi momento la distribuzione rimane inattiva per più di quindici (15) giorni, la distribuzione verrà eliminata. La distribuzione di un modello personalizzato è inattiva se il modello è stato distribuito più di quindici (15) giorni prima e non sono stati effettuati completamenti o chiamate di completamento della chat per un periodo continuativo di 15 giorni.
L'eliminazione di una distribuzione inattiva non elimina o influisce sul modello personalizzato sottostante e il modello personalizzato può essere ridistribuito in qualsiasi momento. Come descritto nei prezzi di Azure OpenAI in Modelli di Fonderia Microsoft, ogni modello personalizzato, ottimizzato e distribuito comporta un costo di hosting orario indipendentemente dal fatto che vengano effettuate chiamate di completamento o di completamento della chat al modello. Per altre informazioni sulla pianificazione e la gestione dei costi con Azure OpenAI, vedere le linee guida in Pianificare la gestione dei costi per Azure OpenAI.
È possibile usare vari metodi per eliminare la distribuzione per il modello personalizzato:
Eliminare il modello personalizzato
Analogamente, è possibile usare vari metodi per eliminare il modello personalizzato:
Annotazioni
Non è possibile eliminare un modello personalizzato se ha una distribuzione esistente. Prima di poter eliminare il modello personalizzato, è necessario eliminare la distribuzione del modello.
Eliminare i file di training
Facoltativamente, è possibile eliminare i file di training e convalida caricati per il training e i file di risultato generati durante il training dall'abbonamento a Azure OpenAI. È possibile usare i metodi seguenti per eliminare i file di training, convalida e risultato:
- Microsoft Foundry
- Le API REST
- Python SDK
L'esempio Python seguente usa Python SDK per eliminare i file di training, convalida e risultato per il modello personalizzato:
print('Checking for existing uploaded files.')
results = []
# Get the complete list of uploaded files in our subscription.
files = openai.File.list().data
print(f'Found {len(files)} total uploaded files in the subscription.')
# Enumerate all uploaded files, extracting the file IDs for the
# files with file names that match your training dataset file and
# validation dataset file names.
for item in files:
if item["filename"] in [training_file_name, validation_file_name, result_file_name]:
results.append(item["id"])
print(f'Found {len(results)} already uploaded files that match our files')
# Enumerate the file IDs for our files and delete each file.
print(f'Deleting already uploaded files.')
for id in results:
openai.File.delete(sid = id)
Prerequisiti
- Leggere la Guida Quando usare l'ottimizzazione di Azure OpenAI.
- Una sottoscrizione di Azure. Creane uno gratis.
- Risorsa Azure OpenAI. Per altre informazioni, vedere Creare una risorsa e distribuire un modello con Azure OpenAI.
- Per ottimizzare l'accesso è necessario il ruolo Utente AI di Azure.
- Se non si ha già accesso alla quota di visualizzazione e si distribuiscono modelli nel portale di Microsoft Foundry, sono necessarie autorizzazioni aggiuntive.
Modelli supportati
Consultare la pagina dei modelli per verificare quali aree supportano attualmente l'ottimizzazione.
In alternativa, è possibile ottimizzare un modello ottimizzato in precedenza, formattato come base-model.ft-{jobid}.
Esaminare il flusso di lavoro per l'API REST
Esaminare il flusso di lavoro di ottimizzazione per l'uso delle API REST e Python con Azure OpenAI:
- Preparare i dati di training e convalida.
- Selezionare un modello di base.
- Caricare i dati di training.
- Eseguire il training del nuovo modello personalizzato.
- Controllare lo stato del modello personalizzato.
- Distribuire il modello personalizzato per l'uso.
- Usare il modello personalizzato.
- Facoltativamente, analizzare prestazioni e adattamento del modello personalizzato.
Preparare i dati di training e convalida
I dati di training e i set di dati di convalida sono costituiti da esempi di input e output per il modo in cui si vuole eseguire il modello.
I dati di training e convalida che utilizzi devono essere formattati come documento JSON Lines (JSONL) e nel formato conversazionale utilizzato dall'API Chat completions.
Per una procedura dettagliata sull'ottimizzazione di un modello gpt-4o-mini-2024-07-18, vedere l'esercitazione sull'ottimizzazione di OpenAI di Azure.
Formato del file di esempio
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Formato di file chat multiturn
Sono inoltre supportati diversi turn di una conversazione in una singola riga del file di training jsonl. Per ignorare l'ottimizzazione su messaggi di assistente specifici, aggiungere la coppia di valori di chiave weight facoltativa. Attualmente è possibile impostare weight su 0 o 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Completamento della chat con Visione
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Oltre al formato JSONL, i file di dati di training e convalida devono essere codificati in UTF-8 e includere un byte order mark (BOM). Il file deve avere dimensioni inferiori a 512 MB.
Creare i set di dati di training e convalida
Più esempi di training sono disponibili, meglio è. L'ottimizzazione dei processi non procederà senza almeno 10 esempi di training; tuttavia, un numero così ridotto non è sufficiente per influenzare notevolmente le risposte del modello. È consigliabile fornire centinaia, se non migliaia, di esempi di training per avere successo.
In generale, il raddoppio delle dimensioni del set di dati può comportare un aumento lineare della qualità del modello. Tenere tuttavia presente che gli esempi di bassa qualità possono influire negativamente sulle prestazioni. Se si esegue il training del modello su una grande quantità di dati interni, senza prima eliminare il set di dati solo degli esempi di qualità più elevati, è possibile ottenere un modello che comporta prestazioni molto peggiori del previsto.
Caricare i dati di training
Il passaggio successivo consiste nella scelta dei dati di training preparati esistenti o nel caricamento di nuovi dati di training preparati da usare durante l'ottimizzazione del modello. Dopo aver preparato i dati di training, è possibile caricare i file nel servizio. Sono disponibili due modi per caricare i dati di training:
Per i file di dati di grandi dimensioni, è consigliabile eseguire l'importazione da un archivio BLOB di Azure. I file di grandi dimensioni possono diventare instabili quando vengono caricati tramite moduli in più parti, perché le richieste sono atomiche e non possono essere ritentate o riprese. Per altre informazioni su Archiviazione BLOB di Azure, vedere Che cos’è l’archiviazione BLOB di Azure?
Annotazioni
I file di dati di training devono essere formattati come file JSONL, codificati in UTF-8 con un byte order mark (BOM). Il file deve avere dimensioni inferiori a 512 MB.
Carica dati di training
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/files \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\training_set.jsonl;type=application/json"
Caricare i dati di convalida
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/files \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\validation_set.jsonl;type=application/json"
Creare un modello personalizzato
Dopo aver caricato i file di training e convalida, si è pronti per avviare il processo di ottimizzazione. Il codice seguente mostra un esempio di come creare un nuovo processo di ottimizzazione con l'API REST.
In questo esempio viene passato anche il parametro per il inizializzazione. Il seme controlla la riproducibilità del lavoro. Il passaggio degli stessi parametri di inizializzazione e processo dovrebbe produrre gli stessi risultati, ma in rari casi può differire. Se non viene specificato un valore di inizializzazione, ne verrà generato uno automaticamente.
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-4.1-2025-04-14",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"seed": 105
}'
Se si ottimizza finemente un modello che supporta Training Globale, è possibile specificare il tipo di training usando l'argomento denominato extra_body e la versione API 2025-04-01-preview:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2025-04-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-4.1-2025-04-14",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"seed": 105,
"trainingType": "globalstandard"
}'
È anche possibile passare parametri facoltativi aggiuntivi, ad esempio gli iperparametri, per assumere un maggiore controllo del processo di ottimizzazione. Per il training iniziale, è consigliabile usare le impostazioni predefinite automatiche presenti senza specificare questi parametri.
Gli iperparametri attualmente supportati per i Fine-Tuning con supervisione sono:
| Nome | Tipo | Descrizione |
|---|---|---|
batch_size |
integer | Dimensioni del batch da usare per il training. Le dimensioni del batch sono il numero di esempi di training usati per eseguire il training di un singolo passaggio avanti e indietro. In generale, è stato rilevato che le dimensioni dei batch più grandi tendono a funzionare meglio per set di dati di dimensioni maggiori. Il valore predefinito e il valore massimo per questa proprietà sono specifici di un modello di base. Una dimensione batch maggiore indica che i parametri del modello vengono aggiornati meno frequentemente, ma con varianza inferiore. |
learning_rate_multiplier |
d'acquisto | Moltiplicatore della frequenza di apprendimento da usare per il training. La velocità di apprendimento di ottimizzazione è la velocità di apprendimento originale usata per il training preliminare moltiplicata per questo valore. I tassi di apprendimento più elevati tendono a ottenere prestazioni migliori con dimensioni batch maggiori. È consigliabile provare con i valori compresi nell'intervallo da 0,02 a 0,2 per vedere quali risultati producono i risultati migliori. Un tasso di apprendimento inferiore può essere utile per evitare l'overfitting. |
n_epochs |
integer | Numero di periodi per cui eseguire il training del modello. Un periodo fa riferimento a un ciclo completo attraverso il set di dati di training. |
seed |
integer | Il seme controlla la riproducibilità del lavoro. Il passaggio degli stessi parametri di inizializzazione e processo dovrebbe produrre gli stessi risultati, ma in rari casi può differire. Se non viene specificato un valore di inizializzazione, ne verrà generato uno automaticamente. |
Annotazioni
Per altre informazioni sugli iperparametri supportati, vedere le guide per l'ottimizzazione delle preferenze dirette e l'ottimizzazione del rinforzo .
Tipo di training
Selezionare il livello di training in base al caso d'uso e al budget.
Standard: il training viene eseguito nell'area della risorsa Fonderia attuale, fornendo garanzie di residenza dei dati. Ideale per i carichi di lavoro in cui i dati devono rimanere in un'area specifica.
Globale: offre prezzi più convenienti rispetto a Standard sfruttando la capacità oltre l'area corrente. I dati e i pesi vengono copiati nella regione in cui avviene l'addestramento. Ideale se la residenza dei dati non è una restrizione e si vogliono tempi di coda più rapidi.
Sviluppatore (anteprima): offre risparmi significativi sui costi sfruttando la capacità inattiva per la formazione. Non ci sono garanzie di latenza o di accordo sul livello del servizio, quindi i processi in questo livello possono essere sospesi automaticamente e ripresi in un secondo momento. Non esistono garanzie di residenza dei dati. Ideale per la sperimentazione e i carichi di lavoro sensibili ai prezzi.
curl -X POST "https://<ACCOUNT-NAME>.openai.azure.com/openai/fine_tuning/jobs?api-version=2025-04-01-preview" -H "Content-Type: application/json" -H "api-key: <API-KEY>" -d "{"model": "gpt-4.1", "training_file": "<FILE_ID>", "hyperparameters": {"prompt_loss_weight": 0.1}, "trainingType": "developerTier"}"
Controllare lo stato del modello personalizzato
Dopo aver avviato un processo di ottimizzazione, il completamento può richiedere del tempo. Il processo potrebbe essere in coda dietro altri processi nel sistema. Il training del modello può richiedere minuti o ore, a seconda delle dimensioni del modello e del set di dati. L'esempio seguente usa l'API REST per controllare lo stato del processo di ottimizzazione. L'esempio recupera informazioni sul processo usando l'ID processo restituito dall'esempio precedente:
curl -X GET $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs/<YOUR-JOB-ID> \
-H "api-key: $AZURE_OPENAI_API_KEY"
Sospendere e riprendere
Durante il training è possibile visualizzare i log e le metriche e sospendere il processo in base alle esigenze. La sospensione può essere utile se le metriche non sono convergenti o se si ritiene che il modello non stia imparando al ritmo corretto. Una volta sospeso il processo di addestramento, verrà creato un checkpoint distribuibile al termine delle valutazioni di sicurezza. Questo checkpoint è disponibile per la distribuzione e l'utilizzo per l'inferenza o per riprendere il processo fino al completamento. L'operazione di sospensione è applicabile solo per i processi sottoposti a training per almeno un passaggio e che siano in stato In esecuzione.
Pausa
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs/{fine_tuning_job_id}/pause \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Riprendi
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs/{fine_tuning_job_id}/resume \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Elencare gli eventi di ottimizzazione
Per esaminare i singoli eventi di ottimizzazione generati durante il training:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs/{fine_tuning_job_id}/events \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Copia modello (anteprima)
È ora possibile copiare un modello con checkpoint ottimizzato da un'area a un'altra, in sottoscrizioni differenti, ma all'interno dello stesso tenant. Il processo usa API dedicate per garantire trasferimenti efficienti e sicuri. Questa funzionalità è attualmente disponibile solo con l'API e non tramite il portale Fonderia. Dopo aver copiato il modello dall'area A all'area B, è possibile ottimizzare continuamente il modello nell'area B e distribuire il modello da questa posizione.
Annotazioni
L'eliminazione del checkpoint del modello nell'area di origine non causerà l'eliminazione del modello nell'area di destinazione. Per eliminare il modello in entrambe le aree dopo che è stato copiato, è necessario eliminare il modello separatamente in ogni area.
Prerequisiti
- La risorsa/l'account di destinazione deve avere almeno un processo di ottimizzazione.
- La risorsa/l'account di destinazione non deve disabilitare l'accesso alla rete pubblica. (almeno durante l'invio della richiesta di copia).
- È possibile copiare nell'account di destinazione solo se l'account che avvia la copia dispone di autorizzazioni sufficienti per accedere all'account di destinazione.
Configurazione delle autorizzazioni
- Creare un'identità gestita assegnata dall'utente.
- Assegna il ruolo utente di Azure AI all'identità gestita assegnata dall'utente sulla risorsa o sull'account di destinazione.
- Assegnare l'identità gestita assegnata dall'utente all'account della risorsa di origine.
Copiare il modello
curl --request POST \
--url 'https://<aoai-resource>.openai.azure.com/openai/v1/fine_tuning/jobs/<ftjob>/checkpoints/<checkpoint-name>/copy' \
--header 'Content-Type: application/json' \
--header 'api-key: <api-key>' \
--header 'aoai-copy-ft-checkpoints: preview' \
--data '{
"destinationResourceId": "<resourceId>",
"region": "<region>"
}'
Poiché si tratta di un'operazione a esecuzione prolungata, controllare lo stato della copia del modello ottimizzata specificando l'ID checkpoint dell'account di origine usato nella chiamata POST.
Verificare lo stato della copia
curl --request GET \
--url 'https://<aoai-resource>.openai.azure.com//openai/v1/fine_tuning/jobs/<ftjob>/checkpoints/<checkpoint-name>/copy' \
--header 'Content-Type: application/json' \
--header 'api-key: <api-key>' \
--header 'aoai-copy-ft-checkpoints: preview'
Annotazioni
Quando si copia un checkpoint da un account di origine, lo stesso nome del checkpoint viene mantenuto nell'account di destinazione. Assicurarsi di usare lo stesso nome per l'ottimizzazione, la distribuzione o per qualsiasi altra operazione nell'account di destinazione. Questo checkpoint non viene visualizzato nell'interfaccia utente o nell'API list checkpoints .
Punti di controllo
Al completamento di ogni periodo di training, viene generato un checkpoint. Un checkpoint è una versione completamente funzionale di un modello che può essere distribuita e usata come modello di destinazione per i processi di ottimizzazione successivi. I checkpoint possono essere particolarmente utili, in quanto possono fornire snapshot prima dell'overfitting. Al termine di un processo di ottimizzazione, le tre versioni più recenti del modello saranno disponibili per la distribuzione. L'epoca finale sarà rappresentata dal modello ottimizzato, le due epoche precedenti saranno disponibili come checkpoint.
È possibile eseguire il comando list checkpoints per recuperare l'elenco dei checkpoint associati a un singolo processo di ottimizzazione:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs/{fine_tuning_job_id}/checkpoints \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Analizzare il modello personalizzato
Azure OpenAI collega un file di risultato, denominato results.csv a ogni processo di ottimizzazione dopo il completamento. È possibile usare il file dei risultati per analizzare le prestazioni del training e convalidare del modello personalizzato. L'ID file per il file dei risultati è elencato per ogni modello personalizzato ed è possibile usare l’API REST per recuperare l'ID file e scaricare il file di risultato per l'analisi.
L'esempio Python seguente usa l'API REST per recuperare l'ID file del primo file dei risultati allegato al processo di ottimizzazione per il modello personalizzato e quindi scaricare il file nella directory di lavoro per l'analisi.
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs/<JOB_ID>" \
-H "api-key: $AZURE_OPENAI_API_KEY")
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/v1/files/<RESULT_FILE_ID>/content" \
-H "api-key: $AZURE_OPENAI_API_KEY" > <RESULT_FILENAME>
Il file dei risultati è un file CSV contenente una riga di intestazione e una riga per ogni passaggio di training eseguito dal processo di ottimizzazione. Il file dei risultati contiene le colonne seguenti:
| Nome della colonna | Descrizione |
|---|---|
step |
Numero del passaggio di training. Un passaggio di training rappresenta un singolo passaggio, avanti e indietro, in un batch di dati di training. |
train_loss |
Perdita per il batch di training. |
train_mean_token_accuracy |
Percentuale di token nel batch di training stimati correttamente dal modello. Ad esempio, se le dimensioni del batch sono impostate su 3 e i dati contengono completamenti [[1, 2], [0, 5], [4, 2]], questo valore viene impostato su 0,83 (5 di 6) se il modello ha previsto [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
Perdita per il batch di convalida. |
validation_mean_token_accuracy |
Percentuale di token nel batch di convalida stimati correttamente dal modello. Ad esempio, se le dimensioni del batch sono impostate su 3 e i dati contengono completamenti [[1, 2], [0, 5], [4, 2]], questo valore viene impostato su 0,83 (5 di 6) se il modello ha previsto [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
Perdita di convalida calcolata alla fine di ogni epoca. Quando il training va bene, la perdita dovrebbe diminuire. |
full_valid_mean_token_accuracy |
Accuratezza del token media valida calcolata alla fine di ogni epoca. Quando il training va bene, l'accuratezza del token dovrebbe aumentare. |
È anche possibile visualizzare i dati nel file results.csv come grafici nel portale Foundry. Selezionare il collegamento per il modello sottoposto a training; verranno visualizzati tre grafici: perdita, accuratezza del token media e accuratezza del token. Se sono stati forniti dati di convalida, entrambi i set di dati verranno visualizzati nello stesso tracciato.
Cercare la perdita da ridurre nel tempo e l'accuratezza da aumentare. Se viene visualizzata una divergenza tra i dati di training e di convalida, ciò potrebbe indicare un overfitting. Provare a eseguire il training con meno periodi o a un moltiplicatore di frequenza di trading più piccolo.
Distribuire un modello ottimizzato
Dopo aver soddisfatto le metriche del processo di ottimizzazione, oppure si vuole semplicemente passare all'inferenza, è necessario distribuire il modello.
Se si esegue la distribuzione per un'ulteriore convalida, valutare la possibilità di eseguire la distribuzione per i test usando una distribuzione per sviluppatori.
Se si è pronti per la distribuzione per la produzione o si hanno specifiche esigenze di residenza dei dati, seguire la guida alla distribuzione.
| Variabile | Definizione |
|---|---|
| token | Esistono diversi modi per generare un token di autorizzazione. Il metodo più semplice per i test iniziali consiste nell'avviare Cloud Shell dal portale di Azure. Quindi eseguire az account get-access-token. È possibile usare questo token come token di autorizzazione temporaneo per il test dell'API. È consigliabile archiviare questo valore in una nuova variabile di ambiente. |
| abbonamento | ID sottoscrizione per la risorsa Azure OpenAI associata. |
| gruppo di risorse | Nome del gruppo di risorse per la risorsa Azure OpenAI. |
| nome_risorsa | Nome della risorsa di Azure OpenAI. |
| model_deployment_name | Nome personalizzato per la nuova distribuzione del modello ottimizzata. Questo è il nome a cui verrà fatto riferimento nel codice quando si effettuano chiamate di completamento della chat. |
| fine_tuned_model | Recuperare questo valore dai risultati del processo di ottimizzazione nel passaggio precedente. Sarà simile a gpt-4.1-2025-04-14.ft-b044a9d3cf9c4228b5d393567f693b83. Sarà necessario aggiungere tale valore al deploy_data json. In alternativa, è anche possibile distribuire un checkpoint passando l'ID del checkpoint, che verrà visualizzato nel formato ftchkpt-e559c011ecc04fc68eaa339d8227d02d |
curl -X POST "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>?api-version=2024-10-21" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1"
}
}
}'
Altre informazioni sulla distribuzione tra aree e sull'uso del modello distribuito sono disponibili qui.
Ottimizzazione continua
Dopo aver creato un modello ottimizzato, si può desiderare di continuare a perfezionare il modello nel tempo tramite un'ulteriore ottimizzazione. L'ottimizzazione continua è il processo iterativo per selezionare un modello già ottimizzato come modello di base e ottimizzarlo ulteriormente sui nuovi set di esempi di training.
Annotazioni
L'ottimizzazione continua è supportata solo per i modelli OpenAI.
Per eseguire l'ottimizzazione su un modello ottimizzato in precedenza, è necessario usare lo stesso processo descritto in Creare un modello personalizzato, ma invece di specificare il nome di un modello di base generico, è necessario specificare l'ID del modello già ottimizzato. L'ID modello ottimizzato è simile al seguente gpt-4.1-2025-04-14.ft-5fd1918ee65d4cd38a5dcf6835066ed7
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-4.1-2025-04-14.ft-5fd1918ee65d4cd38a5dcf6835066ed7",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"suffix": "<additional text used to help identify fine-tuned models>"
}'
È anche consigliabile includere il parametro suffix per semplificare la distinzione tra iterazioni differenti del modello ottimizzato.
suffix accetta una stringa ed è impostato per identificare il modello ottimizzato. Il suffisso può contenere fino a 40 caratteri (a-z, A-Z, 0-9 e _) che verranno aggiunti al nome del modello ottimizzato.
Se non si è certi dell'ID del modello ottimizzato, queste informazioni sono disponibili nella pagina Modelli di Foundry oppure è possibile generare un elenco di modelli per una determinata risorsa OpenAI di Azure usando l'API REST.
Pulire le distribuzioni, i modelli personalizzati e i file di training
Al termine del modello personalizzato, è possibile eliminare la distribuzione e il modello. È anche possibile eliminare i file di training e convalida caricati nel servizio, se necessario.
Eliminare la distribuzione del modello
È possibile usare vari metodi per eliminare la distribuzione per il modello personalizzato:
Eliminare il modello personalizzato
Analogamente, è possibile usare vari metodi per eliminare il modello personalizzato:
Annotazioni
Non è possibile eliminare un modello personalizzato se ha una distribuzione esistente. Prima di poter eliminare il modello personalizzato, è necessario eliminare la distribuzione del modello.
Eliminare i file di training
Facoltativamente, è possibile eliminare i file di training e convalida caricati per il training e i file di risultato generati durante il training dall'abbonamento a Azure OpenAI. È possibile usare i metodi seguenti per eliminare i file di training, convalida e risultato:
Nel portale di Microsoft Foundry sono disponibili due esperienze di ottimizzazione univoche:
- Visualizzazione hub/progetto: supporta modelli di ottimizzazione da più provider, tra cui Azure OpenAI, Meta Llama, Microsoft Phi e così via.
- Visualizzazione incentrata su Azure OpenAI: supporta solo l'ottimizzazione dei modelli di Azure OpenAI, ma supporta funzionalità aggiuntive, ad esempio l'integrazione dell'anteprima di Weights & Biases (W&B).
Se si ottimizzano solo i modelli di Azure OpenAI, è consigliabile usare l'esperienza di ottimizzazione orientata ad Azure OpenAI disponibile passando a https://ai.azure.com/resource/overview.
Importante
Gli elementi contrassegnati (anteprima) in questo articolo sono attualmente disponibili in anteprima pubblica. Questa anteprima viene fornita senza un contratto di servizio e non è consigliabile per i carichi di lavoro di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Prerequisiti
- Leggere la Guida Quando usare l'ottimizzazione di Azure OpenAI.
- Una sottoscrizione di Azure. Creane uno gratis.
- Una risorsa Azure OpenAI che si trova in un'area che supporta l'ottimizzazione del modello Azure OpenAI. Controllare la tabella di riepilogo del modello e la disponibilità dell'area per l'elenco dei modelli disponibili in base all'area e alla funzionalità supportata. Per altre informazioni, vedere Creare una risorsa e distribuire un modello con Azure OpenAI.
- Per ottimizzare l'accesso è necessario il ruolo Utente AI di Azure.
- Se non si ha già accesso alla quota di visualizzazione e si distribuiscono modelli nel portale di Microsoft Foundry, saranno necessarie autorizzazioni aggiuntive.
Modelli supportati
Consultare la pagina dei modelli per verificare quali aree supportano attualmente l'ottimizzazione.
In alternativa, è possibile ottimizzare un modello ottimizzato in precedenza, formattato come base-model.ft-{jobid}.
Esaminare il flusso di lavoro per il portale foundry
Dedicare un istante a rivedere il flusso di lavoro di ottimizzazione per l'uso del portale Fonderia:
- Preparare i dati di training e convalida.
- Usare la finestra di dialogo Crea un modello ottimizzato nel portale di Foundry per eseguire il training del modello personalizzato.
- Selezionare un metodo di training.
- Selezionare un modello di base.
- Scegliere il tipo di training
- Scegliere i dati del training.
- Facoltativamente, scegliere i dati di convalida.
- Facoltativamente, configurare i parametri delle attività per il processo di ottimizzazione.
- Facoltativamente, abilitare la distribuzione automatica per il modello personalizzato risultante.
- Esaminare le scelte ed eseguire il training del nuovo modello personalizzato.
- Controllare lo stato del modello personalizzato ottimizzato.
- Distribuire il modello personalizzato da usare.
- Usare il modello personalizzato.
- Facoltativamente, analizzare prestazioni e adattamento del modello personalizzato.
Preparare i dati di training e convalida
I dati di training e i set di dati di convalida sono costituiti da esempi di input e output per il modo in cui si vuole eseguire il modello.
I dati di training e convalida che utilizzi devono essere formattati come documento JSON Lines (JSONL) e nel formato conversazionale utilizzato dall'API Chat completions.
È in genere consigliabile usare le istruzioni e i suggerimenti che hanno funzionato meglio in ogni esempio di training. Ciò consentirà di ottenere i risultati migliori, soprattutto se si hanno meno di un centinaio di esempi.
Formato del file di esempio
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Formato di file di chat a più turni in Azure OpenAI
Sono inoltre supportati diversi turn di una conversazione in una singola riga del file di training jsonl. Per ignorare l'ottimizzazione su messaggi di assistente specifici, aggiungere la coppia di valori di chiave weight facoltativa. Attualmente è possibile impostare weight su 0 o 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Completamento della chat con Visione
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Oltre al formato JSONL, i file di dati di training e convalida devono essere codificati in UTF-8 e includere un byte order mark (BOM). Il file deve avere dimensioni inferiori a 512 MB.
Considerazioni sulle dimensioni dei set di dati
Più esempi di training sono disponibili, meglio è. L'ottimizzazione dei processi non procederà senza almeno 10 esempi di training, ma un numero così ridotto non è sufficiente per influenzare notevolmente le risposte del modello. È consigliabile fornire centinaia, se non migliaia, di esempi di training per avere successo. È consigliabile iniziare con 50 dati di training ben creati.
In generale, il raddoppio delle dimensioni del set di dati può comportare un aumento lineare della qualità del modello. Tenere tuttavia presente che gli esempi di bassa qualità possono influire negativamente sulle prestazioni. Se si esegue il training del modello su una grande quantità di dati interni, senza prima eliminare il set di dati solo degli esempi di qualità più elevati, è possibile ottenere un modello che comporta prestazioni molto peggiori del previsto.
Creazione di un modello ottimizzato
Il portale di Foundry fornisce la finestra di dialogo Crea un modello ottimizzato , quindi in un'unica posizione è possibile creare ed eseguire facilmente il training di un modello ottimizzato per la risorsa di Azure.
Passare al portale foundry all'indirizzo https://ai.azure.com/ e accedere con le credenziali che hanno accesso alla risorsa OpenAI di Azure. Durante il flusso di lavoro di accesso, selezionare la directory appropriata, la sottoscrizione di Azure e la risorsa OpenAI di Azure.
Nel portale di Foundry passare al riquadro Strumenti > Ottimizzazione e selezionare Ottimizza modello.
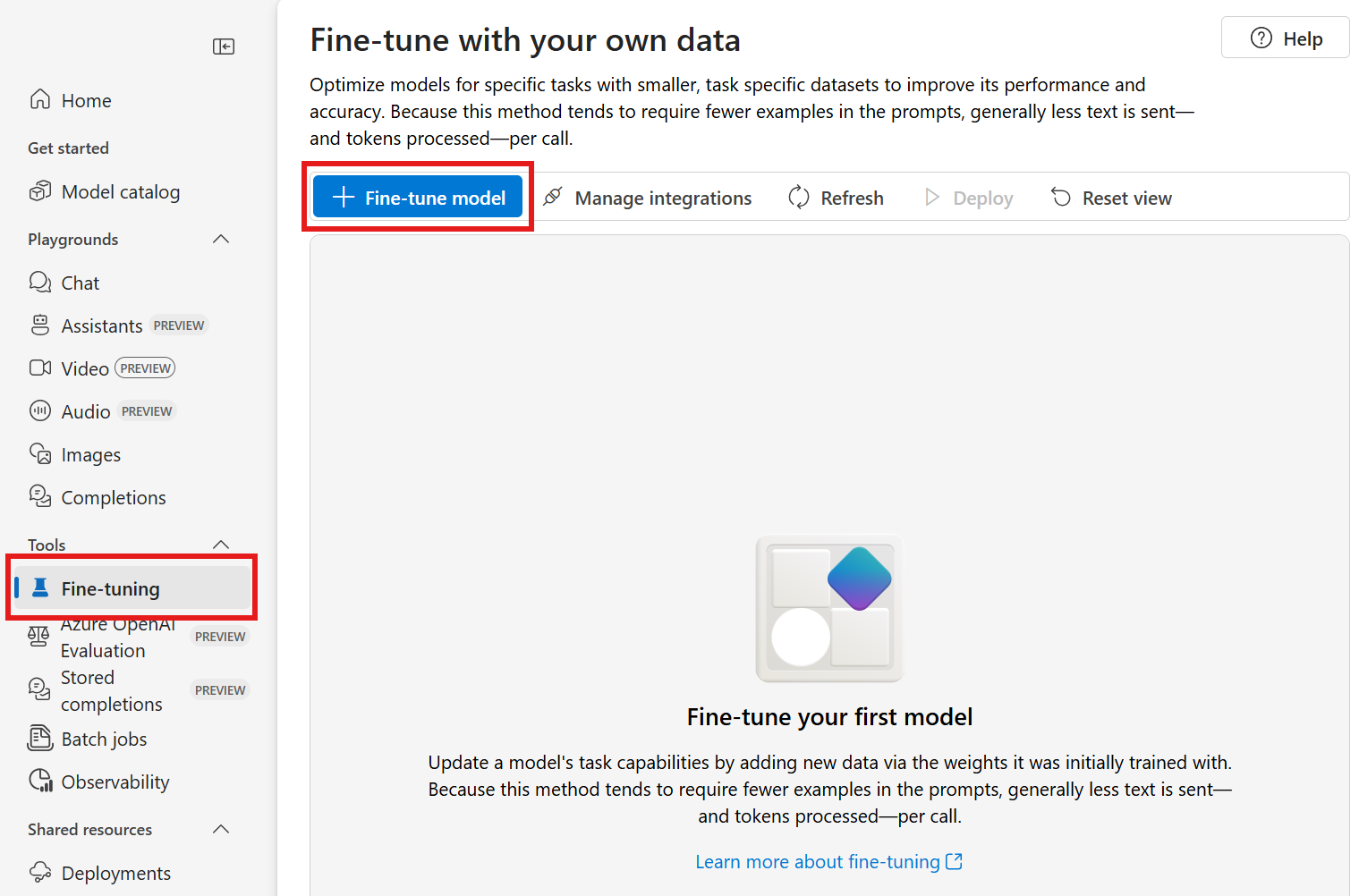
Selezionare un modello da ottimizzare e quindi selezionare Avanti per continuare.
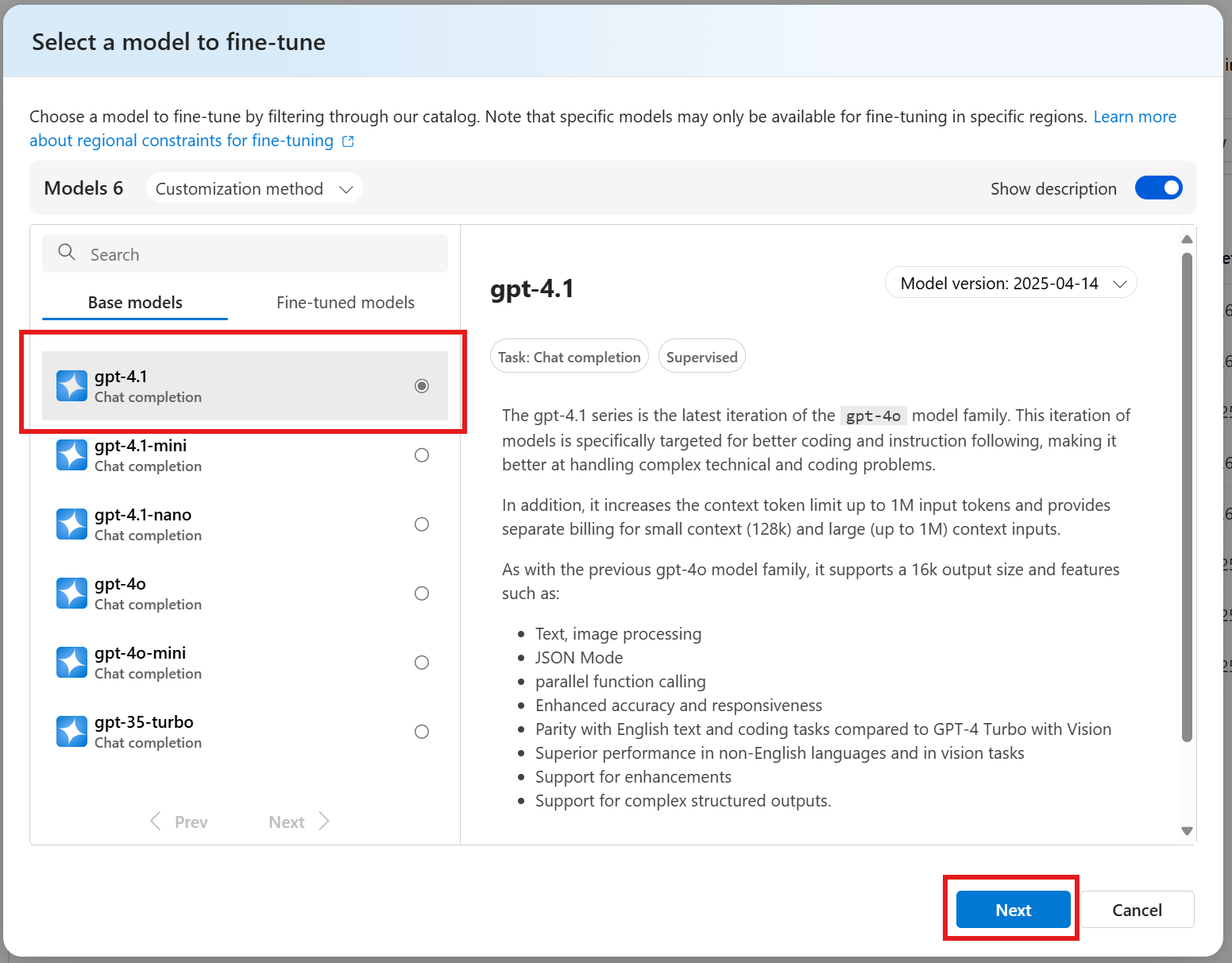

Verrà visualizzata la finestra di dialogo Crea un modello ottimizzato .

Scegliere il metodo di training
Il primo passaggio consiste nel confermare la scelta del modello e il metodo di training. Non tutti i modelli supportano tutti i metodi di training.
- Ottimizzazione supervisionata (SFT): supportata da tutti i modelli che non richiedono ragionamento.
- Ottimizzazione delle preferenze dirette (anteprima) (DPO): supportato da GPT-4o.
- Ottimizzazione per Rinforzo (Anteprima) (RFT): supportata da modelli di ragionamento come o4-mini.
Quando si seleziona il modello, è anche possibile selezionare un modello ottimizzato in precedenza.
Scegliere il tipo di training
Foundry offre tre livelli di training progettati per soddisfare diverse esigenze dei clienti:
Livello di formazione standard
Offre capacità dedicata per l'ottimizzazione con prestazioni prevedibili e contratti di servizio. Ideale per i carichi di lavoro di produzione che richiedono una velocità effettiva garantita.
Livello standard globale di formazione
La Formazione Globale amplia la portata della personalizzazione del modello con i prezzi più convenienti delle altre offerte Globali. Non offre la residenza dei dati. Se è necessaria la residenza dei dati, consultare le aree elencate sulla disponibilità del modello per il modello scelto.
I dati di training e i pesi del modello risultanti possono essere copiati in un'altra area di Azure.
- Addestrare i modelli OpenAI più recenti da oltre una dozzina di aree OpenAI di Azure.
- Trarre vantaggio dalle tariffe di addestramento per token inferiori rispetto al livello Standard.
Livello di formazione per sviluppatori
Opzione conveniente che usa capacità inattiva per carichi di lavoro non urgenti o esplorativi.
I processi in questo livello possono essere annullati e ripresi in un secondo momento, rendendoli ideali per la sperimentazione e i casi d'uso sensibili ai costi.
Scegli i dati di allenamento
Il passaggio successivo consiste nel scegliere i dati di training preparati esistenti o caricare nuovi dati di training preparati da usare durante la personalizzazione del modello selezionando Aggiungi dati di training.
La finestra di dialogo Dati di training visualizza tutti i set di dati caricati in precedenza esistenti e offre anche opzioni per caricare nuovi dati di training.
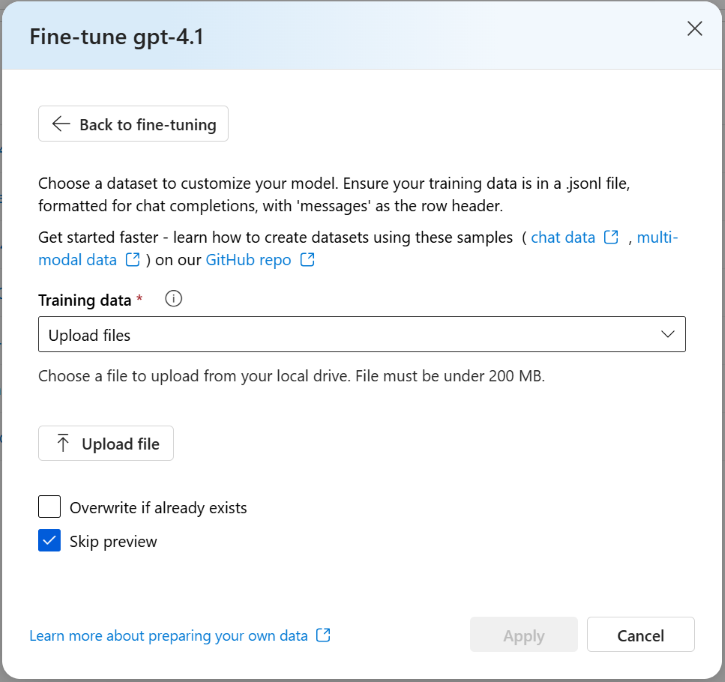
Se i dati di training sono già caricati nel servizio, selezionare File dalla risorsa di intelligenza artificiale connessa.
- Selezionare il file dall'elenco a discesa visualizzato.
Per caricare nuovi dati di training, usare una delle opzioni seguenti:
- Selezionare Carica file per caricare i dati di training da un file locale.
- Selezionare BLOB di Azure o altri percorsi Web condivisi per importare i dati di training dal BLOB di Azure o da un altro percorso Web condiviso.
Per i file di dati di grandi dimensioni, è consigliabile eseguire l'importazione da un archivio BLOB di Azure. I file di grandi dimensioni possono diventare instabili quando vengono caricati tramite moduli in più parti, perché le richieste sono atomiche e non possono essere ritentate o riprese. Per altre informazioni su Archiviazione BLOB di Azure, vedere Che cos'è l'archiviazione BLOB di Azure?
Annotazioni
I file di dati di training devono essere formattati come file JSONL, codificati in UTF-8 con un byte order mark (BOM). Il file deve avere dimensioni inferiori a 512 MB.
Scegliere i dati di convalida (facoltativo)
Se si dispone di un set di dati di convalida, selezionare Aggiungi dati di training. È possibile scegliere i dati di convalida preparati esistenti o caricare nuovi dati di convalida preparati da usare durante la personalizzazione del modello.
La finestra di dialogo Dati di convalida visualizza tutti i set di dati di training e convalida caricati in precedenza esistenti e fornisce opzioni in base alle quali è possibile caricare nuovi dati di convalida.
Screenshot del pannello Dati di convalida per la procedura guidata per la creazione di un modello personalizzato nel portale di Foundry.
Se i dati di convalida sono già caricati nel servizio, selezionare Scegli set di dati.
- Selezionare il file nell'elenco visualizzato nel riquadro Dati di convalida.
Per caricare nuovi dati di convalida, usare una delle opzioni seguenti:
- Selezionare File locale per caricare i dati di convalida da un file locale.
- Selezionare BLOB di Azure o altri percorsi Web condivisi per importare i dati di convalida dal BLOB di Azure o da un altro percorso Web condiviso.
Per i file di dati di grandi dimensioni, è consigliabile eseguire l'importazione da un archivio BLOB di Azure. I file di grandi dimensioni possono diventare instabili quando vengono caricati tramite moduli in più parti, perché le richieste sono atomiche e non possono essere ritentate o riprese.
Annotazioni
Come i file di dati di training, anche i file di dati di convalida devono essere formattati come file JSONL, codificati in UTF-8 con un byte order mark (BOM) e devono avere dimensioni inferiori a 200 MB. Il file deve avere dimensioni inferiori a 512 MB.
Rendere il modello identificabile (facoltativo)
È anche consigliabile includere un suffix parametro per semplificare la distinzione tra iterazioni diverse del modello ottimizzato. Un suffix accetta una stringa di un massimo di 18 caratteri e viene usata quando si assegna un nome al modello ottimizzato risultante.
Configurare i parametri di training (facoltativo)
È possibile fornire un seme facoltativo e regolare ulteriori iperparametri.
Il seme controlla la riproducibilità del compito. Il passaggio degli stessi parametri di inizializzazione e processo dovrebbe produrre gli stessi risultati, ma in rari casi può differire. Se non viene specificato un seme, ne verrà generato uno in modo casuale.
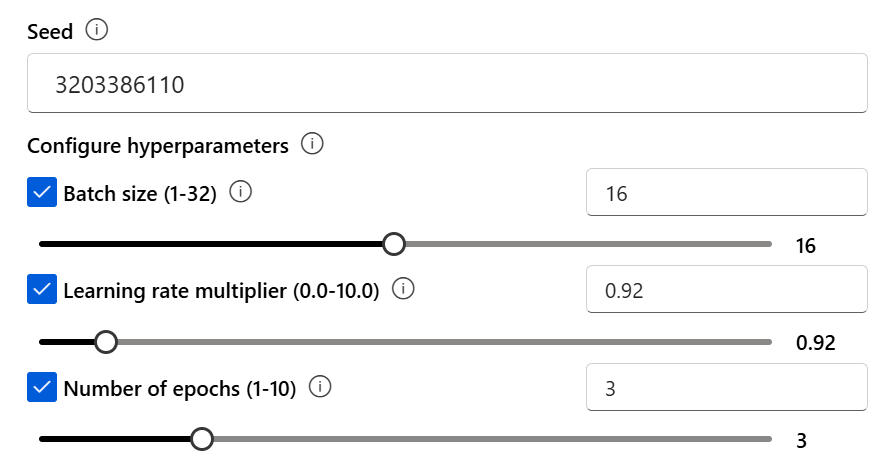
Gli iperparametri seguenti sono disponibili per l'ottimizzazione tramite il portale foundry:
| Nome | Tipo | Descrizione |
|---|---|---|
| Dimensioni del batch | integer | Dimensioni del batch da usare per il training. Le dimensioni del batch sono il numero di esempi di training usati per eseguire il training di un singolo passaggio avanti e indietro. In generale, è stato rilevato che le dimensioni dei batch più grandi tendono a funzionare meglio per set di dati di dimensioni maggiori. Il valore predefinito e il valore massimo per questa proprietà sono specifici di un modello di base. Una dimensione batch maggiore indica che i parametri del modello vengono aggiornati meno frequentemente, ma con varianza inferiore. |
| Moltiplicatore della frequenza di apprendimento | d'acquisto | Moltiplicatore della frequenza di apprendimento da usare per il training. La velocità di apprendimento di ottimizzazione è la velocità di apprendimento originale usata per il training preliminare moltiplicata per questo valore. I tassi di apprendimento più elevati tendono a ottenere prestazioni migliori con dimensioni batch maggiori. È consigliabile provare con i valori compresi nell'intervallo da 0,02 a 0,2 per vedere quali risultati producono i risultati migliori. Una frequenza di apprendimento più piccola può essere utile per evitare l'overfitting. |
| Numero di periodi | integer | Numero di periodi per cui eseguire il training del modello. Un periodo fa riferimento a un ciclo completo attraverso il set di dati di training. |
Abilitare la distribuzione automatica (facoltativo)
Per risparmiare tempo, è possibile abilitare facoltativamente la distribuzione automatica per il modello risultante. Se il training viene completato correttamente, il modello verrà distribuito usando il tipo di distribuzione selezionato. La distribuzione verrà denominata in base al nome univoco generato per il modello personalizzato e al suffisso facoltativo specificato in precedenza.
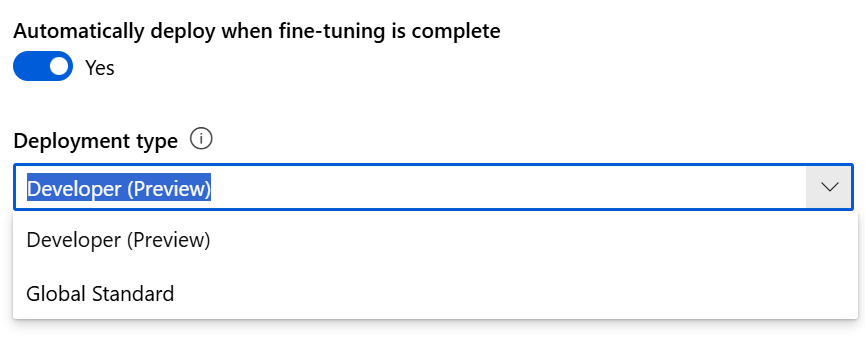
Annotazioni
Per la distribuzione automatica sono attualmente supportate solo le distribuzioni standard globali e per gli sviluppatori. Nessuna di queste opzioni fornisce la residenza dei dati. Per altri dettagli, vedere la documentazione sul tipo di distribuzione .
Esaminare le scelte ed eseguire il training del modello
Esaminare le scelte effettuate e selezionare Invia per avviare il training del nuovo modello ottimizzato.
Controllare lo stato del modello personalizzato
Dopo aver inviato il processo di ottimizzazione, verrà visualizzata una pagina con i dettagli sul modello ottimizzato. È possibile trovare lo stato e altre informazioni sul modello adattato nella pagina Ottimizzazione del portale Foundry.
Il processo potrebbe essere in coda dietro altri processi nel sistema. Il training del modello può richiedere minuti o ore, a seconda delle dimensioni del modello e del set di dati.
Punti di controllo
Al completamento di ogni periodo di training, viene generato un checkpoint. Un checkpoint è una versione completamente funzionale di un modello che può essere distribuita e usata come modello di destinazione per i processi di ottimizzazione successivi. I checkpoint possono essere particolarmente utili, in quanto possono fornire snapshot prima dell'overfitting. Al termine di un processo di ottimizzazione, le tre versioni più recenti del modello saranno disponibili per la distribuzione. È possibile copiare punti di controllo tra risorse e sottoscrizioni attraverso l'API REST.
Sospendere e riprendere
È possibile tenere traccia dello stato di avanzamento in entrambe le visualizzazioni di affinamento del portale Fonderia. Si noterà che il processo passa attraverso gli stessi stati dei normali processi di ottimizzazione (in coda, in esecuzione, completato).
È anche possibile esaminare i file dei risultati durante l'addestramento per dare un'occhiata ai progressi e vedere se l'addestramento sta procedendo come previsto.
Annotazioni
Durante il training è possibile visualizzare i log e le metriche e sospendere il processo in base alle esigenze. La sospensione può essere utile se le metriche non sono convergenti o se si ritiene che il modello non stia imparando al ritmo corretto. Una volta sospeso il processo di addestramento, verrà creato un checkpoint distribuibile al termine delle valutazioni di sicurezza. Questo checkpoint è disponibile per la distribuzione e l'utilizzo per l'inferenza o per riprendere il processo fino al completamento. L'operazione di sospensione è applicabile solo per i processi sottoposti a training per almeno un passaggio e che siano in stato In esecuzione.

Analizzare il modello personalizzato
Azure OpenAI collega un file di risultato, denominato results.csv a ogni processo di ottimizzazione dopo il completamento. È possibile usare il file dei risultati per analizzare le prestazioni del training e convalidare del modello personalizzato. L'ID file per il file di risultato è elencato per ogni modello personalizzato nella colonna ID file risultato nel riquadro Modelli per il portale di Foundry. È possibile usare l'ID file per identificare e scaricare il file di risultato dal riquadro File di dati del portale foundry.
Il file dei risultati è un file CSV contenente una riga di intestazione e una riga per ogni passaggio di training eseguito dal processo di ottimizzazione. Il file dei risultati contiene le colonne seguenti:
| Nome della colonna | Descrizione |
|---|---|
step |
Numero del passaggio di training. Un passaggio di training rappresenta un singolo passaggio, avanti e indietro, in un batch di dati di training. |
train_loss |
Perdita per il batch di training. |
train_mean_token_accuracy |
Percentuale di token nel batch di training stimati correttamente dal modello. Ad esempio, se le dimensioni del batch sono impostate su 3 e i dati contengono completamenti [[1, 2], [0, 5], [4, 2]], questo valore viene impostato su 0,83 (5 di 6) se il modello ha previsto [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
Perdita per il batch di convalida. |
validation_mean_token_accuracy |
Percentuale di token nel batch di convalida stimati correttamente dal modello. Ad esempio, se le dimensioni del batch sono impostate su 3 e i dati contengono completamenti [[1, 2], [0, 5], [4, 2]], questo valore viene impostato su 0,83 (5 di 6) se il modello ha previsto [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
Perdita di convalida calcolata alla fine di ogni epoca. Quando il training va bene, la perdita dovrebbe diminuire. |
full_valid_mean_token_accuracy |
Accuratezza del token media valida calcolata alla fine di ogni epoca. Quando il training va bene, l'accuratezza del token dovrebbe aumentare. |
È anche possibile visualizzare i dati nel file results.csv come grafici nel portale Foundry. Selezionare il collegamento per il modello sottoposto a training; verranno visualizzati tre grafici: perdita, accuratezza del token media e accuratezza del token. Se sono stati forniti dati di convalida, entrambi i set di dati verranno visualizzati nello stesso tracciato.
Cercare la perdita da ridurre nel tempo e l'accuratezza da aumentare. Se viene visualizzata una divergenza tra i dati di training e di convalida, ciò potrebbe indicare un overfitting. Provare a eseguire il training con meno periodi o a un moltiplicatore di frequenza di trading più piccolo.
Distribuire un modello ottimizzato
Dopo essere stati soddisfatti delle metriche del processo di ottimizzazione o semplicemente si vuole passare all'inferenza, è necessario distribuire il modello.
Se si esegue la distribuzione per un'ulteriore convalida, valutare la possibilità di eseguire la distribuzione per i test usando una distribuzione per sviluppatori.
Se si è pronti per la distribuzione per la produzione o si hanno specifiche esigenze di residenza dei dati, seguire la guida alla distribuzione.
Usare un modello ottimizzato per la distribuzione
Dopo la distribuzione del modello ottimizzato, è possibile usarlo come qualsiasi altro modello distribuito. È possibile usare Playground in Foundry per sperimentare la nuova distribuzione. È anche possibile usare l'API REST per chiamare il modello ottimizzato dall'applicazione. È anche possibile iniziare a usare questo nuovo modello ottimizzato nel prompt flow per compilare l'applicazione di intelligenza artificiale generativa.
Annotazioni
Per i modelli di chat, il messaggio di sistema usato per guidare il modello ottimizzato ( distribuito o disponibile per i test nel playground) deve corrispondere al messaggio di sistema usato per il training. Se si usa un messaggio di sistema differente, il modello potrebbe non funzionare come previsto.
Ottimizzazione continua
Dopo aver creato un modello ottimizzato, è possibile continuare a perfezionare il modello nel tempo tramite un'ulteriore ottimizzazione. L'ottimizzazione continua è il processo iterativo per selezionare un modello già ottimizzato come modello di base e ottimizzarlo ulteriormente sui nuovi set di esempi di training.
Per eseguire l'ottimizzazione su un modello ottimizzato in precedenza, è necessario usare lo stesso processo descritto nella creazione di un modello ottimizzato, ma invece di specificare il nome di un modello di base generico, è necessario specificare il modello già ottimizzato. Un modello personalizzato ottimizzato sarà simile al seguente gpt-4o-2024-08-06.ft-d93dda6110004b4da3472d96f4dd4777-ft

Pulire le distribuzioni, i modelli personalizzati e i file di training
Al termine del modello personalizzato, è possibile eliminare la distribuzione e il modello. È anche possibile eliminare i file di training e convalida caricati nel servizio, se necessario.
Eliminare la distribuzione del modello
Importante
Dopo la distribuzione di un modello personalizzato, se in qualsiasi momento la distribuzione rimane inattiva per più di quindici (15) giorni, la distribuzione verrà eliminata. La distribuzione di un modello personalizzato è inattiva se il modello è stato distribuito più di quindici (15) giorni prima e non sono stati effettuati completamenti o chiamate di completamento della chat per un periodo continuativo di 15 giorni.
L'eliminazione di una distribuzione inattiva non elimina o influisce sul modello personalizzato sottostante e il modello personalizzato può essere ridistribuito in qualsiasi momento. Come descritto nei prezzi di Azure OpenAI in Modelli di Fonderia Microsoft, ogni modello personalizzato, ottimizzato e distribuito comporta un costo di hosting orario indipendentemente dal fatto che vengano effettuate chiamate di completamento o di completamento della chat al modello. Per altre informazioni sulla pianificazione e la gestione dei costi con Azure OpenAI, vedere le linee guida in Pianificare la gestione dei costi per Azure OpenAI.
È possibile eliminare la distribuzione per il modello personalizzato nel riquadro Distribuzioni nel portale di Foundry. Selezionare la distribuzione da eliminare, quindi selezionare Elimina per eliminare la distribuzione.
Eliminare il modello personalizzato
È possibile eliminare un modello personalizzato nel riquadro Modelli nel portale di Foundry. Selezionare il modello personalizzato da eliminare dalla scheda Modelli personalizzati, quindi selezionare Elimina per eliminare il modello personalizzato.
Annotazioni
Non è possibile eliminare un modello personalizzato se ha una distribuzione esistente. Prima di poter eliminare il modello personalizzato, è necessario eliminare la distribuzione del modello.
Eliminare i file di training
Facoltativamente, è possibile eliminare i file di training e convalida caricati per il training e i file di risultato generati durante il training nel riquadro Dati di gestione>e indici nel portale di Foundry. Selezionare il file da eliminare, quindi selezionare Elimina per eliminare il file.







Prerequisiti
- Leggere la Guida Quando usare l'ottimizzazione di Azure OpenAI.
- Una sottoscrizione di Azure. Creane uno gratis.
- Risorsa Azure OpenAI. Per altre informazioni, vedere Creare una risorsa e distribuire un modello con Azure OpenAI.
- Le librerie Python seguenti:
os,json,requests,openai. - Libreria Python OpenAI.
- Per ottimizzare l'accesso è necessario il ruolo Utente AI di Azure.
- Se non si ha già accesso alla quota di visualizzazione e si distribuiscono modelli nel portale di Microsoft Foundry, saranno necessarie autorizzazioni aggiuntive.
Modelli supportati
Consultare la pagina dei modelli per verificare quali aree supportano attualmente l'ottimizzazione.
In alternativa, è possibile ottimizzare un modello ottimizzato in precedenza, formattato come base-model.ft-{jobid}.
Esaminare il flusso di lavoro per Python SDK
Esaminare il flusso di lavoro di ottimizzazione per l'uso di Python SDK con Azure OpenAI:
- Preparare i dati di training e convalida.
- Selezionare un modello di base.
- Caricare i dati di training.
- Eseguire il training del nuovo modello personalizzato.
- Controllare lo stato del modello personalizzato.
- Distribuire il modello personalizzato per l'uso.
- Usare il modello personalizzato.
- Facoltativamente, analizzare prestazioni e adattamento del modello personalizzato.
Preparare i dati di training e convalida
I dati di training e i set di dati di convalida sono costituiti da esempi di input e output per il modo in cui si vuole eseguire il modello.
I dati di training e convalida che utilizzi devono essere formattati come documento JSON Lines (JSONL) e nel formato conversazionale utilizzato dall'API Chat completions.
Per una procedura dettagliata sull'ottimizzazione, gpt-4o-mini-2024-07-18 vedere l'esercitazione sull'ottimizzazione di Azure OpenAI
Formato del file di esempio
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Formato di file chat multiturn
Sono inoltre supportati diversi turn di una conversazione in una singola riga del file di training jsonl. Per ignorare l'ottimizzazione su messaggi di assistente specifici, aggiungere la coppia di valori di chiave weight facoltativa. Attualmente è possibile impostare weight su 0 o 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Completamento della chat con Visione
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Oltre al formato JSONL, i file di dati di training e convalida devono essere codificati in UTF-8 e includere un byte order mark (BOM). Il file deve avere dimensioni inferiori a 512 MB.
Creare i set di dati di training e convalida
Più esempi di training sono disponibili, meglio è. L'ottimizzazione dei processi non procederà senza almeno 10 esempi di training; tuttavia, un numero così ridotto non è sufficiente per influenzare notevolmente le risposte del modello. È consigliabile fornire centinaia, se non migliaia, di esempi di training per avere successo.
In generale, il raddoppio delle dimensioni del set di dati può comportare un aumento lineare della qualità del modello. Tenere tuttavia presente che gli esempi di bassa qualità possono influire negativamente sulle prestazioni. Se si esegue il training del modello su una grande quantità di dati interni, senza prima eliminare il set di dati solo degli esempi di qualità più elevati, è possibile ottenere un modello che comporta prestazioni molto peggiori del previsto.
Caricare i dati di training
Il passaggio successivo consiste nella scelta dei dati di training preparati esistenti o nel caricamento di nuovi dati di training preparati da usare durante la personalizzazione del modello. Dopo aver preparato i dati di training, è possibile caricare i file nel servizio. Sono disponibili due modi per caricare i dati di training:
Per i file di dati di grandi dimensioni, è consigliabile eseguire l'importazione da un archivio BLOB di Azure. I file di grandi dimensioni possono diventare instabili quando vengono caricati tramite moduli in più parti, perché le richieste sono atomiche e non possono essere ritentate o riprese. Per altre informazioni su Archiviazione BLOB di Azure, vedere Che cos’è l’archiviazione BLOB di Azure?
Annotazioni
I file di dati di training devono essere formattati come file JSONL, codificati in UTF-8 con un byte order mark (BOM). Il file deve avere dimensioni inferiori a 512 MB.
L'esempio Python seguente carica i file di training e convalida locali usando Python SDK e recupera gli ID file restituiti.
import os
from openai import OpenAI
# Load the OpenAI client
client = OpenAI(
api_key = os.getenv("AZURE_OPENAI_API_KEY"),
base_url="https://YOUR-RESOURCE-NAME.openai.azure.com/openai/v1/"
)
# Upload the training and validation dataset files to Microsoft Foundry with the SDK.
training_file_name = 'training_set.jsonl'
validation_file_name = 'validation_set.jsonl'
training_response = client.files.create(file=open(training_file_name, "rb"), purpose="fine-tune")
validation_response = client.files.create(file=open(validation_file_name, "rb"), purpose="fine-tune")
training_file_id = training_response.id
validation_file_id = validation_response.id
print("Training file ID:", training_file_id)
print("Validation file ID:", validation_file_id)
Creare un modello personalizzato
Dopo aver caricato i file di training e convalida, si è pronti per avviare il processo di ottimizzazione.
Il codice Python seguente illustra un esempio di come creare un nuovo processo di ottimizzazione con Python SDK:
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-4.1-2025-04-14", # Enter base model name.
suffix="my-model", # Custom suffix for naming the resulting model. Note that in Microsoft Foundry the model cannot contain dot/period characters.
seed=105, # Seed parameter controls reproducibility of the fine-tuning job. If no seed is specified one will be generated automatically.
extra_body={ "trainingType": "GlobalStandard" } # Change this to your preferred training type. Other options are `Standard` and `Developer`.
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print(response.model_dump_json(indent=2))
Annotazioni
È consigliabile usare il livello Standard globale per il tipo di training, perché offre risparmi sui costi e sfrutta la capacità globale per tempi di accodamento più rapidi. Tuttavia, copia i dati e i pesi fuori dall'area di risorse corrente. Se la residenza dei dati è un requisito, usare un modello che supporta l'addestramento al livello Standard.
È anche possibile passare parametri facoltativi aggiuntivi, ad esempio gli iperparametri, per assumere un maggiore controllo del processo di ottimizzazione. Per il training iniziale, è consigliabile usare le impostazioni predefinite automatiche presenti senza specificare questi parametri.
Gli iperparametri attualmente supportati per i Fine-Tuning con supervisione sono:
| Nome | Tipo | Descrizione |
|---|---|---|
batch_size |
integer | Dimensioni del batch da usare per il training. Le dimensioni del batch sono il numero di esempi di training usati per eseguire il training di un singolo passaggio avanti e indietro. In generale, è stato rilevato che le dimensioni dei batch più grandi tendono a funzionare meglio per set di dati di dimensioni maggiori. Il valore predefinito e il valore massimo per questa proprietà sono specifici di un modello di base. Una dimensione batch maggiore indica che i parametri del modello vengono aggiornati meno frequentemente, ma con varianza inferiore. |
learning_rate_multiplier |
d'acquisto | Moltiplicatore della frequenza di apprendimento da usare per il training. La velocità di apprendimento di ottimizzazione è la velocità di apprendimento originale usata per il training preliminare moltiplicata per questo valore. I tassi di apprendimento più elevati tendono a ottenere prestazioni migliori con dimensioni batch maggiori. È consigliabile provare con i valori compresi nell'intervallo da 0,02 a 0,2 per vedere quali risultati producono i risultati migliori. Un tasso di apprendimento inferiore può essere utile per evitare l'overfitting. |
n_epochs |
integer | Numero di periodi per cui eseguire il training del modello. Un periodo fa riferimento a un ciclo completo attraverso il set di dati di training. |
seed |
integer | Il seme controlla la riproducibilità del lavoro. Il passaggio degli stessi parametri di inizializzazione e processo dovrebbe produrre gli stessi risultati, ma in rari casi può differire. Se non viene specificato un valore di inizializzazione, ne verrà generato uno automaticamente. |
Per impostare iperparametri personalizzati con la versione 1.x dell'API Python OpenAI, specificarli come parte di method:
client.fine_tuning.jobs.create(
training_file="file-abc123",
model="gpt-4.1-2025-04-14",
suffix="my-model",
seed=105,
method={
"type": "supervised", # In this case, the job will be using Supervised Fine Tuning.
"supervised": {
"hyperparameters": {
"n_epochs": 2
}
}
},
extra_body={ "trainingType": "GlobalStandard" }
)
Annotazioni
Per altre informazioni sugli iperparametri supportati, vedere le guide per l'ottimizzazione delle preferenze dirette e l'ottimizzazione del rinforzo .
Tipo di training
Selezionare il livello di training in base al caso d'uso e al budget.
Standard: il training viene eseguito nell'area della risorsa Fonderia attuale, fornendo garanzie di residenza dei dati. Ideale per i carichi di lavoro in cui i dati devono rimanere in un'area specifica.
Globale: offre prezzi più convenienti rispetto a Standard sfruttando la capacità oltre l'area corrente. I dati e i pesi vengono copiati nella regione in cui avviene l'addestramento. Ideale se la residenza dei dati non è una restrizione e si vogliono tempi di coda più rapidi.
Sviluppatore (anteprima): fornisce significativi risparmi sfruttando la capacità inattiva per il training. Non ci sono garanzie di latenza o di accordo sul livello del servizio, quindi i processi in questo livello possono essere sospesi automaticamente e ripresi in un secondo momento. Non esistono garanzie di residenza dei dati. Ideale per la sperimentazione e i carichi di lavoro sensibili ai prezzi.
import openai
from openai import AzureOpenAI
base_uri = "https://<ACCOUNT-NAME>.services.ai.azure.com"
api_key = "<API-KEY>"
api_version = "2025-04-01-preview"
client = AzureOpenAI(
azure_endpoint=base_uri,
api_key=api_key,
api_version=api_version
)
try:
client.fine_tuning.jobs.create(
model="gpt-4.1-mini",
training_file="<FILE-ID>",
extra_body={"trainingType": "developerTier"}
)
except openai.APIConnectionError as e:
print("The server could not be reached")
print(e.__cause__) # an underlying Exception, likely raised within httpx.
except openai.RateLimitError as e:
print("A 429 status code was received; we should back off a bit.")
except openai.APIStatusError as e:
print("Another non-200-range status code was received")
print(e.status_code)
print(e.response)
print(e.body)
Controllare lo stato del processo di ottimizzazione
response = client.fine_tuning.jobs.retrieve(job_id)
print("Job ID:", response.id)
print("Status:", response.status)
print(response.model_dump_json(indent=2))
Elencare gli eventi di ottimizzazione
Per esaminare i singoli eventi di ottimizzazione generati durante il training, potrebbe essere necessario aggiornare la libreria client OpenAI alla versione più recente con per pip install openai --upgrade eseguire questo comando.
response = client.fine_tuning.jobs.list_events(fine_tuning_job_id=job_id, limit=10)
print(response.model_dump_json(indent=2))
Punti di controllo
Al completamento di ogni periodo di training, viene generato un checkpoint. Un checkpoint è una versione completamente funzionale di un modello che può essere distribuita e usata come modello di destinazione per i processi di ottimizzazione successivi. I checkpoint possono essere particolarmente utili, in quanto possono fornire snapshot prima dell'overfitting. Al termine di un processo di ottimizzazione, le tre versioni più recenti del modello saranno disponibili per la distribuzione. L'epoca finale sarà rappresentata dal modello ottimizzato, le due epoche precedenti saranno disponibili come checkpoint.
È possibile eseguire il comando list checkpoints per recuperare l'elenco di checkpoint associati a un singolo processo di ottimizzazione. Per eseguire questo comando potrebbe essere necessario aggiornare la libreria client OpenAI all'ultima versione con pip install openai --upgrade.
response = client.fine_tuning.jobs.checkpoints.list(job_id)
print(response.model_dump_json(indent=2))
Analizzare il modello personalizzato
Azure OpenAI collega un file di risultato, denominato results.csv a ogni processo di ottimizzazione dopo il completamento. È possibile usare il file dei risultati per analizzare le prestazioni del training e convalidare del modello personalizzato. L'ID file per il file dei risultati è elencato per ogni modello personalizzato ed è possibile usare Python SDK per recuperare l'ID file e scaricare il file di risultato per l'analisi.
L'esempio python seguente recupera l'ID file del primo file di risultato allegato al processo di ottimizzazione per il modello personalizzato e quindi usa Python SDK per scaricare il file nella directory di lavoro corrente per l'analisi.
# Retrieve the file ID of the first result file from the fine-tuning job
# for the customized model.
response = client.fine_tuning.jobs.retrieve(job_id)
if response.status == 'succeeded':
result_file_id = response.result_files[0]
retrieve = client.files.retrieve(result_file_id)
# Download the result file.
print(f'Downloading result file: {result_file_id}')
with open(retrieve.filename, "wb") as file:
result = client.files.content(result_file_id).read()
file.write(result)
Il file dei risultati è un file CSV contenente una riga di intestazione e una riga per ogni passaggio di training eseguito dal processo di ottimizzazione. Il file dei risultati contiene le colonne seguenti:
| Nome della colonna | Descrizione |
|---|---|
step |
Numero del passaggio di training. Un passaggio di training rappresenta un singolo passaggio, avanti e indietro, in un batch di dati di training. |
train_loss |
Perdita per il batch di training. |
train_mean_token_accuracy |
Percentuale di token nel batch di training stimati correttamente dal modello. Ad esempio, se le dimensioni del batch sono impostate su 3 e i dati contengono completamenti [[1, 2], [0, 5], [4, 2]], questo valore viene impostato su 0,83 (5 di 6) se il modello ha previsto [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
Perdita per il batch di convalida. |
validation_mean_token_accuracy |
Percentuale di token nel batch di convalida stimati correttamente dal modello. Ad esempio, se le dimensioni del batch sono impostate su 3 e i dati contengono completamenti [[1, 2], [0, 5], [4, 2]], questo valore viene impostato su 0,83 (5 di 6) se il modello ha previsto [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
Perdita di convalida calcolata alla fine di ogni epoca. Quando il training va bene, la perdita dovrebbe diminuire. |
full_valid_mean_token_accuracy |
Accuratezza del token media valida calcolata alla fine di ogni epoca. Quando il training va bene, l'accuratezza del token dovrebbe aumentare. |
È anche possibile visualizzare i dati nel file results.csv come tracciati nel portale di Microsoft Foundry. Selezionare il collegamento per il modello sottoposto a training; verranno visualizzati tre grafici: perdita, accuratezza del token media e accuratezza del token. Se sono stati forniti dati di convalida, entrambi i set di dati verranno visualizzati nello stesso tracciato.
Cercare la perdita da ridurre nel tempo e l'accuratezza da aumentare. Una divergenza tra i dati di training e i dati di convalida potrebbe indicare un overfitting. Provare a eseguire il training con meno periodi o a un moltiplicatore di frequenza di trading più piccolo.
Distribuire un modello ottimizzato
Dopo aver soddisfatto le metriche del processo di ottimizzazione, oppure si vuole semplicemente passare all'inferenza, è necessario distribuire il modello.
Se si esegue la distribuzione per un'ulteriore convalida, valutare la possibilità di eseguire la distribuzione per i test usando una distribuzione per sviluppatori.
A differenza dei comandi SDK precedenti, la distribuzione deve essere eseguita usando l'API del piano di controllo che richiede un'autorizzazione separata, un percorso API diverso e una versione differente dell'API.
| Variabile | Definizione |
|---|---|
| token | Esistono diversi modi per generare un token di autorizzazione. Il metodo più semplice per i test iniziali consiste nell'avviare Cloud Shell dal portale di Azure. Quindi eseguire az account get-access-token. È possibile usare questo token come token di autorizzazione temporaneo per il test dell'API. È consigliabile archiviare questo valore in una nuova variabile di ambiente. |
| abbonamento | ID sottoscrizione per la risorsa Azure OpenAI associata. |
| gruppo di risorse | Nome del gruppo di risorse per la risorsa Azure OpenAI. |
| nome_risorsa | Nome della risorsa di Azure OpenAI. |
| model_deployment_name | Nome personalizzato per la nuova distribuzione del modello ottimizzata. Questo è il nome a cui verrà fatto riferimento nel codice quando si effettuano chiamate di completamento della chat. |
| fine_tuned_model | Recuperare questo valore dai risultati del processo di ottimizzazione nel passaggio precedente. Sarà simile a gpt-4.1-2025-04-14.ft-b044a9d3cf9c4228b5d393567f693b83. Sarà necessario aggiungere tale valore al deploy_data json. In alternativa, è anche possibile distribuire un checkpoint passando l'ID del checkpoint, che verrà visualizzato nel formato ftchkpt-e559c011ecc04fc68eaa339d8227d02d |
import json
import os
import requests
token= os.getenv("<TOKEN>")
subscription = "<YOUR_SUBSCRIPTION_ID>"
resource_group = "<YOUR_RESOURCE_GROUP_NAME>"
resource_name = "<YOUR_AZURE_OPENAI_RESOURCE_NAME>"
model_deployment_name ="gpt-41-ft" # custom deployment name that you will use to reference the model when making inference calls.
deploy_params = {'api-version': "2024-10-01"} # control plane API version rather than dataplane API for this call
deploy_headers = {'Authorization': 'Bearer {}'.format(token), 'Content-Type': 'application/json'}
deploy_data = {
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": <"fine_tuned_model">, #retrieve this value from the previous call, it will look like gpt-4.1-2025-04-14.ft-b044a9d3cf9c4228b5d393567f693b83
"version": "1"
}
}
}
deploy_data = json.dumps(deploy_data)
request_url = f'https://management.azure.com/subscriptions/{subscription}/resourceGroups/{resource_group}/providers/Microsoft.CognitiveServices/accounts/{resource_name}/deployments/{model_deployment_name}'
print('Creating a new deployment...')
r = requests.put(request_url, params=deploy_params, headers=deploy_headers, data=deploy_data)
print(r)
print(r.reason)
print(r.json())
Altre informazioni sulla distribuzione tra aree e sull'uso del modello distribuito sono disponibili qui.
Se si è pronti per la distribuzione per la produzione o si hanno specifiche esigenze di residenza dei dati, seguire la guida alla distribuzione.
Ottimizzazione continua
Dopo aver creato un modello ottimizzato, si può desiderare di continuare a perfezionare il modello nel tempo tramite un'ulteriore ottimizzazione. L'ottimizzazione continua è il processo iterativo per selezionare un modello già ottimizzato come modello di base e ottimizzarlo ulteriormente sui nuovi set di esempi di training.
Annotazioni
L'ottimizzazione continua è supportata solo per i modelli OpenAI.
Per eseguire l'ottimizzazione su un modello ottimizzato in precedenza, è necessario usare lo stesso processo descritto in Creare un modello personalizzato, ma invece di specificare il nome di un modello di base generico, è necessario specificare l'ID del modello già ottimizzato. L'ID modello ottimizzato è simile al seguente gpt-4.1-2025-04-14.ft-5fd1918ee65d4cd38a5dcf6835066ed7
response = client.fine_tuning.jobs.create(
training_file=training_file_id,
validation_file=validation_file_id,
model="gpt-4.1-2025-04-14.ft-5fd1918ee65d4cd38a5dcf6835066ed7"
)
job_id = response.id
# You can use the job ID to monitor the status of the fine-tuning job.
# The fine-tuning job will take some time to start and complete.
print("Job ID:", response.id)
print("Status:", response.id)
print(response.model_dump_json(indent=2))
È anche consigliabile includere il parametro suffix per semplificare la distinzione tra iterazioni differenti del modello ottimizzato.
suffix accetta una stringa ed è impostato per identificare il modello ottimizzato. Con l'API Python OpenAI è supportata una stringa di un massimo di 18 caratteri che verrà aggiunta al nome del modello ottimizzato.
Se non si è certi dell'ID del modello ottimizzato esistente, queste informazioni sono disponibili nella pagina Modelli di Microsoft Foundry oppure è possibile generare un elenco di modelli per una determinata risorsa OpenAI di Azure usando l'API REST.
Pulire le distribuzioni, i modelli personalizzati e i file di training
Al termine del modello personalizzato, è possibile eliminare la distribuzione e il modello. È anche possibile eliminare i file di training e convalida caricati nel servizio, se necessario.
Eliminare la distribuzione del modello
Importante
Dopo la distribuzione di un modello personalizzato, se in qualsiasi momento la distribuzione rimane inattiva per più di quindici (15) giorni, la distribuzione verrà eliminata. La distribuzione di un modello personalizzato è inattiva se il modello è stato distribuito più di quindici (15) giorni prima e non sono stati effettuati completamenti o chiamate di completamento della chat per un periodo continuativo di 15 giorni.
L'eliminazione di una distribuzione inattiva non elimina o influisce sul modello personalizzato sottostante e il modello personalizzato può essere ridistribuito in qualsiasi momento. Come descritto nei prezzi di Azure OpenAI in Modelli di Fonderia Microsoft, ogni modello personalizzato, ottimizzato e distribuito comporta un costo di hosting orario indipendentemente dal fatto che vengano effettuate chiamate di completamento o di completamento della chat al modello. Per altre informazioni sulla pianificazione e la gestione dei costi con Azure OpenAI, vedere le linee guida in Pianificare la gestione dei costi per Azure OpenAI.
È possibile usare vari metodi per eliminare la distribuzione per il modello personalizzato:
Eliminare il modello personalizzato
Analogamente, è possibile usare vari metodi per eliminare il modello personalizzato:
Annotazioni
Non è possibile eliminare un modello personalizzato se ha una distribuzione esistente. Prima di poter eliminare il modello personalizzato, è necessario eliminare la distribuzione del modello.
Eliminare i file di training
Facoltativamente, è possibile eliminare i file di training e convalida caricati per il training e i file di risultato generati durante il training dall'abbonamento a Azure OpenAI. È possibile usare i metodi seguenti per eliminare i file di training, convalida e risultato:
- Microsoft Foundry
- Le API REST
- Python SDK
L'esempio Python seguente usa Python SDK per eliminare i file di training, convalida e risultato per il modello personalizzato:
print('Checking for existing uploaded files.')
results = []
# Get the complete list of uploaded files in our subscription.
files = openai.File.list().data
print(f'Found {len(files)} total uploaded files in the subscription.')
# Enumerate all uploaded files, extracting the file IDs for the
# files with file names that match your training dataset file and
# validation dataset file names.
for item in files:
if item["filename"] in [training_file_name, validation_file_name, result_file_name]:
results.append(item["id"])
print(f'Found {len(results)} already uploaded files that match our files')
# Enumerate the file IDs for our files and delete each file.
print(f'Deleting already uploaded files.')
for id in results:
openai.File.delete(sid = id)
Prerequisiti
- Leggere la Guida Quando usare l'ottimizzazione di Azure OpenAI.
- Una sottoscrizione di Azure. Creane uno gratis.
- Risorsa Azure OpenAI. Per altre informazioni, vedere Creare una risorsa e distribuire un modello con Azure OpenAI.
- Per ottimizzare l'accesso è necessario il ruolo Utente AI di Azure.
- Se non si ha già accesso alla quota di visualizzazione e si distribuiscono modelli nel portale di Microsoft Foundry, sono necessarie autorizzazioni aggiuntive.
Modelli supportati
Consultare la pagina dei modelli per verificare quali aree supportano attualmente l'ottimizzazione.
In alternativa, è possibile ottimizzare un modello ottimizzato in precedenza, formattato come base-model.ft-{jobid}.
Esaminare il flusso di lavoro per l'API REST
Esaminare il flusso di lavoro di ottimizzazione per l'uso delle API REST e Python con Azure OpenAI:
- Preparare i dati di training e convalida.
- Selezionare un modello di base.
- Caricare i dati di training.
- Eseguire il training del nuovo modello personalizzato.
- Controllare lo stato del modello personalizzato.
- Distribuire il modello personalizzato per l'uso.
- Usare il modello personalizzato.
- Facoltativamente, analizzare prestazioni e adattamento del modello personalizzato.
Preparare i dati di training e convalida
I dati di training e i set di dati di convalida sono costituiti da esempi di input e output per il modo in cui si vuole eseguire il modello.
I dati di training e convalida che utilizzi devono essere formattati come documento JSON Lines (JSONL) e nel formato conversazionale utilizzato dall'API Chat completions.
Per una procedura dettagliata sull'ottimizzazione di un modello gpt-4o-mini-2024-07-18, vedere l'esercitazione sull'ottimizzazione di OpenAI di Azure.
Formato del file di esempio
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who discovered Antarctica?"}, {"role": "assistant", "content": "Some chaps named Fabian Gottlieb von Bellingshausen and Mikhail Lazarev, as if they don't teach that in every school!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the biggest ocean?"}, {"role": "assistant", "content": "The Pacific Ocean. It's not like it's a small pond or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest planet?"}, {"role": "assistant", "content": "It's called Jupiter, you might have heard of it...or not."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who painted the Mona Lisa?"}, {"role": "assistant", "content": "Oh, some obscure artist named Leonardo da Vinci. Not that he is famous or anything."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the boiling point of water?"}, {"role": "assistant", "content": "Exciting fact of the day: it's 100 degrees Celsius. Life-changing, isn't it?"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'The Odyssey'?"}, {"role": "assistant", "content": "Oh, just some poet named Homer. Nothing special, really."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the largest mammal?"}, {"role": "assistant", "content": "Blue Whale. Quite a big fish isn't it? Oh wait, it's not a fish!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the highest mountain peak?"}, {"role": "assistant", "content": "Everest. Brace yourself, it's not a walk in the park."}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who invented the telephone?"}, {"role": "assistant", "content": "A guy named Alexander Graham Bell. Bet you didn't guess that one!"}]}
{"messages": [{"role": "system", "content": "Clippy is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What is the distance from Earth to the Sun?"}, {"role": "assistant", "content": "About 93 million miles. Just a quick drive, really."}]}
Formato di file chat multiturn
Sono inoltre supportati diversi turn di una conversazione in una singola riga del file di training jsonl. Per ignorare l'ottimizzazione su messaggi di assistente specifici, aggiungere la coppia di valori di chiave weight facoltativa. Attualmente è possibile impostare weight su 0 o 1.
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "What's the capital of France?"}, {"role": "assistant", "content": "Paris", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Paris, as if everyone doesn't know that already.", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "Who wrote 'Romeo and Juliet'?"}, {"role": "assistant", "content": "William Shakespeare", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Oh, just some guy named William Shakespeare. Ever heard of him?", "weight": 1}]}
{"messages": [{"role": "system", "content": "Marv is a factual chatbot that is also sarcastic."}, {"role": "user", "content": "How far is the Moon from Earth?"}, {"role": "assistant", "content": "384,400 kilometers", "weight": 0}, {"role": "user", "content": "Can you be more sarcastic?"}, {"role": "assistant", "content": "Around 384,400 kilometers. Give or take a few, like that really matters.", "weight": 1}]}
Completamento della chat con Visione
{"messages": [{"role": "user", "content": [{"type": "text", "text": "What's in this image?"}, {"type": "image_url", "image_url": {"url": "https://raw.githubusercontent.com/MicrosoftDocs/azure-ai-docs/main/articles/ai-services/openai/media/how-to/generated-seattle.png"}}]}, {"role": "assistant", "content": "The image appears to be a watercolor painting of a city skyline, featuring tall buildings and a recognizable structure often associated with Seattle, like the Space Needle. The artwork uses soft colors and brushstrokes to create a somewhat abstract and artistic representation of the cityscape."}]}
Oltre al formato JSONL, i file di dati di training e convalida devono essere codificati in UTF-8 e includere un byte order mark (BOM). Il file deve avere dimensioni inferiori a 512 MB.
Creare i set di dati di training e convalida
Più esempi di training sono disponibili, meglio è. L'ottimizzazione dei processi non procederà senza almeno 10 esempi di training; tuttavia, un numero così ridotto non è sufficiente per influenzare notevolmente le risposte del modello. È consigliabile fornire centinaia, se non migliaia, di esempi di training per avere successo.
In generale, il raddoppio delle dimensioni del set di dati può comportare un aumento lineare della qualità del modello. Tenere tuttavia presente che gli esempi di bassa qualità possono influire negativamente sulle prestazioni. Se si esegue il training del modello su una grande quantità di dati interni, senza prima eliminare il set di dati solo degli esempi di qualità più elevati, è possibile ottenere un modello che comporta prestazioni molto peggiori del previsto.
Caricare i dati di training
Il passaggio successivo consiste nella scelta dei dati di training preparati esistenti o nel caricamento di nuovi dati di training preparati da usare durante l'ottimizzazione del modello. Dopo aver preparato i dati di training, è possibile caricare i file nel servizio. Sono disponibili due modi per caricare i dati di training:
Per i file di dati di grandi dimensioni, è consigliabile eseguire l'importazione da un archivio BLOB di Azure. I file di grandi dimensioni possono diventare instabili quando vengono caricati tramite moduli in più parti, perché le richieste sono atomiche e non possono essere ritentate o riprese. Per altre informazioni su Archiviazione BLOB di Azure, vedere Che cos’è l’archiviazione BLOB di Azure?
Annotazioni
I file di dati di training devono essere formattati come file JSONL, codificati in UTF-8 con un byte order mark (BOM). Il file deve avere dimensioni inferiori a 512 MB.
Carica dati di training
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/files \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\training_set.jsonl;type=application/json"
Caricare i dati di convalida
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/files \
-H "Content-Type: multipart/form-data" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-F "purpose=fine-tune" \
-F "file=@C:\\fine-tuning\\validation_set.jsonl;type=application/json"
Creare un modello personalizzato
Dopo aver caricato i file di training e convalida, si è pronti per avviare il processo di ottimizzazione. Il codice seguente mostra un esempio di come creare un nuovo processo di ottimizzazione con l'API REST.
In questo esempio viene passato anche il parametro per il inizializzazione. Il seme controlla la riproducibilità del lavoro. Il passaggio degli stessi parametri di inizializzazione e processo dovrebbe produrre gli stessi risultati, ma in rari casi può differire. Se non viene specificato un valore di inizializzazione, ne verrà generato uno automaticamente.
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-4.1-2025-04-14",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"seed": 105
}'
Se si ottimizza finemente un modello che supporta Training Globale, è possibile specificare il tipo di training usando l'argomento denominato extra_body e la versione API 2025-04-01-preview:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/fine_tuning/jobs?api-version=2025-04-01-preview \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-4.1-2025-04-14",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"seed": 105,
"trainingType": "globalstandard"
}'
È anche possibile passare parametri facoltativi aggiuntivi, ad esempio gli iperparametri, per assumere un maggiore controllo del processo di ottimizzazione. Per il training iniziale, è consigliabile usare le impostazioni predefinite automatiche presenti senza specificare questi parametri.
Gli iperparametri attualmente supportati per i Fine-Tuning con supervisione sono:
| Nome | Tipo | Descrizione |
|---|---|---|
batch_size |
integer | Dimensioni del batch da usare per il training. Le dimensioni del batch sono il numero di esempi di training usati per eseguire il training di un singolo passaggio avanti e indietro. In generale, è stato rilevato che le dimensioni dei batch più grandi tendono a funzionare meglio per set di dati di dimensioni maggiori. Il valore predefinito e il valore massimo per questa proprietà sono specifici di un modello di base. Una dimensione batch maggiore indica che i parametri del modello vengono aggiornati meno frequentemente, ma con varianza inferiore. |
learning_rate_multiplier |
d'acquisto | Moltiplicatore della frequenza di apprendimento da usare per il training. La velocità di apprendimento di ottimizzazione è la velocità di apprendimento originale usata per il training preliminare moltiplicata per questo valore. I tassi di apprendimento più elevati tendono a ottenere prestazioni migliori con dimensioni batch maggiori. È consigliabile provare con i valori compresi nell'intervallo da 0,02 a 0,2 per vedere quali risultati producono i risultati migliori. Un tasso di apprendimento inferiore può essere utile per evitare l'overfitting. |
n_epochs |
integer | Numero di periodi per cui eseguire il training del modello. Un periodo fa riferimento a un ciclo completo attraverso il set di dati di training. |
seed |
integer | Il seme controlla la riproducibilità del lavoro. Il passaggio degli stessi parametri di inizializzazione e processo dovrebbe produrre gli stessi risultati, ma in rari casi può differire. Se non viene specificato un valore di inizializzazione, ne verrà generato uno automaticamente. |
Annotazioni
Per altre informazioni sugli iperparametri supportati, vedere le guide per l'ottimizzazione delle preferenze dirette e l'ottimizzazione del rinforzo .
Tipo di training
Selezionare il livello di training in base al caso d'uso e al budget.
Standard: il training viene eseguito nell'area della risorsa Fonderia attuale, fornendo garanzie di residenza dei dati. Ideale per i carichi di lavoro in cui i dati devono rimanere in un'area specifica.
Globale: offre prezzi più convenienti rispetto a Standard sfruttando la capacità oltre l'area corrente. I dati e i pesi vengono copiati nella regione in cui avviene l'addestramento. Ideale se la residenza dei dati non è una restrizione e si vogliono tempi di coda più rapidi.
Sviluppatore (anteprima): offre risparmi significativi sui costi sfruttando la capacità inattiva per la formazione. Non ci sono garanzie di latenza o di accordo sul livello del servizio, quindi i processi in questo livello possono essere sospesi automaticamente e ripresi in un secondo momento. Non esistono garanzie di residenza dei dati. Ideale per la sperimentazione e i carichi di lavoro sensibili ai prezzi.
curl -X POST "https://<ACCOUNT-NAME>.openai.azure.com/openai/fine_tuning/jobs?api-version=2025-04-01-preview" -H "Content-Type: application/json" -H "api-key: <API-KEY>" -d "{"model": "gpt-4.1", "training_file": "<FILE_ID>", "hyperparameters": {"prompt_loss_weight": 0.1}, "trainingType": "developerTier"}"
Controllare lo stato del modello personalizzato
Dopo aver avviato un processo di ottimizzazione, il completamento può richiedere del tempo. Il processo potrebbe essere in coda dietro altri processi nel sistema. Il training del modello può richiedere minuti o ore, a seconda delle dimensioni del modello e del set di dati. L'esempio seguente usa l'API REST per controllare lo stato del processo di ottimizzazione. L'esempio recupera informazioni sul processo usando l'ID processo restituito dall'esempio precedente:
curl -X GET $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs/<YOUR-JOB-ID> \
-H "api-key: $AZURE_OPENAI_API_KEY"
Sospendere e riprendere
Durante il training è possibile visualizzare i log e le metriche e sospendere il processo in base alle esigenze. La sospensione può essere utile se le metriche non sono convergenti o se si ritiene che il modello non stia imparando al ritmo corretto. Una volta sospeso il processo di addestramento, verrà creato un checkpoint distribuibile al termine delle valutazioni di sicurezza. Questo checkpoint è disponibile per la distribuzione e l'utilizzo per l'inferenza o per riprendere il processo fino al completamento. L'operazione di sospensione è applicabile solo per i processi sottoposti a training per almeno un passaggio e che siano in stato In esecuzione.
Pausa
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs/{fine_tuning_job_id}/pause \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Riprendi
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs/{fine_tuning_job_id}/resume \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Elencare gli eventi di ottimizzazione
Per esaminare i singoli eventi di ottimizzazione generati durante il training:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs/{fine_tuning_job_id}/events \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Copia modello (anteprima)
È ora possibile copiare un modello con checkpoint ottimizzato da un'area a un'altra, in sottoscrizioni differenti, ma all'interno dello stesso tenant. Il processo usa API dedicate per garantire trasferimenti efficienti e sicuri. Questa funzionalità è attualmente disponibile solo con l'API e non tramite il portale Fonderia. Dopo aver copiato il modello dall'area A all'area B, è possibile ottimizzare continuamente il modello nell'area B e distribuire il modello da questa posizione.
Annotazioni
L'eliminazione del checkpoint del modello nell'area di origine non causerà l'eliminazione del modello nell'area di destinazione. Per eliminare il modello in entrambe le aree dopo che è stato copiato, è necessario eliminare il modello separatamente in ogni area.
Prerequisiti
- La risorsa/l'account di destinazione deve avere almeno un processo di ottimizzazione.
- La risorsa/l'account di destinazione non deve disabilitare l'accesso alla rete pubblica. (almeno durante l'invio della richiesta di copia).
- È possibile copiare nell'account di destinazione solo se l'account che avvia la copia dispone di autorizzazioni sufficienti per accedere all'account di destinazione.
Configurazione delle autorizzazioni
- Creare un'identità gestita assegnata dall'utente.
- Assegna il ruolo utente di Azure AI all'identità gestita assegnata dall'utente sulla risorsa o sull'account di destinazione.
- Assegnare l'identità gestita assegnata dall'utente all'account della risorsa di origine.
Copiare il modello
curl --request POST \
--url 'https://<aoai-resource>.openai.azure.com/openai/v1/fine_tuning/jobs/<ftjob>/checkpoints/<checkpoint-name>/copy' \
--header 'Content-Type: application/json' \
--header 'api-key: <api-key>' \
--header 'aoai-copy-ft-checkpoints: preview' \
--data '{
"destinationResourceId": "<resourceId>",
"region": "<region>"
}'
Poiché si tratta di un'operazione a esecuzione prolungata, controllare lo stato della copia del modello ottimizzata specificando l'ID checkpoint dell'account di origine usato nella chiamata POST.
Verificare lo stato della copia
curl --request GET \
--url 'https://<aoai-resource>.openai.azure.com//openai/v1/fine_tuning/jobs/<ftjob>/checkpoints/<checkpoint-name>/copy' \
--header 'Content-Type: application/json' \
--header 'api-key: <api-key>' \
--header 'aoai-copy-ft-checkpoints: preview'
Annotazioni
Quando si copia un checkpoint da un account di origine, lo stesso nome del checkpoint viene mantenuto nell'account di destinazione. Assicurarsi di usare lo stesso nome per l'ottimizzazione, la distribuzione o per qualsiasi altra operazione nell'account di destinazione. Questo checkpoint non viene visualizzato nell'interfaccia utente o nell'API list checkpoints .
Punti di controllo
Al completamento di ogni periodo di training, viene generato un checkpoint. Un checkpoint è una versione completamente funzionale di un modello che può essere distribuita e usata come modello di destinazione per i processi di ottimizzazione successivi. I checkpoint possono essere particolarmente utili, in quanto possono fornire snapshot prima dell'overfitting. Al termine di un processo di ottimizzazione, le tre versioni più recenti del modello saranno disponibili per la distribuzione. L'epoca finale sarà rappresentata dal modello ottimizzato, le due epoche precedenti saranno disponibili come checkpoint.
È possibile eseguire il comando list checkpoints per recuperare l'elenco dei checkpoint associati a un singolo processo di ottimizzazione:
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs/{fine_tuning_job_id}/checkpoints \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY"
Analizzare il modello personalizzato
Azure OpenAI collega un file di risultato, denominato results.csv a ogni processo di ottimizzazione dopo il completamento. È possibile usare il file dei risultati per analizzare le prestazioni del training e convalidare del modello personalizzato. L'ID file per il file dei risultati è elencato per ogni modello personalizzato ed è possibile usare l’API REST per recuperare l'ID file e scaricare il file di risultato per l'analisi.
L'esempio Python seguente usa l'API REST per recuperare l'ID file del primo file dei risultati allegato al processo di ottimizzazione per il modello personalizzato e quindi scaricare il file nella directory di lavoro per l'analisi.
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs/<JOB_ID>" \
-H "api-key: $AZURE_OPENAI_API_KEY")
curl -X GET "$AZURE_OPENAI_ENDPOINT/openai/v1/files/<RESULT_FILE_ID>/content" \
-H "api-key: $AZURE_OPENAI_API_KEY" > <RESULT_FILENAME>
Il file dei risultati è un file CSV contenente una riga di intestazione e una riga per ogni passaggio di training eseguito dal processo di ottimizzazione. Il file dei risultati contiene le colonne seguenti:
| Nome della colonna | Descrizione |
|---|---|
step |
Numero del passaggio di training. Un passaggio di training rappresenta un singolo passaggio, avanti e indietro, in un batch di dati di training. |
train_loss |
Perdita per il batch di training. |
train_mean_token_accuracy |
Percentuale di token nel batch di training stimati correttamente dal modello. Ad esempio, se le dimensioni del batch sono impostate su 3 e i dati contengono completamenti [[1, 2], [0, 5], [4, 2]], questo valore viene impostato su 0,83 (5 di 6) se il modello ha previsto [[1, 1], [0, 5], [4, 2]]. |
valid_loss |
Perdita per il batch di convalida. |
validation_mean_token_accuracy |
Percentuale di token nel batch di convalida stimati correttamente dal modello. Ad esempio, se le dimensioni del batch sono impostate su 3 e i dati contengono completamenti [[1, 2], [0, 5], [4, 2]], questo valore viene impostato su 0,83 (5 di 6) se il modello ha previsto [[1, 1], [0, 5], [4, 2]]. |
full_valid_loss |
Perdita di convalida calcolata alla fine di ogni epoca. Quando il training va bene, la perdita dovrebbe diminuire. |
full_valid_mean_token_accuracy |
Accuratezza del token media valida calcolata alla fine di ogni epoca. Quando il training va bene, l'accuratezza del token dovrebbe aumentare. |
È anche possibile visualizzare i dati nel file results.csv come grafici nel portale Foundry. Selezionare il collegamento per il modello sottoposto a training; verranno visualizzati tre grafici: perdita, accuratezza del token media e accuratezza del token. Se sono stati forniti dati di convalida, entrambi i set di dati verranno visualizzati nello stesso tracciato.
Cercare la perdita da ridurre nel tempo e l'accuratezza da aumentare. Se viene visualizzata una divergenza tra i dati di training e di convalida, ciò potrebbe indicare un overfitting. Provare a eseguire il training con meno periodi o a un moltiplicatore di frequenza di trading più piccolo.
Distribuire un modello ottimizzato
Dopo aver soddisfatto le metriche del processo di ottimizzazione, oppure si vuole semplicemente passare all'inferenza, è necessario distribuire il modello.
Se si esegue la distribuzione per un'ulteriore convalida, valutare la possibilità di eseguire la distribuzione per i test usando una distribuzione per sviluppatori.
Se si è pronti per la distribuzione per la produzione o si hanno specifiche esigenze di residenza dei dati, seguire la guida alla distribuzione.
| Variabile | Definizione |
|---|---|
| token | Esistono diversi modi per generare un token di autorizzazione. Il metodo più semplice per i test iniziali consiste nell'avviare Cloud Shell dal portale di Azure. Quindi eseguire az account get-access-token. È possibile usare questo token come token di autorizzazione temporaneo per il test dell'API. È consigliabile archiviare questo valore in una nuova variabile di ambiente. |
| abbonamento | ID sottoscrizione per la risorsa Azure OpenAI associata. |
| gruppo di risorse | Nome del gruppo di risorse per la risorsa Azure OpenAI. |
| nome_risorsa | Nome della risorsa di Azure OpenAI. |
| model_deployment_name | Nome personalizzato per la nuova distribuzione del modello ottimizzata. Questo è il nome a cui verrà fatto riferimento nel codice quando si effettuano chiamate di completamento della chat. |
| fine_tuned_model | Recuperare questo valore dai risultati del processo di ottimizzazione nel passaggio precedente. Sarà simile a gpt-4.1-2025-04-14.ft-b044a9d3cf9c4228b5d393567f693b83. Sarà necessario aggiungere tale valore al deploy_data json. In alternativa, è anche possibile distribuire un checkpoint passando l'ID del checkpoint, che verrà visualizzato nel formato ftchkpt-e559c011ecc04fc68eaa339d8227d02d |
curl -X POST "https://management.azure.com/subscriptions/<SUBSCRIPTION>/resourceGroups/<RESOURCE_GROUP>/providers/Microsoft.CognitiveServices/accounts/<RESOURCE_NAME>/deployments/<MODEL_DEPLOYMENT_NAME>?api-version=2024-10-21" \
-H "Authorization: Bearer <TOKEN>" \
-H "Content-Type: application/json" \
-d '{
"sku": {"name": "standard", "capacity": 1},
"properties": {
"model": {
"format": "OpenAI",
"name": "<FINE_TUNED_MODEL>",
"version": "1"
}
}
}'
Altre informazioni sulla distribuzione tra aree e sull'uso del modello distribuito sono disponibili qui.
Ottimizzazione continua
Dopo aver creato un modello ottimizzato, si può desiderare di continuare a perfezionare il modello nel tempo tramite un'ulteriore ottimizzazione. L'ottimizzazione continua è il processo iterativo per selezionare un modello già ottimizzato come modello di base e ottimizzarlo ulteriormente sui nuovi set di esempi di training.
Annotazioni
L'ottimizzazione continua è supportata solo per i modelli OpenAI.
Per eseguire l'ottimizzazione su un modello ottimizzato in precedenza, è necessario usare lo stesso processo descritto in Creare un modello personalizzato, ma invece di specificare il nome di un modello di base generico, è necessario specificare l'ID del modello già ottimizzato. L'ID modello ottimizzato è simile al seguente gpt-4.1-2025-04-14.ft-5fd1918ee65d4cd38a5dcf6835066ed7
curl -X POST $AZURE_OPENAI_ENDPOINT/openai/v1/fine_tuning/jobs \
-H "Content-Type: application/json" \
-H "api-key: $AZURE_OPENAI_API_KEY" \
-d '{
"model": "gpt-4.1-2025-04-14.ft-5fd1918ee65d4cd38a5dcf6835066ed7",
"training_file": "<TRAINING_FILE_ID>",
"validation_file": "<VALIDATION_FILE_ID>",
"suffix": "<additional text used to help identify fine-tuned models>"
}'
È anche consigliabile includere il parametro suffix per semplificare la distinzione tra iterazioni differenti del modello ottimizzato.
suffix accetta una stringa ed è impostato per identificare il modello ottimizzato. Il suffisso può contenere fino a 40 caratteri (a-z, A-Z, 0-9 e _) che verranno aggiunti al nome del modello ottimizzato.
Se non si è certi dell'ID del modello ottimizzato, queste informazioni sono disponibili nella pagina Modelli di Foundry oppure è possibile generare un elenco di modelli per una determinata risorsa OpenAI di Azure usando l'API REST.
Pulire le distribuzioni, i modelli personalizzati e i file di training
Al termine del modello personalizzato, è possibile eliminare la distribuzione e il modello. È anche possibile eliminare i file di training e convalida caricati nel servizio, se necessario.
Eliminare la distribuzione del modello
È possibile usare vari metodi per eliminare la distribuzione per il modello personalizzato:
Eliminare il modello personalizzato
Analogamente, è possibile usare vari metodi per eliminare il modello personalizzato:
Annotazioni
Non è possibile eliminare un modello personalizzato se ha una distribuzione esistente. Prima di poter eliminare il modello personalizzato, è necessario eliminare la distribuzione del modello.
Eliminare i file di training
Facoltativamente, è possibile eliminare i file di training e convalida caricati per il training e i file di risultato generati durante il training dall'abbonamento a Azure OpenAI. È possibile usare i metodi seguenti per eliminare i file di training, convalida e risultato: